
[TOC]
## redis的使用场景
(1)缓存
毫无疑问这是Redis当今最为人熟知的使用场景。再提升服务器性能方面非常有效;
一些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis 是放在内存中的可以很高效的访问。
(2)排行榜
在使用传统的关系型数据库(mysql oracle 等)来做这个事儿,非常的麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单的搞定;
(3)计算器/限速器
Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
(4)好友关系
利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能。
(5)简单消息队列
除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
(6)Session共享
以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
(7)分布式锁
分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
链接地址:https://mp.weixin.qq.com/s/r9_0xpRsp2ubgyvpiyMfuw
## String
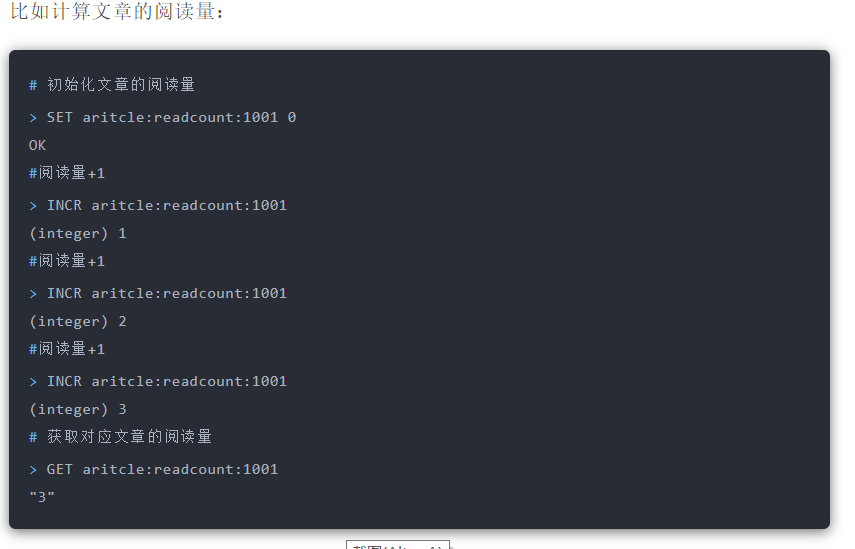
### 常规计数
### 分布式锁
SET lock\_key unique\_value NX PX 10000
还是不安全
## List
### 常用命令

### 应用场景
#### 消息队列
List 可以使用 LPUSH + RPOP (或者反过来,RPUSH+LPOP)命令实现消息队列。
* 生产者使用`LPUSH key value[value...]`将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。
* 消费者使用`RPOP key`依次读取队列的消息,先进先出。
建议使用BRPOP ,**BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据**。和消费者程序自己不停地调用RPOP命令相比,这种方式能节省CPU开销。
* 消息保序:使用 LPUSH + RPOP;
* 阻塞读取:使用 BRPOP;
* 重复消息处理:生产者自行实现全局唯一 ID;(eg:LPUSH mq "111000102:stock:99")
* 消息的可靠性:使用 BRPOPLPUSH(读出来之后放到另一个list,作为备份)
缺点:不能多消费者,在redis5.0 之后增加了stream ,可以使用消费者组,进行消费
## Hash
### 常用命令

