
[TOC]
Mysql中日志还是挺多的,主要包含以下几个常用的日志:
1. **binlog**:归档日志, Server层的日志。
2. **redo log**:重做日志,InnoDB存储引擎层的日志。
3. **undo log**:回滚日志,提供回滚操作,InnoDB存储引擎层的日志。
4. **relay log**:中继日志,主从复制原理日志。
5. **slow_query_log**:慢查询日志,用于慢sql。
* redo log重做日志用来保证事务的持久性
* undo log回滚日志 保证事务的原子性
* undo log+redo log保证事务的一致性
* 锁(共享、排他)用来保证事务的隔离性
## binlog
binlog称为归档日志,是逻辑上的日志,它属于Mysql的Server层面的日志,记录着sql的原始逻辑
有三种格式,statement,row和mixed.
* statement模式下,记录单元为语句.即每一个sql造成的影响会记录.由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制.
* row级别下,记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大.
* mixed. 一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row.
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录.
## redo log----保证事务的持久性
>redo log日志也叫做WAL技术(Write- Ahead Logging),他是一种先写日志,并更新内存,最后再更新磁盘的技术,为了就是减少sql执行期间的数据库io操作,并且更新磁盘往往是在Mysql比较闲的时候,这样就大大减轻了Mysql的压力。
redo log是固定大小,是物理日志,属于InnoDB引擎的,并且写redo log是环状写日志的形式:
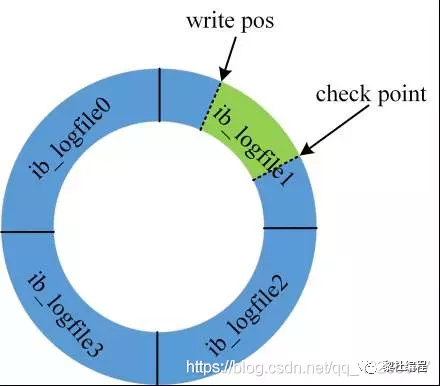
check point记录擦除的位置,因为redo log是固定大小,所以当redo log满的时候,也就是write pos追上check point的时候,需要清除redo log的部分数据,清除的数据会被持久化到磁盘中,然后将check point向前移动。
redo log日志实现了即使在数据库出现异常宕机的时候,重启后之前的记录也不会丢失,这就是crash-safe能力。
### 组成
分为两部分:一部分是内存中的重做日志缓冲(redo log buffer),是易丢失的;二部分是重做日志文件(redo log file),是持久的。InnoDB通过Force Log at Commit机制来实现持久性,当commit时,必须先将事务的所有日志写到重做日志文件进行持久化,待commit操作完成才算完成。
InnoDB在下面情况下会将重做日志缓冲的内容写入重做日志文件:
* master thread 每一秒将重做日志缓冲刷新到重做日志文件;
* 每个事务提交时
* 当重做日志缓冲池剩余空间小于1/2时
为了确保每次日志都写入重做日志文件,在每次将日志缓冲写入重做日志文件后,InnoDB存储引擎都需要调用一次fsync(刷盘)操作。但这也不是绝对的。用户可以通过修改innodb\_flush\_log\_at\_trx\_commoit参数来控制重做日志刷新到磁盘的策略,这个可以作为大量事务提交时的优化点。
* 1参数默认值,表示事务提交时必须调用一次fsync操作。
* 0表示事务提交时,重做日志缓存并不立即写入重做日志文件,而是随着Master Thread的间隔进行fsync操作。
* 2表示事务提交时将重做日志写入重做日志文件,但仅写入文件系统的缓存中,不进行fsync操作。
fsync的效率取决于磁盘的性能,因此磁盘的性能决定了事务提交的性能,也就是数据库的性能。**所以如果有人问你如何优化Mysql数据库的时候别忘了有硬件这一条,让他们提升硬盘配置,换SSD固态硬盘**
重做日志都是以512字节进行存储的,称之为重做日志块,与磁盘扇区大小一致,这意味着重做日志的写入可以保证原子性,不需要doublewrite技术。它有以下3个特性:
* 重做日志是在InnoDB层产生的
