
[TOC]
https://mp.weixin.qq.com/s/Tc09ovdNacOtnMOMeRc_uA
https://mp.weixin.qq.com/s/dET7DblCg1b6KUuE-FqH-g
https://mp.weixin.qq.com/s/_ilWHsMN0mr-wTP_n7MJSQ
## 简述滑动窗口
每次tcp传输过程中,server和client会携带一个滑动窗口大小,意味着此时它能一次接受多少数据,因为数据在客户端和服务器之间是有缓存的,滑动窗口也就相当于对方告诉自己目前缓冲区的大小,不需要每次发一个数据包就回一个ACK,通过滑动窗口来进行简单的拥塞控制
## TCP如何实现可靠交付?
1. 序列号:TCP 传输时将每个字节的数据都进行了编号,这就是序列号。序列号的作用不仅仅是应答作用,有了序列号能够将接收到的数据根据序列号进行排序,并且去掉重复的数据。
2. 校验和:每个数据包保持一个端到端的校验和,接收方收到之后检查数据在传输过程中有没有改变,若发生了改变则丢弃;
3. 流量控制:保证接收方缓冲区足够接收数据,防止丢失;
>如果发送方的发送速度太快,会导致接收方的接收缓冲区填充满了,这时候继续传输数据,就会造成大量丢包,进而引起丢包重传等等一系列问题。TCP 支持根据接收端的处理能力来决定发送端的发送速度,这就是流量控制机制。
具体实现方式:接收端将自己的接收缓冲区大小放入 TCP 首部的『窗口大小』字段中,通过 ACK 通知发送端。
4. 拥塞控制:降低网络拥塞程度,防止数据包丢失;
5. 连接管理:三次握手、四次挥手的过程。
6. 超时重传:若超时未接受到对方的确认,立即重传数据包。
## TCP拥塞控制是什么?
拥塞控制是为了降低整个网络的拥塞程度。当网络出现拥塞时,分组丢失引发重传,继而加重拥塞程度,因此需要控制。发送方维护一个叫做拥塞窗口的状态变量cwnd,实际决定发送数据量的还是发送窗口。
* 慢启动 & 拥塞避免:
* 发送最初执行慢启动,cwnd = 1,发送方只能发送一个报文段。发送方每次收到ACK后将cwnd加倍。
* 为避免成倍增加的cwnd使得网络拥塞的可能增加,设置慢启动阈值ssthreash。当cwnd >= ssthresh的时候,进入拥塞避免,每次只能将cwnd的值加一。
* 若出现超时,则将 ssthresh减半,cwnd=1,重新开始慢启动。
* 快速重传 & 快速恢复:
* 在接受方,每次只确认收到的最后一个有序报文段;
* 在发送方,若收到m2的3次重复ACK,则可以确认m3丢失,此时执行快速重传,即立即重传m3;同时,由于只是丢包而不是网络拥塞,执行快速恢复:ssthresh = cwnd / 2 ,cwnd = ssthresh。
