
[TOC]
## 数据结构
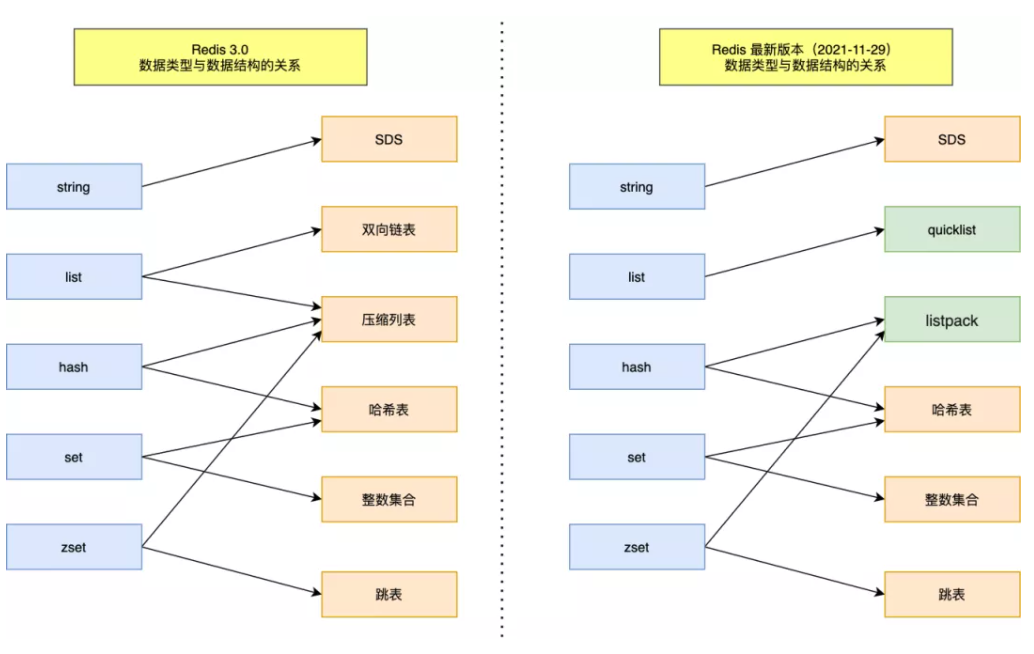
> 数据结构新旧共 9 种,**SDS、双向链表、压缩列表、哈希表、跳表、整数集合、quicklist、listpack。**
### 键值对数据库是怎么实现的?
* set name "cccc"
* hset people name "cccc"
1、name是字符串的key,值是 字符串
2、people是哈希的key,值是 键值对的哈希表对象
#### 键值对是如何保存在 Redis 中的呢?
Redis 是使用了一个「哈希表」保存所有键值对,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。
#### Redis 的哈希桶是怎么保存键值对数据的呢?
哈希桶存放的是指向键值对数据的指针(dictEntry\*),这样通过指针就能找到键值对数据,然后因为键值对的值可以保存字符串对象和集合数据类型的对象,所以键值对的数据结构中并不是直接保存值本身,而是保存了 void \* key 和 void \* value 指针,分别指向了实际的键对象和值对象,这样一来,即使值是集合数据,也可以通过 void \* value 指针找到。
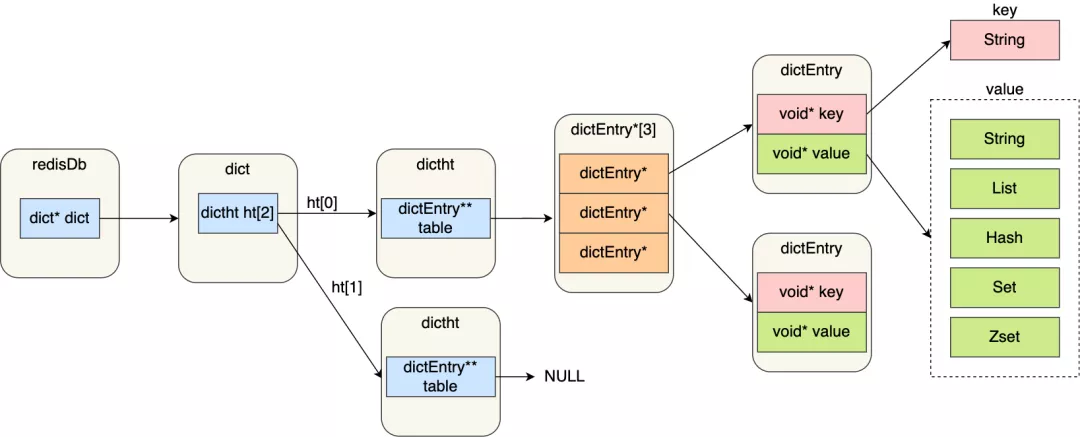
图中涉及到的数据结构的名字和用途:
* redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向了 dict 结构的指针;
* dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用「哈希表1」,「哈希表2」只有在 rehash 的时候才用,具体什么是 rehash,我在本文的哈希表数据结构会讲;
* ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
* dictEntry 结构,表示哈希表节点的结构,结构里存放了**void * key 和 void * value 指针, *key 指向的是 String 对象,而 *value 则可以指向 String 对象,也可以指向集合类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象**。
void * key 和 void * value 指针指向的是**Redis 对象**,Redis 中的每个对象都由 redisObject 结构表示,如下图:
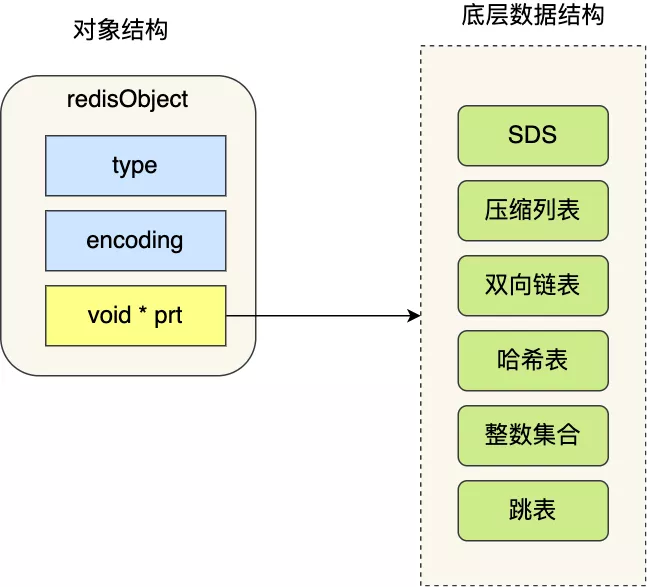
对象结构里包含的成员变量:
* type,标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象);
* encoding,标识该对象使用了哪种底层的数据结构;
