
[TOC]
## 概述
Redis中的List是一个有序(按加入的时序排序)的数据结构,一般有序我们会采用数组或者是双向链表,其中双向链表由于有前后指针实际上会很浪费内存。3.2版本之前采用两种数据结构作为底层实现:
* 压缩列表ziplist
* 双向链表linkedlist
## ziplist的结构
ziplist的数据结构及解释如下:
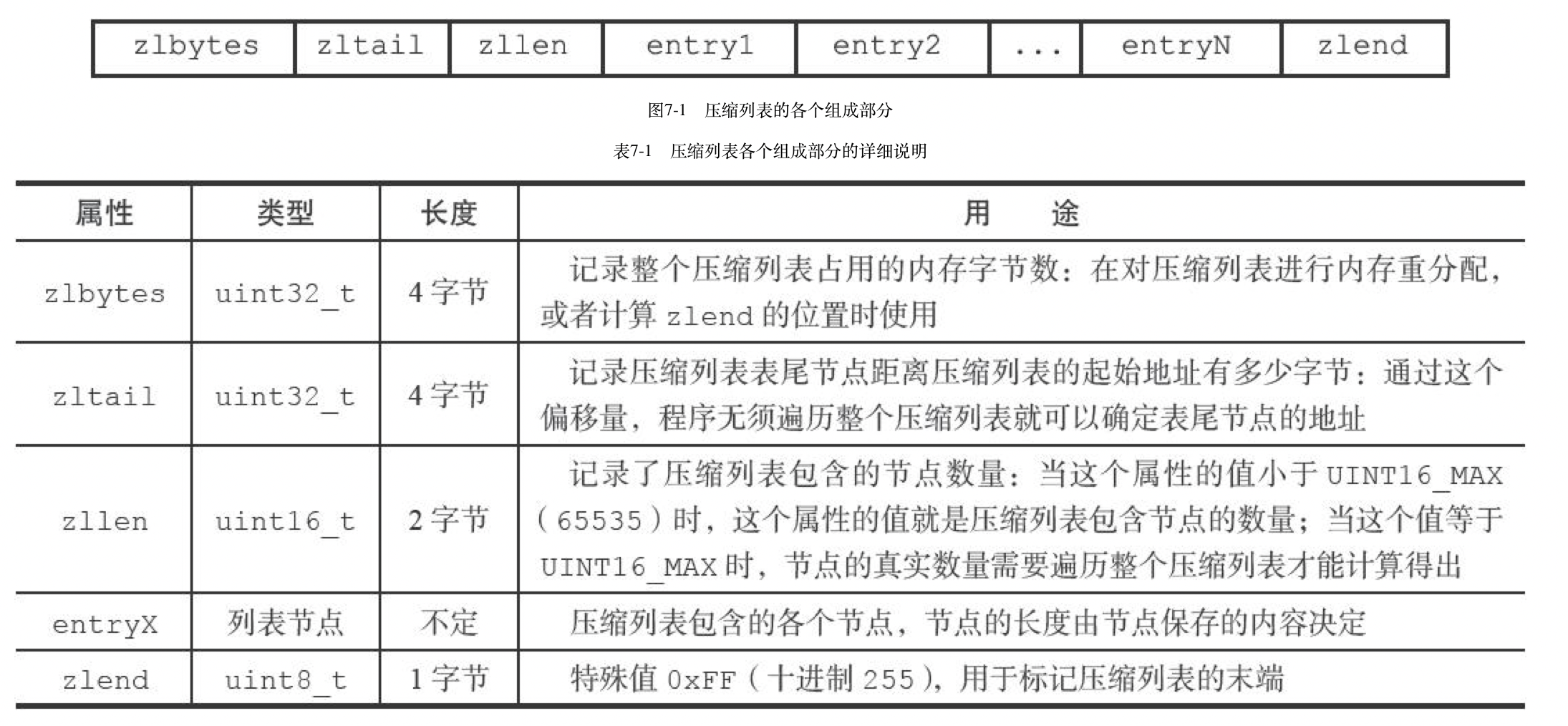
`ziplist`的节点信息如下:
```
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小,有1字节和5个字节两种。
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;
```
返回一个zlenrty
```
static zlentry zipEntry(unsigned char *p) {
zlentry e;
// e.prevrawlensize 保存着编码前一个节点的长度所需的字节数
// e.prevrawlen 保存着前一个节点的长度
// T = O(1)
ZIP_DECODE_PREVLEN(p, e.prevrawlensize, e.prevrawlen);
// p + e.prevrawlensize 将指针移动到列表节点本身
// e.encoding 保存着节点值的编码类型
// e.lensize 保存着编码节点值长度所需的字节数
// e.len 保存着节点值的长度
// T = O(1)
ZIP_DECODE_LENGTH(p + e.prevrawlensize, e.encoding, e.lensize, e.len);
// 计算头结点的字节数
e.headersize = e.prevrawlensize + e.lensize;
// 记录指针
e.p = p;
return e;
}
```
## ziplist的原理
ziplist是使用连续的内存块存储的:
* zlbytes:表示整个ziplist占用的字节数,一般用于内存重分配或者计算列表尾端
* zltail:到达列表最后一个节点的偏移量,方便直接找到尾部节点
* zllen:列表节点的数量
* entryX:列表中的各节点
* zlend:作用就是用来标记列表尾端,占用一个字节
>注意zllen用16个比特位存储,也就是说起长度最大表示65535,所以如果长度超过这个值,只能够通过节点遍历来确定列表元素数量
每个节点`zlentry`是如何存储的,完整的`zlentry`由以下几个部分组成:
* `prevrawlen`: 记录前一个节点所占内存的字节数,方便查找上一个元素地址
* `unsigned int lensize, len`: lensize表示编码 len 所需的字节大小,len表示当前节点值的长度
* `unsigned int headersize`: 当前节点 header 的大小,等于 prevrawlensize + lensize
* `unsigned char encoding`: 当前节点值所使用的编码类型
>ziplist数据结构中`prevrawlen`是变长编码的,如果上一个节点长度小于254个字节,则只是用一个字节存储prevrawlen,如果大于等于254,那么第一个字节用254标记,后面四个字节表示上一个节点长度
## ziplist 的优缺点
* `ziplist`存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当`ziplist`长度很长的时候,一次`realloc`可能会导致大批量的数据拷贝。
* 双向链表`linkedlist`便于在表的两端进行`push`和`pop`操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