### 应用场景
#### 缓存对象
1、hset key feild value,可以单独取出key的某项信息去操作

#### 购物车
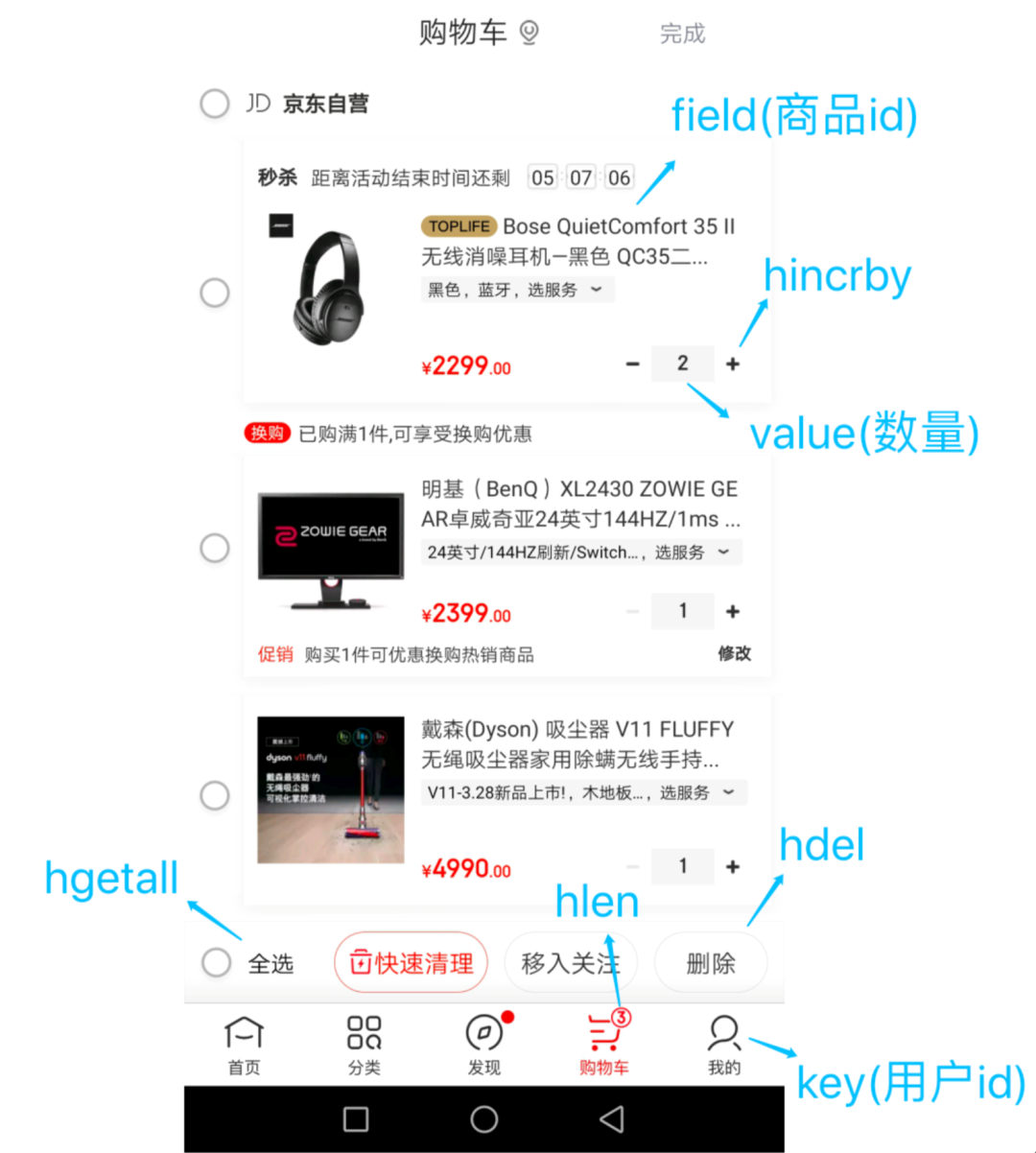
涉及的命令如下:
* 添加商品:`HSET cart:{用户id} {商品id} 1`
* 添加数量:`HINCRBY cart:{用户id} {商品id} 1`
* 商品总数:`HLEN cart:{用户id}`
* 删除商品:`HDEL cart:{用户id} {商品id}`
* 获取购物车所有商品:`HGETALL cart:{用户id}`
当前仅仅是将商品ID存储到了Redis 中,在回显商品具体信息的时候,还需要拿着商品 id 查询一次数据库,获取完整的商品的信息。
## Set
### 常用命令
Set常用操作:

