
# 十二、分布式 TensorFlow 和云深度学习
在本章中,我们将讨论使用分布式 TensorFlow 和云深度学习。 我们将为您提供一些秘籍:
* 使用 TensorFlow 和 GPU
* 使用分布式 TensorFlow:多个 GPU 和一个 CPU
* 使用分布式 TensorFlow:多台服务器
* 训练分布式 TensorFlow MNIST 分类器
* 使用 TensorFlow Serving 和 Docker
* 使用 Compute Engine 在 Google Cloud(GCP)上运行分布式 TensorFlow
* 在 Google CloudML 上运行分布式 TensorFlow
* 在 Microsoft Azure 上运行分布式 TensorFlow
* 在 Amazon AWS 上运行分布式 TensorFlow
# 介绍
每个 TensorFlow 计算均以图描述。 这允许在结构和操作的放置方面具有自然的灵活性,可以在计算的分布式节点之间拆分操作。 该图可以拆分为多个子图,这些子图分配给服务器集群中的不同节点。
我强烈建议读者看一看[大型分布式深度网络](https://research.google.com/archive/large_deep_networks_nips2012.html)(Jeffrey Dean,Greg S.Corrado,Rajat Monga,Kai Chen,Matthieu Devin,Quoc V.Le,Mark Z.Mao,Marc'Aurelio Ranzato,Andrew Senior ,Paul Tucker,Ke Yang 和 Andrew Y. Ng。 NIPS,2012 年)
本文的一项关键结果是证明可以运行分布式**随机梯度下降**(**SGD**),其中多个节点在数据碎片上并行工作,并且通过将更新发送到参数服务器,来实现梯度的独立和异步更新。 引用论文摘要:
我们的实验揭示了关于大规模非凸优化的几个令人惊讶的结果。 首先,异步 SGD 很少用于非凸问题,对于训练深度网络非常有效,特别是与 Adagrad 自适应学习率结合使用时。
下图取自论文本身,很好地说明了这一点:
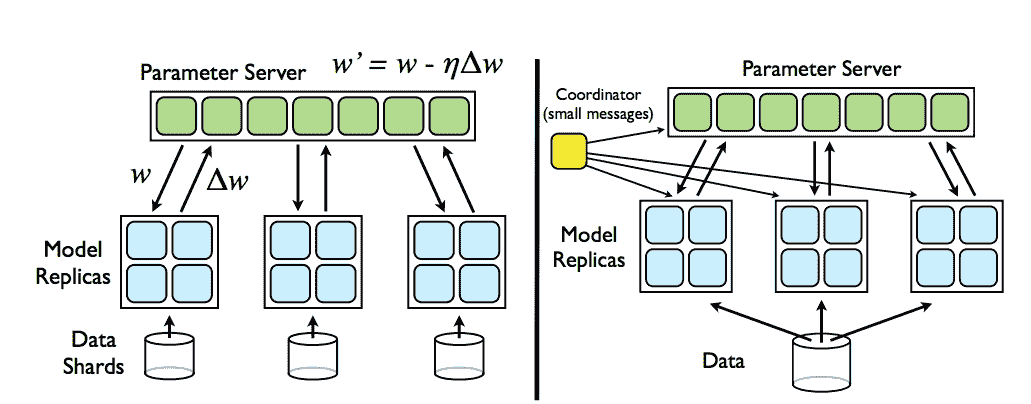
[来自参数服务器的分布式梯度下降示例](https://research.google.com/archive/large_deep_networks_nips2012.html)
您应该阅读的另一份文档是白皮书[《TensorFlow:异构分布式系统上的大规模机器学习》](http://download.tensorflow.org/paper/whitepaper2015.pdf)(MartínAbadi 等人,2015 年 11 月)
考虑其中包含的一些示例,我们可以在下面的图片的左侧看到 TensorFlow 代码的片段,然后将其表示为右侧的图形:

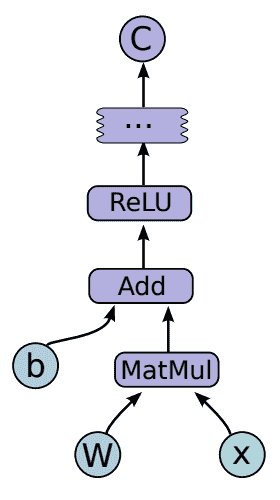
[TensorFlow 图的示例](http://download.tensorflow.org/paper/whitepaper2015.pdf)
通过进行本地计算并在需要时透明地将远程通信节点添加到图,可以在多个节点之间划分图。 下图中对此作了很好的解释,该图仍取自前面提到的论文:
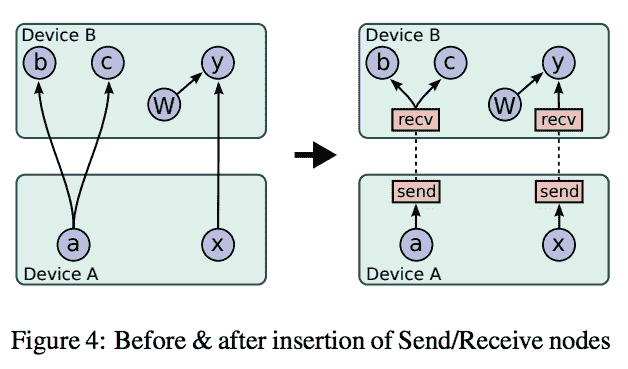
[摘自以下内容的分布式 TensorFlow 图计算示例](http://download.tensorflow.org/paper/whitepaper2015.pdf)
可以通过集中方式(下图的左侧)或分布式方式(右侧)来计算梯度下降和所有主要的优化器算法。 后者涉及一个主进程,该主进程与调配 GPU 和 CPU 的多个工作器进行对话:
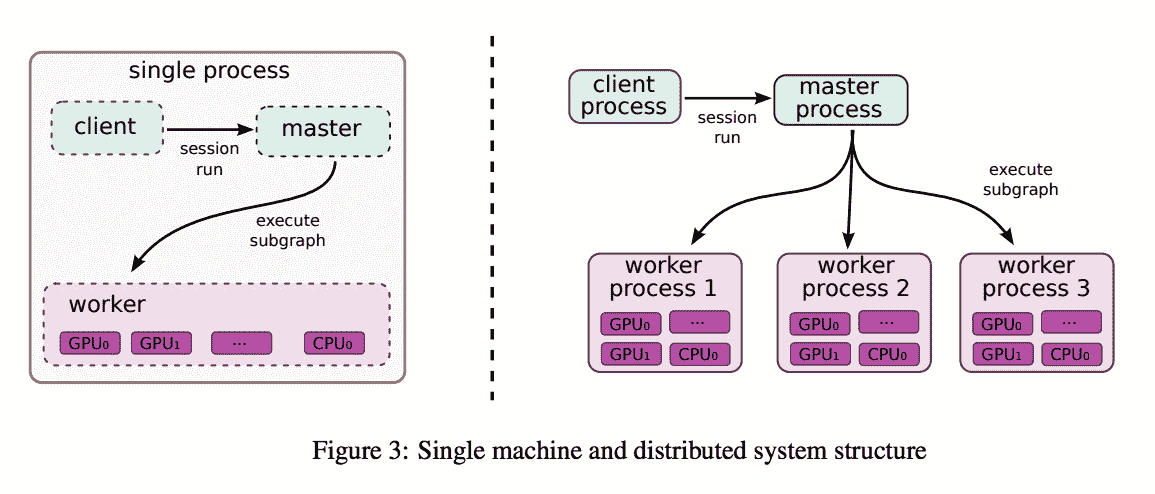
[摘自以下内容的单机和分布式系统结构示例和分布式 TensorFlow 图计算示例](http://download.tensorflow.org/paper/whitepaper2015.pdf)
分布式计算既可以是同步的(所有工作程序都在同时更新分片数据上的梯度),也可以是异步的(更新没有同时发生)。 后者通常可以实现更高的可伸缩性,并且在收敛到最佳解决方案方面,较大的图计算仍然可以很好地工作。 同样,这些图片均来自 TensorFlow 白皮书,如果您想了解更多信息,我强烈建议有兴趣的读者阅读本文:
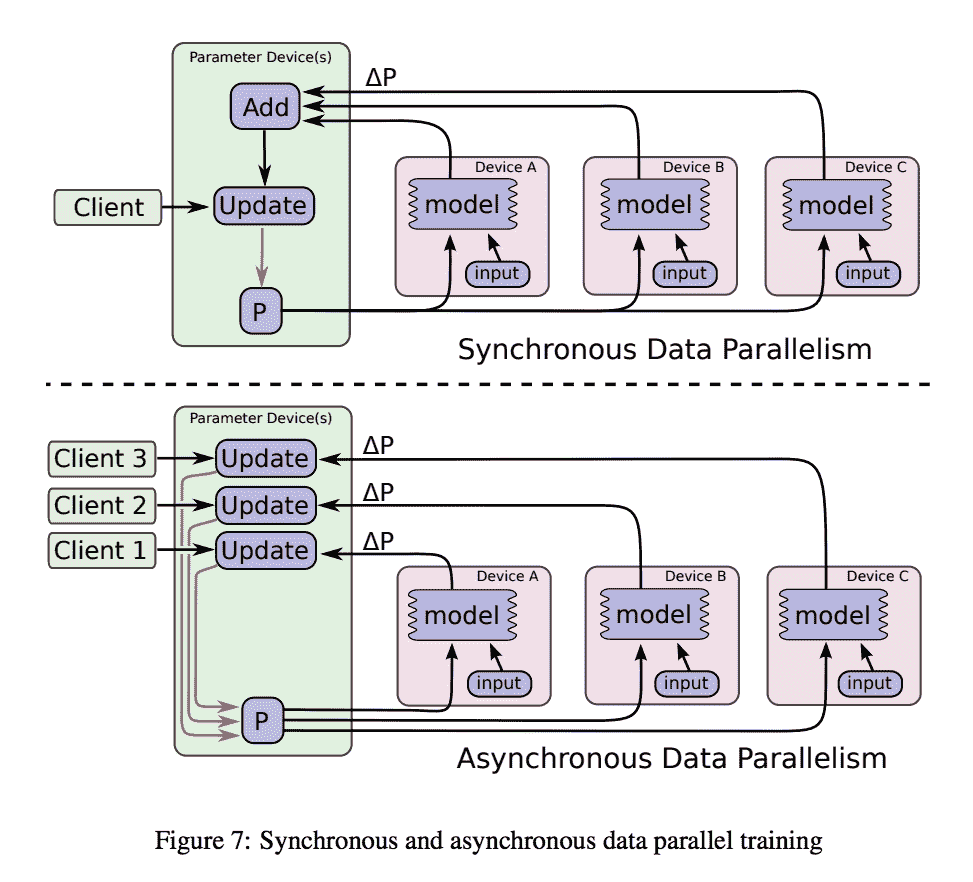
同步和异步数据并行训练的示例
# 使用 TensorFlow 和 GPU
在本秘籍中,我们将学习如何在 GPU 上使用 TensorFlow:执行的操作是在 CPU 或 GPU 上的简单矩阵乘法。