ziplist 最大的确定就是*连锁更新问题*
因为在`ziplist`中,每个`zlentry`都存储着前一个节点所占的字节数,而这个数值又是变长编码的。假设存在一个压缩列表,其包含 e1、e2、e3、e4.....,e1 节点的大小为 253 字节,那么 e2.prevrawlen 的大小为 1 字节,如果此时在 e2 与 e1 之间插入了一个新节点 e,e 编码后的整体长度(包含 e1 的长度)为 254 字节,此时 e2.prevrawlen 就需要扩充为 5 字节;如果 e2 的整体长度变化又引起了 e3.prevrawlen 的存储长度变化,那么 e3 也需要扩.......如此递归直到表尾节点或者某一个节点的 prevrawlen 本身长度可以容纳前一个节点的变化。其中每一次扩充都需要进行空间再分配操作。删除节点亦是如此,只要引起了操作节点之后的节点的 prevrawlen 的变化,都可能引起连锁更新,引发内存 realloc。
连锁更新在最坏情况下需要进行 N 次空间再分配,而每次空间再分配的最坏时间复杂度为 O(N),因此连锁更新的总体时间复杂度是 O(N^2)。
基于上述来看ziplist的缺点大于优点,所以*3.2版本之后采用了另外一个数据结构为quicklist*
## 应用场景
* 压缩列表(ziplist)是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。redis数据列表`list`操作,在列表中添加一个或多个值`RPUSH`:
```
redis> RPUSH lst 1 3 5 10086 "hello" "world"
(integer)6
redis> OBJECT ENCODING lst
"ziplist"
```
* 当一个哈希键只包含少量键值对,比且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做哈希键的底层实现。
```
redis> HMSET profile "name" "Jack" "age" 28 "job" "Programmer"
OK
redis> OBJECT ENCODING profile
"ziplist"
```
>哈希键里面包含的所有键和值都是小整数值或者短字符串
ps: 以上截图来自《Redis设计与实现一书》
- Unity3D
- Unity3D学习路线
- U3D基础
- UGUI
- 数据结构和算法
- 算法时间复杂度
- 二叉树
- B树 & B+树
- 红黑树
- 跳跃表
- Lecod算法题目
- C++-排序算法
- sort排序
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 希尔排序
- 堆排序
- 归并排序
- 递归算法
- LSMs和B tree
- mysql引擎
- 汇编程序
- 汇编入门 Hello World
- 汇编语言整数加减法
- 寄存器的使用和说明
- 汇编语言常用知识点
- 汇编语言中的几个伪指令
- 汇编语言数据类型以及数据定义
- 汇编语言计算数组和字符串长度
- 汇编语言中寄存器加[]的意思
- 汇编语言中$符号的用法
- 汇编语言系统调用(System Calls)
- 汇编语言push和pop指令
- 汇编语言寻址操作
- 汇编语言进阶
- GNUx86-64汇编
- C/C++调用汇编函数
- 用汇编理解C函数的调用过程和返回值
- 从汇编的角度看C++
- C/C++
- C++-编程入门
- C/C++环境搭建
- JsonCPP的使用
- 连接数据库
- 连接mysql
- connector
- C API
- 连接sqlite3
- 使用sqlite3步骤
- 使用Clion
- thread-多线程
- 初识thread
- detach陷阱
- 事实
- 陷阱总结
- 剪切板操作
