
* 类似于SQL里面的group by 语句,不过pandas提供了更加复杂的函数方法
* 我们可以对index或者column进行分组,可以被一个元素,也可以是任意多个元素分组。分组后计算的方式是一样的,无论是基于index还是column.
*****
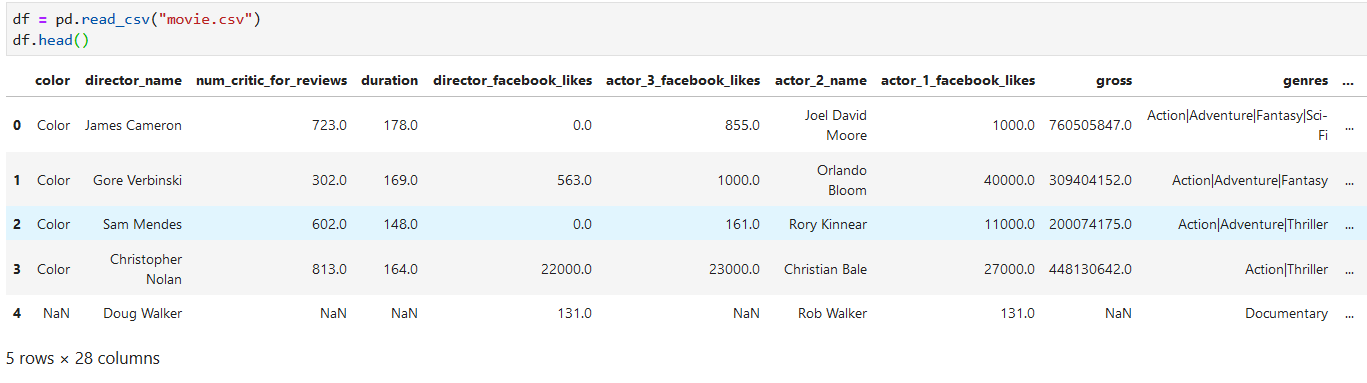
读文件
*****
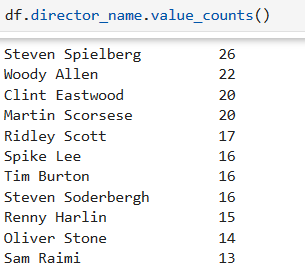
对director_name列的每个数据值进行频数统计
*****
```
#将数据集按director_name分组
grouped = df.groupby("director_name")
```
*****
#分组后对各组进行频数统计
```
grouped.size()
```

*****
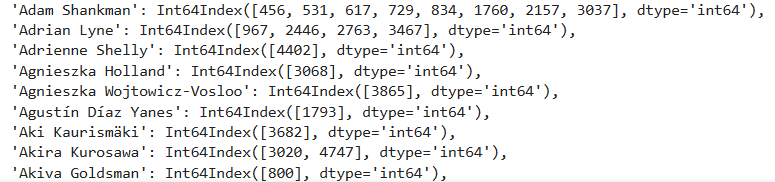
```
#可以看到每个分组的名字和在这个组下的各个索引
grouped.groups
```
*****
```
# 可以看到各个分组的名字,和每个分组下组内的各个数据
for name,group in grouped:
print(name)
print(group)
```
*****
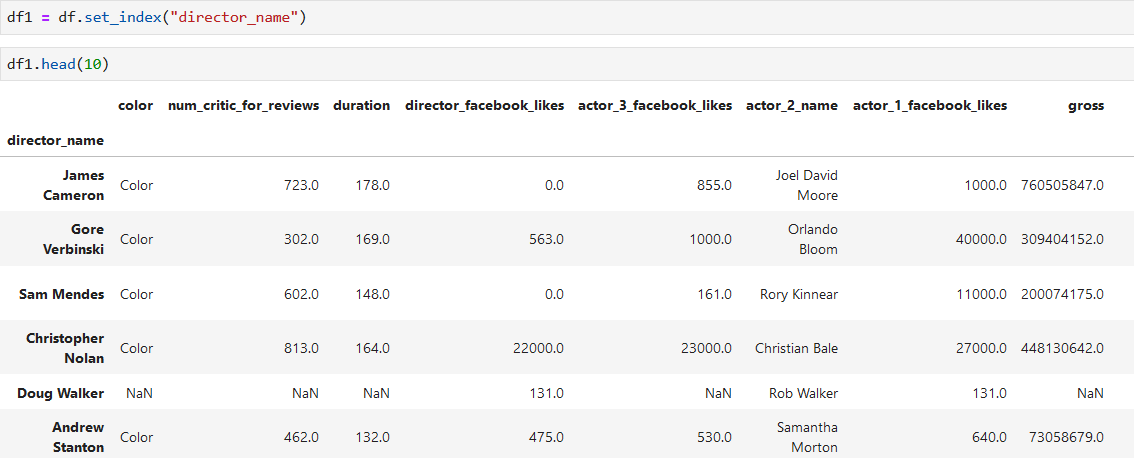
**把导演名字列作为索引,然后按照索引分组**
```
# 按照第一层索引分组
#g2 = df1.groupby(level=0)
g2 = df1.groupby(level=["director_name"])
```

### 2.2.1. 统计计算
1. 单个统计量计算 mean/sum/std
