
# 1985:SuperMemo 的诞生
[TOC=2,5]
## 为了更好学习的动力
我在教育系统里待了 22 年。关于学校教育的古老真理与我的观点完全吻合。我从不喜欢上学,但我总是喜欢学习。我从不让学校妨碍我的学习。在公立学校系统待了 12 年之后,进入大学时,我仍然热爱学习。学校教育并没有破坏这种热爱,主要有两个原因:(1)学校对我很宽容,(2)在家里,我可以自由地学习我喜欢的东西。在共产主义的波兰,我从未真正经历过沉重的学业带来的毒鞭。这个制度疏忽大意,我喜欢由此带来的自由。
我们都知道最好的学习来自激情。它是由学习内驱力驱动的。我的学习内驱力很强,但也夹杂着一些挫折。我学得越多,就越能看到遗忘的力量。我无法通过更多的学习来弥补遗忘 。与其他学生相比,我的记忆力并不差,但很明显,我的记忆力有漏洞。
1982 年,我更加关注大多数学生迟早会发现的东西:考试效果。我开始形成主动回忆的知识。我会把问题写在一页的左边,答案写在右边的一栏里:

> **图:** 1982 年,我的学习资料被组织成问答栏,用于主动回忆。图为我的波兰英语单词对数据库(1982 年 6 月)
这样,我就可以用一张纸把答案盖住,并通过主动回忆来获得更好的复习记忆效果。这是一个缓慢的过程,但学习效率显著提高。我当时的笔记被描述为“*快速吸收材料*”,指的是学习的速度,表示的是这种特定的两栏方式,我的知识就是用这种方式记录下来的。
在 1982 - 1983 年期间,我不断扩大我在生物化学和英语领域的“快速吸收”知识。我会不时地回顾我的资料页,以减少遗忘。我的记忆力提高了,但我再次碰壁只是时间问题。我拥有的页面越多,复习的频率越低,记忆遗漏的问题就越明显。下面是一个重复历史的例子:
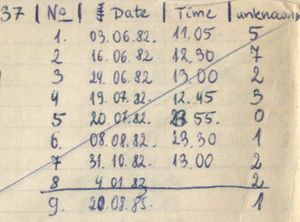
> **图:** 复习历史是记录复习的日期和成绩。在这个例子中,1982 - 1985 年进行了 8 次重复。38 对单词的页面记录了每次重复 0 - 7 次的记忆流失。这种断断续续的复习在 1985 年被 SuperMemo 方法所取代
1982 年 6 月到 1984 年 12 月之间,我的英语 - 波兰语单词对笔记本增加到 79 页,看起来像这样:

> **图:** 我的英语 - 波兰语笔记本中的一个典型页面开始于 1982 年 6 月。单词对将列在左侧。复习历史记录在右侧。回忆错误将被标记为中间的点
这 79 页只有 2794 个单词。这只是我所需要的一小部分,而且已经相当令人头疼了。有趣的是,这些页面是为被动理解英语而建立的(英语:波兰语)。直到 1984 年,我才开始积极学习英语(波兰语:英语)。这两年的耽搁来自这样一个事实:我发现被动的词汇知识在阅读中就足够了,但对于说一门语言是不够的,可惜为时已晚。这种在 6 年学校教育后的无知是一种常态。学校做了大量的练习,但对什么才能提高学习效率却鲜有说明。
1984 年底,我决定改进复习过程,并进行一项改变了我生活的实验。最后,三十年后,我非常自豪地注意到它实际上影响了数百万人。实验打开了闸门。我们已经进入了更快更好学习的时代。
我在 1990 年的硕士论文中是这样描述这个初级阶段的:
> 存档警告:为什么使用文字存档?
