
php.ini设置浏览器默认的字符集:
```
default_charset = "UTF-8"
```
指定页面编码
```
header("content-type;text/html;charset=UTF-8");
```
字符编码优先级:由高--->低
1.http消息报头的Content-Type字段中的charset参数。
2.通过meta元素声明,将http-equiv设置成Content-Type。
3.一些元素的charset属性设置。
# **字符集转换**
# mb_detect_encoding:检测字符编码
# mb_detect_order:设置检测字符的顺序
```
mb_detect_order('ASCII,ANSI,GB2312,BIG5,GBK,GB18030,Unicode,UTF-8,UTF-16,UTF-32');
//显示当前的检测顺序
echo implode(", ", mb_detect_order());
```
该设置会影响 [mb_detect_encoding()](http://www.php.net/manual/zh/function.mb-detect-encoding.php) 和 [mb_send_mail()](http://www.php.net/manual/zh/function.mb-send-mail.php)
只能检测;*UTF-8*, *UTF-7*, *ASCII*, *EUC-JP*,*SJIS*, *eucJP-win*, *SJIS-win*, *JIS*, *ISO-2022-JP*
对于 *UTF-16*、*UTF-32*、 *UCS2* 和 *UCS4*,编码检测总是会失败。
对于 *ISO-8859-\**,*mbstring* 总是检测为 *ISO-8859-\**。
# [mb_internal_encoding()](http://www.php.net/manual/zh/function.mb-internal-encoding.php) - 设置/获取内部字符编码
# [mb_http_input()](http://www.php.net/manual/zh/function.mb-http-input.php) - 检测 HTTP 输入字符编码
# [mb_http_output()](http://www.php.net/manual/zh/function.mb-http-output.php) - 设置/获取 HTTP 输出字符编码
# [mb_send_mail()](http://www.php.net/manual/zh/function.mb-send-mail.php) - 发送编码过的邮件
总是检测为 ISO-8859-1的情况: detect\_order = ISO-8859-1, UTF-8
总是检测为 UTF-8,由于 ASCII/UTF-7 的值对 UTF-8 是有效的:detect\_order = UTF-8, ASCII, UTF-7
例子:
```
function getEncoding($data)
{
return mb_detect_encoding($data, mb_detect_order());
}
$str='username';
$encoding=getEncoding($str);
$str=iconv($encoding, 'UTF-8', $str);
```
**中文字符编码标准**
**GB2312**,**CP936**,**GBK**,**GB18030**,**GB13000**
在技术编码方面上,演化顺序为真子集关系,ASCII ⊂ GB2312 ⊂ GBK ⊂ GB18030。
字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unicode 字符集和 UTF-8、UTF-16、UTF-32 等等编码……
Unicode 字符集为每一个字符分配一个码位,例如「知」的码位是 30693,记作 U+77E5(30693 的十六进制为 0x77E5)。
| 编码 | 描述 |在window中的代码页(Code Page) ,也可叫别名| 标准所属 |
| --- | --- | --- | --- |
| **ASCII** | 单字节编码(1字节 = 8 bit 即最多可以表示255 个字符)包含英文大小写字母和(! @ #等)特殊符号,如大写字母`U`就表示成`01010101` | --- | 国际通用 |
| GB2312 | 二个字节编码; 1980年,中国制定了GB2312-80,一共收录了**7445个字符**,包括6763个简体汉字(不含繁体)和包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。GB2312-80,简称为GB2312 | window以前的CP936 | 中国大陆 |
| Unicode 1.1 | 1993年,国际标准**Unicode 1.1**版本推出,收录中国大陆、台湾、日本及韩国通用字符集的汉字,总共有**20,902个字符**。 | --- | 国际通用 |
| GB13000 | 中国大陆订定了等同于Unicode 1.1版本的“GB 13000.1-93”,简称为GB13000 。包含的GB2312已有的文字和其他很多为包含的文字(总共有**20,902个**),如GB 2312-80推出以后才简化的汉字(如“啰”),部分人名用字(如中国前总理朱镕基的“镕”字),台湾及香港使用的繁体字,日语及朝鲜语汉字等 | --- (使用UTF的一套标准) | 中国大陆 |