Set运算操作:
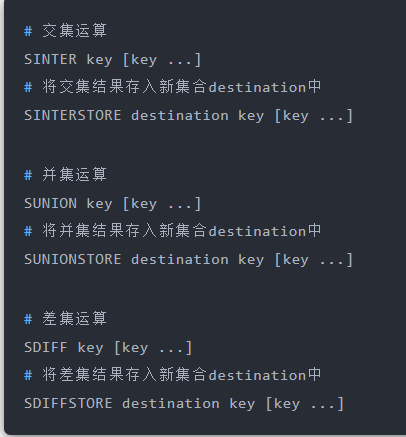
### 应用场景
集合的主要几个特性,无序、不可重复、支持并交差等操作。
**Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞**。
#### 点赞
```
//uid:1 用户对文章 article:1 点赞
SADD article:1 uid:1
//uid:1`取消了对 article:1 文章点赞。
SREM article:1 uid:1
//获取 article:1 文章所有点赞用户
SMEMBERS article:1
//获取 article:1 文章的点赞用户数量:
SCARD article:1
//判断用户`uid:1`是否对文章 article:1 点赞了:
SISMEMBER article:1 uid:1
```
#### 关注
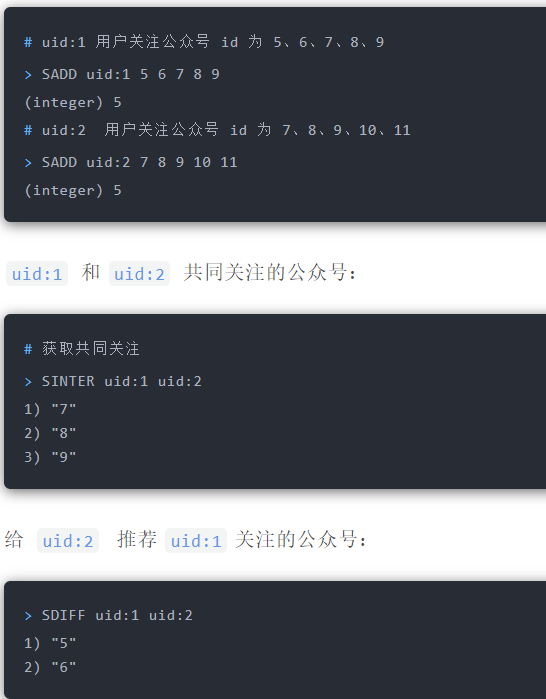
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
key 可以是用户id,value 则是已关注的公众号的id。
`uid:1`用户关注公众号 id 为 5、6、7、8、9,`uid:2` 用户关注公众号 id 为 7、8、9、10、11。
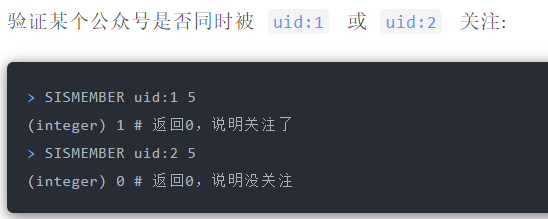
#### 抽奖
key为抽奖活动名,value为员工名称,把所有员工名称放入抽奖箱 :
~~~
SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
~~~
如果允许重复中奖,可以使用 SRANDMEMBER 命令

如果不允许重复中奖,可以使用 SPOP 命令。

## Zset
### 常用命令
Zset 常用操作:

Zset 运算操作(相比于 Set 类型,ZSet 类型没有支持差集运算):

