
## 调度器调度场景过程全解析
(1) 场景 1
P 拥有 G1,M1 获取 P 后开始运行 G1,G1 使用 go func() 创建了 G2,为了局部性 G2 优先加入到 P1 的本地队列。
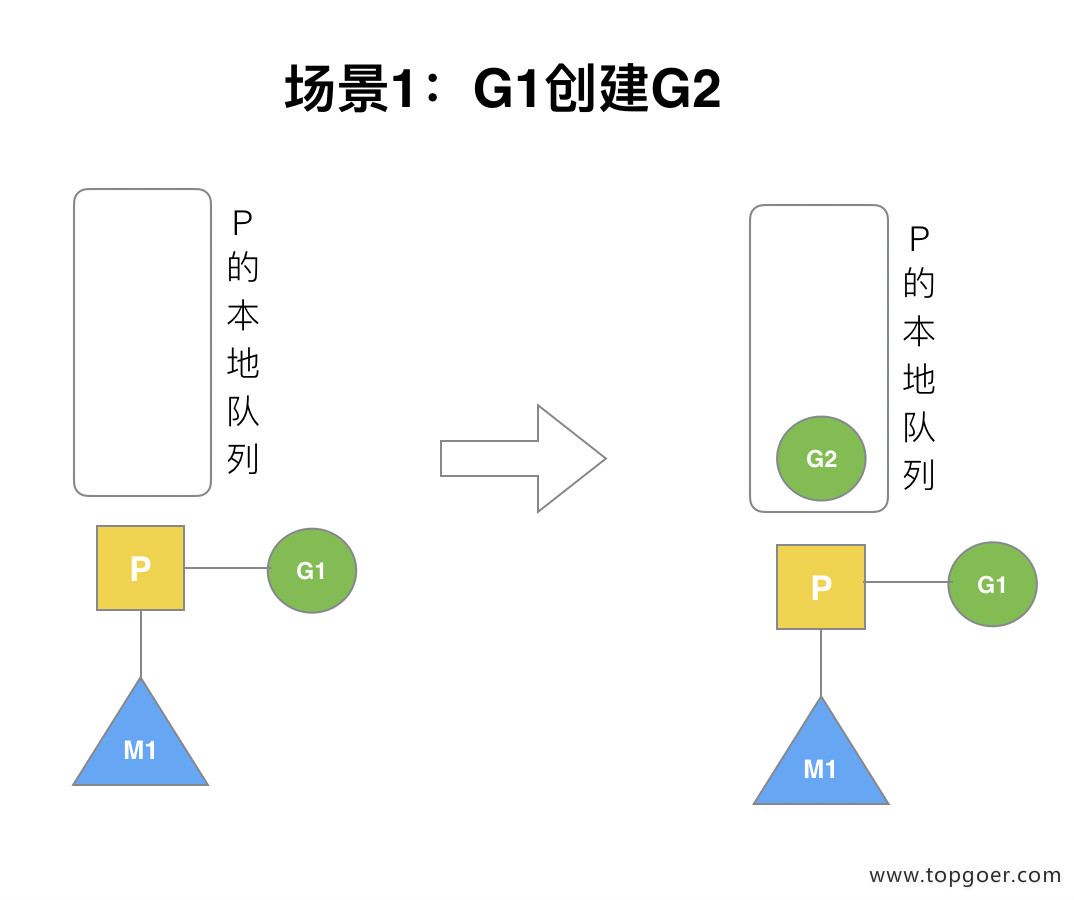
(2) 场景 2
G1 运行完成后 (函数:goexit),M 上运行的 goroutine 切换为 G0,G0 负责调度时协程的切换(函数:schedule)。从 P 的本地队列取 G2,从 G0 切换到 G2,并开始运行 G2 (函数:execute)。实现了线程 M1 的复用。
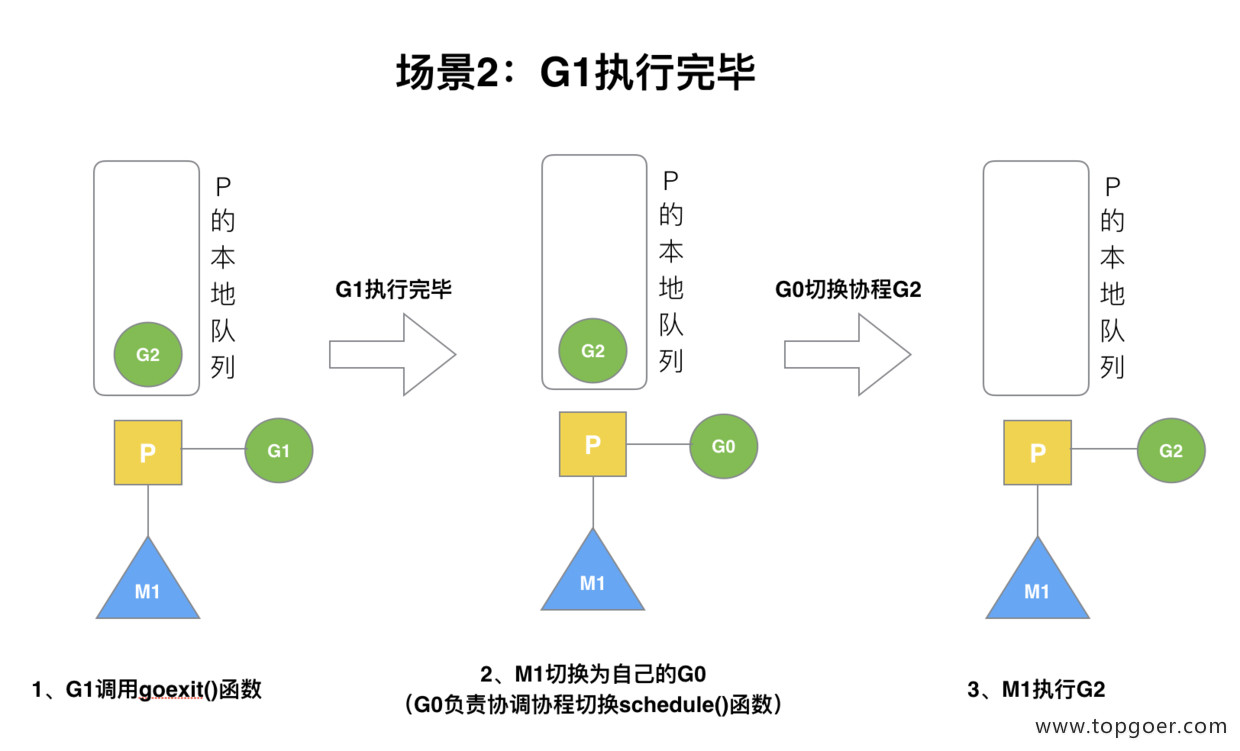
(3) 场景 3
假设每个 P 的本地队列只能存 3 个 G。G2 要创建了 6 个 G,前 3 个 G(G3, G4, G5)已经加入 p1 的本地队列,p1 本地队列满了。
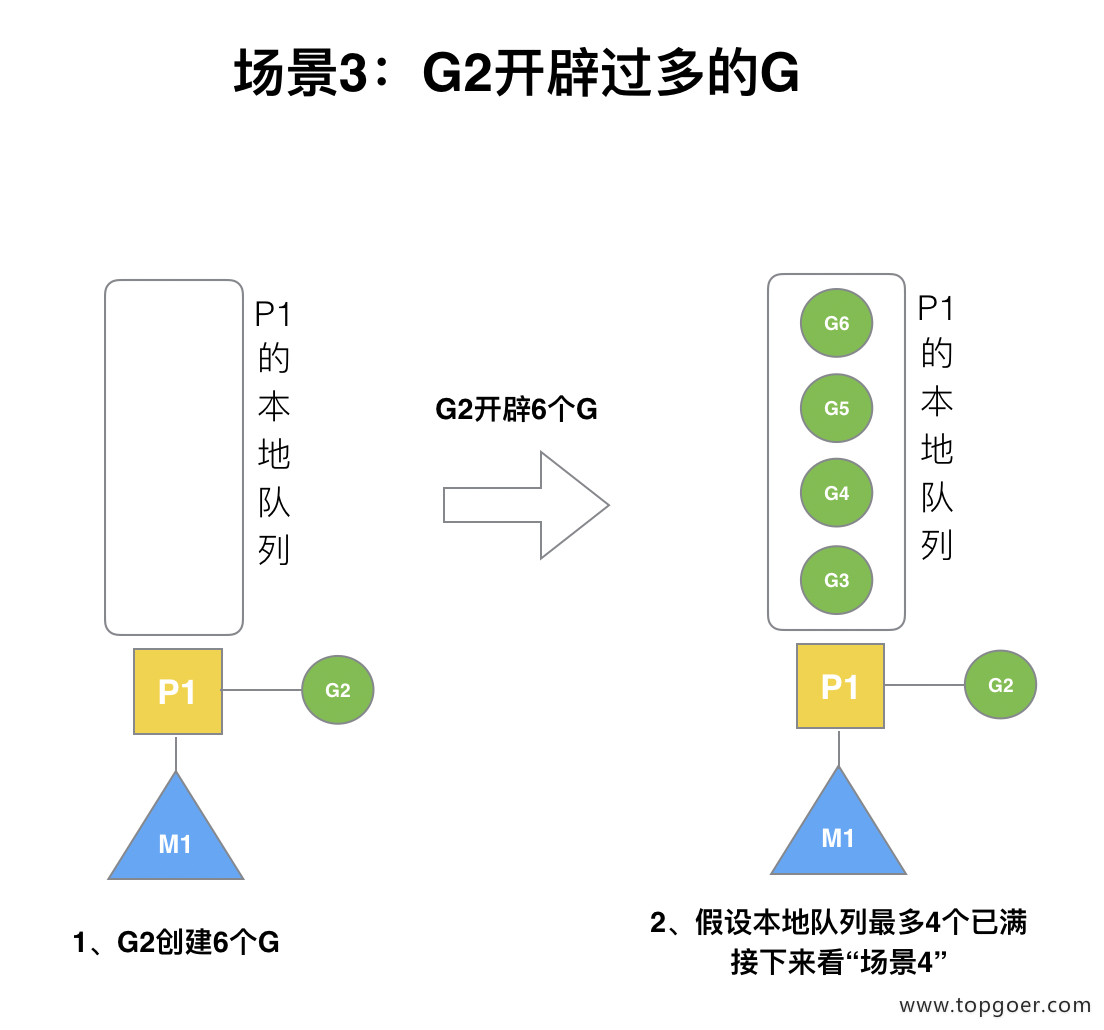
(4) 场景 4
G2 在创建 G7 的时候,发现 P1 的本地队列已满,需要执行负载均衡 (把 P1 中本地队列中前一半的 G,还有新创建 G 转移到全局队列)