| GBK | GBK作为微软对GB2312的扩展,即利用GB 2312-80未使用的编码空间,收录所有的GB 13000.1-93和Unicode 1.1之中的汉字全部字符,制定了GBK编码。GBK收录了**21886个字符**,它分为汉字区和图形符号区。汉字区包括21003个字符;GBK兼容旧的GB2312,但是编码方式和GB13000不同,不兼容GB13000,但是所包含文字上,算是和GB13000相同 | window现在的CP936 | 微软 |
| GB18030 | GBK自身并非国家标准,原始GB13000一直未被业界采用,2000年,国家出了标准GB18030-2000,简称GB18030,技术上兼容GBK而非GB13000,取代了GBK1.0,成了正式的国家标准。该标准收录了27484个汉字+其他少数民族字符 | CP54936 | 中国大陆 |
| **Unicode**· | 为了解决各国间编码不统一的问题,国际标准化组织(ISO)和多语言软件制造商这两个组织合作搞出了 **unicode编码**,它将所有语言统一到一套编码,解决了各国间编码格式不兼容的问题,运用在内存处理中。 unicode 编码采用**两个字节**来表示一个字符,这可以涵盖世界上主流使用的字符;Unicode(学名:Universal Multiple-Octet Coded Character Set)就是世界各国合作开发的一种语言,简称为UCS; | --- | --- |
| UTF-8 | utf-8 编码是一种可变长编码,是 Unicode 编码根据一套规则转换而来的,会将一个字符编码为 1 到 4 个字节,utf-8 编码一般可以减少字符编码的长度(特别是英文字符较多的情况),运用在传输和存储中;<br>如:在ASCII编码中,`U`对应二进制序列是`01010101,`而在 Unicode中,`U`对应的二进制序列是`0000000001010101`,同样表示一个英文字符,利用 Unicode 编码较 ASCII编码将多花费一倍的存储空间。将Unicode编码转换为utf-8编码**一般**(英文字符居多的情况)可以节省存储空间 | | |
| ISO | 欧洲语系 | | |
举一个例子:It's 知乎日报
unicode:每一个字符对应一个十六进制数字
```
I 0049
t 0074
' 0027
s 0073
0020
知 77e5
乎 4e4e
日 65e5
报 62a5
```
严格按照unicode的方式(UCS-2),应该这样存储:
```
I 00000000 01001001
t 00000000 01110100
' 00000000 00100111
s 00000000 01110011
00000000 00100000
知 01110111 11100101
乎 01001110 01001110
日 01100101 11100101
报 01100010 10100101
```
英文前9位都是0浪费,我们换成utf-8
```
I 01001001
t 01110100
' 00100111
s 01110011
00100000
知 11100111 10011111 10100101
乎 11100100 10111001 10001110
日 11100110 10010111 10100101
报 11100110 10001010 10100101
```
详细的转换过程参看[https://www.zhihu.com/question/23374078](https://www.zhihu.com/question/23374078)
utf-8 编码一般可以减少字符编码的长度(特别是英文字符较多的情况),因此它广泛运用在存储和传输的情形下。但是 utf-8 也不是没有缺点,由于在 utf-8 编码的规则下中英文的编码长度不同,因此这使得我们在内存中操作它们时变得很复杂。所以我们在内存中操作的字符使用的一般是 Unicode 编码,比如 Python 。下面一张图将清楚的描述出 Unicode 和 utf-8 编码的关系
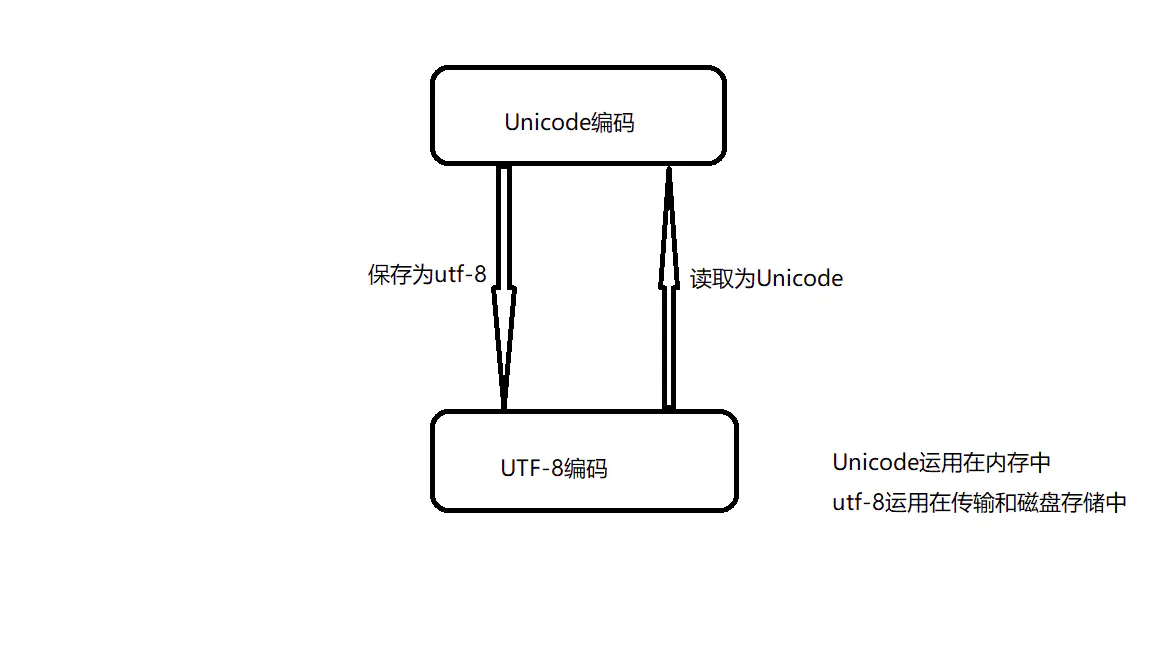
[**Code Page**](https://www.crifan.com/chinese_character_encoding_standard__unicode__code_page/)
什么是codepage?codepage就是各国的文字编码和Unicode之间的映射表
而目前现存的有多个厂家,都为对应的不同的字符集,定义了对应的Code Page
unicode包含gb13000
**图表3DBCS字符集所对应的Code Page**
| **代码页Code Page** | **对应的字符集Character Set** |
| --- | --- |
| 932 | Japanese |
| 936 | GBK – Simplified Chinese |
| 949 | Korean |
| 950 | BIG5 – Traditional Chinese |
**图表4微软的其他字符编码的Code Page**
| **代码页Code Page** | **对应的字符集Character Set** |
| --- | --- |
| 1200 | UTF-16LE Unicode little-endian |
| 1201 | UTF-16BE Unicode big-endian |
| 65000 | UTF-7 Unicode |
| 65001 | UTF-8 Unicode |
| 10000 | Macintosh Roman encoding (followed by several other Mac character sets) |
| 10007 | Macintosh Cyrillic encoding |