* 重做日志是物理格式日志,记录的是对每个页的修改
* 重做日志在事务进行中不断被写入,而且是顺序写入
## undo log-----保证事务的原子性
它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
**作用**
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
**内容**
逻辑格式的日志,在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,这一点是不同于redo log的。
**什么时候产生**
事务开始之前,将当前是的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性
**什么时候释放**
当事务提交之后,undo log并不能立马被删除,
而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
### 实现的功能
1.实现事务回滚
2.实现MVCC
>事务提交后并不能马上删除undo log,这是因为可能还有其他事务需要通过undo log 来得到行记录之前的版本。故事务提交时将undo log 放入一个链表中,是否可以删除undo log 根据操作不同分以下2种情况:
>* Insert undo log: insert操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo log可以在事务提交后直接删除。不需要进行 purge操作。
>* update undo log:记录的是对 delete和 update操作产生的 undo log。该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待 purge线程进行最后的删除。
## relay log
relay log中继日志用于实现主从复制
主从复制中分为「主服务器(master)「和」从服务器(slave)」,「主服务器负责写,而从服务器负责读」,Mysql的主从复制的过程是一个「异步的过程」。
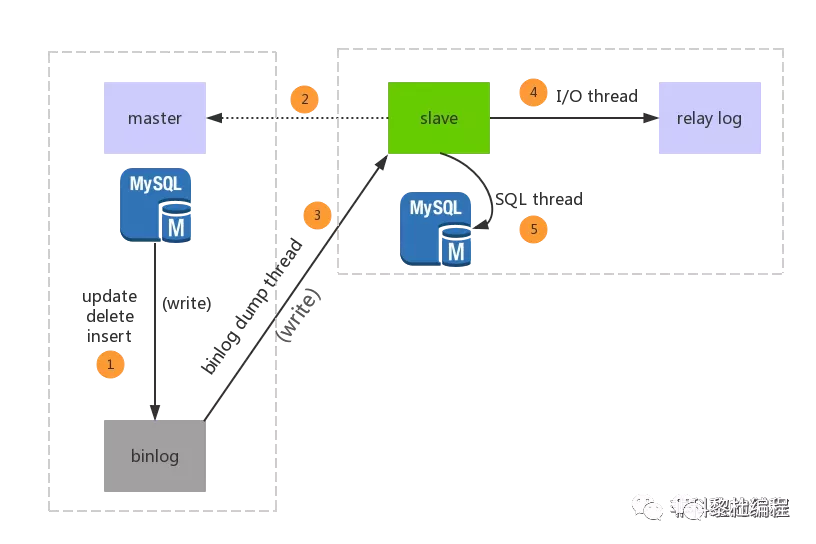
Mysql的主从复制中主要有三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread),Master一条线程和Slave中的两条线程。
master(binlog dump thread)主要负责Master库中有数据更新的时候,会按照binlog格式,将更新的事件类型写入到主库的binlog文件中。
并且,Master会创建log dump线程通知Slave主库中存在数据更新,这就是为什么主库的binlog日志一定要开启的原因。
I/O thread线程在Slave中创建,该线程用于请求Master,Master会返回binlog的名称以及当前数据更新的位置、binlog文件位置的副本。
然后,将binlog保存在 「relay log(中继日志)」 中,中继日志也是记录数据更新的信息。
SQL线程也是在Slave中创建的,当Slave检测到中继日志有更新,就会将更新的内容同步到Slave数据库中,这样就保证了主从的数据的同步。
以上就是主从复制的过程,当然,主从复制的过程有不同的策略方式进行数据的同步,主要包含以下几种:
1. 「全同步策略」:Master会等待所有的Slave都回应后才会提交,这个主从的同步会受到严重的影响。
2. 「半同步策略」:Master至少会等待一个Slave回应后提交。
3. 「异步策略」:Master不用等待Slave回应就可以提交。
4. 「延迟策略」:Slave要落后于Master指定的时间。
## slow_query_log
在mysql中有一个动态参数long_query_time表示慢查询的阈值,表示当执行的sql超过这个这个参数的时间,就数据慢查询的范围就会将此纪录存入该日志中,该值默认为10,通以下命令进行查看。

一般情况下是关闭的
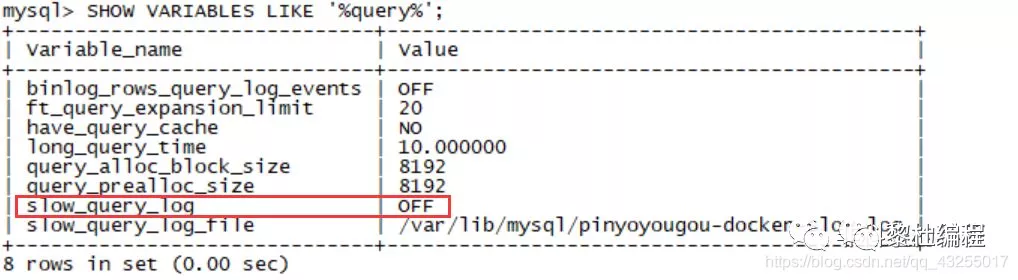
通过命令SET GLOBAL slow_query_log=ON将该功能开启
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期