2. 多个统计量计算
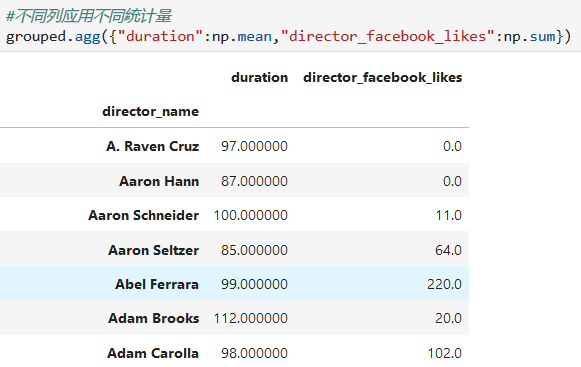
3. 不同列应用不同统计量
分组计算很重要的一点是:**我们的每一个统计函数都是作用在每一个group上,不是单个样本,也不是全部数据**
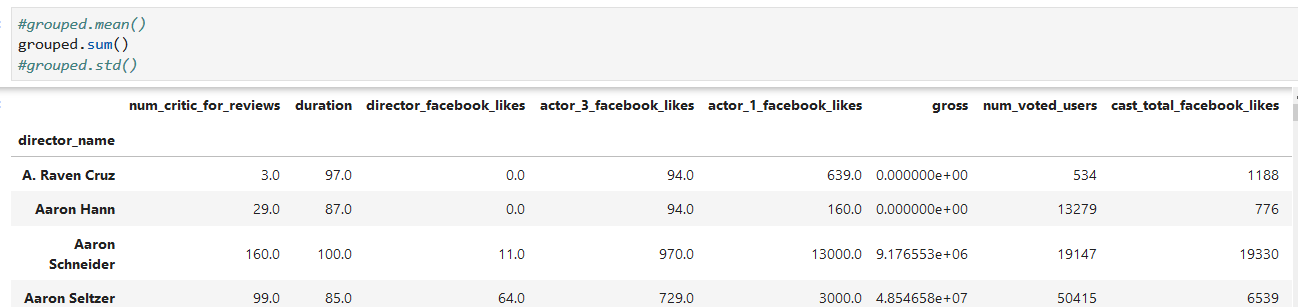
*****
对每个导演电影的时长进行求和统计
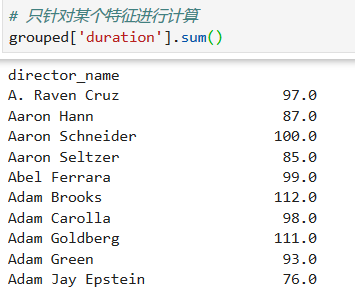
*****
对每组的两列进行统计
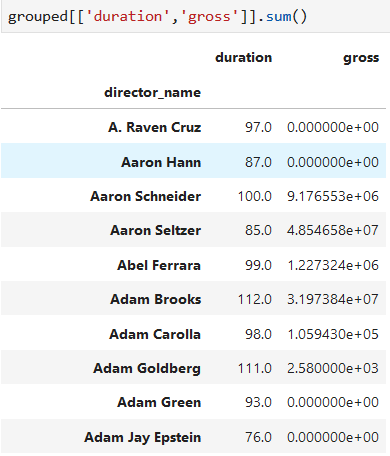
*****
对多个列进行多个统计量的统计
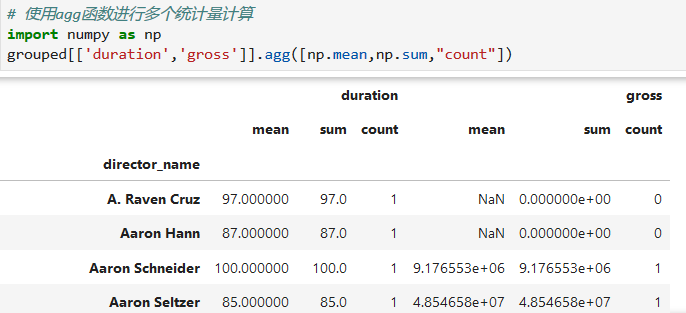
*****
*****
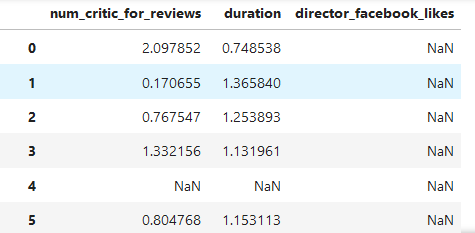
### 2.2.2. Transformation
基于每个分组操作,对组内元素进行转换
```
#将缺失值都填充为0
df1 = df.fillna(0)
#将数据集按导演名字分组
grouped = df1.groupby("director_name")
#lambda表达式 z分数计算
z_score = lambda s : (s-s.mean())/ s.std()
#将每个列的每个组内元素根据z_score进行计算转换,s.mean()是每个组的平均值
grouped[['num_critic_for_reviews','duration','director_facebook_likes']].transform(z_score)