> (实现中并不一定是新的 G,如果 G 是 G2 之后就执行的,会被保存在本地队列,利用某个老的 G 替换新 G 加入全局队列)
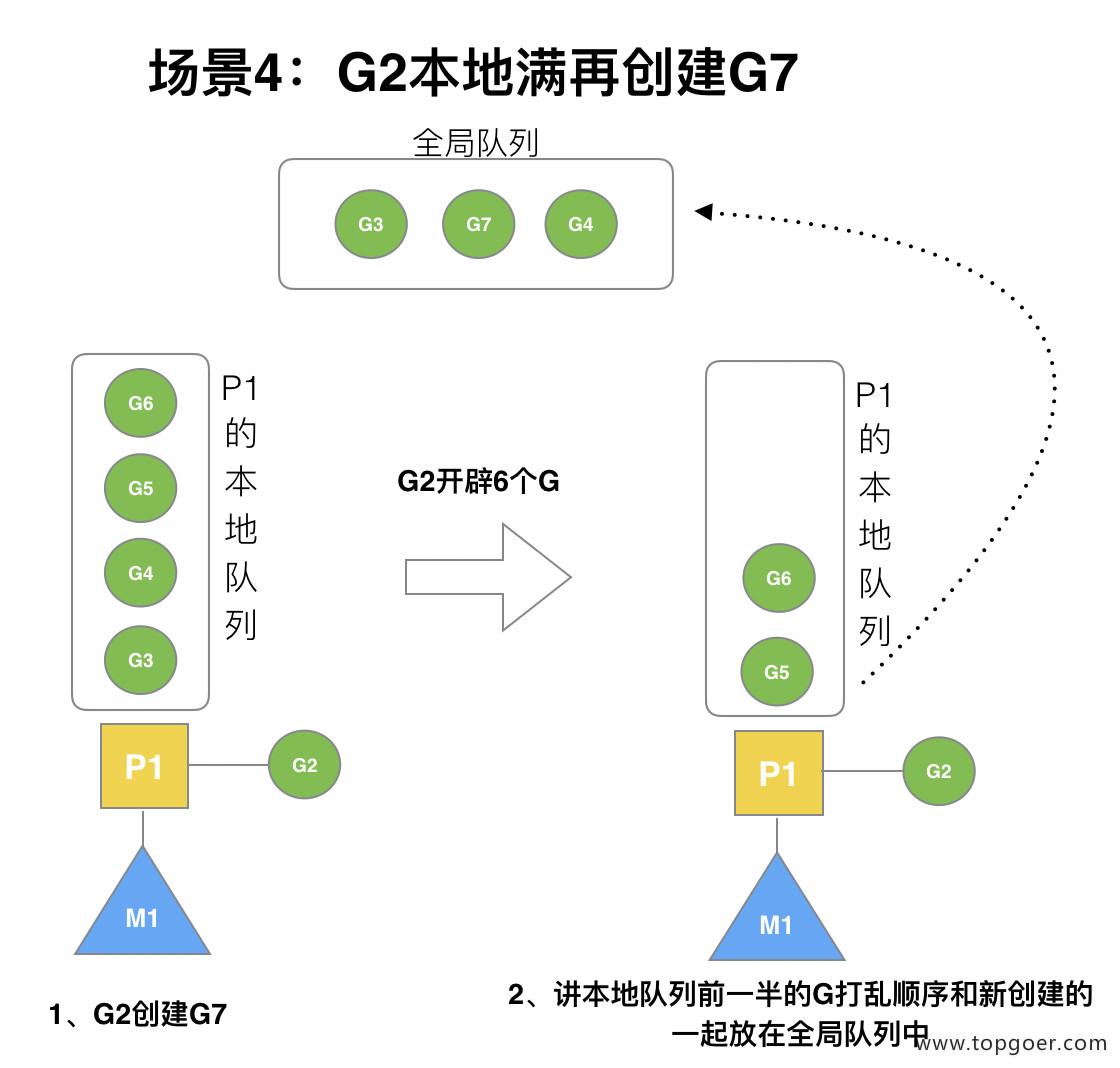
这些 G 被转移到全局队列时,会被打乱顺序。所以 G3,G4,G7 被转移到全局队列。
(5) 场景 5
G2 创建 G8 时,P1 的本地队列未满,所以 G8 会被加入到 P1 的本地队列。
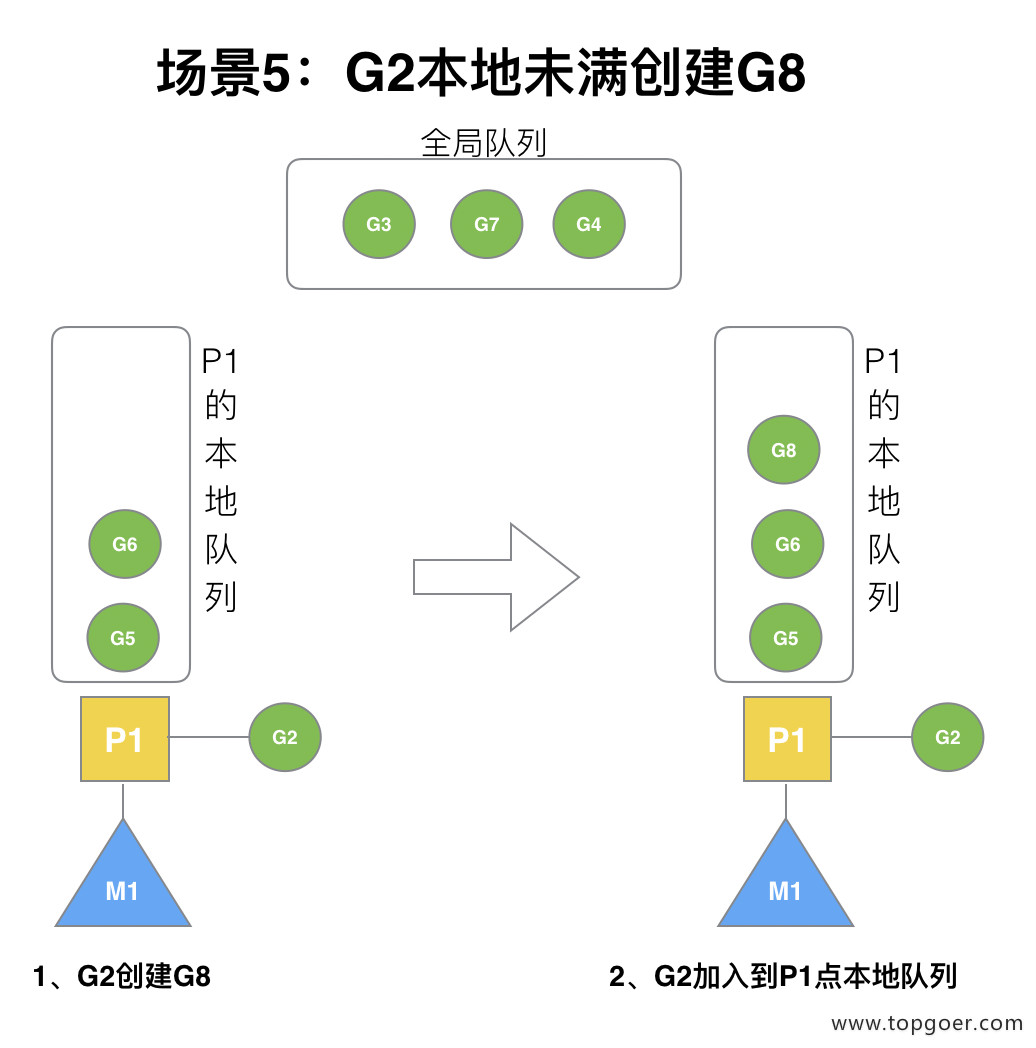
G8 加入到 P1 点本地队列的原因还是因为 P1 此时在与 M1 绑定,而 G2 此时是 M1 在执行。所以 G2 创建的新的 G 会优先放置到自己的 M 绑定的 P 上。
(6) 场景 6
规定:在创建 G 时,运行的 G 会尝试唤醒其他空闲的 P 和 M 组合去执行。
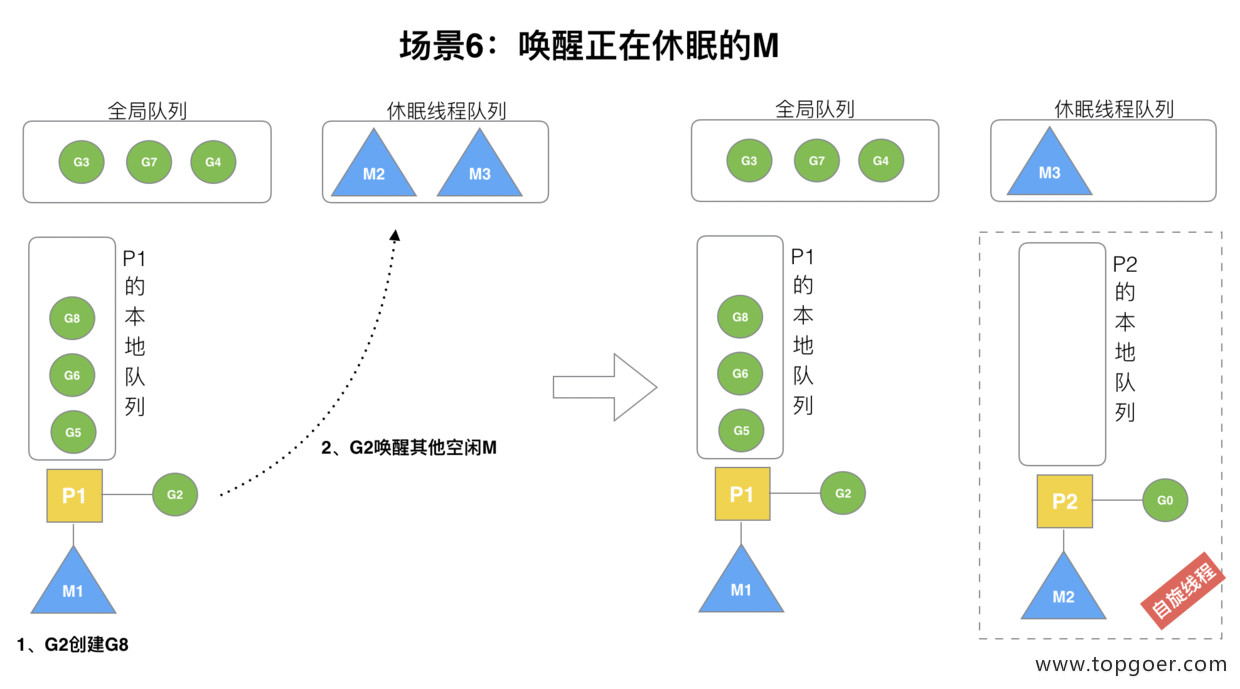
假定 G2 唤醒了 M2,M2 绑定了 P2,并运行 G0,但 P2 本地队列没有 G,M2 此时为自旋线程(没有 G 但为运行状态的线程,不断寻找 G)。
(7) 场景 7