* **ptr,指向底层数据结构的指针**
Redis 对象和数据结构的关系:

### SDS
#### 为什么没有用C语言的原始的*char结构
* 获取字符串长度的时间复杂度为 O(N);
* 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符因此不能保存二进制数据;
> eg:
str = 'xiaodingdang' len= 12
str= 'xiao\0dingdang' len= 4
* 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止;
#### redis5.0的SDS 数据结构

* **len,记录了字符串长度**。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
* **alloc,分配给字符数组的空间长度**。这样在修改字符串的时候,可以通过`alloc - len`计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。
* **flags,用来表示不同类型的 SDS**。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64
* **buf[],字符数组,用来保存实际数据**。不仅可以保存字符串,也可以保存二进制数据。
** 通过len、allock、flags解决了C的缺陷
>1、O(1)复杂度获取字符串长度
2、二进制安全,不再需要“\0”字符来标识字符串结尾了,长度由len直接返回,然后buf[]存储的数据没有任何限制,写入和读取的是一样的,而且也能保存二进制数据
3、不会发生缓冲区溢出,因为引入了 alloc 和 len 成员变量,在计算剩余空间时,通过`alloc - len`计算,**当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容)**,为了**有效的减少内存分配次数**,在检查空间是否够用时,除了分配修改所必须要的空间,还会给 SDS 分配额外的「未使用空间」
4、节省内存空间,不再内存对齐
### 链表
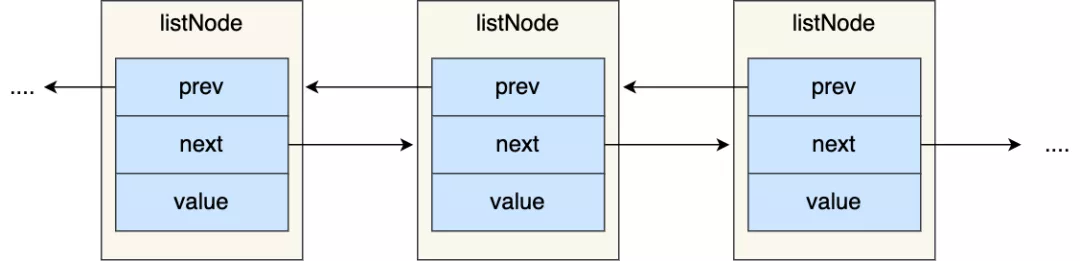
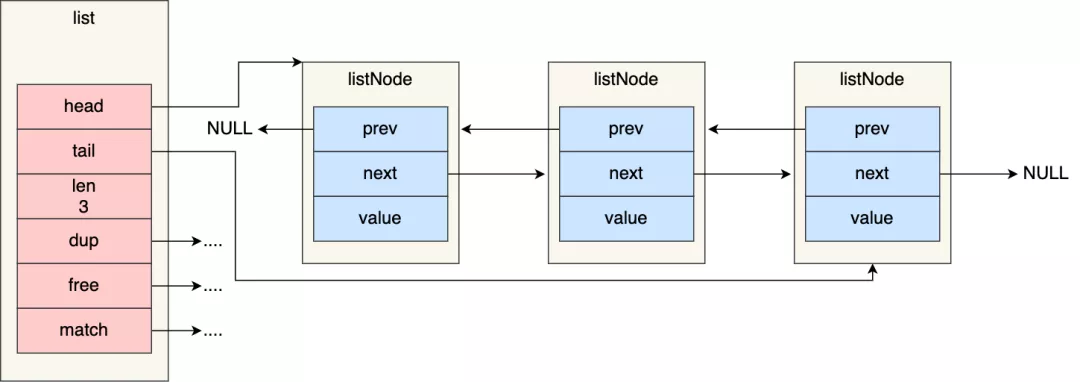
#### 链表节点结构设计
~~~
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
~~~
有前置和后置节点,
#### 链表结构设计
Redis 在 listNode 结构体基础上又封装了 list 这个数据结构,这样操作起来会更方便,链表结构如下:
~~~
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsignedlong len;
