
>[success] # 链表
~~~
1.了解链表前还需要再次看一下数组的概念,在类似java的语言中'数组的大小在生命使用的时候是固定'
,因此数组需要一块'连续的内存空间'来储存。因此产生的问题如下:
1.1.如果申请内存大小为'100MB'大小数组,由于'连续的内存空间'没有这么大数组申请失败
1.2.从数组起点或者中间位置插入或移除所需时间成本较高,因为数组要保证内存数据的连续性,因此
需要做大量的数据搬移,也就是数组插入和删除的复杂度为O(n),
2.链表是用来存储有序的元素集合,但它'不需要连续的内存空间',也就是说链表中的元素在内存中
'并不是连续放置的,它是通过'指针'将一组零散的内存块串联起来使用,因此它的好处:
1.1.使用时'不在受连续的内存空间'这个问题所影响,也就是如果需要'100MB'的内存空间只要剩余空间加来
有这么大就行
1.2.'不在需要因为要保持内存的连续性而搬移结点'简单地说因为'链表空间不是连续的',所以他的插入和删除
速度非常快,时间复杂度表示'O(1)'
3.数组在查找的时候时间复杂度为'O(1)' 但是在插入和删除的时候时间复杂度'O(n)',链表在插入和删除的时候
时间复杂度为'O(1)',在查找的时候时间复杂度为'O(n)',这都是因为彼此的特性导致的
~~~
>[info] ## 使用图进一步说明
* 图片来自极客时间数据结构与算法之美(结构来说明)
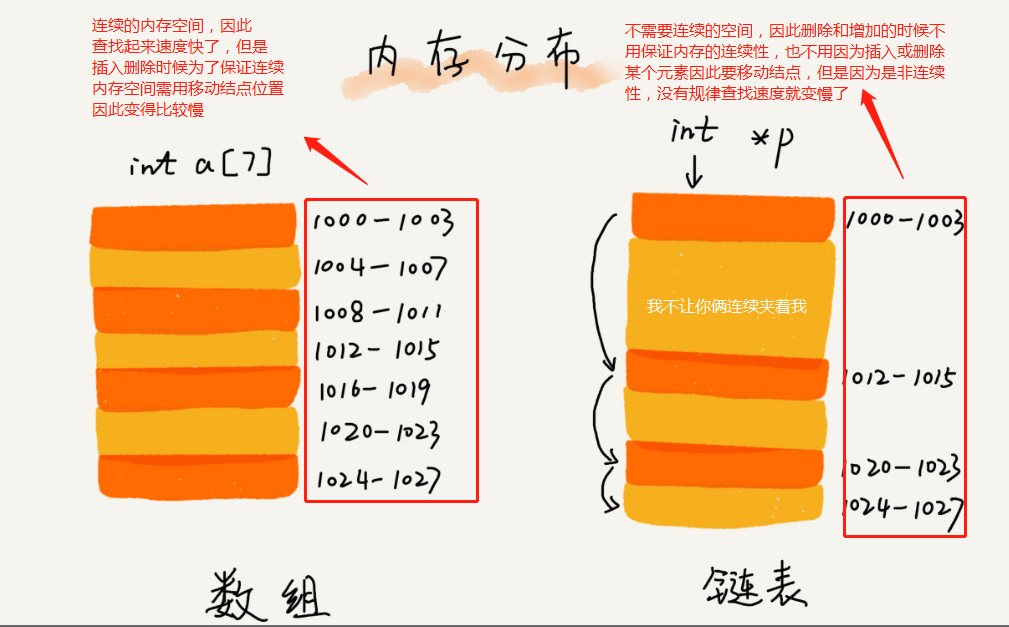
* 图片来自极客时间数据结构与算法之美(来说明为什插入和删除速度快)
~~~
1.插入的时候只要让b 和 c 结点没有关系,让b结点指向新插入的x节点,让x结点指向c节点
2.删除的时候让b节点和 a,c节点一点关系没有即可
~~~
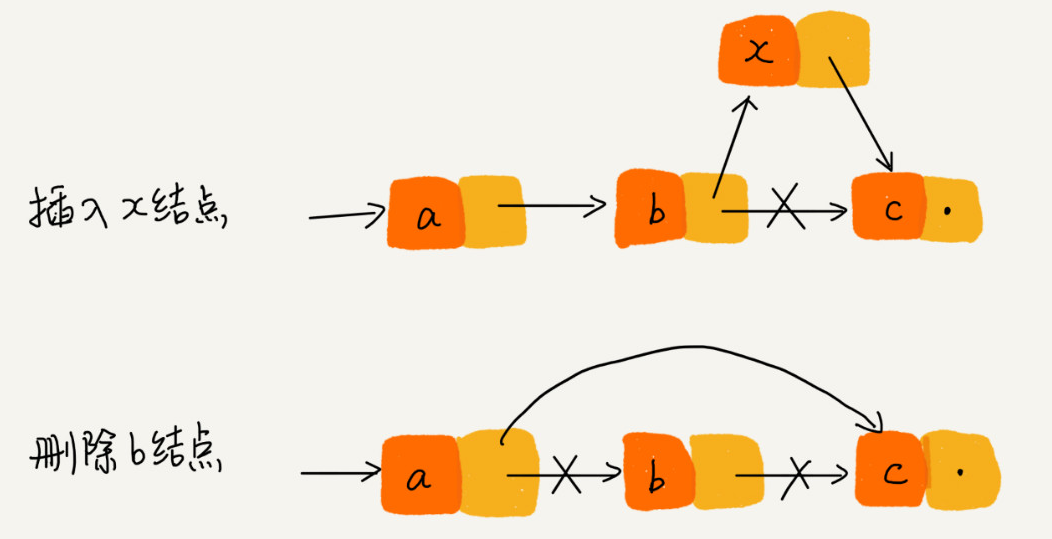
>[danger] ##### 单链表
~~~
1.首先是链表的构成可以理解成:每个元素由一个存储元素本身的节点和一个指向下一个元素的引用
(也称指针或链接)组成。
2.把内存块称为'结点',把当前结点和下一结点连接的指针叫'后继指针next'