| 10029 | Macintosh Central European encoding |
| 20127 | US-ASCII The classic US 7 bit character set with no char larger than 127 |
| 28591 | ISO-8859-1 (followed by ISO-8859-2 to ISO-8859-15) |
微软自己定义了一系列的Code Page,称为ANSI Code Page。
起初,CP1252是基于ANSI的draft版本的,而ANSI后来演化为称为ISO 8859-1,所以,算是CP1252是基于ISO 8859-1的,但是将ISO 8859-1中的C1 Control Code用作为扩展的可打印字符。
| **代码页Code Page** | **对应的字符集Character Set** |
| --- | --- |
| 1250 | Central and East European Latin |
| 1251 | Cyrillic |
| 1252 | West European Latin |
| 1253 | Greek |
| 1254 | Turkish |
| 1255 | Hebrew |
| 1256 | Arabic |
| 1257 | Baltic |
| 1258 | Vietnamese |
| 874 | Thai |
上述Code Page中,我们比较常见一些的有:
简体中文是CP936,繁体中文是CP950,UTF-8是65001等。
https://my.oschina.net/junn/blog/282160
## **字符编码转换:**
*iconv('GB2312', 'UTF-8//IGNORE', $str); //将字符串的编码从GB2312转到UTF-8 c底层实现 转码速度快*
// utf8转gb2312 可能会被截断而报错;如utf8的中文字符”—”转换gb2312。可以加//IGNORE或者//TRANSLIT解决
// //IGNORE 忽略不能转换的字符
// //TRANSLIT如果在目标编码中找不到与源编码相匹配的字符,会选择相似的字符进行转换
*mb\_convert\_encoding(字符串,新编码,原编码,) 必须开启扩展才行,转码速度也比较慢 在不能转码的字符时会强制转换成\\0x00\\0x80,如从utf8转换成gbk时*
一般情况下用 iconv,只有当遇到无法确定原编码是何种编码,或者iconv转化后无法正常显示时才用mb\_convert\_encoding 函数
[iconv支持的字符集](http://www.gnu.org/software/libiconv/)
~~~
mbstring该 PHP 扩展支持的字符编码有以下几种: (即带有mb_xxx的函数)
UCS-4*
UCS-4BE
UCS-4LE*
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*
EUC-JP*
SJIS*
eucJP-win*
SJIS-win*
ISO-2022-JP
ISO-2022-JP-MS
CP932
CP51932
SJIS-mac** (别名: MacJapanese)
SJIS-Mobile#DOCOMO** (别名: SJIS-DOCOMO)
SJIS-Mobile#KDDI** (别名: SJIS-KDDI)
SJIS-Mobile#SOFTBANK** (别名: SJIS-SOFTBANK)
UTF-8-Mobile#DOCOMO** (别名: UTF-8-DOCOMO)
UTF-8-Mobile#KDDI-A**
UTF-8-Mobile#KDDI-B** (别名: UTF-8-KDDI)
UTF-8-Mobile#SOFTBANK** (别名: UTF-8-SOFTBANK)
ISO-2022-JP-MOBILE#KDDI** (别名: ISO-2022-JP-KDDI)
JIS
JIS-ms
CP50220
CP50220raw
CP50221
CP50222
ISO-8859-1*
ISO-8859-2*
ISO-8859-3*
ISO-8859-4*
ISO-8859-5*
ISO-8859-6*
ISO-8859-7*
ISO-8859-8*
ISO-8859-9*
ISO-8859-10*
ISO-8859-13*
ISO-8859-14*
ISO-8859-15*
ISO-8859-16*
byte2be
byte2le
byte4be
byte4le
BASE64
HTML-ENTITIES
7bit
8bit
EUC-CN*
CP936
GB18030**
HZ
EUC-TW*
CP950
BIG-5*
EUC-KR*
UHC (CP949)
ISO-2022-KR
Windows-1251 (CP1251)
Windows-1252 (CP1252)
CP866 (IBM866)
KOI8-R*
KOI8-U*
ArmSCII-8 (ArmSCII8)
* 表示该编码也可以在正则表达式中使用。
** 表示该编码自 PHP 5.4.0 始可用。
~~~
- php更新内容
- PHP PSR 标准规范
- 辅助查询(*)
- composer项目的创建
- composer安装及设置
- composer自动加载讲解
- phpsdudy的composer操作
- git
- Git代码同时上传到GitHub和Gitee(码云)
- Git - 多人协同开发利器,团队协作流程规范与注意事项
- 删除远程仓库的文件
- github查询方法
- 错误
- 其他
- php.ini
- php配置可修改范围
- php超时
- 防跨目录设置
- 函数可变参数
