
# 四、文本序列到 TFRecords
大家好! 在本教程中,我将向你展示如何将原始文本数据解析为 TFRecords。 我知道很多人都卡在输入处理流水线,尤其是当你开始着手自己的个人项目时。 所以我真的希望它对你们任何人都有用!
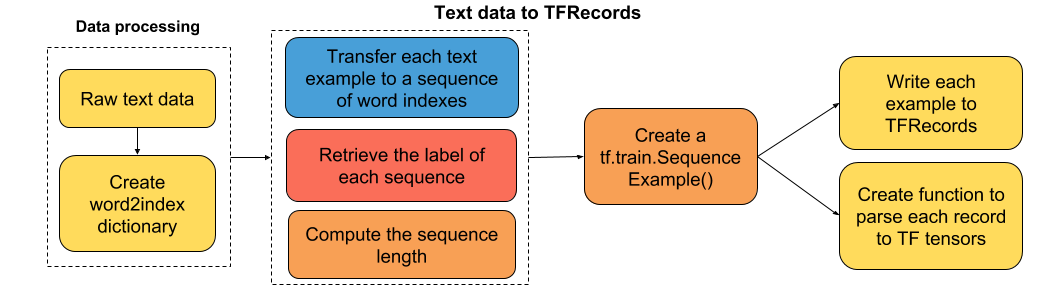
教程的流程图
### 虚拟的IMDB文本数据
在实践中,我从斯坦福大学提供的大型电影评论数据集中选择了一些数据样本。
### 在这里导入有用的库
```py
from nltk.tokenize import word_tokenize
import tensorflow as tf
import pandas as pd
import pickle
import random
import glob
import nltk
import re
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
nltk.download('punkt')
```
### 将数据解析为 TFRecords
```py
def imdb2tfrecords(path_data='datasets/dummy_text/', min_word_frequency=5,
max_words_review=700):
'''
这个脚本处理数据
并将其保存为默认的 TensorFlow 文件格式:tfrecords。
Args:
path_data: the path where the imdb data is stored.
min_word_frequency: the minimum frequency of a word, to keep it
in the vocabulary.
max_words_review: the maximum number of words allowed in a review.
'''
# 获取正面/负面评论的文件名
pos_files = glob.glob(path_data + 'pos/*')
neg_files = glob.glob(path_data + 'neg/*')
# 连接正负评论的文件名
filenames = pos_files + neg_files
# 列出数据集中的所有评论
reviews = [open(filenames[i],'r').read() for i in range(len(filenames))]
# 移除 HTML 标签
reviews = [re.sub(r'<[^>]+>', ' ', review) for review in reviews]
# 将每个评论分词
reviews = [word_tokenize(review) for review in reviews]
# 计算每个评论的的长度
len_reviews = [len(review) for review in reviews]
# 展开嵌套列表
reviews = [word for review in reviews for word in review]
# 计算每个单词的频率
word_frequency = pd.value_counts(reviews)
# 仅仅保留频率高于最小值的单词
vocabulary = word_frequency[word_frequency>=min_word_frequency].index.tolist()
# 添加未知,起始和终止记号
extra_tokens = ['Unknown_token', 'End_token']
vocabulary += extra_tokens
# 创建 word2idx 词典
word2idx = {vocabulary[i]: i for i in range(len(vocabulary))}
# 将单词的词汇表写到磁盘
pickle.dump(word2idx, open(path_data + 'word2idx.pkl', 'wb'))
def text2tfrecords(filenames, writer, vocabulary, word2idx,
max_words_review):
'''
用于将每个评论解析为部分,并作为 tfrecord 写入磁盘的函数。
Args:
filenames: the paths of the review files.
writer: the writer object for tfrecords.
vocabulary: list with all the words included in the vocabulary.
word2idx: dictionary of words and their corresponding indexes.
