
索引:
https://mp.weixin.qq.com/s/NDktOXaObJYQ1dM49oi9HA
面试题:
https://mp.weixin.qq.com/s/aiD91w3ez48o-SiOAOSK-A
# MySQL 数据库面试题
https://mp.weixin.qq.com/s/8uMUu5vqPShVv4LatCD5qg
[TOC]
## 各种树的形式?
1、二叉树

**特点:**
* 所有的非叶子节点最多拥有两个子节点树(左子树和右子树)。
* 所有结点存储一个关键字。
* 节点的左右儿子,左边是比该节点小的,右边是比该节点大的。
**缺点:**
因为二叉搜索树不存在平衡算法,所以在某些特殊的情况下,二叉搜索树等同于线性。
红黑树和AVL树是在二叉树的基础上机上加上平衡算法,红黑树确保没有一条路径会比其它路径长出两倍,它是弱平衡树而AVL是严格的平衡,所以相对于二叉树的蹩脚情况做了很大的改进,加入了平衡算法:
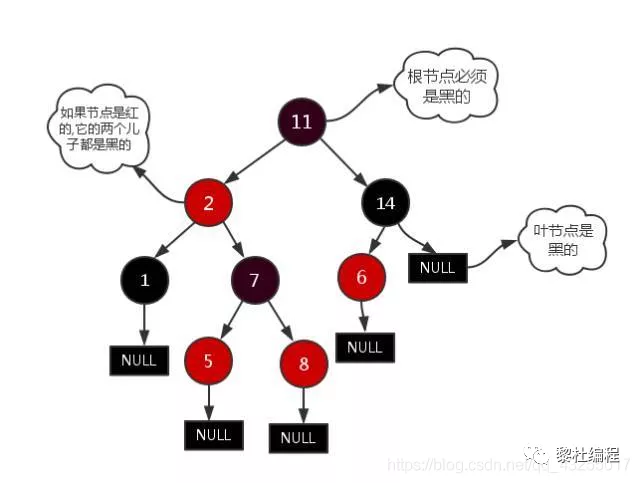
但是,同样还是存在数据量大导致树非常高的问题,所以现在的目标就是压缩树的高度。
## 为什么要用 B+ 树,为什么不用普通二叉树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数,为什么不是普通二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是 B+ 树呢?
>为什么不是普通二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
>为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快啦。
>为什么不是 B 树而是 B+ 树呢?
B+ 树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么 B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
> 为何不采用Hash方式?
因为Hash索引底层是哈希表,哈希表是一种以key-value存储数据的结构,所以多个数据在存储关系上是完全没有任何顺序关系的,所以,对于区间查询是无法直接通过索引查询的,就需要全表扫描。所以,哈希索引只适用于等值查询的场景。而B+ Tree是一种多路平衡查询树,所以他的节点是天然有序的(左子节点小于父节点、父节点小于右子节点),所以对于范围查询的时候不需要做全表扫描。
哈希索引不支持多列联合索引的最左匹配规则,如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题。
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期