# 准备
第一步是安装支持 GPU 的 TensorFlow 版本。 [正式的 TensorFlow 安装说明是您的起点](https://www.tensorflow.org/)。 请记住,您需要一个通过 CUDA 或 CuDNN 支持 GPU 的环境。
# 操作步骤
我们按以下步骤进行:
1. 首先导入一些模块
```py
import sys
import numpy as np
import tensorflow as tf
from datetime import datetime
```
2. 从命令行获取要使用的处理单元的类型(`"gpu"`或`"cpu"`)
```py
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpu
shape = (int(sys.argv[2]), int(sys.argv[2]))
if device_name == "gpu":
device_name = "/gpu:0"
else:
device_name = "/cpu:0"
```
3. 在 GPU 或 CPU 上执行矩阵乘法。 按键说明与`tf.device(device_name)`一起使用。 它创建一个新的上下文管理器,告诉 TensorFlow 在 GPU 或 CPU 上执行这些操作
```py
with tf.device(device_name):
random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1)
dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix))
sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session:
result = session.run(sum_operation)
print(result)
```
4.打印一些调试时间,只是为了验证 CPU 和 GPU 有什么区别
```py
print("Shape:", shape, "Device:", device_name)
print("Time taken:", datetime.now() - startTime)
```
# 工作原理
本秘籍说明了如何将 TensorFlow 计算分配给 CPU 或 GPU。 该代码非常简单,它将用作下一个秘籍的基础。
# 使用分布式 TensorFlow:多个 GPU 和一个 CPU
我们将展示一个数据并行化的示例,其中数据被拆分到多个 GPU 中
# 准备
此秘籍的灵感来自尼尔·特内霍尔茨(Neil Tenenholtz)撰写的一篇不错的博客文章,[该文章可在线获取](https://clindatsci.com/blog/2017/5/31/distributed-tensorflow)
# 操作步骤
我们按以下步骤进行:
1. 考虑这段在单个 GPU 上运行矩阵乘法的代码。
```py
# single GPU (baseline)
import tensorflow as tf
# place the initial data on the cpu
with tf.device('/cpu:0'):
input_data = tf.Variable([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
[10., 11., 12.]])
b = tf.Variable([[1.], [1.], [2.]])
# compute the result on the 0th gpu
with tf.device('/gpu:0'):
output = tf.matmul(input_data, b)
# create a session and run
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print sess.run(output)
```
2. 如图 2 所示,在 2 个不同的 GPU 之间使用代码复制对代码进行分区。 请注意,CPU 充当主节点来分发图并收集最终结果。
```py
# in-graph replication
import tensorflow as tf
num_gpus = 2
# place the initial data on the cpu
with tf.device('/cpu:0'):
input_data = tf.Variable([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
[10., 11., 12.]])
b = tf.Variable([[1.], [1.], [2.]])