- 剪切板基本操作
- 剪切板详细api
- 文件操作
- 桌面右键菜单批处理
- Resource Hacker
- 获取指定输入法
- 学习网站
- C++11中的匿名函数(lambda函数,lambda表达式)
- sleep和usleep的区别
- 使用std::unique_ptr 管理 FILE 指针
- typedef的用法
- strtuct中的char*和char数组
- 各个平台不同类型占用字节数
- C++进阶
- C++浅拷贝和深拷贝的区别
- C++类型强制转换
- C++11写的定时器
- C调用java函数
- C++11 特性
- 二进制兼容
- GDB的基础命令
- GDB调试死锁
- 核心底层代码
- 线程池的实现
- 线程池的应用场景
- C++协程库
- C++定时器原理
- 通信协议
- Socket5协议
- https 协议
- TCP-拥塞控制
- C++-STL
- map/unordered_map/hash_map区别
- 初始化vector
- STL算法
- Effective STL
- 条款5:尽量使用区间成员函数代替它们的单元素兄弟
- 条款9:在删除选项中仔细选择
- 条款13:尽量使用vector和string来代替动态分配的数组
- 条款14:使用reserve来避免不必要的重新分配
- 条款16: 如何将vector和string的数据传给遗留的API
- 条款17:使用“交换技巧”来修整过剩容量
- 条款18:避免使用vector<bool>
- 条款30:确保目标区间足够大
- 编辑器
- VS Code
- 配置C++
- 命令行编译
- CMake
- CMake 升级
- cmake-基本操作
- 设置入口
- 修改vs运行时库
- CMake生成sln
- CMake设置输出目录
- CMake添加GDB调试
- 使静态库和动态库同时存在
- C/C++网络编程
- 网络基础
- 5种网络IO模型总结
- 条件变量
- 设置阻塞socket超时时间
- ccnet
- 一个reactor单线程库
- ccnet从单线程转变为多线程
- IO多路复用
- IO多路复用的理解
- EPOLL
- select示例代码
- epoll 示例代码
- iocp示例代码
- muduo库
- muduo编译
- Libevent的简单使用
- 编译libevent
- Libevent几个简单的api
- Libevent 定时器
- Libevent通用的编程技法
- Libevent简单的Server/Client
- Boost库学习
- Boost库编译
- 利用Boost 实现线程池
- boost::asio
- boost::mutex
- Boost解析Json
- Boost.Asio的一些想法
- win32t网络编程
- 简单的c/s socket通信
- 回响
- 迭代服务器跟客户端
- 进行类创建
- socket文件传输
- 简单的udp
- Reactor模型与Proactor模型
- Actor和CSP模型
- 大量的timewait
- EPOLL的bug
- C++-界面
- MFC
- mfc小知识
- MFC吕鑫
- 初识mfc
- 初始化
- 消息映射
- 组合键 与(&)运算
- WIN32+MFC自定义消息
- 对话框的相关消息
- DestroyWindow
- GDI
- 初窥
- 坐标
- 创建画笔
- CDC
- CPaintDC
- CPen
- CBursh
- CFont
- CBitmap
- LoadImage
- CMemDC
- 自适应
- 双缓冲问题
- 闪烁问题
- 小型软件开发
- 记事本
- 图形架构软件
- 提纲图形
- 操作
- 重载关闭按钮
- 自定义消息
- 自绘按钮
- 自绘基础知识
- 自绘按钮提纲
- 步骤
- 自会下拉列表
- 自绘下拉列表
- 自绘菜单栏