>
> 本文是 Piotr Wozniak 的“*学习的优化*”(1990)的一部分
>
> 1982 年,我对记忆机制进行了第一次观察,这些观察后来被用于制定 Supermemo 方法。作为一名当时的分子生物学学生,我被通过数学、物理、化学、生物学等考试所需的大量知识所淹没。问题不在于无法掌握这些知识。通常情况下,2 - 3 天的密集学习足以使头脑中充满通过考试所需的数据。令人沮丧的是,在考试后的几个月后,新获得的学识中只有极小的一部分可以留在记忆中。
>
> 我的第一个观察结果,对每个细心的学生来说都是显而易见的,那就是学习的关键要素之一是积极的回忆。这种观察表明,如果没有试图从记忆中回忆所学到的事实,被动阅读书籍是不够的。将学习过程建立在回忆基础上的原则稍后将被称为**主动回忆原则**。如果学生提出的问题是具体的而不是一般的,那么回忆的过程会更快,也不会降低效率。这是因为一般问题的答案包含描述应答子组件之间的关系所必需的冗余信息。
>
> 为了说明这个问题,让我们设想一个极端的情况,在这种情况下,一个学生想要掌握某种教科书中包含的知识,而谁在回忆过程中只使用一个问题:你从教科书中学到了什么?显然,描述这本书的章节顺序的信息将有助于回答这个问题,但对于学生真正想知道的内容来说,这肯定是多余的。将回忆过程建立在具体问题基础上的原则稍后将被称为**最小信息原则**。这一原则似乎是合理的,不仅仅是因为消除了冗余。
>
> 考虑到主动回忆和最小信息的原则,我创建了我的第一个数据库(即问题和答案的集合),试图将获得的知识保留在记忆中。当时,数据库是以书面形式存储在纸上的。我的第一个数据库开始于 1982 年 6 月 6 日,由页面组成,每个页面包含大约 40 对单词。一对单词中的第一个单词(即问题)是英语术语,第二个单词(即答案)是波兰语中的等价词。我将这些对称为**项目**。
>
> 我在数据库中以不规则的间隔重复特定的页面(主要取决于是否有时间),并记录重复的日期,没有被记住的项目及其数量。在足够频繁地执行重复的条件下,这种将获得的知识保存在记忆中的方法对于中等大小的数据库来说是足够的。
>
## 间隔重复诞生的日子:1985 年 7 月 31 日
### 直觉
1984 年,我关于记忆的推理基于两个可能所有学生都有的简单直觉:
- 如果我们复习两次,我们就能更好地记住它。这很明显,不是吗?如果我们把它复习三遍,我们可能会记得更清楚。
- 如果我们记住一组笔记,它们将逐渐从记忆中消失,即不是一次全部消失。这在生活中很容易观察到。记忆有不同的寿命
这两种直觉应该让每个人都想知道:我们失去了多少笔记,速度有多快?我们下一次应该什么时候复习?
直到今天,我仍然感到惊讶的是,很少有人费心去测量这个“最佳间隔”。当我自己测量它时,我确信我会在心理学书籍中找到更准确的结果。我没有。请看:为什么间隔重复研究总是失败?
### 实验
下面这个简单的实验导致了间隔重复的诞生。它于 1985 年进行,并于 1990 年在我的硕士论文中首次描述。它被用来建立前 5 页重复知识页的最佳间隔。每页包含大约 40 个单词对,最佳间隔在大约 5 - 10% 的知识被遗忘的时候取到。当然,这些间隔只适合于特定类型的知识,以及特定的人(在本例中是我)。此外,为了加快速度,测量样本很小。请注意,这不是一个研究项目。它不是为出版而准备的。目的只是为了加快我自己的学习速度。我确信肯定有其他人更精确地测量了间隔,但在 Google 诞生 13 年前,我认为测量间隔会比挖掘图书馆寻找更好的数据更快。实验于 1985 年 8 月 24 日结束,我最初将这一天命名为间隔重复的生日。然而,在 2018 年写这篇课文时,我找到了原始的学习材料,似乎是我对学习的渴望让我在 1985 年 7 月 31 日制定了算法大纲。这是我开始学习人类生物学的一天,使用我的间隔重复算法。
基于这个原因,我可以说最准确的 Supermemo 和计算间隔重复的诞生日是 1985 年 7 月 31 日。
到 7 月 31 日,在实验结束之前,结果似乎是可以预测的。在后来的几年里,这一特殊实验的发现显得相当普遍,可以扩展到更多的知识领域,并扩展到整个健康的成年人群体。即使在 2018 年,算法 SM-17 的默认设置也与那些早期的初步发现相差不远。
> **间隔重复出生于 1985 年 7 月 31 日**
这是我硕士论文中对实验的原始描述,对语法和风格做了一些小的修改。2018 年增加了文本中的重点,以突出重要部分。如果文本看起来枯燥难懂,请比较一下 1885 年艾宾浩斯。这是在记忆区域中相同的书写风格。只有目标不同。艾宾浩斯试图理解记忆。100 年后,我只想学得更快:
> 存档警告:为什么使用文字存档?