'''
# 打乱 filenames
random.shuffle(filenames)
for filename in filenames:
review = open(filename, 'r').read()
review = re.sub(r'<[^>]+>', ' ', review)
review = word_tokenize(review)
# 将 review 归约为最大单词
review = review[-max_words_review:]
# 将单词替换为来自 word2idx 的等效索引
review = [word2idx[word] if word in vocabulary else
word2idx['Unknown_token'] for word in review]
indexed_review = review + [word2idx['End_token']]
sequence_length = len(indexed_review)
target = 1 if filename.split('/')[-2]=='pos' else 0
# Create a Sequence Example to store our data in
ex = tf.train.SequenceExample()
# 向我们的示例添加非顺序特性
ex.context.feature['sequence_length'].int64_list.value.append(sequence_length)
ex.context.feature['target'].int64_list.value.append(target)
# 添加顺序特征
token_indexes = ex.feature_lists.feature_list['token_indexes']
for token_index in indexed_review:
token_indexes.feature.add().int64_list.value.append(token_index)
writer.write(ex.SerializeToString())
##########################################################################
# Write data to tfrecords.This might take a while.
##########################################################################
writer = tf.python_io.TFRecordWriter(path_data + 'dummy.tfrecords')
text2tfrecords(filenames, writer, vocabulary, word2idx,
max_words_review)
imdb2tfrecords(path_data='datasets/dummy_text/')
```
### 将 TFRecords 解析为 TF 张量
```py
def parse_imdb_sequence(record):
'''
解析 imdb tfrecords 的脚本
Returns:
token_indexes: sequence of token indexes present in the review.
target: the target of the movie review.
sequence_length: the length of the sequence.
'''
context_features = {
'sequence_length': tf.FixedLenFeature([], dtype=tf.int64),
'target': tf.FixedLenFeature([], dtype=tf.int64),
}
sequence_features = {
'token_indexes': tf.FixedLenSequenceFeature([], dtype=tf.int64),
}
context_parsed, sequence_parsed = tf.parse_single_sequence_example(record,
context_features=context_features, sequence_features=sequence_features)
return (sequence_parsed['token_indexes'], context_parsed['target'],
context_parsed['sequence_length'])
```
如果你希望我在本教程中添加任何内容,请告诉我,我将很乐意进一步改善它。
- TensorFlow 1.x 深度学习秘籍
- 零、前言
- 一、TensorFlow 简介
- 二、回归
- 三、神经网络:感知器
- 四、卷积神经网络
- 五、高级卷积神经网络
- 六、循环神经网络
- 七、无监督学习
- 八、自编码器
- 九、强化学习
- 十、移动计算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度学习
- 十三、AutoML 和学习如何学习(元学习)
- 十四、TensorFlow 处理单元
- 使用 TensorFlow 构建机器学习项目中文版
- 一、探索和转换数据
- 二、聚类
- 三、线性回归
- 四、逻辑回归
- 五、简单的前馈神经网络
- 六、卷积神经网络
- 七、循环神经网络和 LSTM
- 八、深度神经网络
- 九、大规模运行模型 -- GPU 和服务
- 十、库安装和其他提示
- TensorFlow 深度学习中文第二版
- 一、人工神经网络
- 二、TensorFlow v1.6 的新功能是什么?
- 三、实现前馈神经网络
- 四、CNN 实战
- 五、使用 TensorFlow 实现自编码器
- 六、RNN 和梯度消失或爆炸问题
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用协同过滤的电影推荐
- 十、OpenAI Gym
- TensorFlow 深度学习实战指南中文版
- 一、入门
- 二、深度神经网络
- 三、卷积神经网络
