
[TOC]
## mysql的锁了解么,如何分类?
可以从四个维度给锁分类,分别如下:
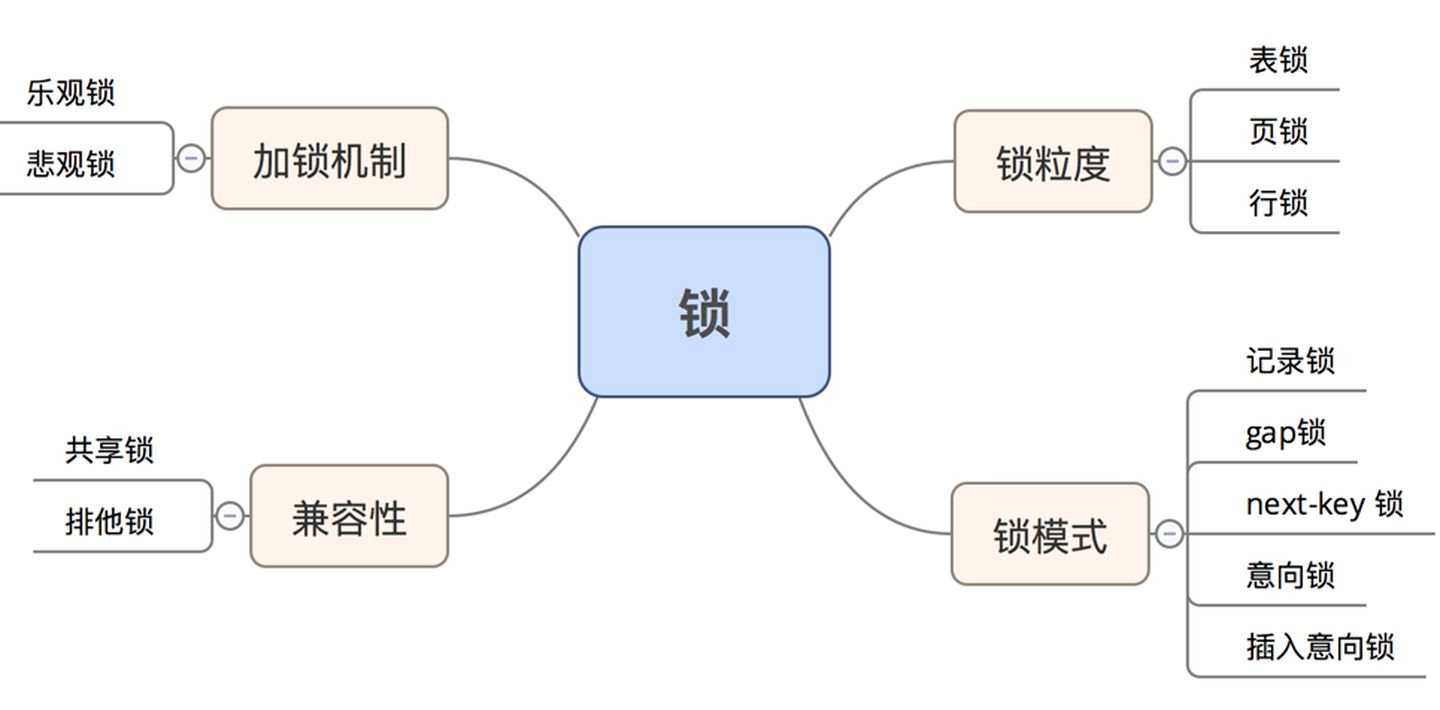
## 乐观锁和悲观锁是什么,如何实现?
1、乐观锁:先修改,保存时判断是够被更新过,应用级别,说白了就是自己写代码实现,是一种思想,可以基于版本号、更新时间戳可以实现,
2、悲观锁:先获取锁,再操作修改,数据库级别,比如sql后缀写 for update,是基于MySQL自带的功能。
## 锁的粒度有哪几种?
表级锁:开销小,加锁快,粒度大,锁冲突概率大,并发度低,适用于读多写少的情况。
页级锁:BDB存储引擎
行级锁:Innodb存储引擎,默认选项
注意,innoDB中行级锁是加在索引上的,因此只有命中索引的情况才会是行级锁,不然是表级锁,
## 锁的兼容性对比
* S锁:也叫做读锁、共享锁,对应于`select * from users where id =1 lock in share mode`
* X锁:也叫做写锁、排它锁、独占锁、互斥锁,对应于`select * from users where id =1 for update`
## 什么是mysql的锁机制
数据库为了保证数据的一致性而设计的面对并发场景的一种规则。最显著的特点是不同的存储引擎支持不同的锁机制,InnoDB支持行锁和表锁,MyISAM支持表锁。
1. 表锁就是把整张表锁起来,特点是加锁快,开销小,不会出现死锁,锁粒度大,发生锁冲突的概率高,并发相对较低。
2. 行锁就是以行为单位把数据锁起来,特点是加锁慢,开销大,会出现死锁,锁粒度小,发生锁冲突的概率低,并发度也相对表锁较高。
## 什么是死锁
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
## 死锁产生的原因
* 死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环
* 当事务试图以不同的顺序锁定资源时,就可能产生死锁。多个事务同时锁定同一个资源时也可能会产生死锁
* 锁的行为和顺序和存储引擎相关。以同样的顺序执行语句,有些存储引擎会产生死锁有些不会——死锁有双重原因:真正的数据冲突;存储引擎的实现方式。
## 怎么解决死锁
* 1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
* 2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
* 3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
* 4、 尽量按照索引去查数据,范围查找增加了锁冲突的可能性。
## InnoDB
InnoDB 实现了以下两种类型的行锁:
* 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。select ... lock in share mode;
* 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。select ... for update;
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是**表锁**:
* 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
* 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
**索引失效会导致行锁变表锁**
### InnoDB存储引擎的锁的算法有三种
* Record lock:单个行记录上的锁
* Gap lock:间隙锁,锁定一个范围,不包括记录本身
* Next-key lock:record+gap 锁定一个范围,包含记录本身
#### 相关知识点:
* innodb对于行的查询使用next-key lock
* Next-locking keying为了解决Phantom Problem幻读问题
* 当查询的索引含有唯一属性时,将next-key lock降级为record key
* Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
* 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
### 检测死锁
数据库系统实现了各种死锁检测和死锁超时的机制。InnoDB存储引擎能检测到死锁的循环依赖并立即返回一个错误。innodb_deadlock_detect 配置
