
[TOC]
前言
有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page\_source方法可以获取到页面源码。
selenium的page\_source方法很少有人用到,小编最近看api不小心发现这个方法,于是突发奇想,这里结合python的re模块用正则表达式爬出页面上所有的url地址,可以批量请求页面url地址,看是否存在404等异常
<br />
## 一、page_source
1. selenium的page\_source方法可以直接返回页面源码
2. 重新赋值后打印出来
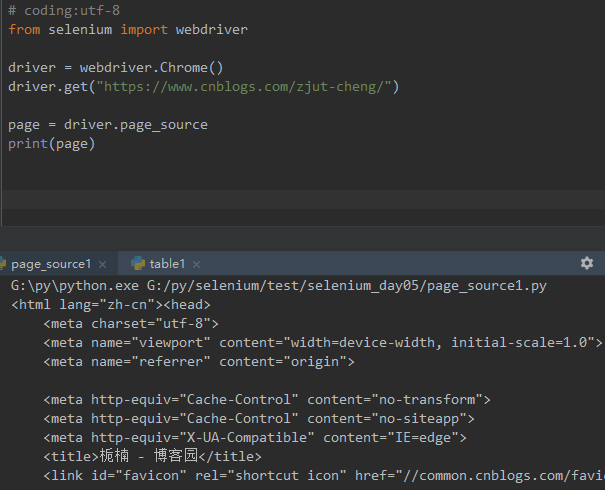
<br />
## 二、re非贪婪模式
1. 这里需导入re模块
2. 用re的正则匹配:非贪婪模式
3. findall方法返回的是一个list集合
4. 匹配出来之后发现有一些不是url链接,可以删选下
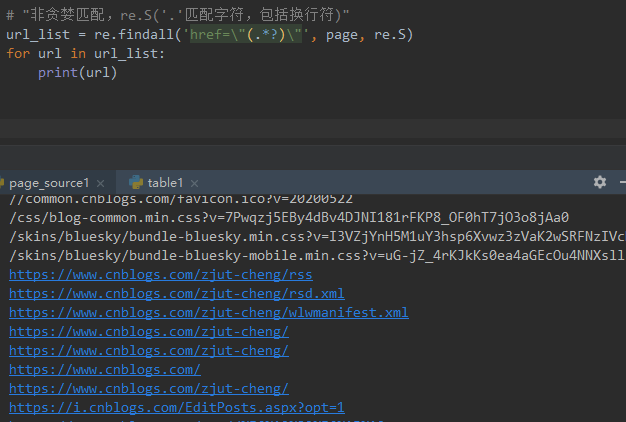
<br />
## 三、删选url地址出来
1. 加个if语句判断,‘http’在url里面说明是正常的url地址了
2. 把所有的url地址放到一个集合,就是我们想要的结果啦
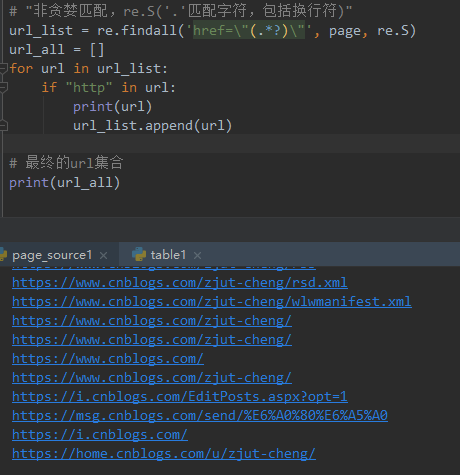
<br />
## 四、参考代码
```
# coding:utf-8
from selenium import webdriver
import re
driver = webdriver.Chrome()
driver.get("https://www.cnblogs.com/zjut-cheng/")
page = driver.page_source
print(page)
# "非贪婪匹配,re.S('.'匹配字符,包括换行符)"
url_list = re.findall('href=\"(.*?)\"', page, re.S)
url_all = []
for url in url_list:
if "http" in url:
print(url)
url_list.append(url)
# 最终的url集合
print(url_all)
```
- Linux
- Linux 文件权限概念
- 重点总结
- Linux 文件与目录管理
- 2.1 文件与目录管理
- 2.2 文件内容查阅
- 文件与文件系统的压缩,打包与备份
- 3.1 Linux 系统常见的压缩指令
- 3.2 打包指令: tar
- vi/vim 程序编辑器
- 4.1 vi 的使用
- 4.2 vim编辑器删除一行或者多行内容
- 进程管理
- 5.1 常用命令使用技巧
- 5.2 进程管理
- 系统服务 (daemons)
- 6.1 通过 systemctl 管理服务
- Linux 系统目录结构
- Linux yum命令
- linux系统查看、修改、更新系统时间(自动同步网络时间)
- top linux下的任务管理器
- Linux基本配置
- CentOS7开启防火墙
- CentOS 使用yum安装 pip
- strace 命令
- Linux下设置固定IP地址
- 查看Linux磁盘及内存占用情况
- Mysql
- 关系数据库概述
- 数据库技术
- 数据库基础语句
- 查询语句(--重点--)
- 约束
- 嵌套查询(子查询)
- 表emp
- MySQL数据库练习
- 01.MySQL数据库练习数据
- 02.MySQL数据库练习题目
- 03.MySQL数据库练习-答案
- Mysql远程连接数据库
- Python
- python基础
- Python3中字符串、列表、数组的转换方法
- python字符串
- python安装、pip基本用法、变量、输入输出、流程控制、循环
- 运算符及优先级、数据类型及常用操作、深浅拷贝
- 虚拟环境(virtualenv)
- 网络编程
- TCP/IP简介
- TCP编程
- UDP编程
- 进程和线程
- 访问数据库
- 使用SQLite
- 使用MySQL
- Web开发
- HTML简介
- Python之日志处理(logging模块)
- 函数式编程
- 高阶函数
- python报错解决
- 启动Python时报“ImportError: No module named site”错误
- python实例
- 01- 用python解决数学题
- 02- 冒泡排序