- 【时间】操作
- 时间函数例子
- Date/Time 函数(不包含别名函数)
- DateTime类别名函数
- 【数字】操作
- 【字符串】操作
- 【数组】操作
- 排序
- 合并案例
- empty、isset、is_null
- echo 输出bool值
- if真假情况
- 流程控制代替语法【if (条件): endif;】
- 三元运算
- 运算符优先级
- 常量
- define与const(php5.3) 类常量
- 递归
- 单元测试
- 面向对象
- 对象(object) 与 数组(array) 的转换
- php网络相关
- 支持的协议和封装协议(如http,php://input)
- php://协议
- file://协议
- http(s)://协议
- ftp(s)://协议
- zip://, bzip2://, zlib://协议
- data://协议
- glob://协议
- expect://协议
- phar://
- ssh2
- rar://
- ogg://
- 上下文(Context)选项和参数
- 过滤器
- http请求及模拟登录
- 常用的header头部定义汇总
- HTTP响应头和请求头信息对照表
- HTTP请求的返回值含义说明
- content-type对照表
- Cache-Control对照
- curl函数
- 防止页面刷新
- telnet模拟get、post请求
- 三种方式模拟表单发布留言
- 模拟登陆
- 防盗链
- php+mysql模拟队列发送邮件
- socket
- 使用websocket实现php消息实时推送完整示例
- streams
- Stream函数实现websocket
- swoole
- 网络编程基本概念
- 全局变量域超全局变量
- 超全局变量
- $_ENV :存储了一些系统的环境变量
- $_COOKIE
- $_SESSION
- $_FILES
- $_SERVER
- 正则
- php正则函数
- 去除文本中的html、xml的标签
- 特殊符号
- \r\n
- 模式修正符
- 分组
- 断言(环视?)
- 条件表达式
- 递归表达式 (?R)
- 固化分组
- 正则例子
- 提取类文件的公共方法
- 抓取网页内容
- 匹配中文字符
- 提取sql日志文件
- 框架
- 文件操作
- 自动加载spl_autoload_register
- 文件加载
- 文件的上传下载
- 常见的mimi类型
- 文件断点续传
- 下载文件防盗链
- 破解防盗链
- 将字节转为人可读的单位
- 无限分类
- 短信验证码
- 短信宝
- 视频分段加载
- 隐藏地址
- MPEG DASH视频分片技术
- phpDoc注释
- @错误抑制符
- 字符编码
- PHP CLI模式开发
- CGI、FastCGI和PHP-FPM关系图解
- No input file specified的解决方法
- SAPI(PHP常见的四种运行模式)
- assert断言
- 轮询(Event Loop)
- 异常处理
- 异常分类
- php系统异常
- 错误级别
- set_error_handler
- set_exception_handler
- register_shutdown_function
- try catch
- tp5异常处理类解析
- 文件上传相关设置
- 进程/线程/协程
- 协程
- 什么是协程
- 引用&
- Heredoc和Nowdoc语法
- 类基础
- 系统预定义类
- pdo
- 类的三大特性:封装,继承,多态
- 魔术方法
- extends继承
- abstract 抽象类
- interface 接口(需要implements实现)
- 抽象类和接口的区别
- 多态
- static
- final
- serialize与unserialize
- instanceof 判断后代子类
- 类型约束
- clone克隆
- ::的用法
- static::class、self::class
- new self()与new static()
- this、self、static、parent、super
- self、static、parent:后期静态绑定
- PHP的静态变量
- php导入
- trait
- 动态调用类方法
- 参数及类型申明
- 方法的重载覆盖
- return $a && $b
- 类型声明
- 设计思想
- 依赖注入与依赖倒置
- MVC模式与模板引擎
- 模版引擎
- smarty模版
- 系统变量、全局变量
- 语言切换
- 函数-给函数默认值
- 流程控制-遍历
- 模版加载
- 模版继承
- blade
- twig
- Plates
- 创建型模式(创建类对象)--单原二厂建
- (*)单例模式(保证一个类仅有一个实例)
- (*)工厂模式(自动实例化想要的类)
- 原型模式(在指定方法里克隆this)
- 创建者模式(建造者类组装近似类属性)
- 结构型模式 --桥(帮)组享外带装适
- 适配器模式(Adapter 用于接口兼容)
- 桥接模式(方法相同的不同类之间的快速切换)
- 装饰模式(动态增加类对象的功能 如游戏角色的装备)
- 组合模式(用于生成类似DOMDocument这种节点类)
- 外观模式(门面(Facade)模式 不同类的统一调用)
- 享元模式
- 代理模式
- 行为型模式--观摩职命状-备爹在房中洁厕
- (*)观察者模式
- (*)迭代器模式(Iterator)
- 模板方法模式 Template
- 命令模式(Command)
- 中介者模式(Mediator)
- 状态模式(State)
- 职责链模式 (Chainof Responsibility)
- 策略模式(Strategy)
