
# 7.8 Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均 [1]。下面我们来介绍这个算法。
> 所以Adam算法可以看做是RMSProp算法与动量法的结合。
## 7.8.1 算法
Adam算法使用了动量变量`$ \boldsymbol{v}_t $`和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量`$ \boldsymbol{s}_t $`,并在时间步0将它们中每个元素初始化为0。给定超参数`$ 0 \leq \beta_1 < 1 $`(算法作者建议设为0.9),时间步 `$ t $`的动量变量`$ \boldsymbol{v}_t $`即小批量随机梯度`$ \boldsymbol{g}_t $`的指数加权移动平均:
```[tex]
\boldsymbol{v}_t \leftarrow \beta_1 \boldsymbol{v}_{t-1} + (1 - \beta_1) \boldsymbol{g}_t.
```
和RMSProp算法中一样,给定超参数`$ 0 \leq \beta_2 < 1 $`(算法作者建议设为0.999),
将小批量随机梯度按元素平方后的项`$ \boldsymbol{g}_t \odot \boldsymbol{g}_t $`做指数加权移动平均得到`$ \boldsymbol{s}_t $`:
```[tex]
\boldsymbol{s}_t \leftarrow \beta_2 \boldsymbol{s}_{t-1} + (1 - \beta_2) \boldsymbol{g}_t \odot \boldsymbol{g}_t.
```
由于我们将`$ \boldsymbol{v}_0 $` 和`$ \boldsymbol{s}_0 $`中的元素都初始化为0,
在时间步`$ t $`我们得到 `$ \boldsymbol{v}_t = (1-\beta_1) \sum_{i=1}^t \beta_1^{t-i} \boldsymbol{g}_i $`。将过去各时间步小批量随机梯度的权值相加,得到 `$ (1-\beta_1) \sum_{i=1}^t \beta_1^{t-i} = 1 - \beta_1^t $`。需要注意的是,当 `$ t $`较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当`$ \beta_1 = 0.9 $`时,`$ \boldsymbol{v}_1 = 0.1\boldsymbol{g}_1 $`。为了消除这样的影响,对于任意时间步`$ t $`,我们可以将`$ \boldsymbol{v}_t $`再除以`$ 1 - \beta_1^t $`,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量`$ \boldsymbol{v}_t $`和`$ \boldsymbol{s}_t $`均作偏差修正:
```[tex]
\hat{\boldsymbol{v}}_t \leftarrow \frac{\boldsymbol{v}_t}{1 - \beta_1^t},
```
```[tex]
\hat{\boldsymbol{s}}_t \leftarrow \frac{\boldsymbol{s}_t}{1 - \beta_2^t}.
```
接下来,Adam算法使用以上偏差修正后的变量`$ \hat{\boldsymbol{v}}_t $`和`$ \hat{\boldsymbol{s}}_t $`,将模型参数中每个元素的学习率通过按元素运算重新调整:
```[tex]
\boldsymbol{g}_t' \leftarrow \frac{\eta \hat{\boldsymbol{v}}_t}{\sqrt{\hat{\boldsymbol{s}}_t} + \epsilon},
```
其中`$ \eta $`是学习率,`$ \epsilon $`是为了维持数值稳定性而添加的常数,如`$ 10^{-8} $`。和AdaGrad算法、RMSProp算法以及AdaDelta算法一样,目标函数自变量中每个元素都分别拥有自己的学习率。最后,使用`$ \boldsymbol{g}_t' $`迭代自变量:
```[tex]
\boldsymbol{x}_t \leftarrow \boldsymbol{x}_{t-1} - \boldsymbol{g}_t'.
```
## 7.8.2 从零开始实现
我们按照Adam算法中的公式实现该算法。其中时间步`$ t $`通过`hyperparams`参数传入`adam`函数。
``` python
%matplotlib inline
import torch
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
features, labels = d2l.get_data_ch7()
def init_adam_states():
v_w, v_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)
s_w, s_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)
return ((v_w, s_w), (v_b, s_b))
def adam(params, states, hyperparams):