M2 尝试从全局队列 (简称 “GQ”) 取一批 G 放到 P2 的本地队列(函数:findrunnable())。M2 从全局队列取的 G 数量符合下面的公式:
> n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
至少从全局队列取 1 个 g,但每次不要从全局队列移动太多的 g 到 p 本地队列,给其他 p 留点。这是从全局队列到 P 本地队列的负载均衡。
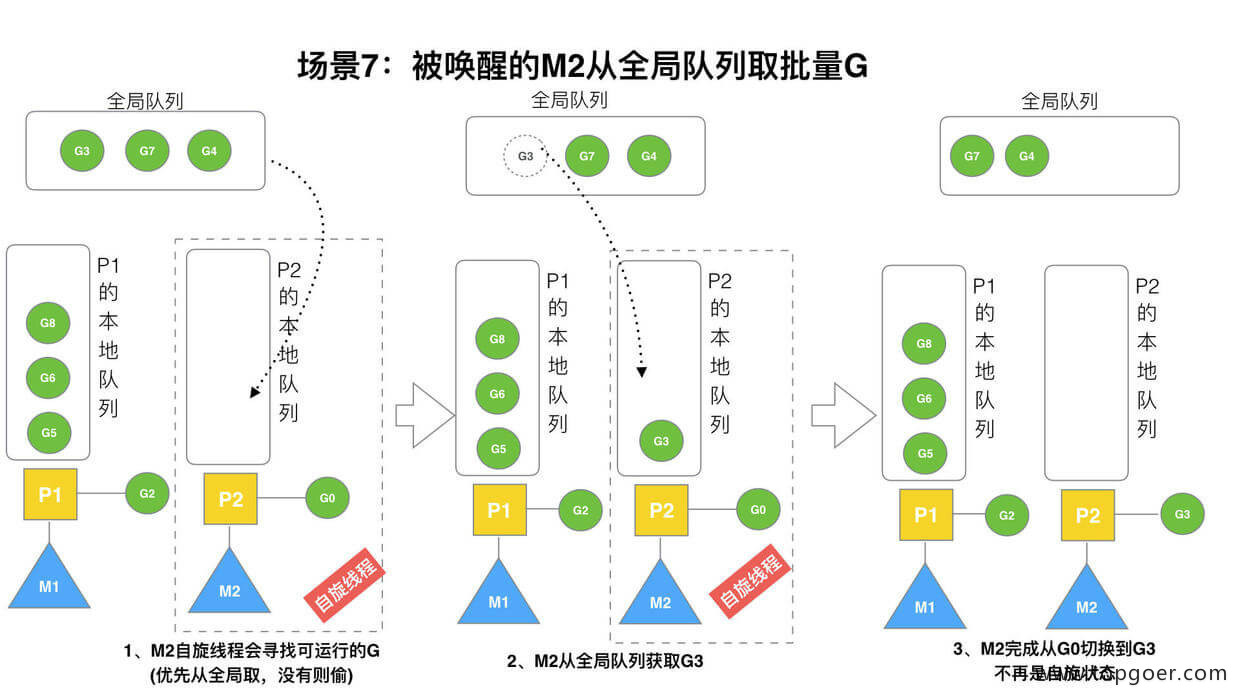
假定我们场景中一共有 4 个 P(GOMAXPROCS 设置为 4,那么我们允许最多就能用 4 个 P 来供 M 使用)。所以 M2 只从能从全局队列取 1 个 G(即 G3)移动 P2 本地队列,然后完成从 G0 到 G3 的切换,运行 G3。
(8) 场景 8
假设 G2 一直在 M1 上运行,经过 2 轮后,M2 已经把 G7、G4 从全局队列获取到了 P2 的本地队列并完成运行,全局队列和 P2 的本地队列都空了,如场景 8 图的左半部分。
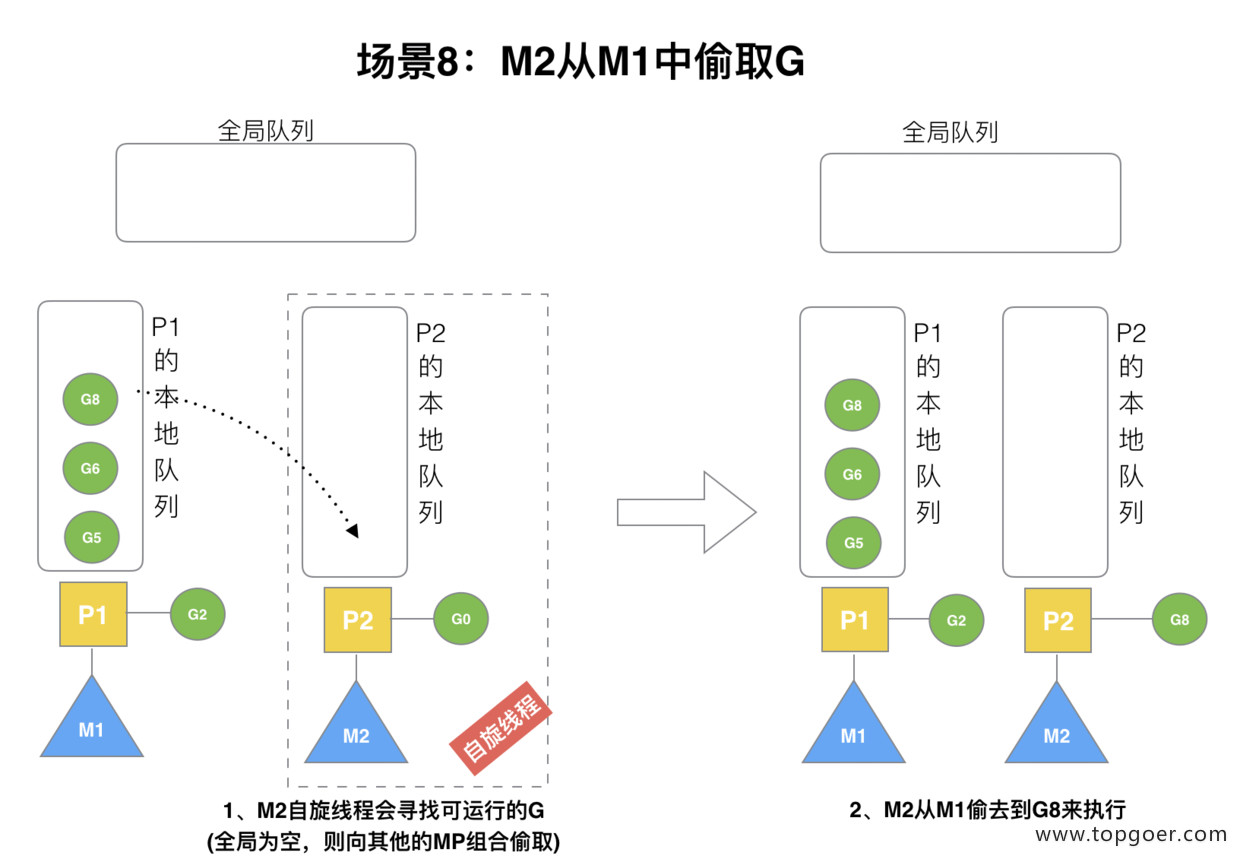