- 已知模式-备忘录模式(Memento)
- 深度模式-解释器模式(Interpreter)
- 深度模式-访问者模式(Visitor)
- (*)注册树(注射器、注册表)模式
- PHP扩展库列表
- 函数参考
- 影响 PHP 行为的扩展
- APC扩展(过时)
- APCu扩展
- APD扩展(过时)
- bcompiler扩展(过时)
- BLENC扩展 (代码加密 实验型)
- Componere扩展(7.1+)
- Componere\Definition
- Componere\Patch
- Componere \ Method
- Componere\Value
- Componere函数
- 错误处理扩展(PHP 核心)
- FFI扩展
- 基本FFI用法
- FFI api
- htscanner扩展
- inclued扩展
- Memtrack扩展
- OPcache扩展(5.5.0内部集成)
- Output Control扩展(核心)
- PHP Options/Info扩展(核心)
- 选项、 信息函数
- phpdbg扩展(5.6+内部集成)
- runkit扩展
- runkit7扩展
- scream扩展
- uopz扩展
- Weakref扩展
- WeakRef
- WeakMap
- WinCache扩展
- Xhprof扩展
- Yac(7.0+)
- 音频格式操作
- ID3
- KTaglib
- oggvorbis
- OpenAL
- 身份认证服务
- KADM5
- Radius
- 针对命令行的扩展
- Ncurses(暂无人维护)
- Newt(暂无人维护)
- Readline
- 压缩与归档扩展
- Bzip2
- LZF
- Phar
- Rar
- Zip
- Zlib
- 信用卡处理
- 加密扩展
- Crack(停止维护)
- CSPRNG(核心)
- Hash扩展(4.2内置默认开启、7.4核心)
- Mcrypt(7.2移除)
- Mhash(过时)
- OpenSSL(*)
- 密码散列算法(核心)
- Sodium(+)
- 数据库扩展
- 数据库抽象层
- DBA
- dbx
- ODBC
- PDO(*)
- 针对各数据库系统对应的扩展
- CUBRID
- DB++(实验性)
- dBase
- filePro
- Firebird/InterBase
- FrontBase
- IBM DB2
- Informix
- Ingres
- MaxDB
- Mongo(MongoDB老版本)
- MongoDB
- mSQL
- Mssql
- MySQL
- OCI8(Oracle OCI8)
- Paradox
- PostgreSQL
- SQLite
- SQLite3
- SQLSRV(SQL Server)
- Sybase
- tokyo_tyrant
- 日期与时间相关扩展
- Calendar
- 日期/时间(核心)
- HRTime(*)
- 文件系统相关扩展
- Direct IO
- 目录(核心)
- Fileinfo(内置)
- 文件系统(核心)
- Inotify
- Mimetype(过时)
- Phdfs
- Proctitle
- xattr
- xdiff
- 国际化与字符编码支持
- Enchant
- FriBiDi
- Gender
- Gettext
- iconv(内置默认开启)
- intl
- 多字节字符串(mbstring)
- Pspell
- Recode(将要过时)
- 图像生成和处理
- Cairo
- Exif
- GD(内置)
- Gmagick
- ImageMagick
- 邮件相关扩展
- Cyrus
- IMAP
- Mail(核心)
- Mailparse
- vpopmail(实验性 )
- 数学扩展
- BC Math
- GMP
- Lapack
- Math(核心)
- Statistics
- Trader
- 非文本内容的 MIME 输出
- FDF
- GnuPG
- haru(实验性)
- Ming(实验性)
- wkhtmltox(*)
- PS
- RPM Reader(停止维护)
- RpmInfo
- XLSWriter Excel操作(*)
- php第三方库非扩展
- 进程控制扩展
- Eio
- Ev
- Expect
- Libevent
- PCNTL
- POSIX
- 程序执行扩展(核心)
- parallel
- pthreads(*)
- pht
- Semaphore
- Shared Memory
- Sync
- 其它基本扩展
- FANN
- GeoIP(*)
- JSON(内置)
- Judy
- Lua
- LuaSandbox
- Misc(核心)
- Parsekit
- SeasLog(-)
- SPL(核心)
- SPL Types(实验性)
- Streams(核心)
- stream_wrapper_register
- stream_register_wrapper(同上别名)
- stream_context_create
- stream_socket_client
- stream_socket_server
- stream_socket_accept
- stream_socket_recvfrom
- stream_socket_sendto
- Swoole(*)
- Tidy扩展
- Tokenizer
- URLs(核心)
- V8js(*)
- Yaml
- Yaf
- Yaconf(核心)
- Taint(检测xss字符串等)
- Data Structures
- Igbinary(7.0+)
- 其它服务
- 网络(核心)
- Sockets
- socket_create