### 应用场景
#### 排行榜
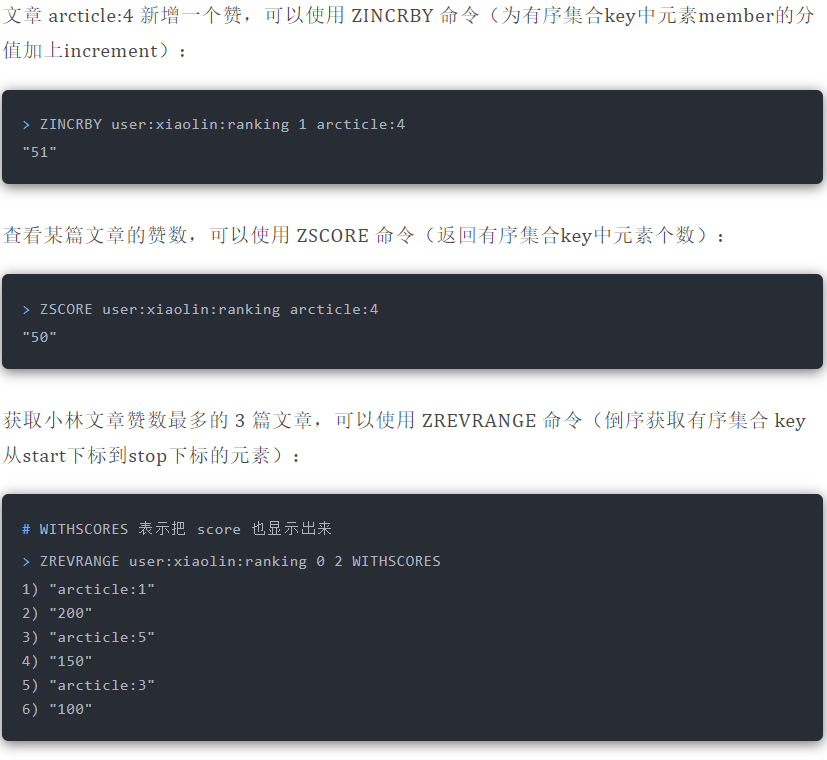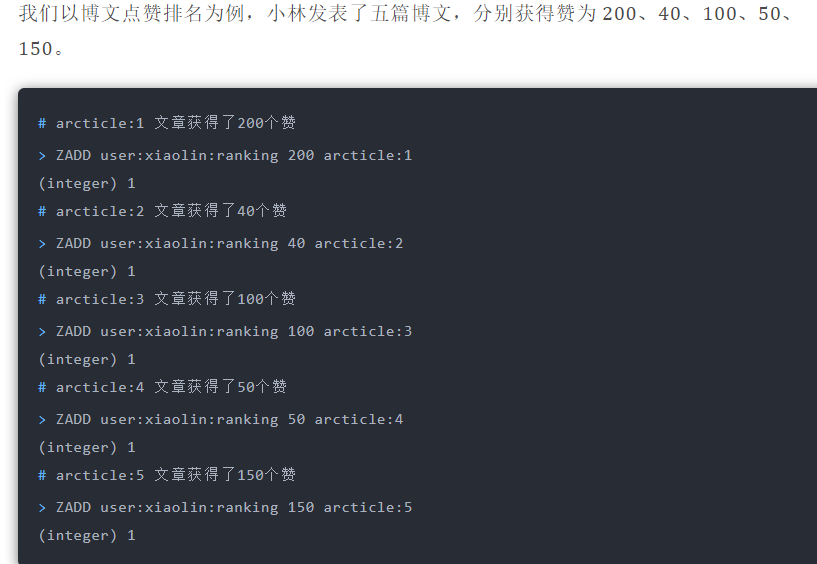
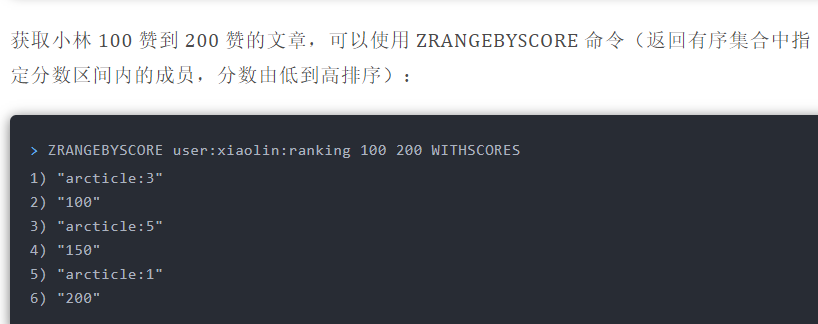
#### 电话、姓名排序
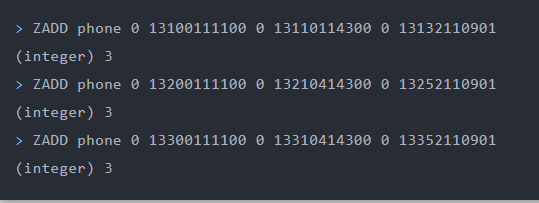
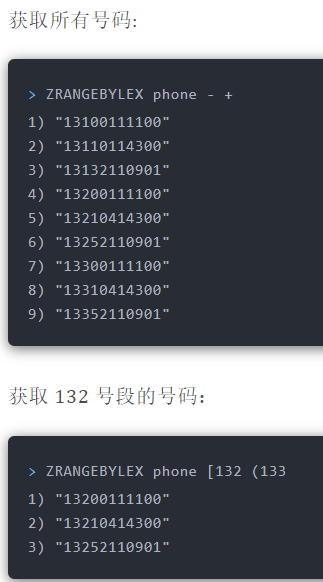
使用有序集合的`ZRANGEBYLEX`或`ZREVRANGEBYLEX`可以帮助我们实现电话号码或姓名的排序,我们以`ZRANGEBYLEX`(返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
**注意:不要在分数不一致的 SortSet 集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确。**
##### 电话排序
##### 姓名排序


## Bitmap
### 简介
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行`0|1`的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用**二值统计的场景**。