全局队列已经没有 G,那 m 就要执行 work stealing (偷取):从其他有 G 的 P 哪里偷取一半 G 过来,放到自己的 P 本地队列。P2 从 P1 的本地队列尾部取一半的 G,本例中一半则只有 1 个 G8,放到 P2 的本地队列并执行。
(9) 场景 9
G1 本地队列 G5、G6 已经被其他 M 偷走并运行完成,当前 M1 和 M2 分别在运行 G2 和 G8,M3 和 M4 没有 goroutine 可以运行,M3 和 M4 处于自旋状态,它们不断寻找 goroutine。
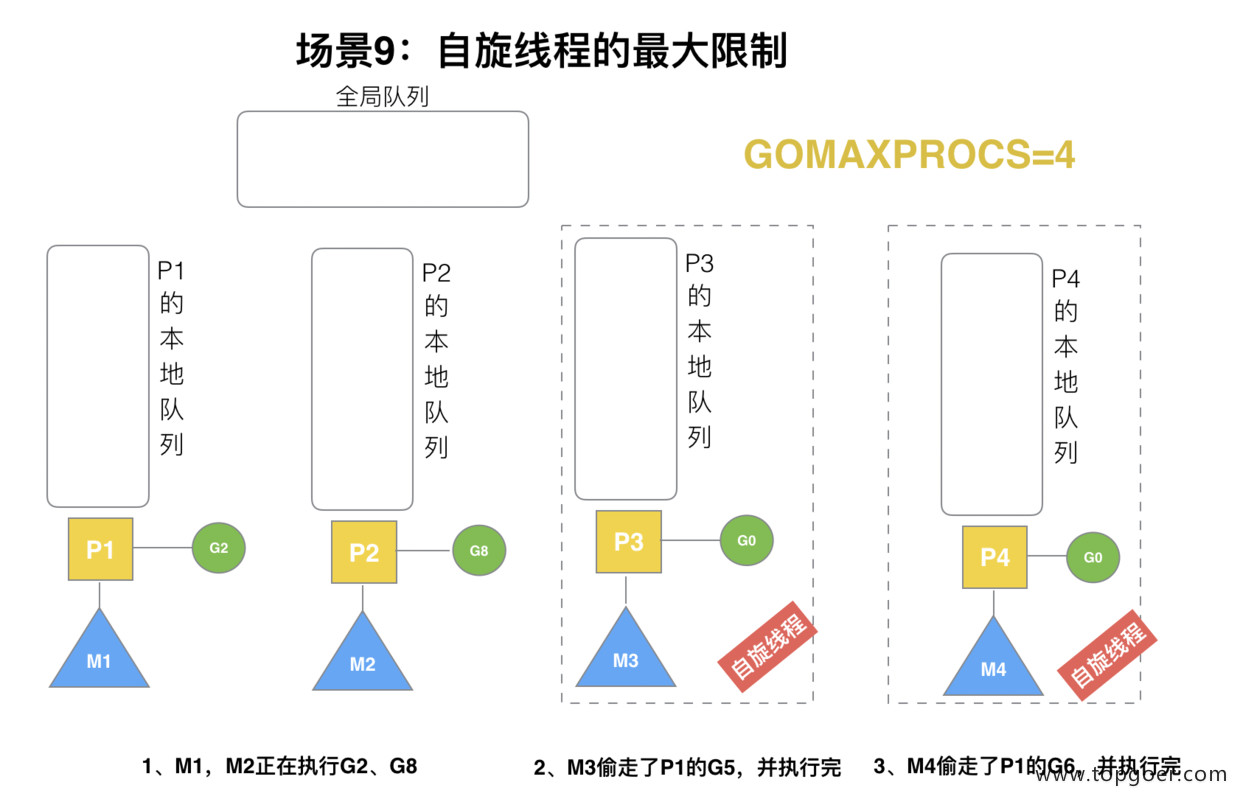
为什么要让 m3 和 m4 自旋,自旋本质是在运行,线程在运行却没有执行 G,就变成了浪费 CPU. 为什么不销毁现场,来节约 CPU 资源。因为创建和销毁 CPU 也会浪费时间,我们希望当有新 goroutine 创建时,立刻能有 M 运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程 (当前例子中的 GOMAXPROCS=4,所以一共 4 个 P),多余的没事做线程会让他们休眠。
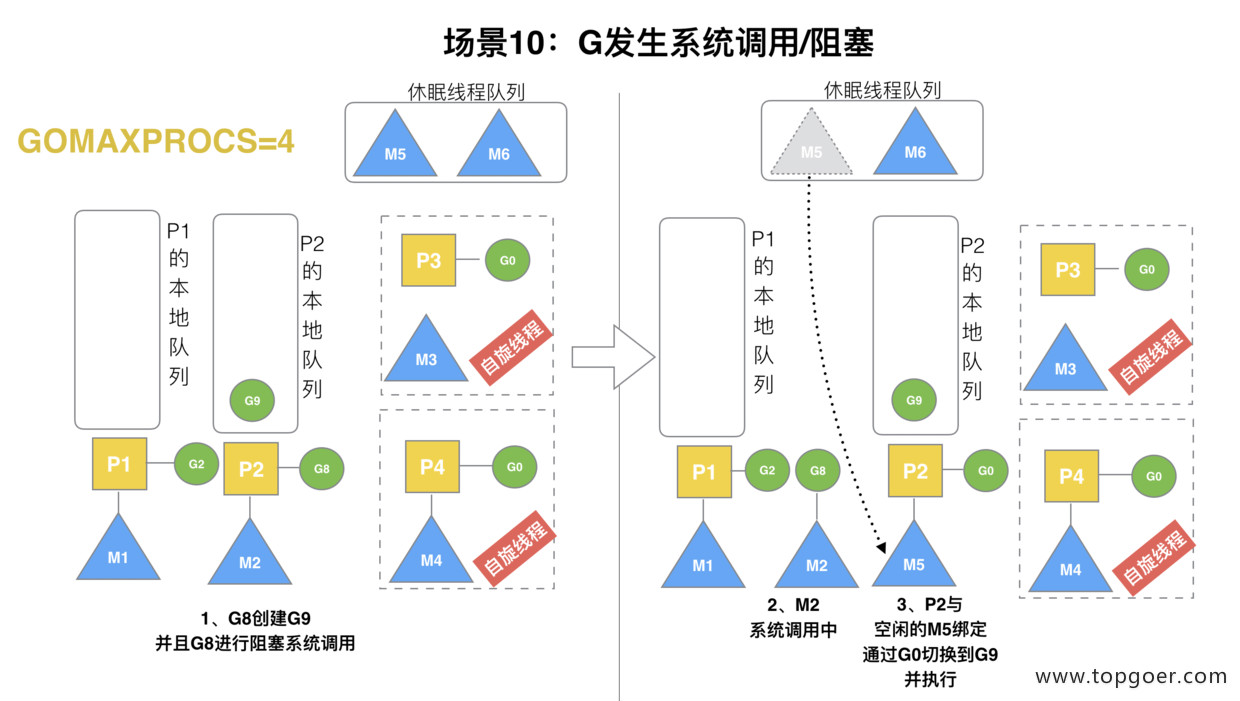
(10) 场景 10