- socket_bind(服务端即用于监听的套接字)
- socket_listen(服务端)
- socket_accept(服务端)
- socket_connect(客户端)
- socket_read
- socket_recv(类似socket_read)
- socket_write
- socket_send
- socket_close
- socket_select
- socket_getpeername
- socket_getsockname
- socket_get_option
- socket_getopt(socket_get_option的别名)
- socket_set_option
- socket_setopt( socket_set_option的别名)
- socket_recvfrom
- socket_sendto
- socket_addrinfo_bind
- socket_addrinfo_connect
- socket_addrinfo_explain
- socket_addrinfo_lookup
- socket_clear_error
- socket_last_error
- socket_strerror
- socket_cmsg_space
- socket_create_listen
- socket_create_pair
- socket_export_stream
- socket_import_stream
- socket_recvmsg
- socket_sendmsg
- socket_set_block
- socket_set_nonblock
- socket_shutdown
- socket_wsaprotocol_info_export
- socket_wsaprotocol_info_import
- socket_wsaprotocol_info_release
- cURL(*)
- curl_setopt
- Event(*)
- chdb
- FAM
- FTP
- Gearman
- Gopher
- Gupnp
- Hyperwave API(过时)
- LDAP(+)
- Memcache
- Memcached(+)
- mqseries
- RRD
- SAM
- ScoutAPM
- SNMP
- SSH2
- Stomp
- SVM
- SVN(试验性的)
- TCP扩展
- Varnish
- YAZ
- YP/NIS
- 0MQ(ZeroMQ、ZMQ)消息系统
- 0mq例子
- ZooKeeper
- 搜索引擎扩展
- mnoGoSearch
- Solr
- Sphinx
- Swish(实验性)
- 针对服务器的扩展
- Apache
- FastCGI 进程管理器
- IIS
- NSAPI
- Session 扩展
- Msession
- Sessions
- Session PgSQL
- 文本处理
- BBCode
- CommonMark(markdown解析)
- cmark函数
- cmark类
- Parser
- CQL
- IVisitor接口
- Node基类与接口
- Document
- Heading(#)
- Paragraph
- BlockQuote
- BulletList
- OrderedList
- Item
- Text
- Strong
- Emphasis
- ThematicBreak
- SoftBreak
- LineBreak
- Code
- CodeBlock
- HTMLBlock
- HTMLInline
- Image
- Link
- CustomBlock
- CustomInline
- Parle
- 类函数
- PCRE( 核心)
- POSIX Regex
- ssdeep
- 字符串(核心)
- 变量与类型相关扩展
- 数组(核心)
- 类/对象(核心)
- Classkit(未维护)
- Ctype
- Filter扩展
- 过滤器函数
- 函数处理(核心)
- quickhash扩展
- 反射扩展(核心)
- Variable handling(核心)
- Web 服务
- OAuth
- api
- 例子:
- SCA(实验性)
- SOAP
- Yar
- XML-RPC(实验性)
- Windows 专用扩展
- COM
- 额外补充:Wscript
- win32service
- win32ps(停止更新且被移除)
- XML 操作(也可以是html)
- libxml(内置 默认开启)
- DOM(内置,默认开启)
- xml介绍
- 扩展类与函数
- DOMNode
- DOMDocument(最重要)
- DOMAttr
- DOMCharacterData
- DOMText(文本节点)
- DOMCdataSection
- DOMComment(节点注释)
- DOMDocumentFragment
- DOMDocumentType
- DOMElement
- DOMEntity
- DOMEntityReference
- DOMNotation
- DOMProcessingInstruction
- DOMXPath
- DOMException
- DOMImplementation
- DOMNamedNodeMap
- DOMNodeList
- SimpleXML(内置,5.12+默认开启)
- XMLReader(5.1+内置默认开启 用于处理大型XML文档)
- XMLWriter(5.1+内置默认开启 处理大型XML文档)
- SDO(停止维护)
- SDO-DAS-Relational(试验性的)
- SDO DAS XML
- WDDX
- XMLDiff
