
# 4.5 错误处理的未来
TODO: 讨论社区里的一些优秀的方案、以及未来可能的设计
## 4.5.1 来自社区的方案
在错误处理这件事情上,其实社区提供了许多非常优秀的方案, 其中一个非常出色的工作来自 Dave Cheney 和他的错误原语。
### 错误原语
`pkg/errors`与标准库中`errors`包不同,它首先提供了`Wrap`:
```
func Wrap(err error, message string) error {
if err == nil {
return nil
}
// 首先将错误产生的上下文进行保存
err = &withMessage{
cause: err,
msg: message,
}
// 再将 withMessage 错误的调用堆栈保存为 withStack 错误
return &withStack{
err,
callers(),
}
}
type withMessage struct {
cause error
msg string
}
func (w *withMessage) Error() string { return w.msg + ": " + w.cause.Error() }
func (w *withMessage) Cause() error { return w.cause }
type withStack struct {
error
*stack // 携带 stack 的信息
}
func (w *withStack) Cause() error { return w.error }
func callers() *stack {
const depth = 32
var pcs [depth]uintptr
n := runtime.Callers(3, pcs[:])
var st stack = pcs[0:n]
return &st
}
```
这是一种依赖运行时接口的解决方案,通过`runtime.Caller`来获取错误出现时的堆栈信息。通过`Wrap()`产生的错误类型`withMessage`还实现了`causer`接口:
```
type causer interface {
Cause() error
}
```
当我们需要对一个错误进行检查时,则可以通过`errors.Cause(err error)`来返回一个错误产生的原因,进而获得了错误产生的上下文信息:
```
func Cause(err error) error {
type causer interface {
Cause() error
}
for err != nil {
cause, ok := err.(causer)
if !ok { break }
err = cause.Cause()
}
return err
}
```
进而可以做到:
```
switch err := errors.Cause(err).(type) {
case *CustomError:
// ...
}
```
得益于`fmt.Formatter`接口,`pkg/errors`还实现了`Fomat(fmt.State, rune)`方法, 进而在使用`%+v`进行错误打印时,能携带堆栈信息:
```
func (w *withStack) Format(s fmt.State, verb rune) {
switch verb {
case 'v':
if s.Flag('+') { // %+v 支持携带堆栈信息的输出
fmt.Fprintf(s, "%+v", w.Cause())
w.stack.Format(s, verb) // 将 runtime.Caller 获得的信息进行打印
return
}
fallthrough
case 's':
io.WriteString(s, w.Error())
case 'q':
fmt.Fprintf(s, "%q", w.Error())
}
}
```
得到形如下面格式的错误输出:
```
current message: causer message