## TCP流量控制是什么?
流量控制是为了调整发送方的发送速率,使得接收方来得及接收。
接收方的确认报文中有一个窗口字段,用来控制发送方的窗口大小,从而控制发送速率。
> TCP需要提供一种机制:**让发送端根据接收端实际的接收能力控制发送的数据量**。这就是所谓的流量控制。
TCP 利用**滑动窗口**实现流量控制的机制, 而滑动窗口大小是通过TCP首部的窗口大小字段来通知对方。
窗口大小的内容实际上是接收端接收数据缓冲区的剩余大小。**这个数字越大,证明接收端接收缓冲区的剩余空间越大,网络的吞吐量越大。**
## 重传机制?
* 超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的`ACK`确认应答报文,就会重发该数据,也就是我们常说的**超时重传**。
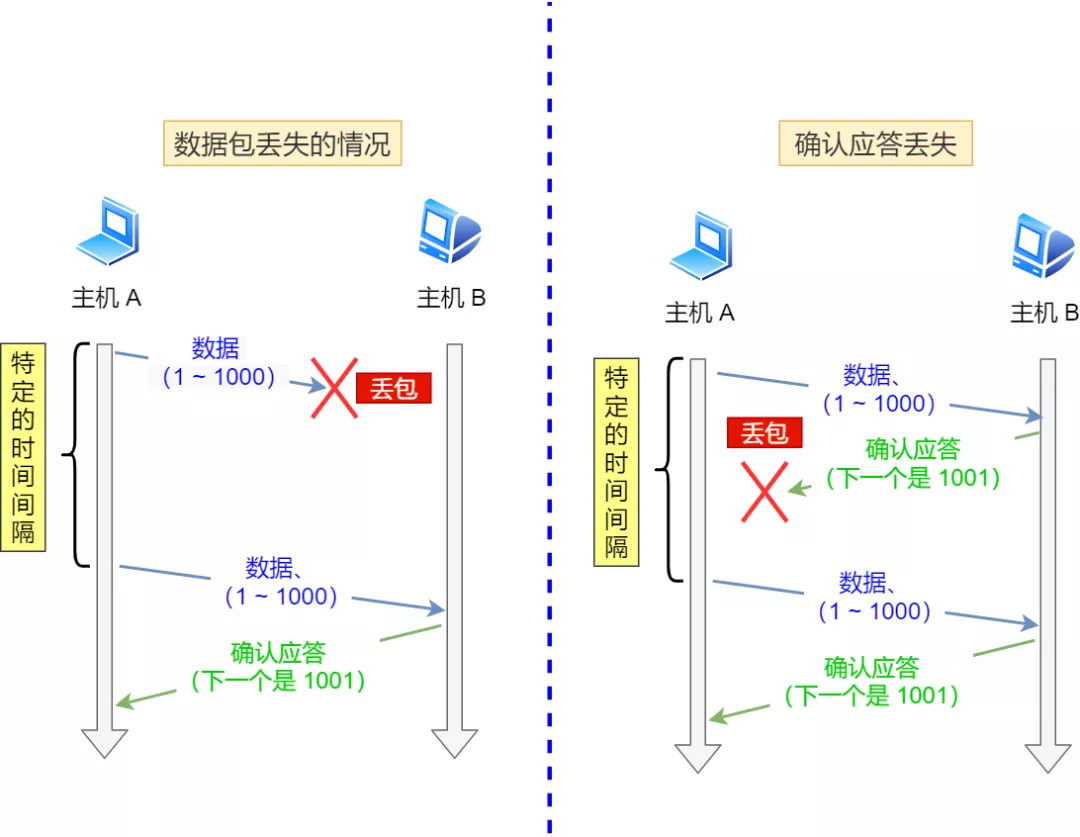
TCP 会在以下两种情况发生超时重传:
* 数据包丢失
* 确认应答丢失
* 快速重传
**不以时间为驱动,而是以数据驱动重传**。
快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是**重传的时候,是重传之前的一个,还是重传所有的问题。**
## 拥塞控制与流量控制的区别
* **流量控制**是作用于接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止丢失数据包的。
* **拥塞控制**拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况
* **流量控制**( 发送方一直发送数据,但是接收方处理不过来怎么办?(流量控制))
TCP需要提供一种机制:**让发送端根据接收端实际的接收能力控制发送的数据量**。这就是所谓的流量控制。
TCP 利用**滑动窗口**实现流量控制的机制, 而滑动窗口大小是通过TCP首部的窗口大小字段来通知对方。
窗口大小的内容实际上是接收端接收数据缓冲区的剩余大小。**这个数字越大,证明接收端接收缓冲区的剩余空间越大,网络的吞吐量越大。**
不过,当接收端这个接收缓冲区面临数据溢出时,窗口大小的值就会随之设置成一个更小值,告诉发送端要控制一下发送的数据量了。
**流量控制的具体操作就是**:接收端会在确认应答发送ACK报文时,将自己的即时窗口大小rwnd(receiver window)填入,并跟随ACK报文一起发送过去。而发送方根据ACK报文里的窗口大小的值进而改变自己的发送速度。
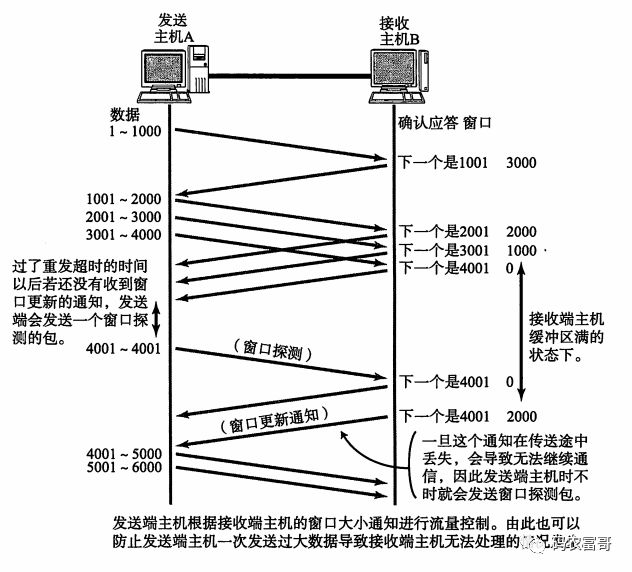
**发送端停止发送数据后,什么时候可以继续发送数据呢?**
我们继续看上图,答案就是等接收端处理完了缓冲区的数据后发送一个**窗口更新**的数据包通知,发送端才可以继续根据窗口大小发送数据。