} list;
~~~
list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
#### 链表的优势与缺陷
Redis 的链表实现优点如下:
* listNode 链表节点的结构里带有 prev 和 next 指针,**获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表**;
* list 结构因为提供了表头指针 head 和表尾节点 tail,所以**获取链表的表头节点和表尾节点的时间复杂度只需O(1)**;
* list 结构因为提供了链表节点数量 len,所以**获取链表中的节点数量的时间复杂度只需O(1)**;
* listNode 链表节使用 void\* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此**链表节点可以保存各种不同类型的值**;
链表的缺陷也是有的:
* 链表每个节点之间的内存都是不连续的,意味着**无法很好利用 CPU 缓存**。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
* 即使保存一个链表节点的值都需要一个链表节点结构头的分配,**内存开销较大**。
因此,Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
### 压缩列表
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
#### 压缩列表结构设计
压缩列表是 Redis 为了节约内存而开发的,它是**由连续内存块组成的顺序型数据结构**,有点类似于数组。

压缩列表在表头有三个字段:
* ***zlbytes***,记录整个压缩列表占用对内存字节数;
* ***zltail***,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
* ***zllen***,记录压缩列表包含的节点数量;
* ***zlend***,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而**查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素**。
#### 压缩列表节点(entry)的构成如下:
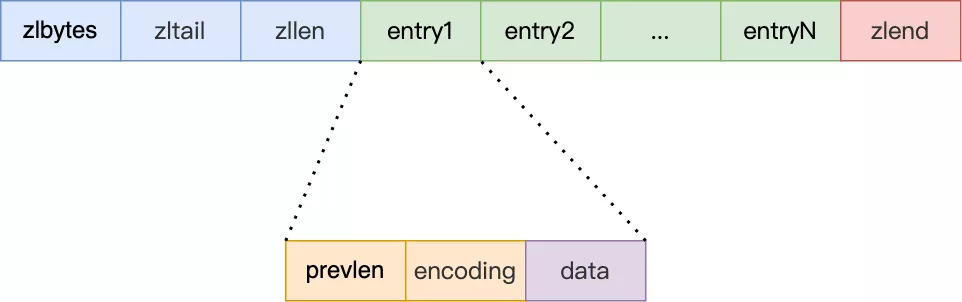
压缩列表节点包含三部分内容:
* ***prevlen***,记录了「前一个节点」的长度;
* ***encoding***,记录了当前节点实际数据的类型以及长度;
* ***data***,记录了当前节点的实际数据;