### 死锁恢复
死锁发生以后,只有部分或完全回滚其中一个事务,才能打破死锁,InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚。所以事务型应用程序在设计时必须考虑如何处理死锁,多数情况下只需要重新执行因死锁回滚的事务即可。
### 外部锁的死锁检测
发生死锁后,InnoDB 一般都能自动检测到,并使一个事务释放锁并回退,另一个事务获得锁,继续完成事务。但在涉及外部锁,或涉及表锁的情况下,InnoDB 并不能完全自动检测到死锁, 这需要通过设置锁等待超时参数 innodb_lock_wait_timeout 来解决
### 死锁影响性能:
死锁会影响性能而不是会产生严重错误,因为InnoDB会自动检测死锁状况并回滚其中一个受影响的事务。在高并发系统上,当许多线程等待同一个锁时,死锁检测可能导致速度变慢。有时当发生死锁时,禁用死锁检测(使用`innodb_deadlock_detect`配置选项)可能会更有效,这时可以依赖`innodb_lock_wait_timeout`设置进行事务回滚。
### 死锁以及事务回滚的MYSQL的配置我们是怎么做的
1、innodb_deadlock_detect = off
2、innodb_lock_wait_timeout = 1
3、innodb_rollback_on_timeout = on
这样配置的MYSQL 后,
1 在高并发的时候, innodb_deadlock_detect 影响性能的隐患解除了
2 我们可以根据系统的特性来设置 innodb_lock_wait_timeout 来针对不同的需求
3 设置innodb_rollback_on_timeout 设置后,整体的事务的原子性得到了保证.
### InnoDB避免死锁:
* 为了在单个InnoDB表上执行多个并发写入操作时避免死锁,可以在事务开始时通过为预期要修改的每个元祖(行)使用`SELECT ... FOR UPDATE`语句来获取必要的锁,即使这些行的更改语句是在之后才执行的。
* 在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁、更新时再申请排他锁,因为这时候当用户再申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁
* 如果事务需要修改或锁定多个表,则应在每个事务中以相同的顺序使用加锁语句。在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会
* 通过SELECT ... LOCK IN SHARE MODE获取行的读锁后,如果当前事务再需要对该记录进行更新操作,则很有可能造成死锁。
* 改变事务隔离级别
如果出现死锁,可以用`show engine innodb status;`命令来确定最后一个死锁产生的原因。返回结果中包括死锁相关事务的详细信息,如引发死锁的 SQL 语句,事务已经获得的锁,正在等待什么锁,以及被回滚的事务等。据此可以分析死锁产生的原因和改进措施。
## MyISAM
MyISAM 的表锁有两种模式:
* 表共享读锁 (Table Read Lock):不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;
* 表独占写锁 (Table Write Lock):会阻塞其他用户对同一表的读和写操作;
MyISAM 表的读操作与写操作之间,以及写操作之间是串行的。当一个线程获得对一个表的写锁后, 只有持有锁的线程可以对表进行更新操作。其他线程的读、 写操作都会等待,直到锁被释放为止。
默认情况下,写锁比读锁具有更高的优先级:当一个锁释放时,这个锁会优先给写锁队列中等候的获取锁请求,然后再给读锁队列中等候的获取锁请求。
// 显式的添加表级读锁
LOCK TABLE 表名 READ
// 显示的添加表级写锁
LOCK TABLE 表名 WRITE
// 显式的解锁(当一个事务commit的时候也会自动解锁)
unlock tables;
### MyISAM避免死锁(不会出现死锁):
* 在自动加锁的情况下,MyISAM 总是一次获得 SQL 语句所需要的全部锁,所以 MyISAM 表不会出现死锁。
## 间隙锁
https://www.jianshu.com/p/32904ee07e56
https://zhuanlan.zhihu.com/p/48269420
## mysql 是怎么加锁的
https://mp.weixin.qq.com/s/8G-4V9-CC_lUblpvbo5Lkw
##### 其他
https://zhuanlan.zhihu.com/p/31875702
https://blog.csdn.net/qq\_38238296/article/details/88362999
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期