**但是如果发送端在重发超时的时间内都没有收到窗口更新的通知或者窗口更新的包丢失了,就没法正常通信了,那怎么办呢?**
TCP为每一个连接设有一个**持续计时器(persistence timer)。**只要TCP连接的一方收到对方的零窗口通知,就启动持续计时器。若持续计时器设置的时间到期,就发送一个零窗口控测数据段(这个数据段只包含一个字节),那么收到这个报文段的一方就重新设置持续计时器。
所以发送端会定时向接收端发送一个**窗口探测**的数据段,这目的是为了获取最新的窗口大小信息。
## TCP 半连接队列和全连接队列是什么?
* TCP三次握手时,客户端发送SYN到服务端,服务端收到之后,便回复**ACK和SYN**,状态由**LISTEN变为SYN\_RCVD**,此时这个连接就被推入了**SYN队列**,即半连接队列。
* 当客户端回复ACK, 服务端接收后,三次握手就完成了。这时连接会等待被具体的应用取走,在被取走之前,它被推入ACCEPT队列,即全连接队列。
这两个队列都是有大小限制的,当超过容量后就会将链接丢弃,或者返回 RST 包。
## 拥塞控制原理
有了TCP的滑动窗口控制,收发主机之间即使不再以一个“段”为单位,而是以一个“窗口”为单位发送确认应答信号,所以发送主机够连续发送大量数据包。然而,**如果在通信刚开始的时候就发送大量的数据包,也有可能会导致网络的瘫痪。**
在拥塞控制中,发送方维持一个叫做**拥塞窗口cwnd**(congestion window)的状态变量。**拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化**。
发送窗口取拥塞窗口和接收端窗口的最小值,避免发送接收端窗口还大的数据。
拥塞控制使用了两个重要的算法:**慢启动算法**,**拥塞避免算法**。
**慢启动算法**:
慢启动算法的思路是,不要一开始就发送大量的数据,先试探一下网络的拥塞程度,也就是说由小到大逐渐增加拥塞窗口的大小。慢算法中,**每个传输轮次后将 cwnd 加倍**。慢启动,不是指拥塞窗口增长慢,而是相对于一开始就上来传输大窗口的数据要显得慢。
**拥塞避免算法**:
拥塞避免算法也是逐渐的增大 cwnd 的大小,只是采用的是**线性增长**而不是像慢启动算法那样的指数增长。
具体来说就是每个传输轮次后将 cwnd 的大小加一(加法增大),如果发现出现网络拥塞的话就按照上面的方法重新设置ssthresh的大小(乘法减小,原来的二分之一)并从cwnd=1开始重新执行慢开始算法。
## 慢启动算法和拥塞避免算法结合:
问题:在拥塞控制中, 慢启动算法 和 拥塞避免算法 是怎么配合使用的呢?
像上面所说,慢启动算法下的cwnd大小是指数增长,所以不能任 cwnd 任意增长,所以我们引入一个慢启动门限(ssthresh)的阈值来控制 cwnd 的增长。
ssthresh的作用是:
* 当cwnd < ssthresh时,使用慢开始算法。
* 当cwnd > ssthresh时,改用拥塞避免算法。
* 当cwnd = ssthresh时,慢开始与拥塞避免算法随机
还有一个问题就是这个 ssthresh 是怎么设置的呢?