- XML 解析器(Expat 解析器 默认开启)
- XSL(内置)
- 图形用户界面(GUI) 扩展
- UI
- PHP SPL(PHP 标准库)
- 数据结构
- SplDoublyLinkedList(双向链表)
- SplStack(栈 先进后出)
- SplQueue(队列)
- SplHeap(堆)
- SplMaxHeap(最大堆)
- SplMinHeap(最小堆)
- SplPriorityQueue(堆之优先队列)
- SplFixedArray(阵列【数组】)
- SplObjectStorage(映射【对象存储】)
- 迭代器
- ArrayIterator
- RecursiveArrayIterator(支持递归)
- DirectoryIterator类
- FilesystemIterator
- GlobIterator
- RecursiveDirectoryIterator
- EmptyIterator
- IteratorIterator
- AppendIterator
- CachingIterator
- RecursiveCachingIterator
- FilterIterator(遍历并过滤出不想要的值)
- CallbackFilterIterator
- RecursiveCallbackFilterIterator
- RecursiveFilterIterator
- ParentIterator
- RegexIterator
- RecursiveRegexIterator
- InfiniteIterator
- LimitIterator
- NoRewindIterator
- MultipleIterator
- RecursiveIteratorIterator
- RecursiveTreeIterator
- 文件处理
- SplFileInfo
- SplFileObject
- SplTempFileObject
- 接口 interface
- Countable
- OuterIterator
- RecursiveIterator
- SeekableIterator
- 异常
- 各种类及接口
- SplSubject
- SplObserver
- ArrayObject(将数组作为对象操作)
- SPL 函数
- 预定义接口
- Traversable(遍历)接口
- Iterator(迭代器)接口
- IteratorAggregate(聚合式迭代器)接口
- ArrayAccess(数组式访问)接口
- Serializable 序列化接口
- JsonSerializable
- Closure 匿名函数(闭包)类
- Generator生成器类
- 生成器(php5.5+)
- yield
- 反射
- 一、反射(reflection)类
- 二、Reflector 接口
- ReflectionClass 类报告了一个类的有关信息。
- ReflectionObject 类报告了一个对象(object)的相关信息。
- ReflectionFunctionAbstract
- ReflectionMethod 类报告了一个方法的有关信息
- ReflectionFunction 类报告了一个函数的有关信息。
- ReflectionParameter 获取函数或方法参数的相关信息
- ReflectionProperty 类报告了类的属性的相关信息。
- ReflectionClassConstant类报告有关类常量的信息。
- ReflectionZendExtension 类返回Zend扩展相关信息
- ReflectionExtension 报告了一个扩展(extension)的有关信息。
- 三、ReflectionGenerator类用于获取生成器的信息
- 四、ReflectionType 类用于获取函数、类方法的参数或者返回值的类型。
- 五、反射的应用场景
- phpRedis
- API
- API详细
- redis DB 概念:
- 通用命令:rawCommand
- Connection
- Server
- List
- Set
- Zset
- Hash
- string
- Keys
- 事物
- 发布订阅
- 流streams
- Geocoding 地理位置
- lua脚本
- Introspection 自我检测
- biMap
- 原生
- php-redis 操作类 封装
- redis 队列解决秒杀解决超卖:
- swoole+框架笔记
- 安装及常用Cli操作
- TCP
- 4种回调函数的写法
- easyswoole
- 目录结构
- 配置文件
- Linux+Nginx
- 前置
- linux
- 开源网站镜像及修改yum源
- 下载linux
- Liunx中安装PHP7.4 的三种方法(Centos8)
- yum安装
- 源码编译安装
- LNMP一键安装
- 查看linux版本号
- 设置全局环境变量
- 查看php.ini必须存放的位置
- 防火墙与端口开放
- nohup 后台运行命令
- linux 查看nginx,php-fpm运行用户及用户组
- 网络配置
- CentOS中执行yum update时报错
- 关闭防火墙
- 查看端口是否被占用
- 查看文件夹大小
- nginx相关
- 一个典型的nginx配置
- nginx关于多个项目的配置(易于管理)
- nginx.config配置文件的结构
- 1、events
- 2、http
- nginx的location配置详解
- Nginx相关命令
- Nginx安装
- 配置伪静态
- 为静态配置例子
- apache
- nginx
- pathinfo模式
- Shell脚本