main.causer
/path/to/caller/main.go:5
main.caller
/path/to/caller/main.go:12
main.main
/path/to/caller/main.go:27
```
### 基于错误链的高层抽象
我们再来看另一种错误处理的哲学,现在我们来考虑下面这个例子:
```
conn, err := net.Dial("tcp", "localhost:1234")
if err != nil {
panic(err)
}
_, err := conn.Write(command1)
if err != nil {
panic(err)
}
r := bufio.NewReader(conn)
status, err := r.ReadString('\n')
if err != nil {
panic(err)
}
if status == "ok" {
_, err := conn.Write(command2)
if err != nil {
panic(err)
}
}
```
我们很明确的能够观察到错误处理带来的问题:为清晰的阅读代码的整体逻辑带来了障碍。我们希望上面的代码能够清晰的展现最重要的代码逻辑:
```
conn := net.Dial("tcp", "localhost:1234")
conn.Write(command1)
r := bufio.NewReader(conn)
status := r.ReadString('\n')
if status == "ok" {
conn.Write(command2)
}
```
如果我们进一步观察这个问题的现象,可以将整段代码抽象为图 1 所示的逻辑结构。
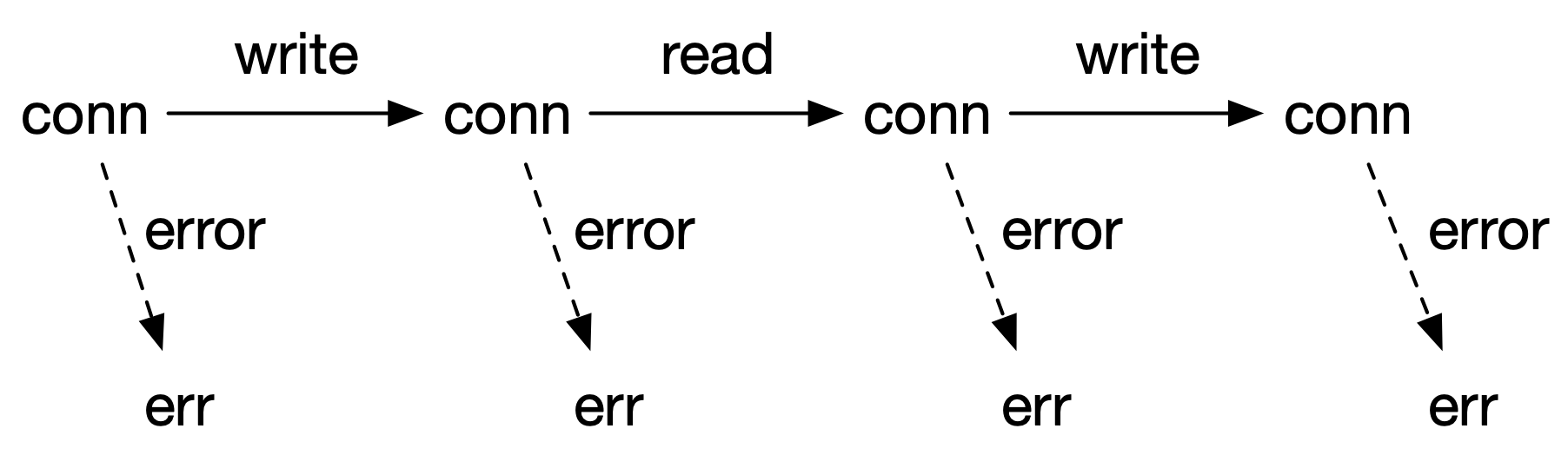**图 1: 产生分支的错误处理手段**
如果我们尝试将这段充满分支的逻辑进行高层抽象,将其转化为一个单一链条,则能够得到 图 2 所示的隐式错误链条。
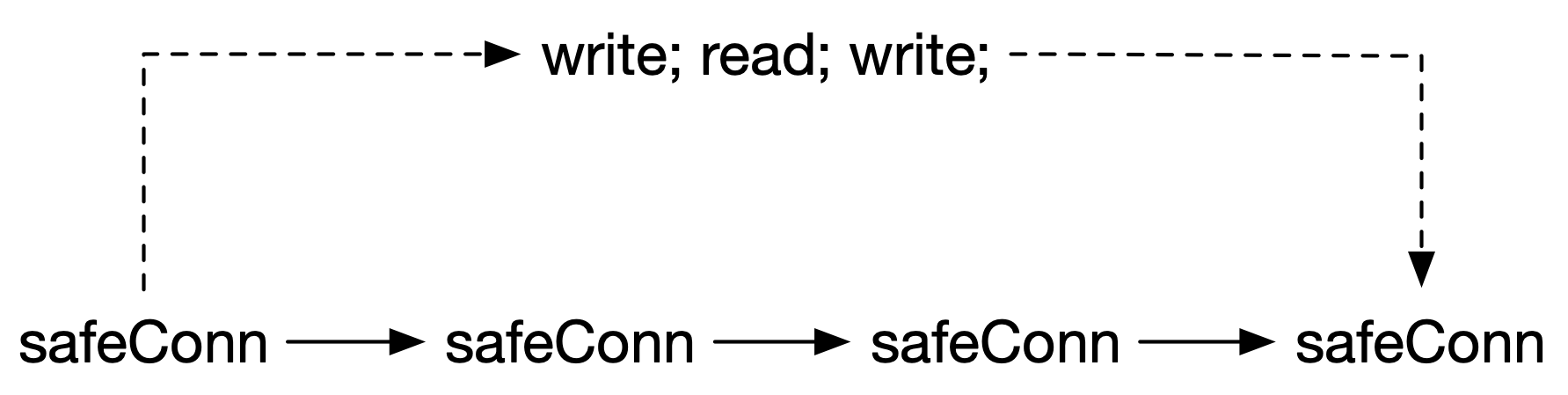**图 2: 消除分支的链式错误处理手段**
则能够得到下面的代码:
```
type SafeConn struct {
conn net.Conn
r *bufio.Reader
status string
err error
}
func safeDial(n, addr string) SafeConn {
conn, err := net.Dial(n, addr)
r := bufio.NewReader(conn)
return SafeConn{conn, r, "ok", err}
}
func (c *SafeConn) write(b []byte) {
if c.err != nil && status == "ok" { return }
_, c.err = c.conn.Write(b)
}
func (c *SafeConn) read() {
if err != nil { return }
c.status, c.err = c.r.ReadString('\n')
}
```
则当建立连接时候:
```
c := safeDial("tcp", "localhost:1234") // 如果此条指令出错
c.write(command1) // 不会发生任何事情
c.read() // 不会发生任何事情
c.write(command2) // 不会发生任何事情
// 最后对进行整个流程的错误处理
if c.err != nil || c.status != "ok" {
panic("bad connection")
}
```
这种将错误进行高层抽象的方法通常包含以下四个一般性的步骤:
1. 建立一种新的类型
2. 将原始值进行封装
3. 将原始行为进行封装
4. 将分支条件进行封装
## 4.5.2 其他可能的设计
TODO:
Generics + Error handling?