>
> 本文是 Piotr Wozniak 的“*学习的优化*”(1990)的一部分
>
> **旨在近似最佳重复间隔长度的实验**(1985 年 2 月 25 日 - 1985 年 8 月 24 日):
>
> 1. 实验分为 A、B、C、… 等阶段。这些阶段中的每个阶段旨在计算第二、第三、第四和进一步的准最优重复间隔(第一间隔被设置为一天,因为从早先收集的数据判断,它似乎是最合适的间隔)。建立准最佳间隔的标准是,它们应该尽可能长,并允许记忆知识的损失不超过 5%。
> 2. 每一阶段 A、B、C 中记忆的知识由5页组成,约40个项目,形式如下:
> 3. 在给定阶段中使用的每一页在单个会话中被记忆,并在第二天重复。为了避免混淆,请注意,为了简化进一步的考虑,我使用术语“第一次重复”来表示对一个项目或一组项目的记忆。毕竟,记忆和再学习这两个过程都有相同的形式:回答问题,直到错误数量达到零为止。
> 4. 在阶段 A(2 月 25 日 - 3 月 16 日),对五页中的每一页分别间隔 2,4,6,8 和 10 天进行第三次重复。这些重复后观察到的知识损失分别为 0,0,0,1,17%。选择七天间隔来近似分隔第二和第三重复的第二准最佳重复间隔。
> 5. 在阶段B(3 月 20 日 - 4 月 13 日)中,第三次重复是在七天间隔之后进行的,而第四次重复分别在 6,8,11,13,16 天内对五页中的每一页进行。观察到的知识损失总计为 3,0,0,0,1%。选择 16 天间隔来近似第三准最佳间隔。注:从科学上讲,用第三个间隔的更长变体重复阶段 B 会更有效,因为即使在所选间隔中最长的间隔之后,知识损失也很少;然而,那时我太渴望看到进一步步骤的结果,花时间重复看起来足够成功的阶段 B(即,导致良好的保留)。
> 6. 在C阶段(4 月 20 日 - 6 月 21 日),在间隔7天之后进行第三次重复,在间隔 16 天之后进行第四次重复,在间隔 20 天、24 天、28 天、33 天和 38 天之后进行第五次重复。观察到的知识损失为 0,3,5,3,0%。阶段 C 在第五次重复(5 月 31 日 - 8 月 24 日)之前重复了更长的时间间隔。间期和记忆损失分别为:32-8%,35-8%,39-17%,44-20%,51%-51% 和 60-20%。选择 35 天的间隔来近似第四准最佳间隔。
>
> 不难注意到,所描述的实验的每个阶段花费的时间大约是前一个阶段的两倍。可能需要几年时间来建立前十个准最佳重复间隔。实际上,我在接下来的几年里继续进行这类实验,以获得对记忆知识的最佳间隔重复过程的更深层次的理解。然而,在那时,我决定将这些发现应用于我日常的学习过程中。
>
1985 年 7 月 31 日,我已经能感觉到实验的结果了。我开始用纸上的 Supermemo 来学习人类生物学。那一天是提名 Supermemo 生日和间隔重复生日的最佳日期。
## 1985 年 7 月 31 日的事件
1985 年 7 月 31 日,Supermemo 诞生了。我从我的间隔重复实验中得到的大部分数据都是可用的。作为一个热心的修行者,我没有等到实验结束。我想尽快开始学习。在人类生物学中建立了大量的笔记之后,我开始将这些笔记转换为特殊记忆测试格式(SMT 是 Supermemo 的原始名称,并且间隔重复)。

> **图:**特殊记忆测试格式中的人类生物学开始于1985年7月31日(即Supermemo的生日)
我的计算告诉我,以每天 20 分钟的速度,我需要 537 天来处理我的笔记,并在 1987 年 1 月之前完成这项工作。我还计算出测试的每一页可能会花费我 2 个小时的生命。尽管 Supermemo 的所有承诺和速度,但这种认识还是相当痛苦的。大学里的学习速度对于人类的记忆能力来说太快了。现在我可以学得更快更好,我也意识到我甚至不会涵盖我认为可能的一小部分。学校的数量和速度毫无意义。同一天,我发现波兰共产党政府取消了微型计算机的进口关税。这将使在某种程度上在波兰购买一台计算机成为可能。这为 2.5 年后开发的 DOS 版 Supermemo开辟了一条道路。
同样在 7 月 31 日,我注意到,如果假期可以永远持续下去,我将在学习上取得更大的成就,甚至在生活中取得更大的成就。上学真是浪费时间。然而,征兵的威胁让我坚持了下来。我会走上一条让我再上 5 年大学的道路。然而,大部分时间都花在了 Supermemo上,我没有什么遗憾。
我的间隔重复实验于 1985 年 8 月 24 日结束。我也开始学习英语词汇。到那一天,我设法把我的大部分生化材料写成页,供 Supermemo 复习。
注:我的硕士论文错误地将 1985 年 10 月 1 日作为我开始学习人类生物学的日子(而不是上图中看到的 7 月 31 日)。1985 年 10 月 1 日实际上是我计算机科学大学的第一天,在其他方面并不引人注目。随着大学的开始,我的学习时间和学习的精力被戏剧性地削减了。矛盾的是,开学似乎总是预示着良好学习的结束。
## 第一个间隔重复算法:算法 SM-0,1985 年 8 月 25 日
作为我间隔重复实验的结果,我能够制定出不需要计算机的第一个间隔重复算法。所有的学习都必须在纸上完成。我在 1985 年没有电脑。我是在 1986 年才得到我的第一台微型计算机,ZX Spectrum。Supermemo 不得不等待更长的时间。1987 年,我得到了我的第一台带有软盘驱动器的计算机,Amstrad PC 1512。
我经常被问到这个简单的问题:“在一个持续了 6 个月的实验之后,你如何制定 Supermemo?你如何预测 20 年后会发生什么?”