**TCP/IP 中规定无论是在慢开始阶段还是在拥塞避免阶段,只要发现网络中出现拥塞(没有按时收到确认),就要把ssthresh设置为此时发送窗口的一半大小**(不能小于2)。
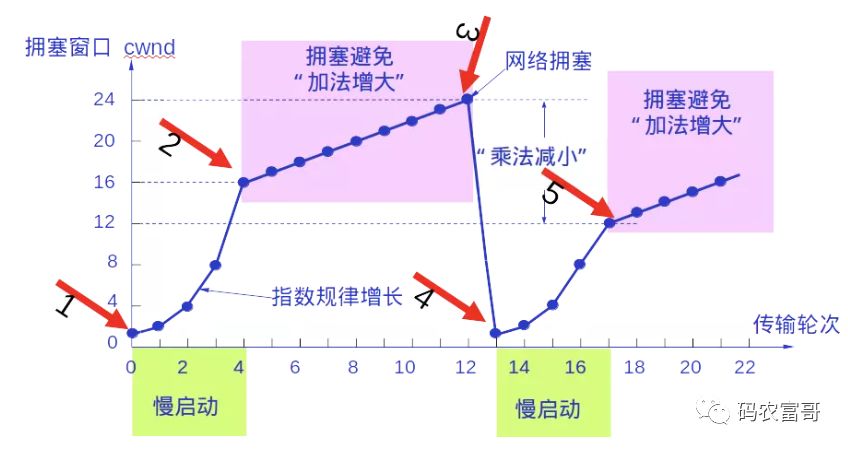
拥塞控制的大致流程如下:
* 一开始把ssthresh初始值设置成16,开始慢启动增加拥塞窗口cwnd,直到cwnd=16 停止慢启动,开始拥塞避免算法。
* 使用拥塞避免算法线性增加cwnd,直到cwnd=24,这时候网络出现拥塞(ACK确认信号没有及时到达),把ssthresh设置成原来的一半,也就是ssthresh=12,同时把cwnd设为1。
* 重新开始慢启动,直到cwnd到达ssthresh=12,然后执行拥塞避免算法进行加法增大,直到遇到网络拥塞,把ssthresh调成原来的一一半。
* 如此反复动态计算cwnd,以达到拥塞控制的目的。
## 快恢复
**快恢复算法是与快重传算法配合使用的一个算法。**
快恢复主要是指,当快重传的时候,发送方快速收到了**3个重复的确认**,因此会认为网络不是拥塞状态,所以在**乘法减小过程(设置sstresh为原来一半)**,会启动**“拥塞避免”**,而不是TCP超时重发机制的重新启动的**慢启动**
**TCP协议在实现传输可靠性上面做了很多:**
* 通过**序列号和确认应答信号**确保了数据不会重复发送和重复接收。
* 同时通过**超时重发控制**保证即使数据包在传输过程中丢失,也能重发保持数据完整。
* 通过三次握手,四次挥手建立和关闭连接的**连接管理**保证了端对端的通信可靠性。
* TCP还使用了**滑动窗口控制**提高了数据传输效率
* 通过**流量控制**控制发送者的发送速度从而使接收者来得及接收,防止丢包。
* 通过**拥塞控制**就是防止过多的数据注入到网络中,避免网络中的路由器或链路不致过载,导致数据丢失。从而保证了TCP传输的可靠性。
## 为什么会产生粘包和拆包呢?
* 要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包;
* 接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包;
* 要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包;