Either Coproduct
[https://www.ituring.com.cn/article/508191](https://www.ituring.com.cn/article/508191)[https://www.bookstack.cn/read/mostly-adequate-guide-chinese/ch8.4](https://www.bookstack.cn/read/mostly-adequate-guide-chinese/ch8.4)
## 4.5.3 历史性评述
- 第一部分 :基础篇
- 第1章 Go语言的前世今生
- 1.2 Go语言综述
- 1.3 顺序进程通讯
- 1.4 Plan9汇编语言
- 第2章 程序生命周期
- 2.1 从go命令谈起
- 2.2 Go程序编译流程
- 2.3 Go 程序启动引导
- 2.4 主Goroutine的生与死
- 第3 章 语言核心
- 3.1 数组.切片与字符串
- 3.2 散列表
- 3.3 函数调用
- 3.4 延迟语句
- 3.5 恐慌与恢复内建函数
- 3.6 通信原语
- 3.7 接口
- 3.8 运行时类型系统
- 3.9 类型别名
- 3.10 进一步阅读的参考文献
- 第4章 错误
- 4.1 问题的演化
- 4.2 错误值检查
- 4.3 错误格式与上下文
- 4.4 错误语义
- 4.5 错误处理的未来
- 4.6 进一步阅读的参考文献
- 第5章 同步模式
- 5.1 共享内存式同步模式
- 5.2 互斥锁
- 5.3 原子操作
- 5.4 条件变量
- 5.5 同步组
- 5.6 缓存池
- 5.7 并发安全散列表
- 5.8 上下文
- 5.9 内存一致模型
- 5.10 进一步阅读的文献参考
- 第二部分 运行时篇
- 第6章 并发调度
- 6.1 随机调度的基本概念
- 6.2 工作窃取式调度
- 6.3 MPG模型与并发调度单
- 6.4 调度循环
- 6.5 线程管理
- 6.6 信号处理机制
- 6.7 执行栈管理
- 6.8 协作与抢占
- 6.9 系统监控
- 6.10 网络轮询器
- 6.11 计时器
- 6.12 非均匀访存下的调度模型
- 6.13 进一步阅读的参考文献
- 第7章 内存分配
- 7.1 设计原则
- 7.2 组件
- 7.3 初始化
- 7.4 大对象分配
- 7.5 小对象分配
- 7.6 微对象分配
- 7.7 页分配器
- 7.8 内存统计
- 第8章 垃圾回收
- 8.1 垃圾回收的基本想法
- 8.2 写屏幕技术
- 8.3 调步模型与强弱触发边界
- 8.4 扫描标记与标记辅助
- 8.5 免清扫式位图技术
- 8.6 前进保障与终止检测
- 8.7 安全点分析
- 8.8 分代假设与代际回收
- 8.9 请求假设与实务制导回收
- 8.10 终结器
- 8.11 过去,现在与未来
- 8.12 垃圾回收统一理论
- 8.13 进一步阅读的参考文献
- 第三部分 工具链篇
- 第9章 代码分析
- 9.1 死锁检测
- 9.2 竞争检测
- 9.3 性能追踪
- 9.4 代码测试
- 9.5 基准测试
- 9.6 运行时统计量
- 9.7 语言服务协议
- 第10章 依赖管理
- 10.1 依赖管理的难点
- 10.2 语义化版本管理
- 10.3 最小版本选择算法
- 10.4 Vgo 与dep之争
- 第12章 泛型
- 12.1 泛型设计的演进
- 12.2 基于合约的泛型
- 12.3 类型检查技术
- 12.4 泛型的未来
- 12.5 进一步阅读的的参考文献
- 第13章 编译技术
- 13.1 词法与文法
- 13.2 中间表示
- 13.3 优化器
- 13.4 指针检查器
- 13.5 逃逸分析
- 13.6 自举
- 13.7 链接器
- 13.8 汇编器
- 13.9 调用规约
- 13.10 cgo与系统调用
- 结束语: Go去向何方?