3.由于链表内存空间不是连续的因此你访问的时候只能从'头'开始访问,这个第一个结点叫'头结点',
把最后一个节点叫做'尾结点'
3.1 '头结点做的是用来记录链表的基地址' 简单的说你要查找链表中某个元素你给先找到这个
链表,在根据每个'结点'互相连接的关系找到你想查找的'结点'
3.2'尾结点指向的是一个空地址null,js是undefined'用来表示链表到头了
~~~
* 图片来自极客时间数据结构与算法之美
~~~
1.因此通过图可以知得知,想查找链表中某个结点位置,需要从头结点开始一个一个结点找直到找到
要找的结点
~~~
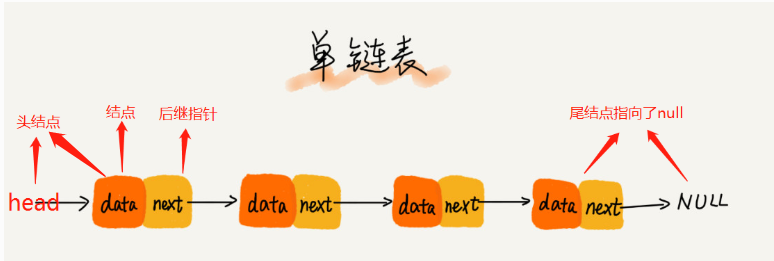
>[danger] ##### 循环链表
~~~
1.循环链表就是将链尾连接到链头,也就是说'尾结点指向的不在是null而是头结点',形成首尾相连的效果
2.需要处理环形结构时候可以使用'循环链表'
~~~
* 图片来自极客时间数据结构与算法之美
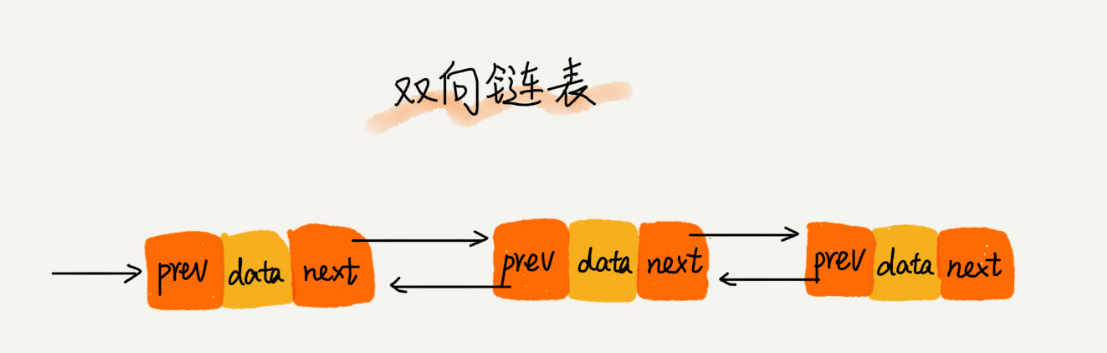
>[danger] ##### 双向链表
~~~
1.双向链表相对于单向链表来说'链接是双向的:一个链向下一个元素, 另一个链向前一个元素'
2.就是说双向链表和单链表相比不止有'后继指针next' 它还有一个'前驱指针prev'
3.因为双向链表的结构导致他独有的特性:
3.1.因为有两个指针因此它的没存空间占用会更多,浪费储存空间
3.2.但可以支持双向遍历,这样也带来了双向链表操作的灵活性举个例子:
在单向链表中,如果迭代时错过了要找的元素,就需要回到起点,重新开始迭代。这是双向 链表的一个优势。
~~~
* 图片来自极客时间数据结构与算法之美
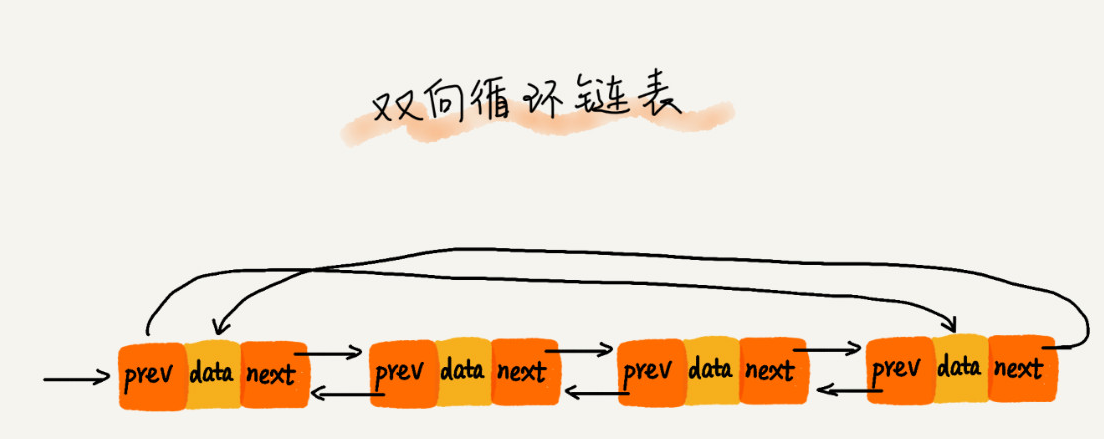
>[danger] ##### 双向循环链表
~~~
1.循环链表可以像链表一样只有单向引用,也可以像双向链表一样有双向引用。循环链表和链
表之间唯一的区别在于,最后一个元素指向下一个元素的指针不是引用
null,而是指向第一个元素(head),
~~~
* 图片来自极客时间数据结构与算法之美