- bash
- shell 语言中 0 代表 true,0 以外的值代表 false。
- 变量
- shell字符串
- shell数组
- shell注释
- 向Shell脚内传递参数
- 运算符
- 显示命令执行结果
- printf
- test 命令
- 流程控制与循环
- if
- case
- for
- while
- until
- break和continue
- select 结构
- shell函数
- shell函数的全局变量和局部变量
- 将shell输出写入文件中(输出重定向)
- Shell脚本中调用另一个Shell脚本的三种方式
- 定时任务
- PHP实现定时任务的五种方法
- 优化
- ab压力测试
- 缓存
- opcache
- memcache
- php操作
- 数据库
- 配置
- 数据库锁机制
- 主从分布
- 数据库设计
- 逻辑设计
- 物理设计
- 字段类型的选择
- 笔记
- SET FOREIGN_KEY_CHECKS
- 字符集与乱码
- SQL插入 去除重复记录的实现
- 分区表
- nginx 主从配置
- nginx 负载均衡的配置
- 手动搭建Redis集群和MySQL主从同步(非Docker)
- Redis Cluster集群
- mysql主从同步
- 用安卓手机搭建 web 服务器
- 软件选择
- url重写
- 大流量高并发解决方案
- 权限设计
- ACL
- RBAC
- RBAC0
- RBAC1(角色上下级分层)
- RBAC2(用户角色限约束)
- RBAC3
- 例子
- Rbac.class.php
- Rbac2
- Auth.class.php
- fastadmin Auth
- tree1
- ABAC 基于属性的访问控制
- 总结:SAAS后台权限设计案例分析
- casbin-权限管理框架
- 开始使用
- casbinAPI
- casbin管理API
- RBAC API
- Think-Casbin
- 单点登录(SSO)
- OAuth授权
- OAuth 2.0 的四种方式
- 授权码
- 隐藏式
- 密码式
- 凭证式
- 更新令牌
- 例子:第三方登录
- 微服务架构下的统一身份认证和授权
- 代码审计
- 漏洞挖掘的思路
- 命令注入
- 代码注入
- XSS 反射型漏洞
- XSS 存储型漏洞
- xss过滤
- HTML Purifier文档
- 开始
- id规则
- class规则
- 过滤分类
- Attr
- AutoFormat
- CSS
- Cache
- Core
- Filter
- html
- Output
- Test
- URI
- 其他
- 嵌入YouTube视频
- 加快HTML净化器的速度
- 字符集
- 定制
- Tidy
- URI过滤器
- 在线测试
- xss例子
- 本地包含与远程包含
- sql注入
- 函数
- 注释
- 步骤
- information_schema
- sql注入的分类
- 实战
- 防御
- CSRF 跨站请求伪造
- 计动态函数执行与匿名函数执行
- unserialize反序列化漏洞
- 覆盖变量漏洞
- 文件管理漏洞
- 文件上传漏洞
- 跳过登录
- URL编码对照表
- XXE
- 前端、移动端
- html5
- meta标签
- flex布局
- javascript
- jquery
- 选择器
- 精细分类
- 事件
- on事件无效:
- jquery自定义事件
- 表单操作
- 通用
- select
- checkbox
- radio
- js正则相关
- js中判断某字符串含有某字符出现的次数
- js匹配指定字符
- $.getjson方法配合在url上传递callback=?参数,实现跨域
- pajax入门
- jquery的extend插件制作
- jquery的兼容
- jquery的连续调用:
- $ 和 jQuery 及 $() 的区别
- 页面响应顺序及$(function(){})等使用
- 匿名函数:
- ajax
- 获取js对象所有方法
- dom加载
- ES6函数写法
- ES6中如何导入和导出模块
- 数组的 交集 差集 补集 并集
- phantomjs
- js数组的map()方法操作json数组
- 实用函数
- js精确计算CalcEval 【价格计算】 浮点计算
- js精确计算2
- js数组与对象的遍历
- bootstrap
- class速查
- 常见data属性
- data-toggle与data-target的作用
- 组件
- bootstrapTable
- 表选项
- 表选项2
- 示例
- 数据格式(json)
- 用法(row:行,column:列)
- Bootstrap-table使用footerFormatter做统计列功能
- 示例2
- JQuery-Jquery的TreeGrid插件
- 服务器端分页
- 合并单元格1
- 合并单元格2
- 合并单元格3
- 合并单元格4
- 合并单元格5(插件)
- 列求和
- 添加行,修改行、扩展行数据
- 扩展
- 开源项目
- PhpSpreadsheet
- 实例
- 会员 数据库表设计
- 程序执行
- 开发总结
- API接口
- API接口设计
- json转化
- app接口
- 杂项
- 三方插件库
- 检测移动设备(包括平板电脑)
- curl封装
- Websocket
- 与谷歌浏览器交互
- Crontab管理器
- 实用小函数
- PHP操作Excel
- SSL证书
- sublime Emmet的快捷语法
- 免费翻译接口
- 接口封装
- 免费空间
- 架构师必须知道的26项PHP安全实践
- 大佬博客
- 个人支付平台
- RPC(远程调用)及框架