- MFC函数类
- SetTimer
- 高级控件应用
- 高级控件开发提纲
- 菜单栏
- 网络通信协议
- 提纲
- sizeof====strlen
- 堆 == 栈
- Socket
- 基本代码
- UDP协议
- Win32
- 窗口操作
- 创建窗口,自定义按钮
- 给按钮加背景图
- 给窗口加背景
- 贴图
- DLL组件创建
- HOOK钩子
- MinGW
- duilib
- 地址
- 属性列表
- 第一个duilib项目
- DUI自带的完整
- ListControl
- TreeView
- 重设窗口大小
- 计算DPI
- HandleMessage跟MessageHandle
- CEF
- cef环境搭建
- cefsimple简单流程
- 优化CEF
- P2P
- stun搭建
- QT5
- QT5环境安装
- QT信号与槽的概念
- QT工程CMakeLists.txt文件的编写
- QT32位
- libShadowQT
- GoflywayQT
- 计划
- Protocol Buffer
- ProtoBuf安装
- 包管理器
- vcpkg
- conan
- xmake
- C++面试总结
- 基础
- 分布式锁
- C++重载、覆盖与多态性
- 20道必须掌握道C++面试题
- 传值、传地址、传引用总结
- 50道面试题 (1)
- 50道面试题 (2)
- 内联函数的作用以及使用限制
- vector的resize用法
- 虚函数/虚表/虚基类
- 公司面试
- 面试:简单算法题目
- 面试:GetMemory
- 2021-3/11号面试记录(lihe)
- leetcode
- leetcode331-验证二叉树的前序序列化
- leetcode141. 环形链表
- C/C++程序员面试秘籍
- 链表
- 使用C/C++实现atoi和itoa函数
- mysql面试题
- 协程解析
- 协程解析一(ucontext解析)
- 协程解析二(云风的coroutine)
- 进程、线程、协程
- 自己制作一个协程库
- C语言中两个指针间的运算
- Windows中一些宏的含义
- C++书籍在线观看
- 安装TeamTalk
- Lua和C/C++互相調用
- android环境配置
- TCP/IP
- 三次握手四次挥手
- 有限状态机
- 游戏开发
- UE4
- 开发一个fps的游戏
- 环境安装,让人物跑起来
- 增加血条和护甲
- 再生盔甲和伤害功能
- 最后一战
- 最后一战安装部署
- 登录流程 LS & BS & CS
- 最后一战-游戏场景服务器SS
- 降临
- 降临安装部署
- skynet
- skynet安装部署
- lua-protobuc库--skynet使用自定义protobuf
- pbc库--skynet使用自定义protobuf
- 扫雷
- 仙剑奇侠传
- 炉石传说
- unity环境搭建
- 寻路算法
- 音视频
- WebRTC
- webrtc源码下载
- webrtc 编译
- gn和ninja文件作用
- webrtc 源码目录结构
- WebRTC实时互动入门
- web 服务
- nodejs 搭建http服务
- nodejs 搭建https服务
- webrtc 获取音视频设备
- webrtc 音视频采集
- webrtc 音视频约束
- webrtc 浏览器视频特效
- webrtc 从视频中获取图片
- webrtc 只采集音频数据
- webrtc MediaStream和获取视频约束
- webrtc 媒体流的录制
- webrtc 捕获桌面
- webrtc 信令服务器
- webrtc 传输基本知识
- webrtc NAT
- webrtc ICE
- webrtc 媒体能力协商
- webrtc 端到端链接的基本流程
- webrtc SDP
- webrtc STUN/TURN