往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,**这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的**。
>prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」
prevlen 属性的空间大小跟前一个节点长度值有关,
>* 如果**前一个节点的长度小于 254 字节**,那么 prevlen 属性需要用**1 字节的空间**来保存这个长度值;
>* 如果**前一个节点的长度大于等于 254 字节**,那么 prevlen 属性需要用**5 字节的空间**来保存这个长度值;
encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关:
>* 如果**当前节点的数据是整数**,则 encoding 会使用**1 字节的空间**进行编码。
>* 如果**当前节点的数据是字符串,根据字符串的长度大小**,encoding 会使用**1 字节/2字节/5字节的空间**进行编码。
#### 压缩列表的缺陷:
* 不能保存过多的元素,否则查询效率就会降低;
* 新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发**连锁更新**的问题。
因此,Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
#### 连锁更新
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
### quicklist
quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
为了解决【连锁更新】,**通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。**
#### quicklist 结构设计
~~~
typedef struct quicklist {
//quicklist的链表头
quicklistNode *head;
//quicklist的链表尾
quicklistNode *tail;
//所有压缩列表中的总元素个数
unsignedlong count;
//quicklistNodes的个数
unsignedlong len;
...
} quicklist;
~~~
quicklistNode 的结构定义:
~~~
typedef struct quicklistNode {
//前一个quicklistNode
struct quicklistNode *prev;
//下一个quicklistNode
struct quicklistNode *next;
//quicklistNode指向的压缩列表