关于最佳间隔长度的第一个实验得出的结论使预测连续重复间隔的最可能长度成为可能,而无需实际测量超过几周的保留率!简而言之,可以用下面的推理来说明这一点。如果研究的头几个月产生了以下最佳间隔:1,2,4,8,16 和 32 天,你可以有信心地希望连续的间隔会增加到2倍。
> 存档警告:为什么使用文字存档?
>
> 本文是 Piotr Wozniak 的“*学习的优化*”(1990)的一部分
>
> **算法 SM-0 在没有计算机的间隔重复中使用(1985 年 8 月 25 日)**
>
> 1. 将知识分成尽可能小的问答项目。
>
> 2. 将项目关联到包含 20 - 40 个元素的组中。这些组后来称为页面。
>
> 3. 使用以下间隔(天)重复整个页面:
> I(1)= 1 天
>
> I(2)= 7 天
>
> I(3)= 16 天
>
> I(4)= 35 天
>
> for i>4: I(i):=I(i-1)*2
>
> 这里:
>
> - I(i) 是第i次重复后使用的间隔
>
> 4. 将 35 天间隔后忘记的所有项目复制到新创建的页面中(不从以前使用的页面中删除)。这些新页面将以与首次学习项目的页面相同的方式重复
>
> 注意,假设第五次重复后的间隔在随后的重复中增加两次。这个事实是基于直觉而不是实验。在使用 SM-0 算法的两年中,收集了足够的数据来确认这一假设的合理准确性。
>
直到今天,我听说有些人使用甚至更喜欢纸质版的 Supermemo。以下是 1992 年的描述。
请注意,间隔应该增加两倍的直觉与学习理论一样古老。1932 年,C.A.Mace 在他的“学习心理学”一书中暗示了有效的学习方法。他提到“积极的排练”和“重复的修改”,应该以逐渐增加的间隔,大约“一天、两天、四天、八天等的间隔”。这一命题后来被其他作者采纳。其中包括 Paul Pimsleur 和 Tony Buzan,他们都提出了自己的直觉,涉及非常短的间隔(以分钟为单位)或“最终重复”(几个月后)。所有这些想法都没有很好地渗透到学习实践中。只有计算机应用程序才能在不研究方法论的情况下有效地开始学习。
直观的间隔倍增因子 2 也在研究记忆进化优化的可能性以响应环境的统计属性的上下文中出现:“**记忆被优化以满足环境的概率属性**”
尽管它很简单,但在我的硕士论文中,我毫不犹豫地把我的新方法称为“革命性的”:
> 存档警告:为什么使用文字存档?
>
> 本文是 Piotr Wozniak 的“*学习的优化*”(1990)的一部分
>
> 虽然学习速率可能看起来并不惊人,但与我以前的方法相比,算法 SM-0 是革命性的,原因有两个:
>
> - 随着时间的推移,知识保留增加而不是减少(就像间歇性学习的情况一样)。
> - 长期来看,习得率几乎保持不变(在间歇性学习的情况下,习得率将随着时间的推移而大幅下降)
>
> [...]
>
> 这是我第一次能够调和高度的知识保留与不频繁的重复,结果导致记忆的知识量稳步增加,而不必增加时间负荷!
>
> 80% 的保留率很容易实现,甚至可以通过缩短重复间隔来增加。然而,这将涉及更频繁的重复,因此,增加了时间负荷。假设的重复间隔在保留和负荷之间提供了令人满意的折衷。
>
> [...]