假定当前除了 M3 和 M4 为自旋线程,还有 M5 和 M6 为空闲的线程 (没有得到 P 的绑定,注意我们这里最多就只能够存在 4 个 P,所以 P 的数量应该永远是 M>=P, 大部分都是 M 在抢占需要运行的 P),G8 创建了 G9,G8 进行了阻塞的系统调用,M2 和 P2 立即解绑,P2 会执行以下判断:如果 P2 本地队列有 G、全局队列有 G 或有空闲的 M,P2 都会立马唤醒 1 个 M 和它绑定,否则 P2 则会加入到空闲 P 列表,等待 M 来获取可用的 p。本场景中,P2 本地队列有 G9,可以和其他空闲的线程 M5 绑定。
(11) 场景 11
G8 创建了 G9,假如 G8 进行了非阻塞系统调用。
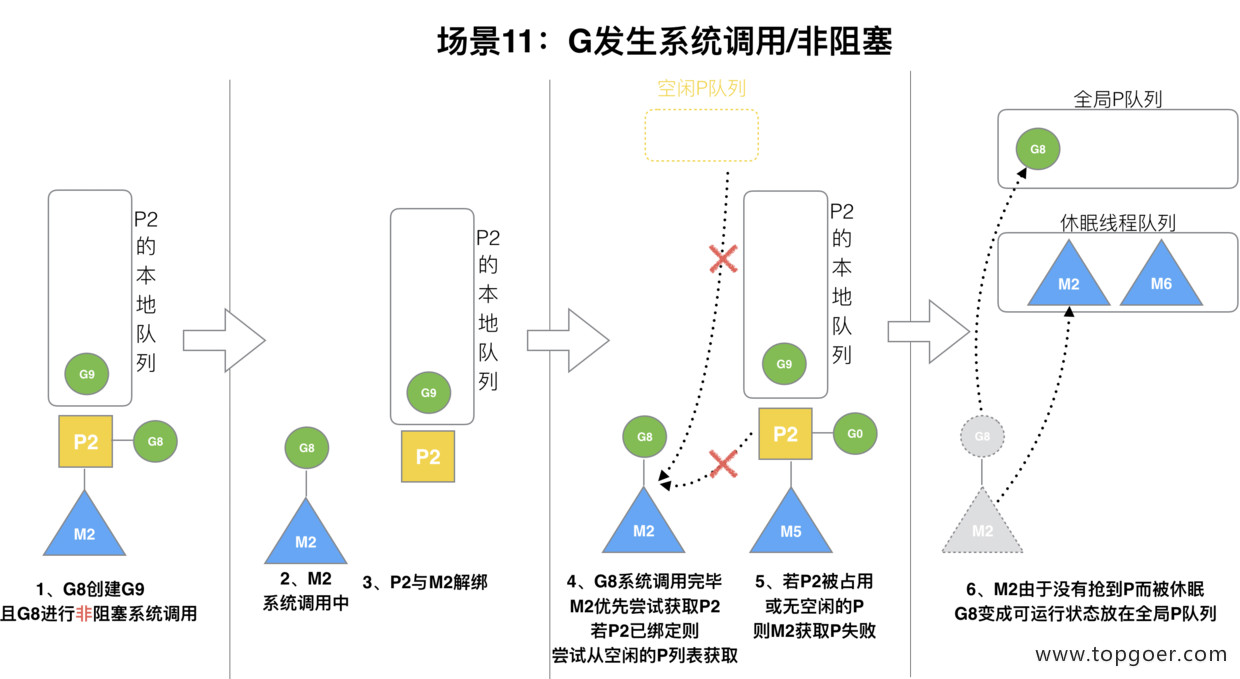
M2 和 P2 会解绑,但 M2 会记住 P2,然后 G8 和 M2 进入系统调用状态。当 G8 和 M2 退出系统调用时,会尝试获取 P2,如果无法获取,则获取空闲的 P,如果依然没有,G8 会被记为可运行状态,并加入到全局队列,M2 因为没有 P 的绑定而变成休眠状态 (长时间休眠等待 GC 回收销毁)
- 概述
- go语言基础特性
- Go语言声明
- Go项目构建及编译