* 待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。即TCP报文长度-TCP头部长度>MSS。
**解决方案:**
* 发送端将每个数据包封装为固定长度
* 在数据尾部增加特殊字符进行分割
* 将数据分为两部分,一部分是头部,一部分是内容体;其中头部结构大小固定,且有一个字段声明内容体的大小。
## 为什么选择在传输层就将数据“大卸八块”分成多个段,而不是等到网络层再分片传递给数据链路层?
因为可以提高重传的性能
需要明确的是:可靠传输是在传输层进行控制的
如果在传输层不分段,一旦出现数据丢失,整个传输层的数据都得重传
如果在传输层分了段,一旦出现数据丢失,只需要重传丢失的那些段即可
## 什么是SYN攻击?怎么解决?
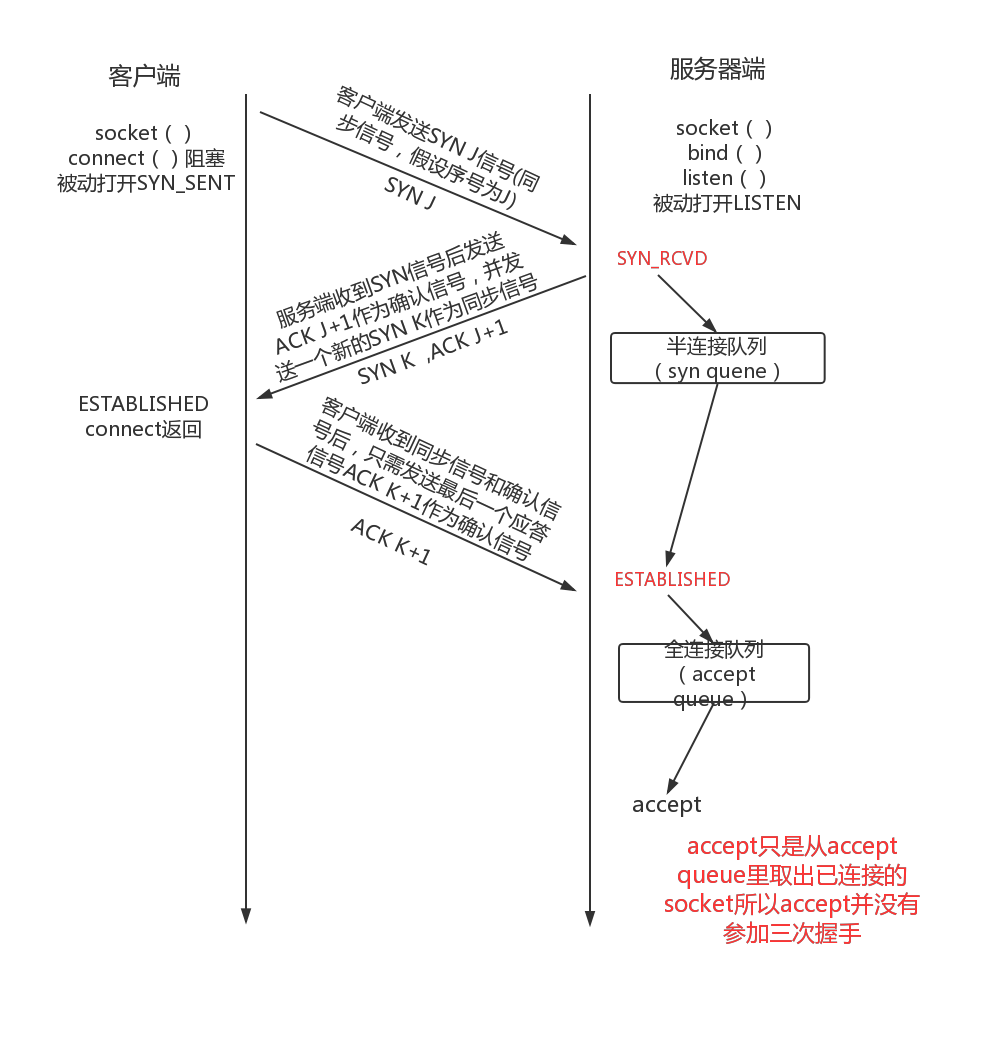
服务端在收到SYN信号后会将ACK信号和新的SYN信号返回给客户端,并将该连接计入半连接队列数目中,当半连接数目大于系统设定的最大值(/proc/sys/net/ipv4/tcp\_max\_syn\_backlog)时系统将不能再接收其他的连接,所以攻击者利用这个原理,在服务器向客户端发送SYN和ACK信号后不做任何回应,这样链接将一直不会被释放,直到累计到链接最大值而不能再创建新的链接,从而达到了让服务器无法响应正常请求的目的。
**解决方案:**
使syncookies生效,将`/proc/sys/net/ipv4/tcp_syncookies`值置改为1即可,这样即使是半连接队列syn queue已经满了,也可以接收正常的非恶意攻击的客户端的请求,
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期