
[TOC]
*****
分类数据对应的是统计学中的分类变量:拥有一些有限的值。比如说性别,类型等等。 分类的数据可以有序列性属性,但是不支持数值类型的操作。
常用的场景如下:
1. 将一个只拥不是很多值的字符串变量转换成分类变量可以节省内存
2. 分类变量可以让数据有逻辑排序而不是词汇(词典)的排序,比如 One/two/three。词汇排序,按首字母排序
3. 和其它Python库交互时,它会被当做分类变量处理
### 1.6.1. 创建分类特征
**Series的创建**
```
import pandas as pd
# 设定dtype为category
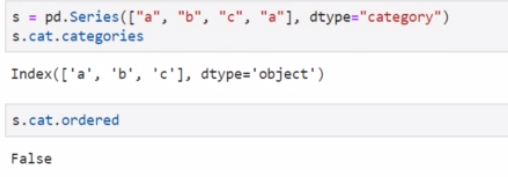
s = pd.Series(["a", "b", "c", "a"], dtype="category")
```
分类数据显示共有多少种值,重复的不显示

*****
```
# 转换已有的数据类型 将A列字符串类型转换为分类数据类型
df = pd.DataFrame({"A": ["a", "b", "c", "a"]})
#将结果保存在dataframe的B列中
df["B"] = df["A"].astype('category')
```

*****
```
# 通过pandas.Categorical 对象进行创建
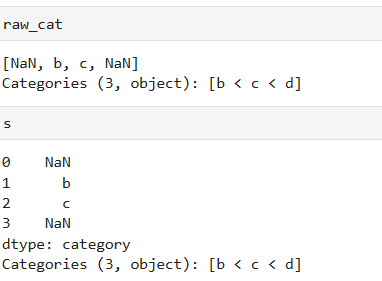
指定b c d是分类数据,同时它们有序,顺序是categories列表顺序, b<c<d
raw_cat = pd.Categorical(["a", "b", "c", "a"], categories=["b", "c", "d"],ordered=True)
#变为series
s = pd.Series(raw_cat)
```
创建结果,d在raw_cat中没有出现,但d也被定义为分类数据,共有三个分类数据
*****
将分类数据变为dataFrame的一个列

*****
**DataFrame的创建**
和之前series创建类似,不过dataframe中可以批量的将列转换格式
```
#将df_cat的两列都转换为category类型
```

*****
```
#collage列转换为category类型
df['collage'] = df['collage'].astype("category")
```

### 1.6.2. 控制分类值行为:CategoricalDtype
"category"默认了分类值的行为:
* 类别从数据中继续进行推断
* 没有排序的性质
```
from pandas.api.types import CategoricalDtype
s = pd.Series(['a','b','b','c','d'])
```
```
cat_type = CategoricalDtype(categories=['b','c','d'],ordered=True)
s.astype(cat_type)
```

一个分类的类别描述如下:
* categories:一个唯一值的序列并且没有缺失值
* ordered: 是否排序,布尔类型
```
CategoricalDtype(categories=['b','c','d'],ordered=True)
```
### 1.6.3. 分类值的描述
```
df['collage'].describe()
```

### 1.6.4. 处理分类变量
分类数据拥有分类与排序的特征:包含了分类值展示以及值之间是否是有序的。我们可以通过 s.cat.categories 与 s.cat.ordered 进行操作。如果你没有人为的设定类别与排序信息,它们会被自动推断
**展示所有的分类值**

**是否有序**
**categories 和 方法 unique()返回的值是不一样的**
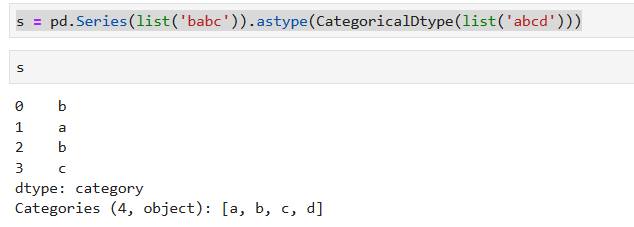
*****
显示series分类值

*****
显示series唯一值

*****

*****
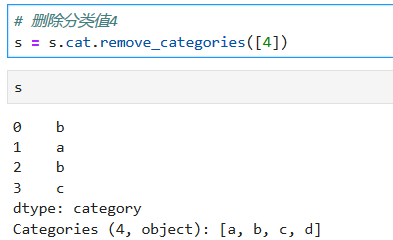
*****
series中没有分类变量d

*****

#### 1.6.4.1. 排序
```
cat_type = CategoricalDtype(categories=['one','two','three'],ordered=True)
s = pd.Series(['one','three','one','two'])
#将series变为分类类型
s = s.astype(cat_type)
```

*****
可以得到分类变量的顺序的最大最小值

- 第五节 Pandas数据管理
- 1.1 文件读取
- 1.2 DataFrame 与 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本数据
- 1.6 分类数据
- 第六节 pandas数据分析
- 2.1 索引选取
- 2.2. 分组计算
- 2.3. 表联结
- 2.4. 数据透视与重塑(pivot table and reshape)
- 2.5 官方小结图片
- 第七节 NUMPY科学计算
- 第八节 python可视化
- 第九节 统计学
- 01 单变量
- 02 双变量
- 03 数值方法
- 第十节 概率
- 01 概率
- 02 离散概率分布
- 03 连续概率分布
- 第一节 抽样与抽样分布
- 01抽样
- 02 点估计
- 03 抽样分布
- 04 抽样分布的性质
- 第十三节 区间估计
- 01总体均值的区间估计:𝝈已知
- 02总体均值的区间估计:𝝈未知
- 03总体容量的确定
- 04 总体比率