# split the data into chunks for each gpu
inputs = tf.split(input_data, num_gpus)
outputs = []
# loop over available gpus and pass input data
for i in range(num_gpus):
with tf.device('/gpu:'+str(i)):
outputs.append(tf.matmul(inputs[i], b))
# merge the results of the devices
with tf.device('/cpu:0'):
output = tf.concat(outputs, axis=0)
# create a session and run
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print sess.run(output)
```
# 工作原理
这是一个非常简单的方法,其中通过将 CPU 用作主对象并将其分配到两个用作分布式工作程序的 GPU,将图分为两部分。 计算结果被收集回 CPU。
# 使用分布式 TensorFlow:多台服务器
在本秘籍中,我们将学习如何在多个服务器之间分配 TensorFlow 计算。 关键假设是工作程序和参数服务器的代码都相同。 因此,每个计算节点的角色都传递给命令行参数。
# 准备
同样,此秘籍的灵感来自尼尔·特纳霍尔茨(Neil Tenenholtz)撰写的一篇不错的博客文章,[该文章可在线获取](https://clindatsci.com/blog/2017/5/31/distributed-tensorflow)
# 操作步骤
我们按以下步骤进行:
1. 考虑这段代码,在此我们指定集群架构,其中一个主服务器运行在`192.168.1.1:1111`上,两个工作服务器分别运行在`192.168.1.2:1111`和`192.168.1.3:1111`上。
```py
import sys
import tensorflow as tf
# specify the cluster's architecture
cluster = tf.train.ClusterSpec({'ps': ['192.168.1.1:1111'],
'worker': ['192.168.1.2:1111',
'192.168.1.3:1111']
})
```
2. 请注意,代码是在多台机器上复制的,因此了解当前执行节点的作用很重要。 我们从命令行获得此信息。 机器可以是工作程序,也可以是参数服务器(`ps`)。
```py
# parse command-line to specify machine
job_type = sys.argv[1] # job type: "worker" or "ps"
task_idx = sys.argv[2] # index job in the worker or ps list
# as defined in the ClusterSpec
```
3. 在给定群集的情况下运行训练服务器,我们为每个计算赋予一个角色(工作者或`ps`)和一个 ID。
```py
# create TensorFlow Server. This is how the machines communicate.
server = tf.train.Server(cluster, job_name=job_type, task_index=task_idx)
```
4. 根据特定计算节点的角色,计算是不同的:
* 如果角色是参数服务器,则条件是要加入服务器。 请注意,在这种情况下,没有代码要执行,因为工作进程将不断推送更新,并且参数服务器唯一要做的就是等待。
* 否则,工作程序代码将在集群中的特定设备上执行。 这部分代码类似于在一台机器上执行的代码,在该机器上我们首先构建模型,然后在本地对其进行训练。 请注意,所有工作分配和更新结果的收集都是由 Tensoflow 透明完成的。 请注意,TensorFlow 提供了方便的`tf.train.replica_device_setter`,可自动将操作分配给设备。
```py
# parameter server is updated by remote clients.
# will not proceed beyond this if statement.
if job_type == 'ps':
server.join()
else:
# workers only
with tf.device(tf.train.replica_device_setter(
worker_device='/job:worker/task:'+task_idx,
cluster=cluster)):
# build your model here as if you only were using a single machine
with tf.Session(server.target):
# train your model here
```
# 工作原理
在本秘籍中,我们已经看到了如何创建具有多个计算节点的集群。 节点既可以扮演参数服务器的角色,也可以扮演工作者的角色。
在这两种情况下,根据从命令行收集的参数,执行的代码相同,但是代码的执行不同。 参数服务器仅需要等待,直到工作器发送更新。 请注意,`tf.train.replica_device_setter(..)`的作用是将操作自动分配给可用设备,而`tf.train.ClusterSpec(..)`则用于集群设置。
# 更多
可以在[这个页面](https://github.com/ischlag/distributed-tensorflow-example/blob/master/example.py)在线获取针对 MNIST 的分布式训练的示例。
此外,请注意,出于效率考虑,您可以决定拥有多个参数服务器。 使用参数,服务器可以提供更好的网络利用率,并且可以将模型扩展到更多并行计算机。 可以分配多个参数服务器。 有兴趣的读者可以看看[这里](https://www.tensorflow.org/deploy/distributed)
# 训练分布式 TensorFlow MNIST 分类器
此秘籍用于以分布式方式训练完整的 MNIST 分类器。 该秘籍的灵感来自[这个页面](http://ischlag.github.io/2016/06/12/async-distributed-tensorflow/)中的博客文章,[此处提供了在 TensorFlow 1.2 上运行的代码](https://github.com/ischlag/distributed-tensorflow-example)
# 准备
此秘籍基于上一个秘籍。 因此,按顺序阅读它们可能会很方便。
# 操作步骤
我们按以下步骤进行:
1. 导入一些标准模块并定义运行计算的 TensorFlow 集群。 然后为特定任务启动服务器
```py
import tensorflow as tf
import sys
import time
# cluster specification
parameter_servers = ["pc-01:2222"]
workers = [ "pc-02:2222",
"pc-03:2222",
"pc-04:2222"]
cluster = tf.train.ClusterSpec({"ps":parameter_servers, "worker":workers})
# input flags
tf.app.flags.DEFINE_string("job_name", "", "Either 'ps' or 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")FLAGS = tf.app.flags.FLAGS
# start a server for a specific task
server = tf.train.Server(
cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
```
2. 读取 MNIST 数据并定义用于训练的超参数
```py
# config
batch_size = 100
learning_rate = 0.0005
training_epochs = 20
logs_path = "/tmp/mnist/1"
# load mnist data set
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
```
3. 检查您的角色是参数服务器还是工作器。 如果工作器随后定义了一个简单的密集神经网络,则定义一个优化器以及用于评估分类器的度量(例如准确率)。
```py
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# count the number of updates
global_step = tf.get_variable( 'global_step', [], initializer = tf.constant_initializer(0),
trainable = False)
# input images
with tf.name_scope('input'):
# None -> batch size can be any size, 784 -> flattened mnist image
x = tf.placeholder(tf.float32, shape=[None, 784], name="x-input")
# target 10 output classes
y_ = tf.placeholder(tf.float32, shape=[None, 10], name="y-input")
# model parameters will change during training so we use tf.Variable
tf.set_random_seed(1)
with tf.name_scope("weights"):
W1 = tf.Variable(tf.random_normal([784, 100]))
W2 = tf.Variable(tf.random_normal([100, 10]))
# bias
with tf.name_scope("biases"):
b1 = tf.Variable(tf.zeros([100]))
b2 = tf.Variable(tf.zeros([10]))
# implement model
with tf.name_scope("softmax"):
# y is our prediction
z2 = tf.add(tf.matmul(x,W1),b1)
a2 = tf.nn.sigmoid(z2)
z3 = tf.add(tf.matmul(a2,W2),b2)
y = tf.nn.softmax(z3)
# specify cost function
with tf.name_scope('cross_entropy'):
# this is our cost
cross_entropy = tf.reduce_mean(
-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# specify optimizer
with tf.name_scope('train'):
# optimizer is an "operation" which we can execute in a session
grad_op = tf.train.GradientDescentOptimizer(learning_rate)
train_op = grad_op.minimize(cross_entropy, global_step=global_step)
with tf.name_scope('Accuracy'):
# accuracy
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# create a summary for our cost and accuracy
tf.summary.scalar("cost", cross_entropy)
tf.summary.scalar("accuracy", accuracy)
# merge all summaries into a single "operation" which we can execute in a session
summary_op = tf.summary.merge_all()
init_op = tf.global_variables_initializer()
print("Variables initialized ...")