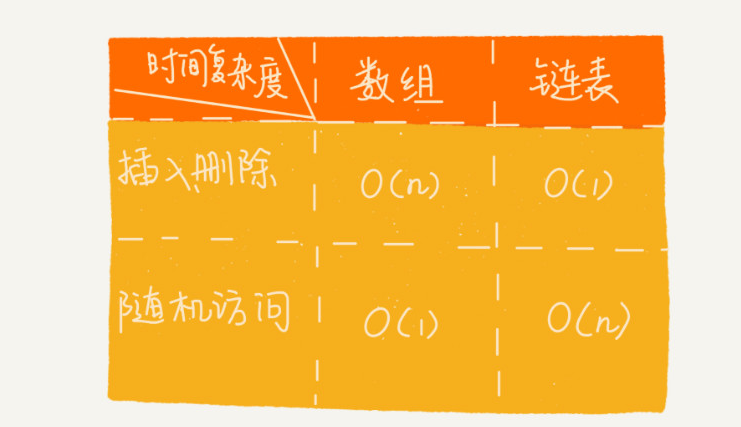
>[success] # 数组和链表的性能分析
>[danger] ##### 两者的区别
~~~
1.数组:插入、删除的时间复杂度是O(n),随机访问的时间复杂度是O(1)。
2.链表:插入、删除的时间复杂度是O(1),随机访问的时间复杂端是O(n)。
3.链表的内存空间消耗更大,因为需要额外的空间存储指针信息。
4.对链表进行频繁的插入和删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,
如果是Java语言,还可能会造成频繁的GC(自动垃圾回收器)操作。
~~~
* 图片来自极客时间数据结构与算法之美
>[danger] ##### 选择两者谁
~~~
1.数组简单易用,在实现上使用连续的内存空间,可以借助CPU的缓冲机制预读数组中的数据,
所以访问效率更高,而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法预读。
如果代码对内存的使用非常苛刻,那数组就更适合。
~~~
>[danger] ##### 对上面的CPU缓存讲解(感谢Rain大佬的讲解)

>[danger] ##### 链表的插入和删除操作真的就是O(1)么
~~~
1.极客时间王争老师说了删除在开发实际应用的场景:
1.1.删除结点中'值等于某个给定值'的结点;
1.2.删除给定指针指向的结点。
2.针对'第一种情况来分析',如果给定值,我们想删除某个元素。那就需要去查到这个元素
链表的查询速度是O(n) 虽然删除速度是O(1)根据复杂度分析加法法则来说整体的执行速度就是
O(n)
但针对'第二种情况来分析'的话,如果是'单链表'你知道指针指向的结点,但是删除这个结点后,
你还需要将这个被删除结点的前面结点指针指向,被删除结点的后面结点,因此你还需要
去查询被删除结点的前面结点,你就需要从头开始查,因此根据复杂度分析O(n),
'双向链表'由于知道自己的'前驱结点'因此不用遍历复杂度O(1)
~~~
>[danger] ##### 时间和空间优化
~~~
1.空间换时间的设计思想。当内存空间充足的时候,如果我们更加追求代码的执行速度,