unsignedchar *zl;
//压缩列表的的字节大小
unsignedint sz;
//压缩列表的元素个数
unsignedint count : 16; //ziplist中的元素个数
....
} quicklistNode;
~~~
可以看到,quicklistNode 结构体里包含了前一个节点和下一个节点指针,这样每个 quicklistNode 形成了一个双向链表。但是链表节点的元素不再是单纯保存元素值,而是保存了一个压缩列表,所以 quicklistNode 结构体里有个指向压缩列表的指针 *zl。
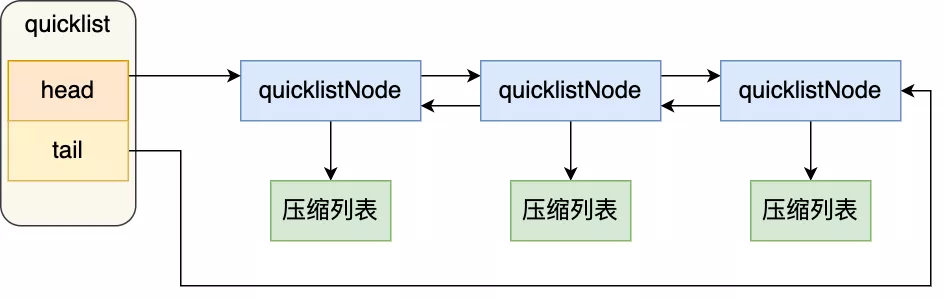
在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。
### 哈希表
#### 简介
哈希表优点在于,它**能以 O(1) 的复杂度快速查询数据**(将 key 通过 Hash 函数的计算,就能定位数据在表中的位置,因为哈希表实际上是数组,所以可以通过索引值快速查询到数据。)
但是存在的风险也是有,在哈希表大小固定的情况下,随着数据不断增多,那么**哈希冲突**的可能性也会越高。
>解决哈希冲突的方式,有很多种。
**Redis 采用了「链式哈希」来解决哈希冲突**,在不扩容哈希表的前提下,将具有相同哈希值的数据串起来,形成链接起,以便这些数据在表中仍然可以被查询到。
#### 哈希表结构设计
哈希表结构如下:
~~~
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsignedlong size;
//哈希表大小掩码,用于计算索引值
unsignedlong sizemask;
//该哈希表已有的节点数量
unsignedlong used;
} dictht;
~~~
哈希表是一个数组(dictEntry \*\*table),数组的每个元素是一个指向「哈希表节点(dictEntry)」的指针
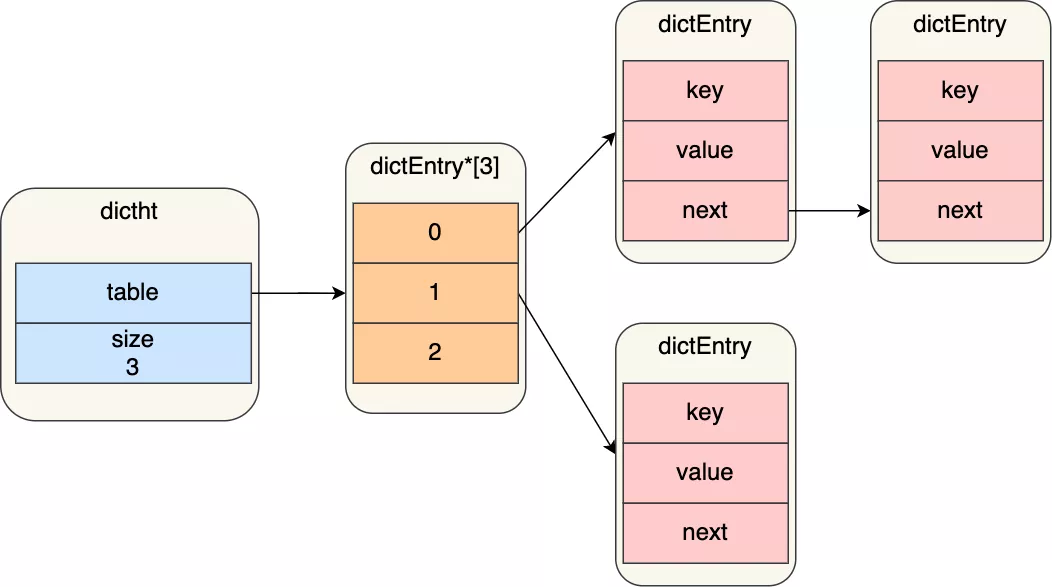
哈希表节点的结构如下:
~~~
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
~~~
dictEntry 结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。
dictEntry 结构里键值对中的值是一个「联合体 v」定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。
#### 哈希冲突
**当有两个以上数量的 key 被分配到了哈希表中同一个哈希桶上时,此时称这些 key 发生了冲突。**
#### 链式哈希
Redis 采用了「**链式哈希**」的方法来解决哈希冲突。
>链式哈希是怎么实现的?