```
4. 启动一个主管,该主管充当分布式设置的首席计算机。 首要的是负责管理集群其余所有部分的工作机。 会话由负责人维护,关键指令为`sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0))`。 同样,使用`prepare_or_wait_for_session(server.target)`,主管将等待模型准备就绪可以使用。 请注意,每个工作器将处理不同的批量模型,然后最终模型可用于主管。
```py
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
begin_time = time.time()
frequency = 100
with sv.prepare_or_wait_for_session(server.target) as sess:
# create log writer object (this will log on every machine)
writer = tf.summary.FileWriter(logs_path, graph=tf.get_default_graph())
# perform training cycles
start_time = time.time()
for epoch in range(training_epochs):
# number of batches in one epoch
batch_count = int(mnist.train.num_examples/batch_size)
count = 0
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# perform the operations we defined earlier on batch
_, cost, summary, step = sess.run(
[train_op, cross_entropy, summary_op, global_step],
feed_dict={x: batch_x, y_: batch_y})
writer.add_summary(summary, step)
count += 1
if count % frequency == 0 or i+1 == batch_count:
elapsed_time = time.time() - start_time
start_time = time.time()
print("Step: %d," % (step+1),
" Epoch: %2d," % (epoch+1), " Batch: %3d of %3d," % (i+1, batch_count),
" Cost: %.4f," % cost,
"AvgTime:%3.2fms" % float(elapsed_time*1000/frequency))
count = 0
print("Test-Accuracy: %2.2f" % sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
print("Total Time: %3.2fs" % float(time.time() - begin_time))
print("Final Cost: %.4f" % cost)
sv.stop()
print("done")
```
# 工作原理
本秘籍描述了分布式 MNIST 分类器的示例。 在此示例中,TensorFlow 允许我们定义三台机器的集群。 一台充当参数服务器,另外两台机器用作工作器,负责处理不同批次的训练数据。
# 使用 TensorFlow Serving 和 Docker
在本秘籍中,我们将展示如何为 TensorFlow Serving 运行 Docker 容器,这是一组组件以导出经过训练的 TensorFlow 模型并使用标准`tensorflow_model_server`为其提供服务。 TensorFlow Serving 服务器发现新导出的模型并运行 gRPC 服务来为其服务。
# 准备
我们将使用 Docker,并假设您熟悉该系统。 如果没有,[请确保查看并安装](https://www.docker.com/)。 我们要做的是构建 TF 服务版本。
# 操作步骤
这是我们进行秘籍的方法:
1. 从[这里](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/tools/docker/Dockerfile.devel)下载`Dockerfile.devel`
2. 通过运行以下来构建容器
```py
docker build --pull -t $USER/tensorflow-serving-devel -f Dockerfile.devel
```
3. 运行容器
```py
docker run -it $USER/tensorflow-serving-devel
```
4. 克隆 TensorFlow 服务,配置和测试服务器
```py
git clone --recurse-submodules https://github.com/tensorflow/serving
cd serving/tensorflow
./configure
cd ..
bazel test tensorflow_serving/...
```
5. 现在,让我们看一个保存模型的示例,以便服务器可以保存它。 此步骤的灵感来自[用于构建 MNIST 训练器和服务模型的示例](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/example/mnist_saved_model.py)。 第一步是将构建器导入为`saved_model_builder`。 然后,大部分工作由`SavedModelBuilder()`完成,该工作将已训练模型的*快照*保存到可靠的存储中。 请注意,此处`export_path`是`/tmp/mnist_model/`
```py
from tensorflow.python.saved_model import builder as saved_model_builder
...
export_path_base = sys.argv[-1]
export_path = os.path.join(
compat.as_bytes(export_path_base),
compat.as_bytes(str(FLAGS.model_version)))
print 'Exporting trained model to', export_path
builder = saved_model_builder.SavedModelBuilder(export_path)
builder.add_meta_graph_and_variables(
sess, [tag_constants.SERVING],
signature_def_map={
'predict_images':
prediction_signature,
signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
classification_signature,
},
legacy_init_op=legacy_init_op)
builder.save()
```
6. 然后可以通过简单的命令为模型提供服务
```py
tensorflow_model_server --port=9000 --model_name=mnist --model_base_path=/tmp/mnist_model/
```
# 工作原理
Google 在 2016 年 2 月发布了 [TensorFlow Serving](https://www.tensorflow.org/serving/),这是一种针对机器学习模型的高性能服务系统,专为生产环境而设计。 截至 2017 年 8 月,谷歌内部有 800 多个使用 TensorFlow Serving 的项目投入生产。
# 更多
TensoFlow Serving 是一款非常通用的软件,在本秘籍中,我们只是初步探究了潜在用途。 如果您有兴趣进一步了解高级功能。 例如大批量运行或动态加载模型,则应查看[这个页面](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/serving_advanced.md)