- 03- 邮件发送(smtplib)
- Django
- 01 Web应用
- Django3.2 教程
- Django简介
- Django环境安装
- 第一个Django应用
- Part 1:请求与响应
- Part 2:模型与后台
- Part 3:视图和模板
- Part 4:表单和类视图
- Part 5:测试
- Part 6:静态文件
- Part 7:自定义admin
- 第一章:模型层
- 实战一:基于Django3.2可重用登录与注册系统
- 1. 搭建项目环境
- 2. 设计数据模型
- 3. admin后台
- 4. url路由和视图
- 5. 前端页面设计
- 6. 登录视图
- 7. Django表单
- 8. 图片验证码
- 9. session会话
- 10. 注册视图
- 实战二:Django3.2之CMDB资产管理系统
- 1.项目需求分析
- 2.模型设计
- 3.数据收集客户端
- 4.收集Windows数据
- 5.Linux下收集数据
- 6.新资产待审批区
- 7.审批新资产
- django 快速搭建blog
- imooc-Django全栈项目开发实战
- redis
- 1.1 Redis简介
- 1.2 安装
- 1.3 配置
- 1.4 服务端和客户端命令
- 1.5 Redis命令
- 1.5.1 Redis命令
- 1.5.2 键(Key)
- 1.5.3 字符串(string)
- 1.5.4 哈希(Hash)
- 1.5.5 列表(list)
- 1.5.6 集合(set)
- 1.5.7 有序集合(sorted set)
- Windows
- Win10安装Ubuntu子系统
- win10远程桌面身份验证错误,要求的函数不受支持
- hm软件测试
- 02 linux基本命令
- Linux终端命令格式
- Linux基本命令(一)
- Linux基本命令(二)
- 02 数据库
- 数据库简介
- 基本概念
- Navicat使用
- SQL语言
- 高级
- 03 深入了解软件测试
- day01
- 04 python基础
- 语言基础
- 程序中的变量
- 程序的输出
- 程序中的运算符
- 数据类型基础
- 数据序列
- 数据类型分类
- 字符串
- 列表
- 元组
- 字典
- 列表与元组的区别详解
- 函数
- 案例综合应用
- 列表推导式
- 名片管理系统
- 文件操作
- 面向对象基础(一)
- 面向对象基础(二)
- 异常、模块
- 05 web自动化测试
- Day01
- Day02
- Day03
- Day04
- Day05
- Day06
- Day07
- Day08
- 06 接口自动化测试
- 软件测试面试大全2020
- 第一章 测试理论
- 软件测试面试
- 一、软件基础知识
- 二、网络基础知识
- 三、数据库
- SQL学生表 — 1
- SQL学生表 — 2
- SQL查询 — 3
- SQL经典面试题 — 4
- 四、linux
- a. linux常用命令
- 五、自动化测试
- 自动化测试
- python 笔试题
- selenium面试题
- 如何判断一个页面上元素是否存在?
- 如何提高脚本的稳定性?
- 如何定位动态元素?
- 如何通过子元素定位父元素?
- 如果截取某一个元素的图片,不要截取全部图片
- 平常遇到过哪些问题?如何解决的
- 一个元素明明定位到了,点击无效(也没报错),如果解决?
- selenium中隐藏元素如何定位?(hidden、display: none)
- 六、接口测试
- 接口测试常规面试题
- 接口自动化面试题
- json和字典dict的区别?
- 测试的数据你放在哪?
- 什么是数据驱动,如何参数化?
- 下个接口请求参数依赖上个接口的返回数据
- 依赖于登录的接口如何处理?
- 依赖第三方的接口如何处理
- 不可逆的操作,如何处理,比如删除一个订单这种接口如何测试
- 接口产生的垃圾数据如何清理
- 一个订单的几种状态如何全部测到,如:未处理,处理中,处理失败,处理成功
- python如何连接数据库操作?
- 七、App测试
- 什么是activity?
- Activity生命周期?
- Android四大组件
- app测试和web测试有什么区别?
- android和ios测试区别?
- app出现ANR,是什么原因导致的?
- App出现crash原因有哪些?
- app对于不稳定偶然出现anr和crash时候你是怎么处理的?
- app的日志如何抓取?