每个哈希表节点都有一个 next 指针,用于指向下一个哈希表节点,因此多个哈希表节点可以用 next 指针构成一个单项链表,**被分配到同一个哈希桶上的多个节点可以用这个单项链表连接起来**,这样就解决了哈希冲突。
链式哈希局限性也很明显,随着链表长度的增加,在查询这一位置上的数据的耗时就会增加,因为链表的查询的时间复杂度是 O(n)。要想解决这一问题,就需要进行 rehash,也就是对哈希表的大小进行扩展。
#### rehash
dict 结构体,定义了两个哈希表
~~~
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;
~~~
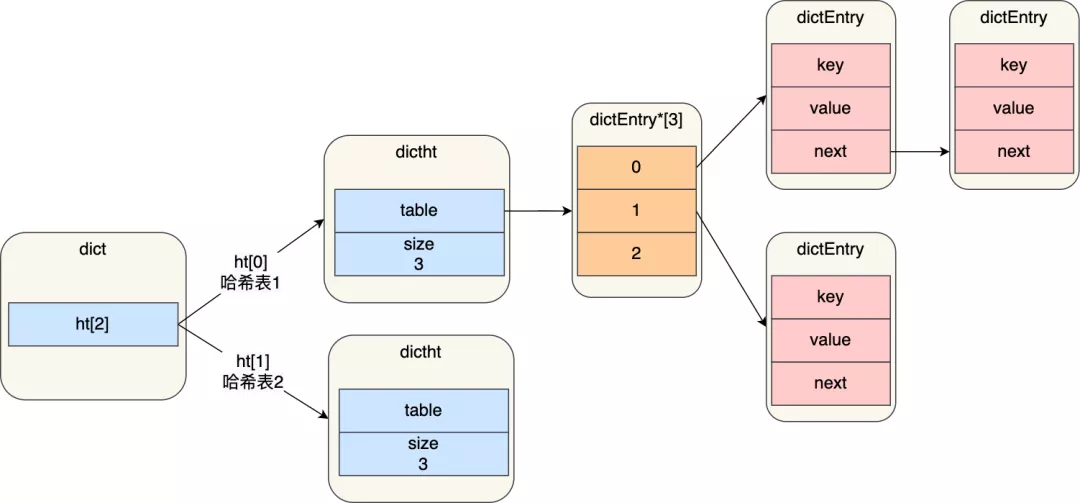
在正常服务请求阶段,插入的数据,都会写入到「哈希表 1」,此时的「哈希表 2 」 并没有被分配空间。
随着数据逐步增多,触发了 rehash 操作,这个过程分为三步:
* 给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍;
* 将「哈希表 1 」的数据迁移到「哈希表 2」 中;
* 迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。
**如果「哈希表 1 」的数据量非常大,那么在迁移至「哈希表 2 」的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求**。
#### 渐进式 rehash
渐进式 rehash 步骤如下:
* 给「哈希表 2」 分配空间;
* **在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上**;
* 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点,会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。
>在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。新增的key-value都会保存到「哈希表 2」,这样「哈希表 1」就会越来越少,直至为空
#### rehash 触发条件
rehash 的触发条件跟**负载因子(load factor)**有关系。
计算公式:

触发 rehash 操作的条件,主要有两个:
* **当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。**
* **当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。**
### 整数集合
>当一个 Set 对象只包含整数值元素,并且元素数量不多时,就会使用整数集这个数据结构作为底层实现
#### 整数集合结构设计
整数集合本质上是一块连续内存空间,它的结构定义如下:
~~~
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
~~~
contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
* 如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
* 如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
* 如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
不同类型的 contents 数组,意味着数组的大小也会不同。
#### 整数集合的升级操作
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
eg:
往这个整数集合中加入一个新元素 65535,这个新元素需要用 int32\_t 类型来保存,所以整数集合要进行升级操作,首先需要为 contents 数组扩容,**在原本空间的大小之上再扩容多 80 位(4x32-3x16=80),这样就能保存下 4 个类型为 int32_t 的元素**。

扩容完 contents 数组空间大小后,需要将之前的三个元素转换为 int32\_t 类型,并将转换后的元素放置到正确的位上面,并且需要维持底层数组的有序性不变,整个转换过程如下:
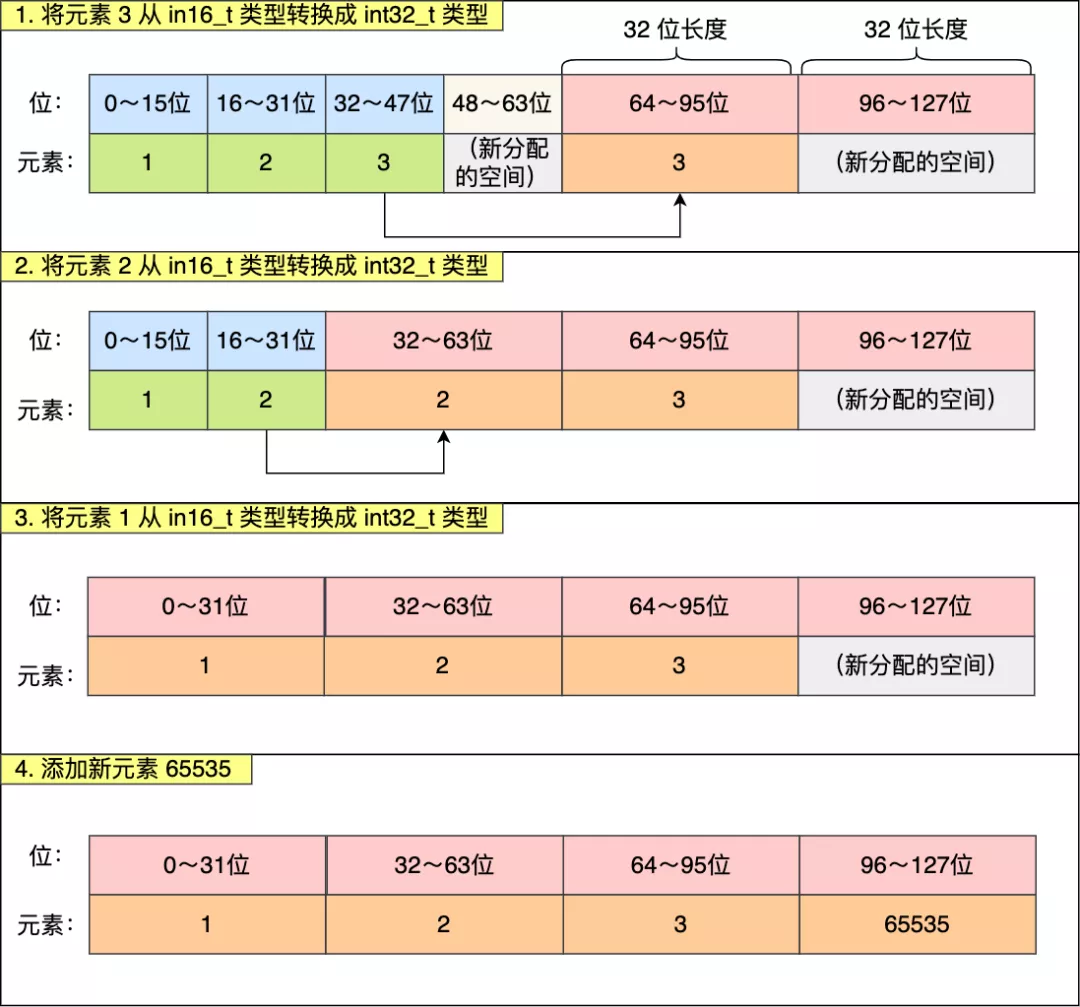
#### 整数集合升级有什么好处呢?
避免资源浪费,**节省内存资源**,如果一直向整数集合添加 int16_t 类型的元素,那么整数集合的底层实现就一直是用 int16_t 类型的数组,只有在我们要将 int32_t 类型或 int64_t 类型的元素添加到集合时,才会对数组进行升级操作。