# 使用 Compute Engine 在 Google Cloud(GCP)上运行分布式 TensorFlow
在本秘籍中,我们将学习如何在 Google Cloud(GCP)上使用 Google Tensorflow。 我们将要审查的示例是经典 MNIST。
# 准备
看看 GCP 在 [GoogleCloud](https://cloud.google.com/) 中的工作方式会很好。 请注意,GCP 提供 300 美元的免费赠金,以开始使用任何 GCP 产品。 此外,在免费试用期间和之后,某些产品针对符合条件的客户可以免费使用。 (优惠如有更改,请参见[这个页面](https://cloud.google.com/free/)。
# 操作步骤
这是我们进行秘籍的方法:
1. [通过网络控制台](https://pantheon.google.com/cloud-resource-manager)创建一个新的 Google Cloud 项目。

单击创建项目时,将显示以下屏幕:
2. 通过选择控制台左侧栏上的相关语音,为该项目启用计费。 然后为该项目启用 Compute Engine 和 Cloud Machine Learning API:

3. 登录到网络 [cloudshell](https://pantheon.google.com/cloudshell/editor)。
4. 从控制台运行以下命令,以配置将在其中执行计算的区域,下载示例代码以及创建用于运行代码的 VM。 最后连接到机器:
```py
gcloud config set compute/zone us-east1-c
gcloud config set project [YOUR_PROJECT_ID]
git clone https://github.com/GoogleCloudPlatform/cloudml-dist-mnist-example
cd cloudml-dist-mnist-example
gcloud compute instances create template-instance \
--image-project ubuntu-os-cloud \
--image-family ubuntu-1604-lts \
--boot-disk-size 10GB \
--machine-type n1-standard-1
gcloud compute ssh template-instance
```
5. 现在,登录到机器后,我们需要通过使用这些命令安装 PIP 和 TensorFlow 来设置环境。
```py
sudo apt-get update
sudo apt-get -y upgrade \
&& sudo apt-get install -y python-pip python-dev
sudo pip install tensorflow
sudo pip install --upgrade tensorflow
```
6. 我们将有多个工作器对 MNIST 数据进行操作,因此最好的方法是创建一个在所有工作器之间共享的存储桶,并在该存储桶中复制 MNIST 数据
```py
BUCKET="mnist-$RANDOM-$RANDOM"
gsutil mb -c regional -l us-east1 gs://${BUCKET}
sudo ./scripts/create_records.py
gsutil cp /tmp/data/train.tfrecords gs://${BUCKET}/data/
gsutil cp /tmp/data/test.tfrecords gs://${BUCKET}/data/
```
7. 现在,我们将创建多个工作程序(`worker-0`,`worker-1`),它们是初始模板实例计算机的克隆。 我们不希望计算机在关闭时删除磁盘,因此这就是我们拥有第一个命令的原因。
```py
gcloud compute instances set-disk-auto-delete template-instance \
--disk template-instance --no-auto-delete
gcloud compute instances delete template-instance
gcloud compute images create template-image \
--source-disk template-instance
gcloud compute instances create \
master-0 worker-0 worker-1 ps-0 \
--image template-image \
--machine-type n1-standard-4 \
--scopes=default,storage-rw
```
8. 最后一步是运行用于分布式训练的计算。
```py
./scripts/start-training.sh gs://${BUCKET}
```
# 工作原理
演示脚本将代码移动到每个 VM 并开始分布式计算。 这两个工作程序在公共存储桶上共享的相同 MNIST 数据上并行运行。 计算结束后,脚本将打印训练后的模型的位置。
# 更多
如果我们不想管理 TensorFlow,那么我们可以决定使用 Google 代表您运行的托管版本。 这是在下一个秘籍中描述的 CloudML 服务。 此外,如果您决定不将 GPU 与 CloudML 一起使用,[那么此 URL 是一个不错的起点](https://cloud.google.com/ml-engine/docs/using-gpus)
# 在 Google CloudML 上运行分布式 TensorFlow
CloudML 是 Google 运行的 Tensorflow 的托管版本。 无需自己运行 TF,您只需使用 CloudML 即可,而无需考虑与基础架构和可伸缩性相关的所有问题。
# 准备
在这里,我们假设您已经创建了一个 Cloud Platform Project,为您的项目启用计费,并启用了 Google Compute Engine 和 Cloud Machine Learning API。 这些步骤类似于先前秘籍中描述的步骤。 此秘籍的灵感来自[这个页面](https://cloud.google.com/ml-engine/docs/distributed-tensorflow-mnist-cloud-datalab)中提供的 MNIST 训练代码。
# 操作步骤
我们继续在 Google CloudML 上运行分布式 TensorFlow:
1. 第一步只是下载示例代码
```py
git clonehttps://github.com/GoogleCloudPlatform/cloudml-dist-mnist-example
cd cloudml-dist-mnist-example
```
2. 然后,我们下载数据并将其保存在 GCP 存储桶中
```py
PROJECT_ID=$(gcloud config list project --format "value(core.project)")
BUCKET="${PROJECT_ID}-ml"
gsutil mb -c regional -l us-central1 gs://${BUCKET}
./scripts/create_records.py
gsutil cp /tmp/data/train.tfrecords gs://${BUCKET}/data/
gsutil cp /tmp/data/test.tfrecords gs://${BUCKET}/data/
```
3. 提交训练工作非常简单:我们可以使用 CloudML 引擎简单地调用训练步骤。 在此示例中,训练人员代码在`us-central1`区域中运行 1000 次迭代。 输入数据是从存储桶中提取的,而输出桶将被提交到其他存储桶中。
```py
JOB_NAME="job_$(date +%Y%m%d_%H%M%S)"
gcloud ml-engine jobs submit training ${JOB_NAME} \
--package-path trainer \
--module-name trainer.task \
--staging-bucket gs://${BUCKET} \
--job-dir gs://${BUCKET}/${JOB_NAME} \
--runtime-version 1.2 \
--region us-central1 \
--config config/config.yaml \
-- \
--data_dir gs://${BUCKET}/data \