- logcat查看日志步骤
- 你平常会看日志吗, 一般会出现哪些异常
- 抓包工具
- fiddler
- Wireshark
- 安全/渗透测试
- 安全性测试都包含哪些内容?
- 开放性思维题
- 面试题
- 字节测试面试
- 一、计算机网络
- 二、操作系统
- 三、数据库
- 四、数据结构与算法
- 五、Python
- 六、Linux
- 七、测试用例
- 八、智力/场景题
- 九、开放性问题
- python3_收集100+练习题(面试题)
- python3_100道题目答案
- 接口测试
- 接口测试实例_01
- python+requests接口自动化测试框架实例详解
- 性能测试
- 性能测试流程
- 性能测试面试题
- 如何编写性能测试场景用例
- 性能测试:TPS和QPS的区别
- jmeter
- jmeter安装配置教程
- Jmeter性能测试 入门
- PyCharm
- 快捷工具
- 1-MeterSphere
- 一、安装和升级
- 2- MobaXterm 教程
- 3-fiddler抓包
- 4-Xshell
- Xshell的安装和使用
- Xshell远程连接失败怎么解决
- 5-Vmware
- Vmware提示以独占方式锁定此配置文件失败
- Windows10彻底卸载VMWare虚拟机步骤
- VM ware无法关机,虚拟机繁忙
- VMware虚拟机下载与安装
- 解决VM 与 Device/Credential Guard 不兼容。在禁用 Device/Credential Guard 后,可以运行 VM 的方法
- VMware虚拟机镜像克隆与导入
- 6-WPS
- 1.WPS文档里的批注怎么删除
- 2.wps表格中设置图表的坐标
- 3. wps快速绘制数学交集图
- 7-MongoDB
- Win10安装配置MongoDB
- Navicat 15.x for MongoDB安装破解教程
- Apache
- apache层的账户权限控制,以及apache黑名单白名单过滤功能
- HTTP / HTTPS协议
- HTTP协议详解
- 代理
- 状态码详解
- HTTPS详解
- Selenium3+python3
- (A) selenium
- selenium自动化环境搭建(Windows10)
- 火狐firebug和firepath插件安装方法(最新)
- 元素定位工具和方法
- Selenium3+python3自动化
- 新手学习selenium路线图---学前篇
- 1-操作浏览器基本方法
- 2-八种元素定位方法
- 3-CSS定位语法
- 4-登录案例
- 5-定位一组元素find_elements
- 6-操作元素(键盘和鼠标事件)
- 7-多窗口、句柄(handle)
- 8-iframe
- 9-select下拉框
- 10-alert\confirm\prompt
- 11-JS处理滚动条
- 12-单选框和复选框(radiobox、checkbox)
- 13-js处理日历控件(修改readonly属性)
- 14-js处理内嵌div滚动条
- 15-table定位
- 16-js处理多窗口
- 17-文件上传(send_keys)
- 18-获取百度输入联想词
- 19-处理浏览器弹窗
- 20-获取元素属性
- 21-判断元素存在
- 22-爬页面源码(page_source)
- 23-显式等待(WebDriverWait)
- 24-关于面试的题
- 25-cookie相关操作
- 26-判断元素(expected_conditions)
- 27-判断title(title_is)
- 28-元素定位参数化(find_element)
- 29-18种定位方法(find_elements)
- 30- js解决click失效问题
- 31- 判断弹出框存在(alert_is_present)
- 32- 登录方法(参数化)
- 33- 判断文本(text_to_be_present_in_element)
- 34- unittest简介
- 35- unittest执行顺序
- 36- unittest之装饰器(@classmethod)
- 37- unittest之断言(assert)
- 38- 捕获异常(NoSuchElementException)
- 39- 读取Excel数据(xlrd)
- 40- 数据驱动(ddt)
- 41- 异常后截图(screenshot)
- 42- jenkins持续集成环境搭建
- 43- Pycharm上python和unittest两种运行方式
- 44- 定位的坑:class属性有空格
- 45- 只截某个元素的图
- 46- unittest多线程执行用例
- 47- unittest多线程生成报告(BeautifulReport)
- 48- 多线程启动多个不同浏览器
- (B) python3+selenium3实现web UI功能自动化测试框架
- (C) selenium3常见报错处理
- 书籍
- (D)Selenium3自动化测试实战--基于Python语
- 第4章 WebDriver API
- 4.1 从定位元素开始
- 4.2 控制浏览器
- 4.3 WebDriver 中的常用方法
- 4.4 鼠标操作
- 4.5 键盘操作
- 4.6 获得验证信息
- 4.7 设置元素等待
- 4.8 定位一组元素
- 4.9 多表单切换
- 4.10 多窗口切换
- 4.11 警告框处理
- 4.12 下拉框处理
- 4.13 上传文件
- 4.14 下载文件
- 4.15 操作cookie
- 4.16 调用JavaScript
- 4.17 处理HTML5视频播放
- 4.18 滑动解锁
- 4.19 窗口截图
- 第5章 自动化测试模型
- 5.3 模块化与参数化
- 5.4 读取数据文件
- 第6章 unittest单元测试框架
- 6.1 认识unittest