**不支持降级操作**
### 跳表
跳表的优势是能支持平均 O(logN) 复杂度的节点查找。采用了两种数据结构,一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
https://blog.csdn.net/weixin_41622183/article/details/91126155 跳表
「跳表」结构体了,如下所示:
~~~
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
~~~
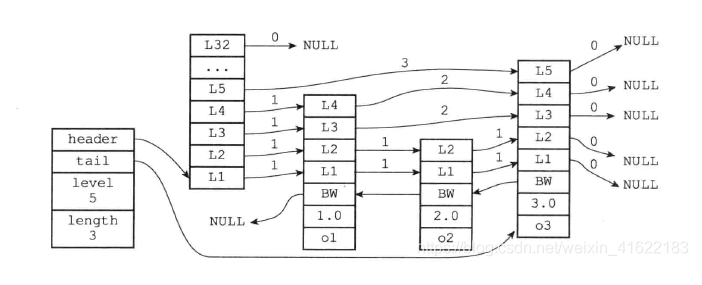
跳表结构里包含了:
* 跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
* 跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
* 跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
zset 对象:
~~~
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
~~~
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
#### 跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。**跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表**,这样的好处是能快读定位数据。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度就是 O(logN)。
那跳表节点是怎么实现多层级的呢?这就需要看「跳表节点」的数据结构了,如下:
~~~
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsignedlong span;
} level[];
} zskiplistNode;
~~~
Zset 对象要同时保存元素和元素的权重,对应到跳表节点结构里就是 sds 类型的 ele 变量和 double 类型的 score 变量。每个跳表节点都有一个后向指针,指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,这样倒序查找时很方便。
跳表是一个带有层级关系的链表,而且每一层级可以包含多个节点,每一个节点通过指针连接起来,实现这一特性就是靠跳表节点结构体中的**zskiplistLevel 结构体类型的 level 数组**。
level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve\[0\] 就表示第一层,leve\[1\] 就表示第二层。zskiplistLevel 结构体里定义了「指向下一个跳表节点的指针」和「跨度」,跨度时用来记录两个节点之间的距离。
比如,下面这张图,展示了各个节点的跨度。

第一眼看到跨度的时候,以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针就可以完成了。
**跨度实际上是为了计算这个节点在跳表中的排位**。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L2),并且层的跨度是 3,所以节点 3 在跳表中的排位是 3。
另外,图中的头节点其实也是 zskiplistNode 跳表节点,只不过头节点的后向指针、权重、元素值都会被用到,所以图中省略了这部分。
#### 跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
* 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
* 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
* 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
* 但是该层上的下一个节点是空节点,于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve\[1\];
* 「元素:abc,权重:3」节点的 leve\[1\] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve\[0\];
* 「元素:abc,权重:3」节点的 leve\[0\] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