--output_dir gs://${BUCKET}/${JOB_NAME} \
--train_steps 10000
```
4. 如果需要,您可以通过访问[这个页面](https://pantheon.google.com/mlengine/)中的 CloudML 控制台来控制训练过程。
5. 训练结束后,就可以直接从 CloudML 服务模型了
```py
MODEL_NAME=MNIST
gcloud ml-engine models create --regions us-central1 ${MODEL_NAME}
VERSION_NAME=v1
ORIGIN=$(gsutil ls gs://${BUCKET}/${JOB_NAME}/export/Servo | tail -1)
gcloud ml-engine versions create \
--origin ${ORIGIN} \
--model ${MODEL_NAME} \
${VERSION_NAME}
gcloud ml-engine versions set-default --model ${MODEL_NAME} ${VERSION_NAME}
```
6. 在线提供模型后,便可以访问服务器并做出预测。 通过使用脚本`make_request.py`创建`request.json`,该脚本从 MNIST 读取数据,执行一次热编码,然后使用格式正确的 json 模式编写功能。
```py
gcloud ml-engine predict --model ${MODEL_NAME} --json-instances request.json
```
# 工作原理
CloudML 是使用 Google 运行的托管版本的 TensorFlow 的便捷解决方案。 除了直接照顾基础设施和运营,还可以直接专注于开发机器学习模型。
# 更多
CloudML 的一项非常酷的功能是能够通过并行运行多个试验来自动调整模型中包含的超参数的能力。 这为您提供了超参数的优化值,从而最大化了模型的预测精度。 如果您有兴趣了解更多信息,那么看看[这里](https://cloud.google.com/ml-engine/docs/hyperparameter-tuning-overview)
# 在 Microsoft Azure 上运行分布式 TensorFlow
Microsoft Azure 提供了一项名为 Batch AI 的服务,该服务使我们能够在 Azure 虚拟机的群集上运行机器学习模型。
# 准备
第一步,我们需要一个 Azure 帐户:如果您还没有 Azure 帐户,则可以[在此处免费创建一个帐户](https://azure.microsoft.com/en-us/services/batch-ai/) 。 Azure 向新用户提供为期 30 天的 200 美元信用额度。 此秘籍将遵循 Microsoft Azure 提供的示例,以使用 TensorFlow 分布式在两个 GPU 上运行 MNIST,相关代码可[在 Github 上获得](https://github.com/Azure/batch-shipyard/tree/master/recipes/TensorFlow-Distributed)
# 操作步骤
我们按以下步骤进行:
1. 第一步是安装 Azure CLI。 可在[此处](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest)获得在不同 OS 平台上安装 Azure CLI 的详细信息。
2. 在创建群集之前,您需要使用命令`az login`登录 Azure。 它将生成一个代码,并为您提供一个网站地址,将要求您在其中验证您的凭据,一旦网站上的所有步骤都结束,将要求您关闭并验证您的 az 凭据。
3. 配置默认位置,创建和配置资源组。
```py
az group create --name myResourceGroup --location eastus
az configure --defaults group=myResourceGroup
az configure --defaults location=eastus
```
4. 接下来,我们将需要使用`az`命令创建存储,并根据您的操作系统设置环境变量,有关环境变量及其值的详细信息,请参见[这里](https://docs.microsoft.com/en-us/azure/batch-ai/quickstart-cli)
5. 下载并提取预处理的 MNIST 数据库
```py
wget "https://batchaisamples.blob.core.windows.net/samples/mnist_dataset_original.zip?st=2017-09-29T18%3A29%3A00Z&se=2099-12-31T08%3A00%3A00Z&sp=rl&sv=2016-05-31&sr=b&sig=Qc1RA3zsXIP4oeioXutkL1PXIrHJO0pHJlppS2rID3I%3D" -O mnist_dataset_original.zip
unzip mnist_dataset_original.zip
```
6. 下载`mnist_replica`
```py
wget "https://raw.githubusercontent.com/Azure/BatchAI/master/recipes/TensorFlow/TensorFlow-GPU-Distributed/mnist_replica.py?token=AcZzrcpJGDHCUzsCyjlWiKVNfBuDdkqwks5Z4dPrwA%3D%3D" -O mnist_replica.py
```
7. 接下来,创建一个 Azure 文件共享,在其中上传下载的 MNIST 数据集和`mnist_replica.py`文件。
```py
az storage share create --name batchaisample
az storage directory create --share-name batchaisample --name mnist_dataset
az storage file upload --share-name batchaisample --source t10k-images-idx3-ubyte.gz --path mnist_dataset
az storage file upload --share-name batchaisample --source t10k-labels-idx1-ubyte.gz --path mnist_dataset
az storage file upload --share-name batchaisample --source train-images-idx3-ubyte.gz --path mnist_dataset
az storage file upload --share-name batchaisample --source train-labels-idx1-ubyte.gz --path mnist_dataset
az storage directory create --share-name batchaisample --name tensorflow_samples
az storage file upload --share-name batchaisample --source mnist_replica.py --path tensorflow_samples
```
8. 现在,我们为该秘籍创建一个集群,该集群由具有 standard_NC6 大小的两个 GPU 节点组成,具有标准的 Ubuntu LTS 或 Ubuntu DVSM。 可以使用 Azure CLI 命令创建群集:
对于 Linux:
```py
az batchai cluster create -n nc6 -i UbuntuDSVM -s Standard_NC6 --min 2 --max 2 --afs-name batchaisample --afs-mount-path external -u $USER -k ~/.ssh/id_rsa.pub
```
对于 Windows:
```py
az batchai cluster create -n nc6 -i UbuntuDSVM -s Standard_NC6 --min 2 --max 2 --afs-name batchaisample --afs-mount-path external -u <user_name> -p <password>