- 四、循环神经网络介绍
- 五、总结
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高级库
- 三、Keras 101
- 四、TensorFlow 中的经典机器学习
- 五、TensorFlow 和 Keras 中的神经网络和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于时间序列数据的 RNN
- 八、TensorFlow 和 Keras 中的用于文本数据的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自编码器
- 十一、TF 服务:生产中的 TensorFlow 模型
- 十二、迁移学习和预训练模型
- 十三、深度强化学习
- 十四、生成对抗网络
- 十五、TensorFlow 集群的分布式模型
- 十六、移动和嵌入式平台上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、调试 TensorFlow 模型
- 十九、张量处理单元
- TensorFlow 机器学习秘籍中文第二版
- 一、TensorFlow 入门
- 二、TensorFlow 的方式
- 三、线性回归
- 四、支持向量机
- 五、最近邻方法
- 六、神经网络
- 七、自然语言处理
- 八、卷积神经网络
- 九、循环神经网络
- 十、将 TensorFlow 投入生产
- 十一、更多 TensorFlow
- 与 TensorFlow 的初次接触
- 前言
- 1. TensorFlow 基础知识
- 2. TensorFlow 中的线性回归
- 3. TensorFlow 中的聚类
- 4. TensorFlow 中的单层神经网络
- 5. TensorFlow 中的多层神经网络
- 6. 并行
- 后记
- TensorFlow 学习指南
- 一、基础
- 二、线性模型
- 三、学习
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 构建简单的神经网络
- 二、在 Eager 模式中使用指标
- 三、如何保存和恢复训练模型
- 四、文本序列到 TFRecords
- 五、如何将原始图片数据转换为 TFRecords
- 六、如何使用 TensorFlow Eager 从 TFRecords 批量读取数据
- 七、使用 TensorFlow Eager 构建用于情感识别的卷积神经网络(CNN)
- 八、用于 TensorFlow Eager 序列分类的动态循坏神经网络
- 九、用于 TensorFlow Eager 时间序列回归的递归神经网络
- TensorFlow 高效编程
- 图嵌入综述:问题,技术与应用
- 一、引言
- 三、图嵌入的问题设定
- 四、图嵌入技术
- 基于边重构的优化问题
- 应用
- 基于深度学习的推荐系统:综述和新视角
- 引言
- 基于深度学习的推荐:最先进的技术
- 基于卷积神经网络的推荐
- 关于卷积神经网络我们理解了什么
- 第1章概论
- 第2章多层网络
- 2.1.4生成对抗网络
- 2.2.1最近ConvNets演变中的关键架构
- 2.2.2走向ConvNet不变性
- 2.3时空卷积网络
- 第3章了解ConvNets构建块
- 3.2整改
- 3.3规范化
- 3.4汇集
- 第四章现状
- 4.2打开问题
- 参考
- 机器学习超级复习笔记
- Python 迁移学习实用指南
- 零、前言
- 一、机器学习基础
- 二、深度学习基础
- 三、了解深度学习架构
- 四、迁移学习基础
- 五、释放迁移学习的力量
- 六、图像识别与分类
- 七、文本文件分类
- 八、音频事件识别与分类
- 九、DeepDream
- 十、自动图像字幕生成器
- 十一、图像着色
- 面向计算机视觉的深度学习
- 零、前言
- 一、入门
- 二、图像分类
- 三、图像检索
- 四、对象检测
- 五、语义分割
- 六、相似性学习
- 七、图像字幕
- 八、生成模型
- 九、视频分类
- 十、部署
- 深度学习快速参考
- 零、前言
- 一、深度学习的基础
- 二、使用深度学习解决回归问题
- 三、使用 TensorBoard 监控网络训练
- 四、使用深度学习解决二分类问题
- 五、使用 Keras 解决多分类问题
- 六、超参数优化
- 七、从头开始训练 CNN
- 八、将预训练的 CNN 用于迁移学习
- 九、从头开始训练 RNN
- 十、使用词嵌入从头开始训练 LSTM
- 十一、训练 Seq2Seq 模型
- 十二、深度强化学习
- 十三、生成对抗网络
- TensorFlow 2.0 快速入门指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 简介
- 一、TensorFlow 2 简介
- 二、Keras:TensorFlow 2 的高级 API
- 三、TensorFlow 2 和 ANN 技术
- 第 2 部分:TensorFlow 2.00 Alpha 中的监督和无监督学习
- 四、TensorFlow 2 和监督机器学习
- 五、TensorFlow 2 和无监督学习
- 第 3 部分:TensorFlow 2.00 Alpha 的神经网络应用
- 六、使用 TensorFlow 2 识别图像
- 七、TensorFlow 2 和神经风格迁移
- 八、TensorFlow 2 和循环神经网络
- 九、TensorFlow 估计器和 TensorFlow HUB
- 十、从 tf1.12 转换为 tf2
- TensorFlow 入门
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 数学运算
- 三、机器学习入门
- 四、神经网络简介
- 五、深度学习
- 六、TensorFlow GPU 编程和服务
- TensorFlow 卷积神经网络实用指南
- 零、前言
- 一、TensorFlow 的设置和介绍
- 二、深度学习和卷积神经网络
- 三、TensorFlow 中的图像分类
- 四、目标检测与分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自编码器,变分自编码器和生成对抗网络
- 七、迁移学习
- 八、机器学习最佳实践和故障排除
- 九、大规模训练
- 十、参考文献