- webrtc 客户端信令消息
- webrtc 视频通话实现
- webrtc 传输速率控制
- webrtc 统计信息
- webrtc IOS
- Kamailio
- webrtc的分析
- Webrtc音视频会议之Mesh/MCU/SFU三种架构
- RTSP / RTP / RTCP协议
- RTMP / RTSP / WebRTC之间的关系
- webrtc源码
- PeerConnection解析
- FFmpeg
- FFmpeg命令行的使用
- ffmpeg命令语法
- FFmpeg设备采集
- FFmpeg生成水印
- FFmpeg画中画和视频多宫格
- FFmpeg定时截图
- FFmpeg基本概念
- FFmpeg基本模块
- ffmpeg 滤镜处理
- ffmpeg流的指定
- FFmpeg相关api
- 基本函数
- 打印音视频信息
- 抽取音视频数据
- 捕捉摄像头并推流
- FFmpeg拉流截图
- vs2017编译错误
- 自定义跨平台FFmpeg播放器
- ffmpeg拉流并且使用qt
- ffmpeg读取摄像头并且推流
- ASS和SRT字幕有何区别
- 解决ffmpeg 在avformat_find_stream_info执行时间太长
- sws_getContext()处理AV_PIX_FMT_NONE 帧格式引起的core dump
- OWT系列
- owt-server
- owt-server 编译运行
- owt-server模块
- owt-client-javascript解析
- owt-client-android
- owt-android编译运行
- owt-client-android系列分析
- owt-conference
- Licode
- licode安装
- licode 系列
- basic example client
- basic example server
- 音视频基础概念
- 视频播放中的码率的概念
- 帧率
- nginx-rtmp 模块搭建与使用
- RTMP分析
- RTMP规范
- RTMP流媒体播放过程
- 一段简单的CMakeLists.txt
- Go
- Go Base
- Go 环境安装
- mod
- Go 流程控制
- interface convert to string/int/float64
- Go mod拉取私有仓库
- VSCode配置go环境
- Go 设置代理
- Viper读取配置文件
- vim打造成go的ide
- Go 交叉编译
- GO 简单功能
- Golang发起http请求
- Go 定时任务
- websocket协议
- Golang的定时器
- JWT认证
- Google Protobuf 请求参数为空的案例
- Go文件下载
- Go 服务热更新方案
- Go 静态服务器
- gocolly的使用
- golang中获取字符串长度的几种方法
- hugo搭建静态博客
- go利用reids实现分布式锁
- Go 代理
- Go 简单http代理
- Go SS代理流程
- Go AES加密和解密的三种模式实现(CBC/ECB/CFB)
- Go 负载均衡
- Go 标准库
- reflect.Type和reflect.Value
- container & list & ring & heap
- Context
- http 请求
- Go base64
- Go struct <=> json
- Go切片合并
- Go 包的使用
- pprof包的使用
- Go Grpc
- ymal 配置文件
- 日志包 logrus / zap
- Go 命令行多指令操作
- Cobra/viper 命令行解析
- Go sync/atomic
- zap日志
- Go 进阶
- Go sync.Mutex详解
- 使用自定义头和protobuf解决沾包问题
