
提供了类似于SQL的join接口,供我们进行多表组合。不同的是,pandas可以对index进行join
### 2.3.1. Concatenate
将数据集拼接在一起
```
# 样本数据
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
```
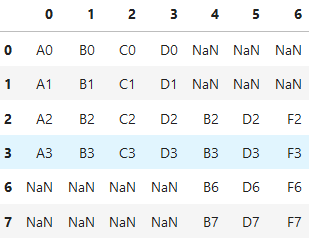
df1 df2 df3如图

```
#拼接结果如下
result = pd.concat([df1,df2,df3])
```
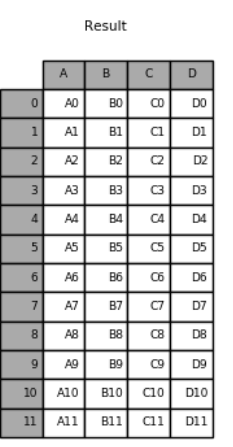
*****
```
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
#axis=1进行拼接,两张表横向相同的索引放在同一行。两张表的列并列拼接
pd.concat([df1, df4], axis=1)
#结果如下
```
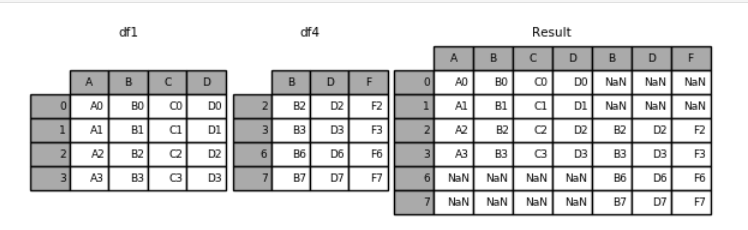
*****
```
#axis=0,两张表行并列。两张表列名相同的列放在同一列
a =pd.concat([df1, df4], axis=0)
```
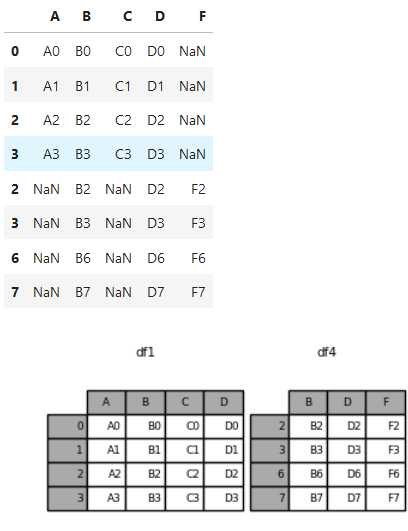
*****
```
# axis=1,join='inner'。 两张表的列并列放,在行上,只保留
#两张表共有的横向索引行
pd.concat([df1, df4], axis=1, join='inner')
```
*****
```
# axis=0,join='inner'。 两张表的行并列放,在列上,只保留
#两张表共有列。两张表列名相同的列放在同一列。
b=pd.concat([df1, df4], axis=0, join='inner')
b
#结果如下图
```
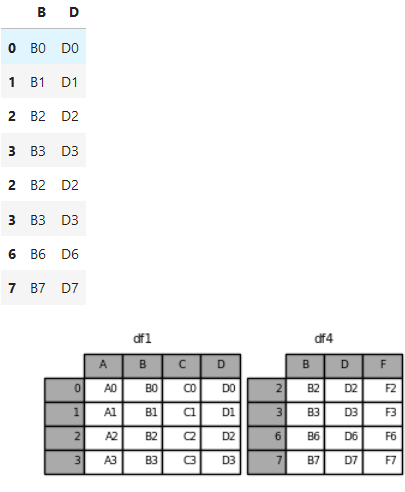
*****
```
# 将两张表按axis=0拼接后。对横向索引从0开始,重排序
d=pd.concat([df1, df4],ignore_index=True,axis=0)
d
```

*****
```
# 将两张表按axis=1拼接后。对拼接结果的列从0开始重新命名
d=pd.concat([df1, df4],ignore_index=True,axis=1)
d
```
### 2.3.2. Database-style DataFrame joining/merging
**要参照sql的表连接**
merge函数用来对两张表进行join,非常类似于sql当中的表联结。 pandas里面不仅可以对columns进行Join,还可以对index进行join。
~~~python
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
~~~
```
# 基于key列将两张表连接
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
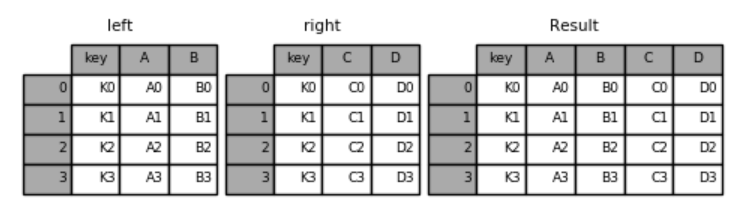
#两张表都有"key"列
result = pd.merge(left, right, on='key')
#假如两张表要连接的列列名不同,要分别指定基于左表的哪列(left_on='key')和基于右表的哪列(right_on = 'key')
pd.merge(left, right, left_on='key',right_on = 'key')
