
[TOC]
## InnoDB 引擎的 4 大特性,了解过吗?
* 插入缓存:对于为非唯一索引,辅助索引的修改操作并非实时更新索引的叶子页,而是把若干对同一页面的更新缓存起来做合并为一次性更新操作,转化随机IO 为顺序IO,这样可以避免随机IO带来性能损耗,提高数据库的写性能。
* 二次写:当页需要写回数据库时,首先把页备份到内存中的doublewrite buffer,然后每次1M,写入到共享表空间中,共享表空间也是在磁盘上,因为是顺序写,所以很快,然后再将这些页写入到真的数据文件中,就算这个时候服务器出了问题,也是可以用共享表空间中的数据进行还原的
* 自适应hash:当某个非聚集索引被等值查询的次数很多时,就会为这个非聚集索引再构造一个hash索引,hash索引对呀等值查询是很快的,这个hash索引会放在缓存中
* 磁盘预读:
## 一条查询语句发生了什么
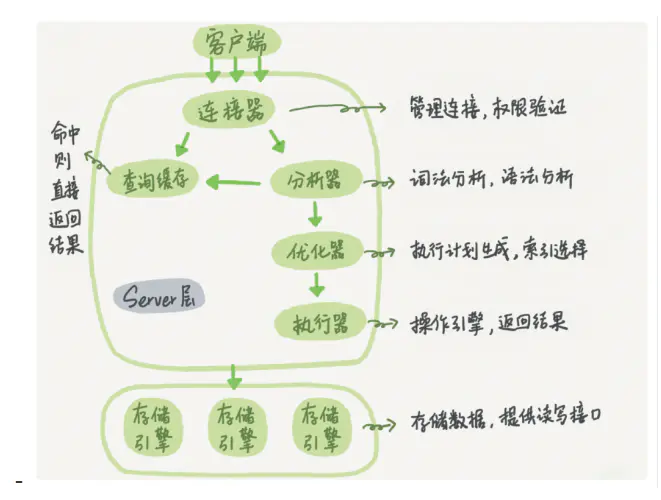
## 三大范式是什么?
* 第一范式:数据表中的每一列(每个字段)必须是不可拆分的最小单元,也就是确保每一列的原子性;
* 第二范式(2NF):满足1NF后,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系,也就是说一个表只描述一件事情;
* 第三范式:必须先满足第二范式(2NF),要求:表中的每一列只与主键直接相关而不是间接相关,(表中的每一列只能依赖于主键);
## 怎么区分三大范式?
第 一范式和第二范式在于有没有分出两张表,第二范式是说一张表中包含了所种不同的实体属性,那么要必须分成多张表, 第三范式是要求已经分成了多张表,那么一张表中只能有另一张表中的id(主键),而不能有其他的任何信息(其他的信息一律用主键在另一表查询)。
## 数据库五大约束是什么?
1.primary KEY:设置主键约束;
2.UNIQUE:设置唯一性约束,不能有重复值;
3.DEFAULT 默认值约束,height DOUBLE(3,2)DEFAULT 1.2 height不输入是默认为1,2
4.NOT NULL:设置非空约束,该字段不能为空;
5.FOREIGN key :设置外键约束。
## 主键是什么,怎么设置主键?
主键默认非空,默认唯一性约束,只有主键才能设置自动增长,自动增长一定是主键,主键不一定自动增长;
在定义列时设置:ID INT PRIMARY KEY
在列定义完之后设置:primary KEY(id)
## 数据库的外键是什么?
只有INNODB的数据库引擎支持外键。
不见已使用基于mysql的物理外键,这样可能会有超出预期的后果。推荐使用逻辑外键,就是自己做表设计,根据代码逻辑设定的外键,自行实现相关的数据操作。
## 主键索引和唯一索引的区别
1. 主键一定会创建一个唯一索引,但是有唯一索引的列不一定是主键;
2. 主键不允许为空值,唯一索引列允许空值;
3. 一个表只能有一个主键,但是可以有多个唯一索引;
4. 主键可以被其他表引用为外键,唯一索引列不可以;