- 使用 build tag 来自定义构建配置
- 使用valgrind检测程序是否内存泄露
- Go参数传递是值传递还是引用传递
- Go 切片/数组
- Channel的使用
- Go Interface详解
- GO-IM系统
- IM架构
- Go搭建一个http服务器
- mattermost-server
- matter编译部署
- mattermost配置
- matter详解
- Goim
- Centrifugo
- Tinode
- cgo入门
- GO语言中使用C语言
- reflect.StringHeader和reflect.SliceHeader
- Cgo使用libevent库实现一个定时器
- cgo遍历C结构体数组
- Go和C之间的类型转换
- Elasticsearch
- Elasticsearch安装
- etcd的使用
- etcd 安装
- Docker
- Docker 安装部署
- 修改Docker镜像源
- 使用Dockerfile构建部署项目
- 使用Dockerfile多阶段构建
- Dockerfile指令解析
- Volume
- 创建一个images
- Docker容器管理
- Shipyard
- Portainer
- lazydocker-docker 终端ui管理
- Docker 容器-ssh登录
- Dockerfile CMD启动命令
- Docker 容器独立ip
- 清理 Docker文件
- Docker-Composer
- Docker远程访问
- Docker 远程访问API设置
- Docker 结合IDEA使用
- Docker 使用错误
- Docker镜像瘦身
- Docker查看退出码 exitCode
- Docker安装宝塔
- Docker创建calibre-web
- Docker不能使用gdb调试的解决方案
- k8s
- K8s安装部署
- 安装部署coreDNS
- web管理之一 Dashboard
- dashboard的yaml文件
- 集群监控 heapster
- 资源监控 metrics
- web管理之二 Prometheus
- idea k8s插件
- 第一个 k8s应用
- k8s将pod在master上运行
- k8s网络通信模型
- Deployment和Pod区别
- Statefulset的基本使用
- k8s的持久化存储 PersistentVolume
- Ingress基本用法
- k8s错误处理
- 角色权限
- busybox k8s的调试工具
- nfs的安装和使用
- Kafka
- kafka介绍
- Redis
- Redis的安装
- Redis主从配置
- Redis数据类型
- Redis-Set
- Redis-Hash
- Redis设计与实现
- 第一节:sds
- 第二节:链表的实现
- 第三节:字典的实现(一) - 基本原理
- 第四节:字典的实现(二) - 哈希算法
- 第五节:字典的实现(三) - 哈希冲突解决方案
- 第六节:字典的实现(四) - rehash原理
- 第七节:跳跃表
- 第七节:整数集合
- 第八节:压缩列表
- 第九节:对象
- 总结
- Redis源码分析
- 配置VScode调试Redis源码
- VScode调试Redis源码,指针显示的问题
- Redis模块概述
- Redis的五个数据类型
- sds字符串分析
- adlist分析
- ziplist压缩列表
- quicklist
- dict字典--hashtable
- zskiplist-跳跃表
- sparkline微线图
- Redis源码的一些基础知识总结
- 在redis中遇见redisObject struct
- acl库编写Redis客户端
- hireids操作
- 当内存耗尽时,redis怎么做
- 如何保证redis的高并发及高可用?