```
*****
**根据多个主键进行join**
```
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
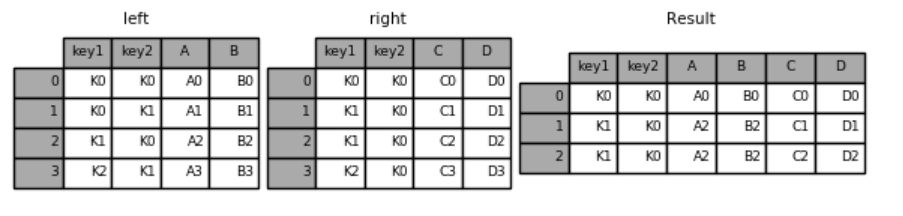
#将两张表多列主键都一样的行join,不一样的主键行都舍弃
result = pd.merge(left, right, on=['key1', 'key2'])
```
*****
```
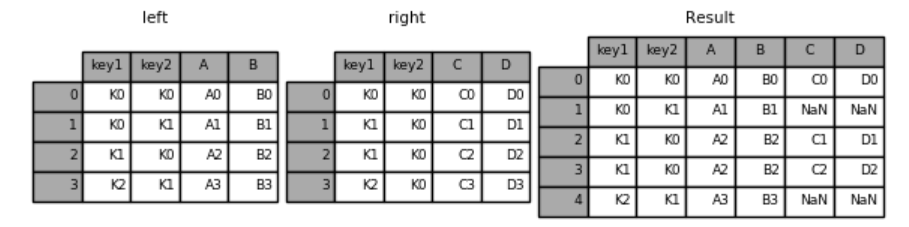
#连接方式:左连接(how='left')。左边表为基础进行连接,右边表没有对应的行显示为NaN
result = pd.merge(left, right, how='left', on=['key1', 'key2'],indicator = True)
```
*****
```
#外连接,基于两张表各自的行进行连接,另一张表若没有对应的行值都显示为NaN
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
```
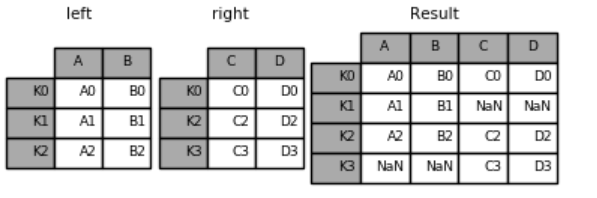
**joining on index**
```
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
#以外连接方式连接,根据左边表的全部索引(left_index=true)和右边表的全部索引(right_index=True)
result = pd.merge(left, right, left_index=True, right_index=True, how='outer')
```
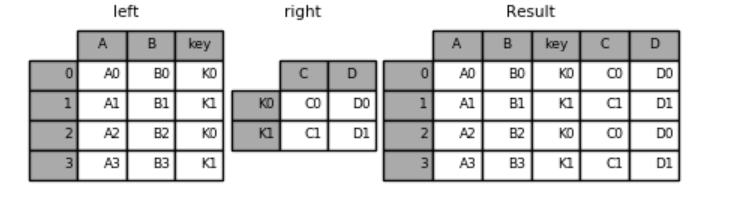
*****
```
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({'C': ['C0', 'C1'],
'D': ['D0', 'D1']},
index=['K0', 'K1'])
#左连接的方式连接两张表。基于左边表的key列(left_on='key')。基于右边表的索引列(right_index=True)
result = pd.merge(left, right, left_on='key', right_index=True,
how='left');
```
*****
- 第五节 Pandas数据管理
- 1.1 文件读取
- 1.2 DataFrame 与 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本数据
- 1.6 分类数据
- 第六节 pandas数据分析
- 2.1 索引选取
- 2.2. 分组计算
- 2.3. 表联结
- 2.4. 数据透视与重塑(pivot table and reshape)
- 2.5 官方小结图片
- 第七节 NUMPY科学计算
- 第八节 python可视化
- 第九节 统计学
- 01 单变量
- 02 双变量
- 03 数值方法
- 第十节 概率
- 01 概率
- 02 离散概率分布
- 03 连续概率分布
- 第一节 抽样与抽样分布
- 01抽样
- 02 点估计
- 03 抽样分布
- 04 抽样分布的性质
- 第十三节 区间估计
- 01总体均值的区间估计:𝝈已知
- 02总体均值的区间估计:𝝈未知
- 03总体容量的确定
- 04 总体比率