5. 主键是一种约束,而唯一索引是一种索引,是表的冗余数据结构,两者有本质的差别
## innodb和myisam有什么区别?
* InnoDB支持事务,而MyISAM不支持事物,崩溃后无法安全恢复,表锁非常影响性能
* InnoDB支持行级锁,而MyISAM支持表级锁
* InnoDB支持MVCC,实现了四个标准的隔离级别 而MyISAM不支持
* InnoDB 表是基于聚族索引建立的,聚族索引对主键查询有很高的性能
* InnoDB支持外键,而MyISAM不支持
* MyISAM 存储引擎已经有了20年的历史,在1995年时,MyISAM 是 MySQL 唯一的存储引擎,服务了20多年,即将退居二线。随着mysql5.7,8版本的提升,myisam优点已经逐渐被 InnoDB 实现了。比如全文索引,表空间优化,临时表优化,高效的count(\*)
## btree和hash类型的索引有什么不同?
首先要知道Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据.B+树底层实现是多路平衡查找树.对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据.
那么可以看出他们有以下的不同:
* hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询.
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询.而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围.
* hash索引不支持使用索引进行排序,原理同上.
* hash索引不支持模糊查询以及多列索引的最左前缀匹配.原理也是因为hash函数的不可预测.**AAAA**和**AAAAB**的索引没有相关性.
* hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询.
* hash索引虽然在等值查询上较快,但是不稳定.性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差.而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低.
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度.而不需要使用hash索引.
## drop、delete与truncate分别在什么场景之下使用?
我们来对比一下他们的区别:
drop table
* 1)属于DDL
* 2)不可回滚
* 3)不可带where
* 4)表内容和结构删除
* 5)删除速度快
truncate table
* 1)属于DDL
* 2)不可回滚
* 3)不可带where
* 4)表内容删除
* 5)删除速度快
delete from
* 1)属于DML
* 2)可回滚
* 3)可带where
* 4)表结构在,表内容要看where执行的情况
* 5)删除速度慢,需要逐行删除
总结:
**不再需要一张表的时候,用drop**
**想删除部分数据行时候,用delete,并且带上where子句**
**保留表而删除所有数据的时候用truncate**
## MySQL中的varchar和char有什么区别?
1. char的长度是不可变的,而varchar的长度是可变的 。
2. 定义一个char\[10\]和varchar\[10\],如果存进去的是‘abcd’,那么char所占的长度依然为10,除了字符‘abcd’外,后面跟六个空格,而varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的,
3. char的存取速度比varchar要快得多,因为其长度固定,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率,而varchar是以空间效率为首位的。
4. char的存储方式是,对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节;而varchar的存储方式是,对每个英文字符占用2个字节,汉字也占用2个字节,两者的存储数据都非unicode的字符数据。
5. char适合存储长度固定的数据,varchar适合存储长度不固定的。
## varchar(10)和int(10)代表什么含义?
varchar的10代表了申请的空间长度,也是可以存储的数据的最大长度,而int的10只是代表了展示的长度,不足10位以0填充.也就是说,int(1)和int(10)所能存储的数字大小以及占用的空间都是相同的,只是在展示时按照长度展示.
## 超大分页怎么处理?
超大的分页一般从两个方向上来解决.
* 数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于`select * from table where age > 20 limit 1000000,10`这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为`select * from table where id in (select id from table where age > 20 limit 1000000,10)`.这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以`select * from table where id > 1000000 limit 10`,效率也是不错的,优化的可能性有许多种,但是核心思想都一样,就是减少load的数据.
* 从需求的角度减少这种请求....主要是不做类似的需求(直接跳转到几百万页之后的具体某一页.只允许逐页查看或者按照给定的路线走,这样可预测,可缓存)以及防止ID泄漏且连续被人恶意攻击.
解决超大分页,其实主要是靠缓存,可预测性的提前查到内容,缓存至redis等k-V数据库中,直接返回即可.
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期