```
9. 下一步是在`job.json`文件中创建作业创建参数:
```py
{
"properties": {
"nodeCount": 2,
"tensorFlowSettings": {
"parameterServerCount": 1,
"workerCount": 2,
"pythonScriptFilePath": "$AZ_BATCHAI_INPUT_SCRIPT/mnist_replica.py",
"masterCommandLineArgs": "--job_name=worker --num_gpus=1 --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX --data_dir=$AZ_BATCHAI_INPUT_DATASET --output_dir=$AZ_BATCHAI_OUTPUT_MODEL",
"workerCommandLineArgs": "--job_name=worker --num_gpus=1 --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX --data_dir=$AZ_BATCHAI_INPUT_DATASET --output_dir=$AZ_BATCHAI_OUTPUT_MODEL",
"parameterServerCommandLineArgs": "--job_name=ps --num_gpus=0 --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX --data_dir=$AZ_BATCHAI_INPUT_DATASET --output_dir=$AZ_BATCHAI_OUTPUT_MODEL"
},
"stdOutErrPathPrefix": "$AZ_BATCHAI_MOUNT_ROOT/external",
"inputDirectories": [{
"id": "DATASET",
"path": "$AZ_BATCHAI_MOUNT_ROOT/external/mnist_dataset"
}, {
"id": "SCRIPT",
"path": "$AZ_BATCHAI_MOUNT_ROOT/external/tensorflow_samples"
}],
"outputDirectories": [{
"id": "MODEL",
"pathPrefix": "$AZ_BATCHAI_MOUNT_ROOT/external",
"pathSuffix": "Models"
}],
"containerSettings": {
"imageSourceRegistry": {
"image": "tensorflow/tensorflow:1.1.0-gpu"
}
}
}
}
```
10. 最后,使用以下命令创建 Batch AI 作业:
```py
az batchai job create -n distibuted_tensorflow --cluster-name nc6 -c job.json
```
# 工作原理
Batch AI 自行管理资源,您只需要指定作业,输入的位置以及存储输出的位置即可。 如果在执行作业期间想要查看结果,则可以使用以下命令:
```py
az batchai job stream-file --job-name myjob --output-directory-id stdouterr --name stderr.txt
```
作业结束后,您可以使用`az batchai job delete`和`az batchai cluster delete`命令删除作业和群集。
# 更多
上面我们学习了如何使用 Azure 命令行工具将 Microsoft Azure Batch AI 用于分布式 TensorFlow。 我们也可以使用 Jupyter 笔记本做同样的事情。 这将涉及设置 Azure Active Directory 并进行新的 App 注册。 [可以在以下链接上获得详细信息](https://docs.microsoft.com/en-us/azure/azure-resource-manager/resource-group-create-service-principal-portal)。
Azure BatchAI 也可以与其他 AI 深度学习库一起使用,我们建议您仔细阅读 BatchAI Github [以获取更多详细信息](https://github.com/Azure/BatchAI)。
# 在 Amazon AWS 上运行分布式 TensorFlow
Amazon AWS 提供了配备 NVIDIA K8 GPU 的 P2.x 机器。 为了能够使用,第一步再次涉及创建一个 Amazon AWS 账户。 如果还没有,[可以使用以下链接创建它](https://portal.aws.amazon.com/billing/signup?nc2=h_ct&redirect_url=https%3A%2F%2Faws.amazon.com%2Fregistration-confirmation#/start)。 登录帐户后,仪表板将如下所示:
您可以看到 Amazon AWS 提供了许多服务,但是在这里,我们担心使用 Amazon AWS 进行深度学习。
GPU 仅在 P2 实例创建中可用,并且默认情况下不可用,要获得此服务,您必须通过 AWS 支持筹集更多资源,一旦获得支持,该支持就会显示在右上角, 您将看到一个按钮,创建案例,选择按钮并进行以下选择:
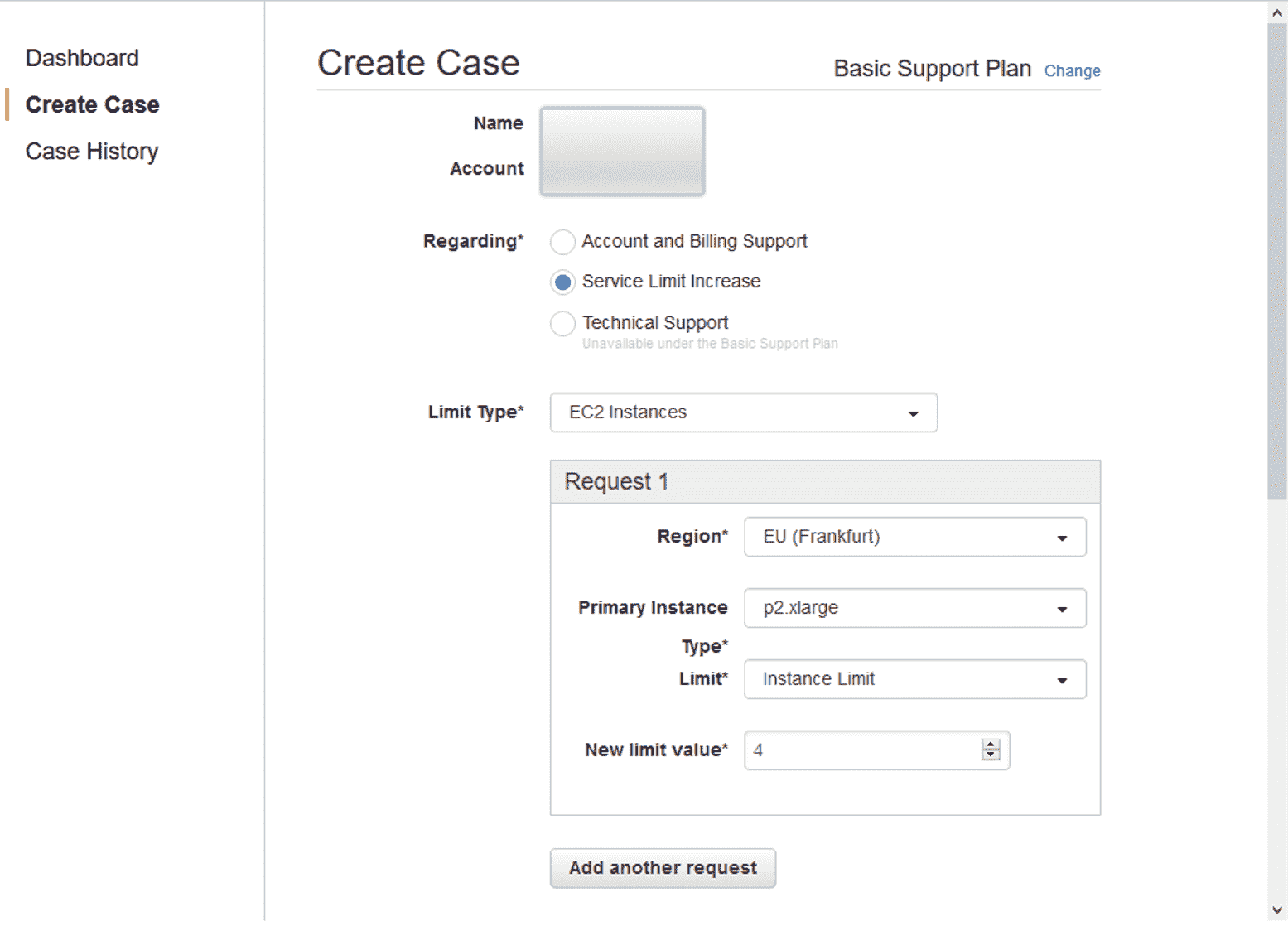
您可以选择提供 p2.xlarge 实例的任何区域。 新的限制值决定了您可以使用的实例的最大数量,请谨慎选择数量,因为该服务不是免费的,并且每小时的费用约为 1 美元。 AWS 大约需要 24 小时才能响应请求。
# 准备
现在您已经可以使用 AWS 账户和 p2.xlarge 实例,现在就可以从 EC2 仪表板创建自己的实例了。 第一步是选择机器映像,到目前为止,Amazon 提供了预装有深度学习库的特殊机器映像,您可以选择 Ubuntu 或 Linux 版本。 接下来,选择 GPU 以计算实例类型。
您可以使用默认参数查看并启动实例,也可以配置设置,选择存储并配置安全组。 配置安全组很重要,默认情况下已设置 SSH 安全组,但是如果要使用 Jupyter 笔记本,则需要为端口 8888 添加自定义安全组,可以选择从中登录的源。 对于实例,有三种可能性:“自定义”,“随处可见”或“我的 IP”:
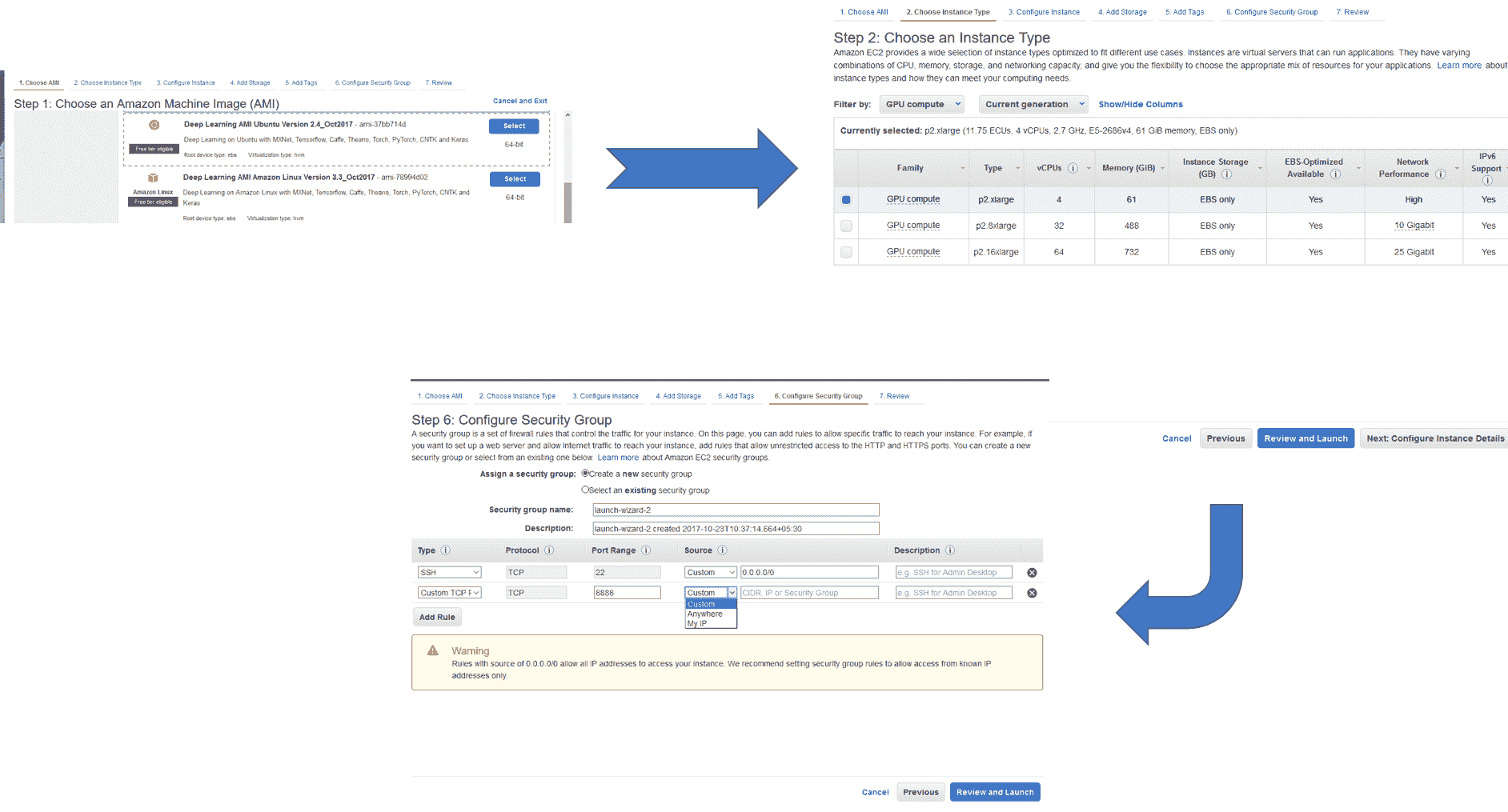
最后,在启动实例时,将要求您创建一个密钥对,以允许您登录到特定实例,您将需要创建一个密钥对并下载相应的`.pem`文件,您将使用文件以便后续记录。
# 操作步骤
1. 第一步是连接到实例,您可以使用命令行通过 SSH 或浏览器来实现。 我们使用 CLI。
2. 要进行连接,首先更改`.pem`文件的模式。
```py
chmod 400 <security-keypair-filename>.pem
```
3. 接下来,使用以下命令对实例进行 SSH。 选择连接时,确切的地址将在仪表板上可用:
```py
ssh -i " <security-keypair-filename>.pem" ubuntu@ec2-XXXXXXXXXXXXX.compute-1.amazonaws.com
```
4. 我们选择的机器实例已经包含了所有深度学习库,包括 TensorFlow,因此我们不需要安装任何东西:
5. 每个文件夹都包含一个自述文件,该文件描述了如何使用相应的库:
# 工作原理
您可以运行在我们创建的实例上学到的代码。 工作结束后,不要忘记退出,并从仪表板停止实例。 有关价格和使用情况的更多详细信息,请参见[这里](https://aws.amazon.com/documentation/ec2/)
# 更多
AWS 市场上提供了带有预配置库和 API 的大量 Docker 映像和机器映像。 要启动 jupyter 笔记本,请在命令行中使用`<jupyter notebook --ip=0.0.0.0 --no-browser>`。 这将导致输出,如下所示:
首次连接以使用令牌登录时,将此 URL 复制/粘贴到浏览器中:
```py
http://0.0.0.0:8888/?token=3156e...