beta1, beta2, eps = 0.9, 0.999, 1e-6
for p, (v, s) in zip(params, states):
v[:] = beta1 * v + (1 - beta1) * p.grad.data
s[:] = beta2 * s + (1 - beta2) * p.grad.data**2
v_bias_corr = v / (1 - beta1 ** hyperparams['t'])
s_bias_corr = s / (1 - beta2 ** hyperparams['t'])
p.data -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)
hyperparams['t'] += 1
```
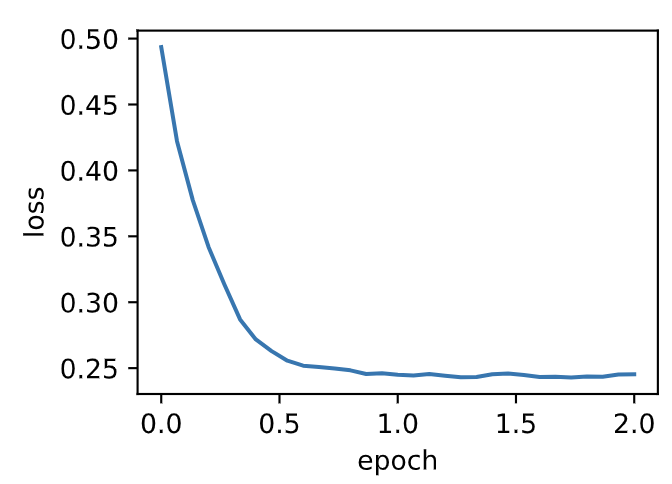
使用学习率为0.01的Adam算法来训练模型。
``` python
d2l.train_ch7(adam, init_adam_states(), {'lr': 0.01, 't': 1}, features, labels)
```
输出:
```
loss: 0.245370, 0.065155 sec per epoch
```
:-: 
## 7.8.3 简洁实现
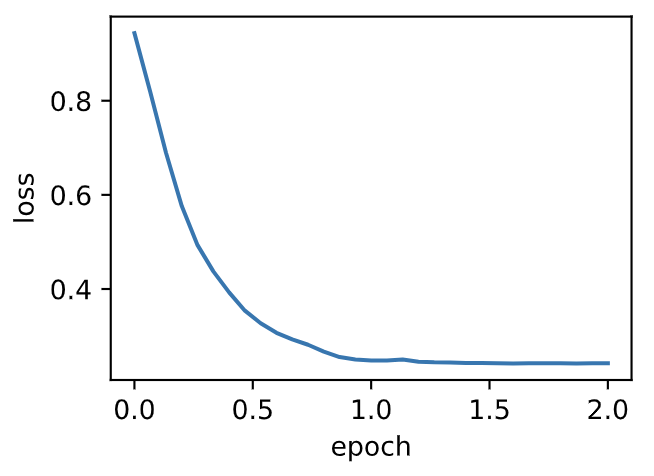
通过名称为“adam”的`Trainer`实例,我们便可使用Gluon提供的Adam算法。
``` python
d2l.train_pytorch_ch7(torch.optim.Adam, {'lr': 0.01}, features, labels)
```
输出:
```
loss: 0.242066, 0.056867 sec per epoch
```
:-: 
## 小结
* Adam算法在RMSProp算法的基础上对小批量随机梯度也做了指数加权移动平均。
* Adam算法使用了偏差修正。
## 参考文献
[1] Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
-----------
> 注:除代码外本节与原书此节基本相同,[原书传送门](https://zh.d2l.ai/chapter_optimization/adam.html)
- Home
- Introduce
- 1.深度学习简介
- 深度学习简介
- 2.预备知识
- 2.1环境配置
- 2.2数据操作
- 2.3自动求梯度
- 3.深度学习基础
- 3.1 线性回归
- 3.2 线性回归的从零开始实现
- 3.3 线性回归的简洁实现
- 3.4 softmax回归
- 3.5 图像分类数据集(Fashion-MINST)
- 3.6 softmax回归的从零开始实现
- 3.7 softmax回归的简洁实现
- 3.8 多层感知机
- 3.9 多层感知机的从零开始实现
- 3.10 多层感知机的简洁实现
- 3.11 模型选择、反向传播和计算图
- 3.12 权重衰减
- 3.13 丢弃法
- 3.14 正向传播、反向传播和计算图
- 3.15 数值稳定性和模型初始化
- 3.16 实战kaggle比赛:房价预测
- 4 深度学习计算
- 4.1 模型构造
- 4.2 模型参数的访问、初始化和共享
- 4.3 模型参数的延后初始化
- 4.4 自定义层
- 4.5 读取和存储
- 4.6 GPU计算
- 5 卷积神经网络
- 5.1 二维卷积层
- 5.2 填充和步幅
- 5.3 多输入通道和多输出通道
- 5.4 池化层
- 5.5 卷积神经网络(LeNet)
- 5.6 深度卷积神经网络(AlexNet)
- 5.7 使用重复元素的网络(VGG)
- 5.8 网络中的网络(NiN)
- 5.9 含并行连结的网络(GoogLeNet)
- 5.10 批量归一化
- 5.11 残差网络(ResNet)
- 5.12 稠密连接网络(DenseNet)
- 6 循环神经网络
- 6.1 语言模型
- 6.2 循环神经网络
- 6.3 语言模型数据集(周杰伦专辑歌词)
- 6.4 循环神经网络的从零开始实现
- 6.5 循环神经网络的简单实现
- 6.6 通过时间反向传播
- 6.7 门控循环单元(GRU)
- 6.8 长短期记忆(LSTM)
- 6.9 深度循环神经网络
- 6.10 双向循环神经网络
- 7 优化算法
- 7.1 优化与深度学习
- 7.2 梯度下降和随机梯度下降
- 7.3 小批量随机梯度下降
- 7.4 动量法
- 7.5 AdaGrad算法
- 7.6 RMSProp算法
- 7.7 AdaDelta
- 7.8 Adam算法
- 8 计算性能
- 8.1 命令式和符号式混合编程
- 8.2 异步计算
- 8.3 自动并行计算
- 8.4 多GPU计算
- 9 计算机视觉
- 9.1 图像增广
- 9.2 微调
- 9.3 目标检测和边界框
- 9.4 锚框
- 10 自然语言处理
- 10.1 词嵌入(word2vec)
- 10.2 近似训练
- 10.3 word2vec实现
- 10.4 子词嵌入(fastText)
- 10.5 全局向量的词嵌入(Glove)
- 10.6 求近义词和类比词
- 10.7 文本情感分类:使用循环神经网络
- 10.8 文本情感分类:使用卷积网络
- 10.9 编码器--解码器(seq2seq)
- 10.10 束搜索
- 10.11 注意力机制
- 10.12 机器翻译