#### 跳表节点层数设置
跳表的相邻两层的节点数量的比例会影响跳表的查询性能。
举个例子,下图的跳表,第二层的节点数量只有 1 个,而第一层的节点数量有 7 个。

这时,如果想要查询节点 6,那基本就跟链表的查询复杂度一样,就需要在第一层的节点中依次顺序查找,复杂度就是 O(N) 了。所以,为了降低查询复杂度,我们就需要维持相邻层结点数间的关系。
**跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)**。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。

> 那怎样才能维持相邻两层的节点数量的比例为 2 : 1 呢?
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。
Redis 则采用一种巧妙的方法是,**跳表在创建节点的时候,随机生成每个节点的层数**,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,**跳表在创建节点时候,会生成范围为\[0-1\]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数**。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
### listpack
它最大特点是每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
#### listpack 结构设计
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。

listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点。

主要包含三个方面内容:
* encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
* data,实际存放的数据;
* len,encoding+data的总长度;
可以看到,**listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题**。
## 类型、编码转换、数据结构
| 类型 | 数据结构 | 编码转换 |
| --- | --- | --- |
| String | SDS 动态字符串 | **int**(保存的是可以用long类型表示的整数值)、**raw**(保存长度大于44字节的字符串)、**embstr**( 保存长度小于44字节的字符串) |
| List | linkedList(双端链表) zipList(压缩链表) | zipList(列表保存元素个数小于512个、每个元素长度小于64字节) 不能满足上面两个条件使用linkedlist(双端列表)编码 |
| Hash | hashtable zipList |当同时满足下面两个条件使用ziplist编码,否则使用hashtable编码 **1.列表保存元素个数小于512个 2.每个元素长度小于64字节** |
| Set | intset(整型数组) hashtable | 当集合满足下列两个条件时,使用intset编码,否则使用hashtable **1. 集合对象中的所有元素都是整数 2.集合对象所有元素数量不超过512** |
| Sort Set | zipList、skipList | 同时满足下面两个条件时使用zipList,否则用skipList:**1.列表保存元素个数小于512个 2. 每个元素长度小于64字节** |
## Redis 的对象 **redisObject**
redisobject最主要的信息:
~~~
redisobject源码
typedef struct redisObject{
//类型 代表一个value对象具体是何种数据类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
~~~
## 处理命令的过程
当执行一个处理数据类型的命令时,Redis执行以下步骤:
* 根据给定`key`,在数据库字典中查找和它相对应的`redisObject`,如果没找到,就返回`NULL`。
* 检查`redisObject`的`type`属性和执行命令所需的类型是否相符,如果不相符,返回类型错误。
* 根据`redisObject`的`encoding`属性所指定的编码,选择合适的操作函数来处理底层的数据结构。
* 返回数据结构的操作结果作为命令的返回值。
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期