```
您将 URL 复制并粘贴到浏览器中,就可以开始使用了。
此外,可以通过查看 AWS CloudFormation 简化整个过程。 它使用模板创建和配置 Amazon Web Services 资源。 这样可以简化设置分布式深度学习集群的过程。 有兴趣的读者可以看看[这里](https://aws.amazon.com/blogs/compute/distributed-deep-learning-made-easy/)
- TensorFlow 1.x 深度学习秘籍
- 零、前言
- 一、TensorFlow 简介
- 二、回归
- 三、神经网络:感知器
- 四、卷积神经网络
- 五、高级卷积神经网络
- 六、循环神经网络
- 七、无监督学习
- 八、自编码器
- 九、强化学习
- 十、移动计算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度学习
- 十三、AutoML 和学习如何学习(元学习)
- 十四、TensorFlow 处理单元
- 使用 TensorFlow 构建机器学习项目中文版
- 一、探索和转换数据
- 二、聚类
- 三、线性回归
- 四、逻辑回归
- 五、简单的前馈神经网络
- 六、卷积神经网络
- 七、循环神经网络和 LSTM
- 八、深度神经网络
- 九、大规模运行模型 -- GPU 和服务
- 十、库安装和其他提示
- TensorFlow 深度学习中文第二版
- 一、人工神经网络
- 二、TensorFlow v1.6 的新功能是什么?
- 三、实现前馈神经网络
- 四、CNN 实战
- 五、使用 TensorFlow 实现自编码器
- 六、RNN 和梯度消失或爆炸问题
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用协同过滤的电影推荐
- 十、OpenAI Gym
- TensorFlow 深度学习实战指南中文版
- 一、入门
- 二、深度神经网络
- 三、卷积神经网络
- 四、循环神经网络介绍
- 五、总结
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高级库
- 三、Keras 101
- 四、TensorFlow 中的经典机器学习
- 五、TensorFlow 和 Keras 中的神经网络和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于时间序列数据的 RNN
- 八、TensorFlow 和 Keras 中的用于文本数据的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自编码器
- 十一、TF 服务:生产中的 TensorFlow 模型
- 十二、迁移学习和预训练模型
- 十三、深度强化学习
- 十四、生成对抗网络
- 十五、TensorFlow 集群的分布式模型
- 十六、移动和嵌入式平台上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、调试 TensorFlow 模型
- 十九、张量处理单元
- TensorFlow 机器学习秘籍中文第二版
- 一、TensorFlow 入门
- 二、TensorFlow 的方式
- 三、线性回归
- 四、支持向量机
- 五、最近邻方法
- 六、神经网络
- 七、自然语言处理
- 八、卷积神经网络
- 九、循环神经网络
- 十、将 TensorFlow 投入生产
- 十一、更多 TensorFlow
- 与 TensorFlow 的初次接触
- 前言
- 1. TensorFlow 基础知识
- 2. TensorFlow 中的线性回归
- 3. TensorFlow 中的聚类
- 4. TensorFlow 中的单层神经网络
- 5. TensorFlow 中的多层神经网络
- 6. 并行
- 后记
- TensorFlow 学习指南
- 一、基础
- 二、线性模型
- 三、学习
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 构建简单的神经网络
- 二、在 Eager 模式中使用指标
- 三、如何保存和恢复训练模型
- 四、文本序列到 TFRecords
- 五、如何将原始图片数据转换为 TFRecords
- 六、如何使用 TensorFlow Eager 从 TFRecords 批量读取数据
- 七、使用 TensorFlow Eager 构建用于情感识别的卷积神经网络(CNN)
- 八、用于 TensorFlow Eager 序列分类的动态循坏神经网络
- 九、用于 TensorFlow Eager 时间序列回归的递归神经网络
- TensorFlow 高效编程
- 图嵌入综述:问题,技术与应用
- 一、引言
- 三、图嵌入的问题设定
- 四、图嵌入技术
- 基于边重构的优化问题
- 应用
- 基于深度学习的推荐系统:综述和新视角
- 引言
- 基于深度学习的推荐:最先进的技术
- 基于卷积神经网络的推荐
- 关于卷积神经网络我们理解了什么
- 第1章概论
- 第2章多层网络
- 2.1.4生成对抗网络
- 2.2.1最近ConvNets演变中的关键架构
- 2.2.2走向ConvNet不变性
- 2.3时空卷积网络
- 第3章了解ConvNets构建块
- 3.2整改
- 3.3规范化
- 3.4汇集
- 第四章现状
- 4.2打开问题
- 参考
- 机器学习超级复习笔记
- Python 迁移学习实用指南
- 零、前言
- 一、机器学习基础
- 二、深度学习基础
- 三、了解深度学习架构
- 四、迁移学习基础
- 五、释放迁移学习的力量
- 六、图像识别与分类
- 七、文本文件分类
- 八、音频事件识别与分类
- 九、DeepDream
- 十、自动图像字幕生成器
- 十一、图像着色
- 面向计算机视觉的深度学习
- 零、前言
- 一、入门
- 二、图像分类
- 三、图像检索
- 四、对象检测
- 五、语义分割
- 六、相似性学习
- 七、图像字幕
- 八、生成模型
- 九、视频分类
- 十、部署
- 深度学习快速参考
- 零、前言
- 一、深度学习的基础
- 二、使用深度学习解决回归问题
- 三、使用 TensorBoard 监控网络训练
- 四、使用深度学习解决二分类问题
- 五、使用 Keras 解决多分类问题
- 六、超参数优化
- 七、从头开始训练 CNN
- 八、将预训练的 CNN 用于迁移学习
- 九、从头开始训练 RNN
- 十、使用词嵌入从头开始训练 LSTM
- 十一、训练 Seq2Seq 模型
- 十二、深度强化学习
- 十三、生成对抗网络
- TensorFlow 2.0 快速入门指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 简介
- 一、TensorFlow 2 简介
- 二、Keras:TensorFlow 2 的高级 API
- 三、TensorFlow 2 和 ANN 技术
- 第 2 部分:TensorFlow 2.00 Alpha 中的监督和无监督学习
- 四、TensorFlow 2 和监督机器学习
- 五、TensorFlow 2 和无监督学习
- 第 3 部分:TensorFlow 2.00 Alpha 的神经网络应用
- 六、使用 TensorFlow 2 识别图像
- 七、TensorFlow 2 和神经风格迁移
- 八、TensorFlow 2 和循环神经网络
- 九、TensorFlow 估计器和 TensorFlow HUB
- 十、从 tf1.12 转换为 tf2
- TensorFlow 入门
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 数学运算
- 三、机器学习入门
- 四、神经网络简介
- 五、深度学习
- 六、TensorFlow GPU 编程和服务
- TensorFlow 卷积神经网络实用指南
- 零、前言
- 一、TensorFlow 的设置和介绍
- 二、深度学习和卷积神经网络
- 三、TensorFlow 中的图像分类
- 四、目标检测与分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自编码器,变分自编码器和生成对抗网络
- 七、迁移学习
- 八、机器学习最佳实践和故障排除
- 九、大规模训练
- 十、参考文献