```
*****
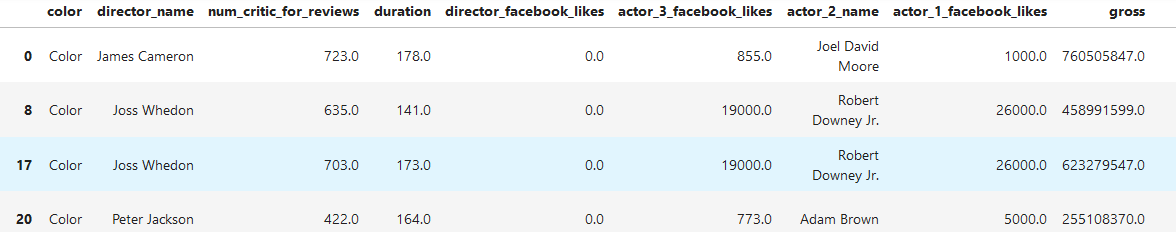
### 2.2.3. Filteration
分组过滤
```
#选出duration平均值大于等于150的分组
grouped.filter(lambda g : g['duration'].mean() >= 150)
```
*****
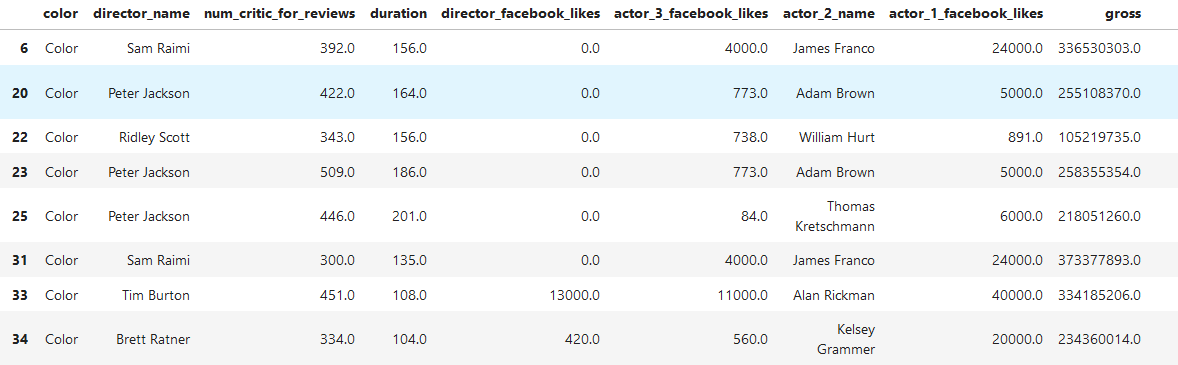
```
#选出组内数据数目大于等于10的分组
grouped.filter(lambda g : len(g) >=10)
```
- 第五节 Pandas数据管理
- 1.1 文件读取
- 1.2 DataFrame 与 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本数据
- 1.6 分类数据
- 第六节 pandas数据分析
- 2.1 索引选取
- 2.2. 分组计算
- 2.3. 表联结
- 2.4. 数据透视与重塑(pivot table and reshape)
- 2.5 官方小结图片
- 第七节 NUMPY科学计算
- 第八节 python可视化
- 第九节 统计学
- 01 单变量
- 02 双变量
- 03 数值方法
- 第十节 概率
- 01 概率
- 02 离散概率分布
- 03 连续概率分布
- 第一节 抽样与抽样分布
- 01抽样
- 02 点估计
- 03 抽样分布
- 04 抽样分布的性质
- 第十三节 区间估计
- 01总体均值的区间估计:𝝈已知
- 02总体均值的区间估计:𝝈未知
- 03总体容量的确定
- 04 总体比率