我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。
相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来
用时间换空间的设计思路。
总结:
对于执行较慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化;
而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存的消耗。
~~~
- 接触数据结构和算法
- 数据结构与算法 -- 大O复杂度表示法
- 数据结构与算法 -- 时间复杂度分析
- 最好、最坏、平均、均摊时间复杂度
- 基础数据结构和算法
- 线性表和非线性表
- 结构 -- 数组
- JS -- 数组
- 结构 -- 栈
- JS -- 栈
- JS -- 栈有效圆括号
- JS -- 汉诺塔
- 结构 -- 队列
- JS -- 队列
- JS -- 双端队列
- JS -- 循环队列
- 结构 -- 链表
- JS -- 链表
- JS -- 双向链表
- JS -- 循环链表
- JS -- 有序链表
- 结构 -- JS 字典
- 结构 -- 散列表
- 结构 -- js 散列表
- 结构 -- js分离链表
- 结构 -- js开放寻址法
- 结构 -- 递归
- 结构 -- js递归经典问题
- 结构 -- 树
- 结构 -- js 二搜索树
- 结构 -- 红黑树
- 结构 -- 堆
- 结构 -- js 堆
- 结构 -- js 堆排序
- 结构 -- 排序
- js -- 冒泡排序
- js -- 选择排序
- js -- 插入排序
- js -- 归并排序
- js -- 快速排序
- js -- 计数排序
- js -- 桶排序
- js -- 基数排序
- 结构 -- 算法
- 搜索算法
- 二分搜索
- 内插搜索
- 随机算法
- 简单
- 第一题 两数之和
- 第七题 反转整数
- 第九题 回文数
- 第十三题 罗马数字转整数
- 常见一些需求
- 把原始 list 转换成树形结构