### 内部实现
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组。
### 常用命令
bitmap 基本操作:

bitmap 运算操作:

### 应用场景
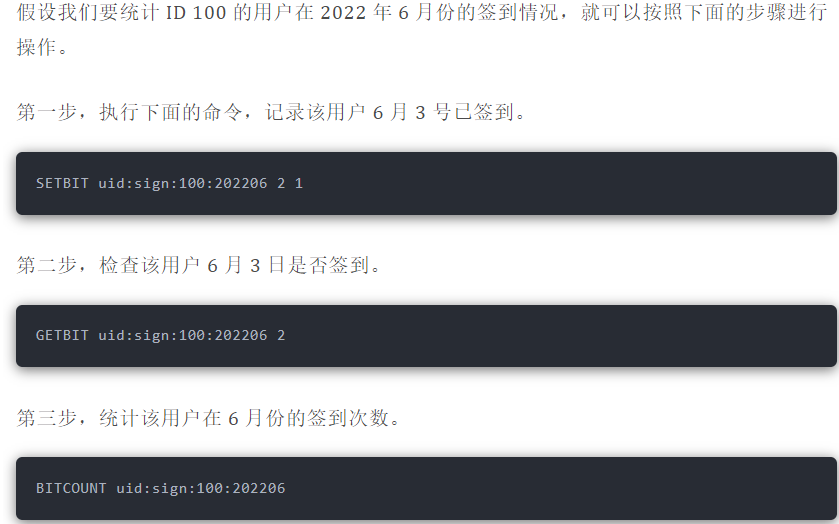
#### 签到统计
签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
#### 判断用户登陆态
Bitmap 提供了`GETBIT、SETBIT`操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
只需要一个 key = login\_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过`GETBIT`判断对应的用户是否在线。50000 万 用户只需要 6 MB 的空间。