>
> 算法 SM-0 的下一个重大改进是在 1987 年应用计算机监控学习过程之后才出现的。同时,我在新的英语和生物数据库中分别积累了大约 7190 条和 2817 条。在每个数据库每天估计工作时间为 12 分钟的情况下,平均知识获取速率分别为 260 和 110 项/年/分钟,而知识保留率最差可达 80%。
>
## 从十年的角度看 Supermemo 的诞生
在 Supermemo 诞生十年后,它在波兰变得相当有名。以下是 J. Kowalski 在 1994 年重述的故事:
> 1982 年,波兹南亚当·米奇维茨大学(Adam Mickiewicz University Of Poznan)20 岁的分子生物学学生 Piotr Wozniak 对自己无法在大脑中保留新学到的知识感到相当沮丧。这指的是生物化学、生理学、化学和英语的大量材料,要想在分子生物学中取得成功,就应该掌握这些材料。以更系统的方式解决遗忘问题的主要动机之一是 Wozniak 所做的一个简单的计算,这表明通过继续使用他的标准方法掌握英语,他需要 120 年才能掌握所有重要的词汇。这不仅促使 Wozniak 致力于学习方法,而且使他成为一种语言为所有人的思想的坚定倡导者(记住人类在翻译和学习语言上花费的时间和金钱)。最初,Wozniak 不断增加他想要记住的事实和数字的笔记。没过多久就发现遗忘需要频繁的重复,需要一种系统的方法来管理所有新收集和记忆的知识。Wozniak 凭借明显的直觉,试图测量在不同的重复间隔后知识的保留情况,并在 1985 年制定了第一个 Supermemo 大纲,这还不需要计算机。到 1987 年,Wozniak ,当时是计算机科学的大二学生,对他的方法的有效性感到非常惊讶,并决定将其作为一个简单的计算机程序来实现。这个计划的有效性似乎远远超出了他的预期。这引发了 Wozniak 与在波兹南科技大学和亚当·米基维奇大学的同事之间令人兴奋的科学交流。他所在系的十几名学生扮演了小白鼠的角色,记忆了数千个项目,提供了持续不断的数据流和批判性反馈。来自医学研究院的 Gorzelańczyk 博士帮助建立了记忆形成的分子模型,并对突触中发生的现象进行了建模。生物聚合物生物化学系的 Makalowski 博士对优化记忆的进化方面的分析做出了贡献(NB:他也是建议注册 Supermemo for Software for Europe 的人)。Janusz Murakowski,物理学硕士,目前在特拉华大学攻读博士课程,帮助 Wozniak 解决与神经细胞中动作电位传输期间间歇学习模型和离子电流模拟相关的数学问题。以 Zbigniew Kierzkowski 教授为代表的十几位即将上任的学术教师帮助 Wozniak 将他的研究计划定制为一个目标:将 Supermemo 的所有方面结合在一个凝聚力的理论中,该理论将涵盖 Supermemo 的分子、进化、行为、心理甚至社会方面。Wozniak 声称已经发现了至少几个重要的从未发表过的记忆属性,他打算通过在美国获得神经科学博士学位来巩固他的理论。与计算机科学硕士 Krzysztof Biedalak 进行了长达数小时的讨论,使他们都选择了另一种方式:努力实现让世界各地的学生了解 SuperMemo 的愿景
- CONTRIBUTING
- 我永远不会送我的孩子去学校
- 01.前言
- 02.箴言
- 03.脑科学
- 04.学习内驱力
- 05.学校教育对学习内驱力的影响
- 06.学习内驱力和奖励
- 07.学习内驱力与习得性无助
- 08.教育抵消进化
- 09.毒性记忆
- 10.为什么学校会失败
- 11.最佳推动区
- 12.自然创造力周期
- 13.大脑进化
- 14.婴儿管理
- 15.婴儿的大脑怎样不起作用
- 16.童年失忆症
- 17.幼儿园的苦难
- 18.压力适应力
- 19.童年的激情
- 20.为什么孩子们讨厌学校
- 21.爬山类比
- 22.术语表
- 23.参考文献
- 24.拓展阅读
- 25.摘要
- 间隔重复的历史
- 01.前言
- 02.1985 SuperMemo 的诞生
- 03.1986 SuperMemo 的第一步
- 04.1987 DOS 上的 SuperMemo 1.0
- 05.1988 记忆的两个组成部分
- 06.1989 SuperMemo 适应用户的记忆
- 07.1990 记忆的通用公式
- 08.1991 采用遗忘曲线
- 09.1994 遗忘的指数性质
- 10.1995 SuperMemo 多媒体
- 11.1997 采用神经网络
- 12.1999 选择名称——间隔重复
- 13.2005 稳定性增长函数
- 14.2014 SM-17 算法
- 15.间隔重复的指数发展
- 16.记忆研究的摘要
- 17.剖析成功与失败
- 18.尾声