- 使用redis实现分布式锁
- Redis管道技术测试
- MongoDB
- MongoDB安装
- MongoDB免安装版
- Mongodb C Driver驱动安装
- MongoDB知识点
- MongoDB基础
- MongodB原子操作
- MongoDB索引
- MongoDB主从/副本集
- MongoDB分片集群
- MongoDB性能检测
- MongoDB构建模式
- Mongo-cxx-driver
- mongo-c-driver
- MongoDB用户操作
- MySQL
- MySQL安装
- 一个机器多个MySQL
- 创建远程链接
- 字段编辑
- 存储过程
- MySQL严格模式
- Mysql 丢失Root密码
- 中国全省市表
- 高性能MySQL
- MySQL并发控制
- MySQL基准测试
- MySQL服务器性能剖析
- MySQLSchema与数据类型优化
- MySQL创建高性能索引
- MySQL复制
- MySQL-高可用
- MySQL引擎
- DB
- Oracle
- ORACLE9i安装
- Oracle存储过程
- Oracle 存储过程基础组件
- Oracle存储过程示例
- Other Language
- Python
- python编程通用概念
- python安装
- pycharm-docker调试
- Python安装AES加密
- python安装pip
- 错误
- py框架
- Django
- 开始一个项目
- 路由
- 模型层
- 创建博客文章模型
- Django Shell
- 初识Django Admin模块
- 实现博客数据返回页面
- 初始Django视图与模板
- boot静态页面
- django分页
- Django设置
- djangocms
- 语言特性
- 切片
- PHP
- php外部扩展
- 添加C扩展
- 添加外部C扩展
- 添加redis
- redis
- 下载
- 封装
- 外部访问配置
- redis基本操作
- 框架
- TP5
- Model
- 自动写入时间戳
- Laravel
- 安装
- TP3.2
- CACHE缓存
- create
- curl
- 文件下载
- 模块名字
- 常用工具
- 功能代码
- 检测磁盘剩余空间
- 静态类
- 消除html标签
- 检测手机号
- 毫秒 == 日期格式
- jQuery
- 找子元素
- php网络编程
- socket
- socket_server.php
- socket_client.php
- websocket
- websocket_server.php
- websocket_client.html
- websocket_unit.js
- swoole
- 环境依赖及安装
- 搭环境
- windows搭建apache+php7
- nginx做成服务顺便配置php
- Lua
- Lua环境安装
- lua api
- lua_pop & lua_settop
- lua_next
- JAVA
- Java通用编程概念
- Java环境安装
- 编译遇到的问题
- 请求接口
- java变量类型
- Android
- IDEA 配置 gradle
- Rust
- Rust编程通用概念
- Rust安装
- 更换crates源
- 写一个hello world
- 变量可变性
- 数据类型
- Struct+方法语法
- 赋值
- tokio网络框架
- tokio安装
- EchoServer
- 实现Future
- 组合器
- shadowsocket-rust
- shadowsocket-rust安装
- Scheme
- 环境搭建及基本语法
- JavaScript
- NodeJs
- React
- React-Native
- 使用pkg打包
- Nginx
- Nginx-反向代理
- OpenResty初探
- OpenResty做一个postman
- lua没有continue
- nginx 配置静态服务器
- 将luarocks整合进openresty,并安装lfs
- Git
- GitHub基本操作
- Github跟本地的配置和操作
- GitHub搜索
- Github镜像
- git修改远程仓库
- Git基本操作
- 安装gitlab
- VC工程的.gitignore
- Git 设置代理
- Git克隆部分文件
- Linux
- 用户操作
- 防火墙操作
- 压缩
- Linux时间同步
- CURL
- Linux samba文件共享
- 使用cat创建新文件并追加内容
- htop / glances / dstat
- IPC错误
- nc的使用
- 核与线程 CPU 4核8线程 的解释
- Linux 使用 MLDonkey 下载 ed2k
- Linux技巧
- LINUX技巧-查找文件行中值重复的行
- tcpdump 抓包
- 日志查找
- nethogs 查看网络流量
- 系统中加入库目录
- 将root权限的文件改为用户权限
- linux 打开文件数 too many open files 解决方法
- 查看系统CPU/GPU/磁盘io
- 快速删除大量文件的方法
- Linux-文件传输
- 安装 nvidia 驱动
- 改造VIM
- 通过vimplus项目一键配置vim
- 自定义vim配置C++IDE
- 终端配色
- VIM+项目管理
- vimplus快捷键
- 自动切换输入法
- Shell编程
- shell脚本守护进程
- if [ $# -eq 0 ]该语句是什么含义?
