
[TOC]
*****
pandas使用numpy.nan来代表缺失值。缺失值不代表没有值,它本身就是某种类型的值。PYTHON中一般用None代表没有值,这与nan是两回事。缺失值不会被程序计算。处理的方式:
1. 删除含有缺失值的行
2. 填充缺失值
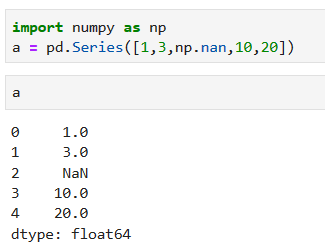
### 1.4.1. 检测缺失值,返回布尔值
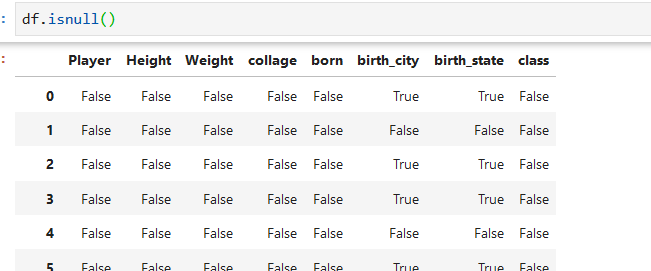
有几种方式检测数据值是否为空或缺失
```
pd.isnull(a)
```

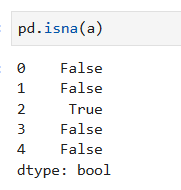

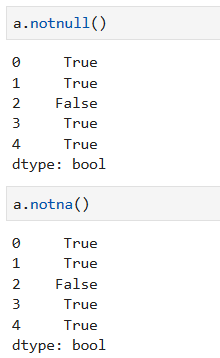
判断数据框中的每个数据是否为空
### 1.4.2. 删除与填充
对于missing value可以删除行或填充缺失值
```
#根据二维数组构建dataFrame,用list('ABCD')构建四个列
df_test = pd.DataFrame([[np.nan, 2, np.nan, 0], [3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5]],
columns=list('ABCD'))
```

```
axis=0按行删除,行里有nan类型数据就删除整行
df_test.dropna(axis = 0)
```

任意一列有nan值,删除整列
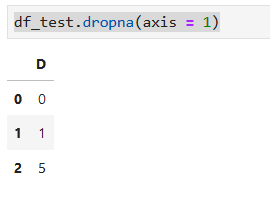
#如果某列上的值全是nan,则删除该列
df_test.dropna(axis = 1,how = "all")
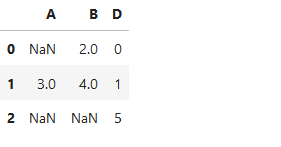
#按行删除,每行与b列相交的数据值为nan,则删除该行
df_test.dropna(axis = 0,subset=['B'])
**填充缺失值**
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)

* backfill:根据后面的值填充缺失值
* bfill根据前面的值填充缺失值
现在有例子:

a.fillna(value=10)

*****
用后面的值填充 backfill/bfill

*****
用前面一个最近的有效值填充 pad/ffill

*****
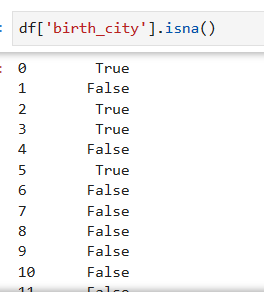
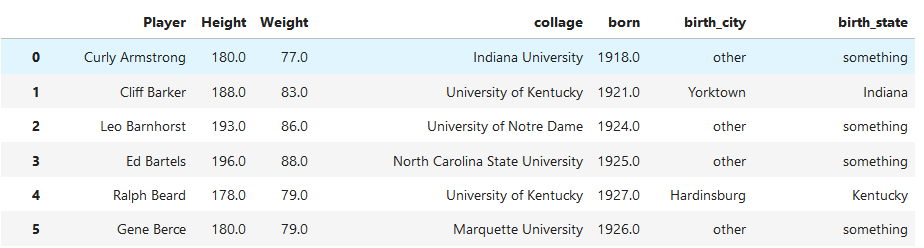
将birth_city和birth_state两列的缺失值替换为other和something
df.fillna({"birth_city":"other","birth_state":"something"})
### 1.4.3. Missing value的计算
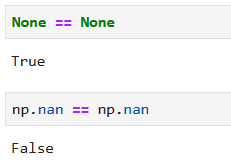
**注意**
nan之间不能比较
*****
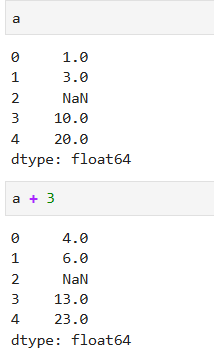
a是series,nan+3仍然是nan
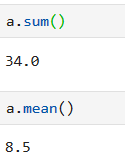
nan不参与任何数学计算,求和 求平均数都不参与
- 第五节 Pandas数据管理
- 1.1 文件读取
- 1.2 DataFrame 与 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本数据
- 1.6 分类数据
- 第六节 pandas数据分析
- 2.1 索引选取
- 2.2. 分组计算
- 2.3. 表联结
- 2.4. 数据透视与重塑(pivot table and reshape)
- 2.5 官方小结图片
- 第七节 NUMPY科学计算
- 第八节 python可视化
- 第九节 统计学
- 01 单变量
- 02 双变量
- 03 数值方法
- 第十节 概率
- 01 概率
- 02 离散概率分布
- 03 连续概率分布
- 第一节 抽样与抽样分布
- 01抽样
- 02 点估计
- 03 抽样分布
- 04 抽样分布的性质
- 第十三节 区间估计
- 01总体均值的区间估计:𝝈已知
- 02总体均值的区间估计:𝝈未知
- 03总体容量的确定
- 04 总体比率