#### 连续签到用户总数
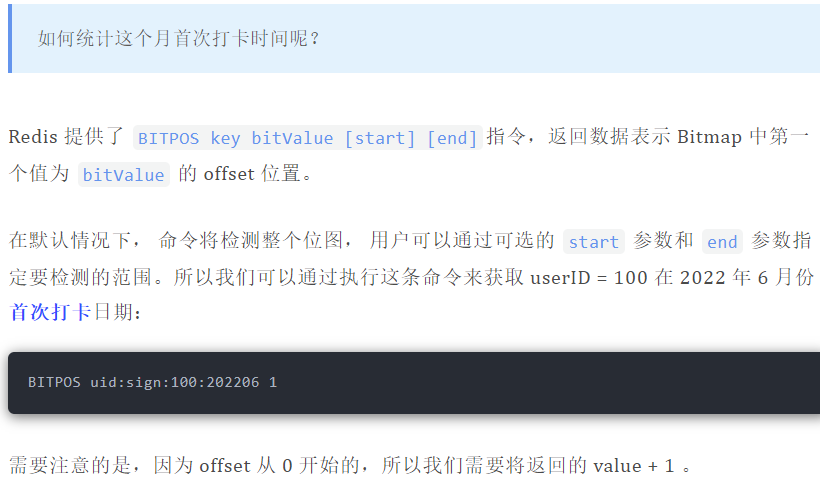
如何统计出这连续 7 天连续打卡用户总数呢?
我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。
key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。
一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。
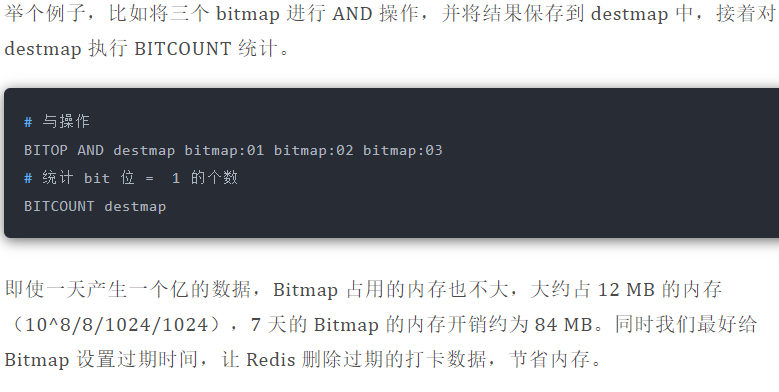
结果保存到一个新 Bitmap 中,我们再通过`BITCOUNT`统计 bit = 1 的个数便得到了连续打卡 3 天的用户总数了。
Redis 提供了`BITOP operation destkey key [key ...]`这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
* `opration`可以是`and`、`OR`、`NOT`、`XOR`。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作`0`。空的`key`也被看作是包含`0`的字符串序列。
## HyperLogLog
### 简介
Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「统计基数」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。
所以,简单来说 HyperLogLog**提供不精确的去重计数**。
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。
在 Redis 里面,**每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近`2^64`个不同元素的基数**,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
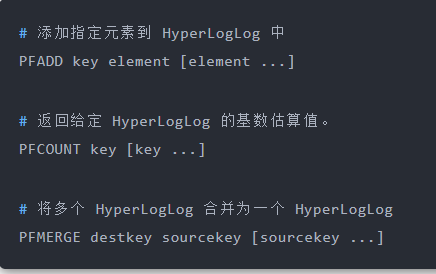
### 常用命令
### 应用场景
#### 百万级网页 UV 计数
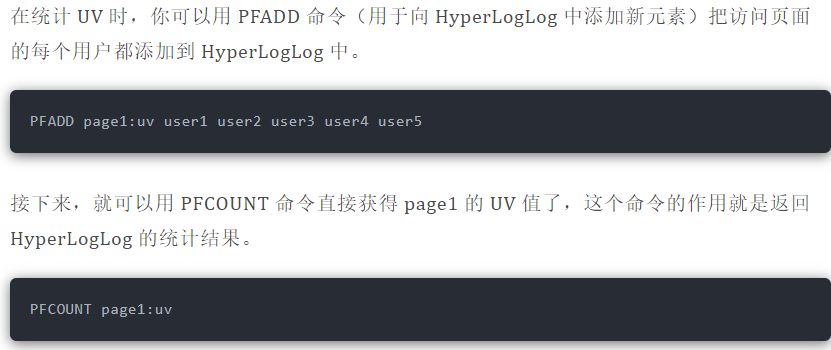
HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。
这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
## Geo
### 简介
GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。
GEO 类型使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。
这样一来,我们就可以把经纬度保存到 Sorted Set 中,利用 Sorted Set 提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求。
### 常用命令
```
# 存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
GEOADD key longitude latitude member [longitude latitude member ...]
# 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。
GEOPOS key member [member ...]
# 返回两个给定位置之间的距离。
GEODIST key member1 member2 [m|km|ft|mi]
# 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
```
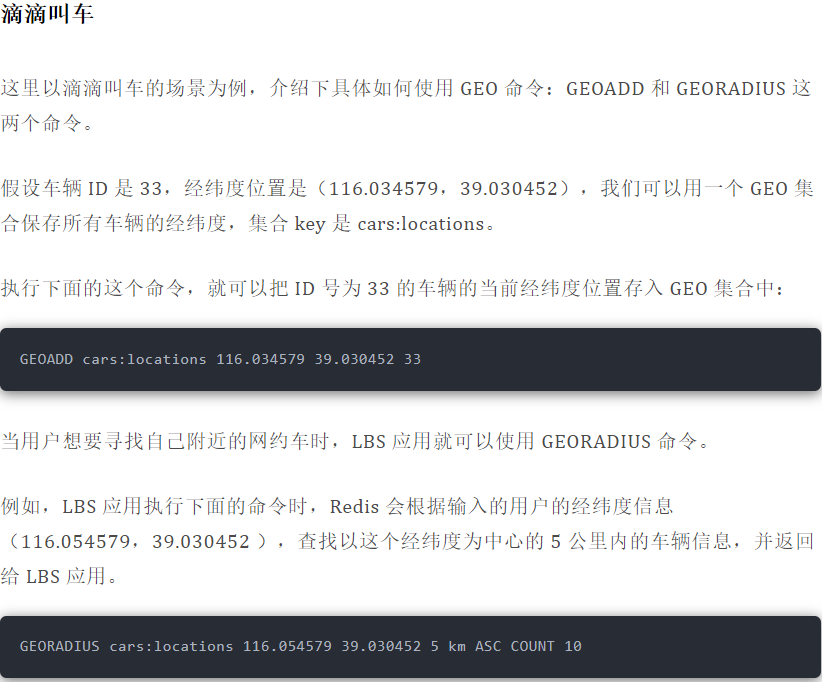
### 应用场景
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期