- 从命令行提示输入,和自动输入,自动交互
- grep指令
- cut指令
- awk指令
- xargs
- 使用except自动交互
- Ubuntu
- 界面安装
- 更换源
- Ubuntu安装docker
- Ubuntu18 安装qt
- 更新密钥
- Ubuntu开启远程登录
- Ubuntu16.04界面无法启动
- apt-get install 没有自动安装
- dpkg: 处理软件包 nginx (--configure)时出错
- ubuntu下浏览器使用代理
- Ubuntu把放大缩小按钮移动到左边
- wine 安装错误
- Ubuntu下安装Microsoft to do
- 在Ubuntu上使用ssh连接另外一台机器出问题
- 解决windows和ubuntu16.04虚拟机拖放问题
- 解决apt-get /var/lib/dpkg/lock-frontend 问题
- Ubuntu安装cinnamon
- sudo apt-get update错误
- googlechrome
- Ubuntu16.04安装xmind
- Ubuntu下载迅雷
- Linux护眼宝
- 查看Ubuntu安装的界面
- 使用aria2
- CentOS7使用yum安装gcc
- System
- MAC
- 安装软件
- mac基本操作
- 安装pod
- 改造终端
- VIM配置
- Chroom浏览器https访问
- mac摄像头打不开
- Mac与Windows或Linux的键鼠共享神器Synergy
- Windows
- 小工具
- bat文件的使用
- bat把exe文件做成单击右键可运行的
- copy
- 注册 dll
- 镜像==分区
- choco
- BaiduPCS-go
- tail日志查看命令
- 右键菜单没有选项
- Proxy SwitchyOmega
- Google云服务器配置
- 百度网盘不限速
- 远程桌面
- 百度地图离线开发
- 查看端口
- SC命令使用
- 开发
- TIME_WAIT过多导致服务不能被访问
- 修改win的默认编码
- 百度网盘二维码刷新不出来
- 移动端
- Object-C
- 录音跟播放
- 视频的采集跟播放
- Swift
- Swift编程通用概念
- Switf环境安装
- Swift Package Manager(SPM)
- 手动导入库
- PerfectTemplate的使用
- PerfectTemplate环境搭建
- ios直播开发
- Simple-RTMP-Server
- Mac上安装ffmpeg环境
- 推流拉流
- 仿直播app开发
- 框架搭建
- 开发流程
- React-Native
- React-native环境安装
- 分布式追踪系统
- Jaeger 客户端库
- LightStep 的使用
- 软件
- PhpStorm
- 安装ThinkStrom
- 添加xdebug
- Clion
- C++开发配置
- 激活码
- 在linux上制作桌面图标
- Vagrant
- VMWare
- VirtualBox
- proxifier + Shadowshocks
- Cmder
- Navicate For MongoDB
- MinDoc
- GitHub速度慢
- 科学
- VMware虚拟机磁盘操作占用过高问题
- PhotoShop+Premiere下载
- ActionView安装部署
- 读书笔记
- 博客
- hexo
- 部署
- jekyll
- 在线编译器
- 书屋
- 如何阅读一本书
- 个人发展
- Linux高性能服务器读书笔记
- TCP/IP协议族
- IP协议
- TCP协议详解
- TCP协议的拥塞控制
- 安全测试
- 常见web安全漏洞
- 程序设计
- log日志设计
- 爬虫项目
- Python3.7的安装
- Scrapy的安装和使用
- Colly框架
- Crawlab是一款款里爬虫的web框架
- 英文学习