- go command
- 程序设计原则
- Go基础
- 变量
- 常量
- iota
- 基本类型
- byte和rune类型
- 类型定义和类型别名
- 数组
- string
- 高效字符串连接
- string底层原理
- 运算符
- new
- make
- 指针
- 下划线 & import
- 语法糖
- 简短变量申明
- 流程控制
- ifelse
- switch
- select
- select实现原理
- select常见案例
- for
- range
- range实现原理
- 常见案例
- range陷阱
- Goto&Break&Continue
- Go函数
- 函数
- 可变参数函数
- 高阶函数
- init函数和main函数
- 匿名函数
- 闭包
- 常用内置函数
- defer
- defer常见案例
- defer规则
- defer与函数返回值
- defer实现原理
- defer陷阱
- 数据结构
- slice
- slice内存布局
- slice&array
- slice底层实现
- slice陷阱
- map
- Map实现原理
- 集合
- List
- Set
- 线程安全数据结构
- sync.Map
- Concurrent Map
- 面向对象编程
- struct
- 匿名结构体&匿名字段
- 嵌套结构体
- 结构体的“继承”
- struct tag
- 行为方法
- 方法与函数
- type Method Value & Method Expressions
- interface
- 类型断言
- 多态
- 错误机制
- error
- 自定义错误
- panic&recover
- reflect
- reflect包
- 应用示例
- DeepEqual
- 反射-fillObjectField
- 反射-copyObject
- IO
- 读取文件
- 写文件
- bufio
- ioutil
- Go网络编程
- tcp
- tcp粘包
- udp
- HTTP
- http服务
- httprouter
- webSocket
- go并发编程
- Goroutine
- thread vs goroutine
- Goroutine任务取消
- 通过channel广播实现
- Context
- Goroutine调度机制
- goroutine调度器1.0
- GMP模型调度器
- 调度器窃取策略
- 调度器的生命周期
- 调度过程全解析
- channel
- 无缓冲的通道
- 缓冲信道
- 单向信道
- chan实现原理
- 共享内存并发机制
- mutex互斥锁
- mutex
- mutex原理
- mutex模式
- RWLock
- 使用信道处理竞态条件
- WaitGroup
- 工作池
- 并发任务
- once运行一次
- 仅需任意任务完成
- 所有任务完成
- 对象池
- 定时器Timer
- Timer
- Timer实现原理
- 周期性定时器Ticker
- Ticker对外接口
- ticker使用场景
- ticker实现原理
- ticker使用陷阱
- 包和依赖管理
- package
- 依赖管理
- 测试
- 单元测试
- 表格测试法
- Banchmark
- BDD
- 常用架构模式
- Pipe-filter pattern
- Micro Kernel
- JSON
- json-内置解析器
- easyjson
- 性能分析
- gc
- 工具类
- fmt
- Time
- builtin
- unsafe
- sync.pool
- atomic
- flag
- runtime
- strconv
- template