
# 5.7 并发安全散列表
语言内建的散列表`map`结构并不是并发安全的,在并发的对该结构进行读写时,甚至可能产生不可恢复的运行时恐慌, 导致程序将不受控制的崩溃,这在对于可用性有一定要求的 Web 场景下,这几乎是一个致命的缺陷。
为了解决并发问题,`sync`包中提供了一种特殊的并发安全散列表`sync.Map`结构。该结构的使用 文档说明了该结构的实现针对了读多写少的这一特殊的场景进行优化, 并得到了优于普通的`map`加`sync.Mutex`结构的性能,例如:
```
// MutexMap 是一个简单的 map + sync.Mutex 的并发安全散列表实现
type MutexMap struct {
data map[interface{}]interface{}
mu sync.Mutex
}
func (m *MutexMap) Load(k interface{}) (v interface{}, ok bool) {
m.mu.Lock()
defer m.mu.Unlock()
v, ok = m.data[k]
return
}
func (m *MutexMap) Store(k, v interface{}) {
m.mu.Lock()
defer m.mu.Unlock()
m.data[k] = v
}
```
## 5.7.1 sync.Map 的性能
在讨论`sync.Map`的设计之前我们不妨先通过基准测试来对其主要使用场景进行一个初步的认识。 正如前面所说,`sync.Map`的主要使用场景是「读多写少」,但即便是对于「读多写少」的场景, 我们也需要对不同的情况进行讨论。作为抛砖引玉,这里我们只针对这一种场景进行基准测试, 读者也可以自行据此举一反三:
**对于一个给定的 sync.Map,并发场景下存在 1 个 goroutine 对某个 key 进行并发写,并同时存在 n-1 个 goroutine 对同一个 key产生并发读。**
根据这个描述,我们不难写出如下的基准测试:
```
func BenchmarkLoadStoreCollision(b *testing.B) {
ms := [...]mapInterface{
&MutexMap{data: map[interface{}]interface{}{}},
&RWMutexMap{data: map[interface{}]interface{}{}},
&sync.Map{},
}
// 测试对于同一个 key 的 n-1 并发读和 1 并发写的性能
for _, m := range ms {
b.Run(fmt.Sprintf("%T", m), func(b *testing.B) {
var i int64
b.RunParallel(func(pb *testing.PB) {
// 记录并发执行的 goroutine id
gid := int(atomic.AddInt64(&i, 1) - 1)
if gid == 0 {
// gid 为 0 的 goroutine 负责并发写
for i := 0; pb.Next(); i++ {
m.Store(0, i)
}
} else {
// gid 不为 0 的 goroutine 负责并发读
for pb.Next() {
m.Load(0)
}
}
})
})
}
}
```
其中`mapInterface`用于让基准测试可以针对具有相同操作不同实现的散列表进行循环处理; 而`RWMutexMap`仅仅只是将`mu`字段从`sync.Mutex`改为了`sync.RWMutex`:
```
type mapInterface interface {
Load(k interface{}) (v interface{}, ok bool)
Store(k, v interface{})
}
// RWMutexMap 是一个简单的 map + sync.RWMutex 的并发安全散列表实现
type RWMutexMap struct {
data map[interface{}]interface{}
mu sync.RWMutex
}
func (m *RWMutexMap) Load(k interface{}) (v interface{}, ok bool) { /* ...实现相同... */ }
func (m *RWMutexMap) Store(k, v interface{}) { /* ...实现相同... */ }
```
在 Go 的基准测试工具中,`b.RunParallel`将执行 GOMAXPROCS 个并发的 Goroutine, 为了测试随并发 Goroutine 数量增多情况下散列表的性能变化情况,可以通过`-cpu`参数 来动态调整 GOMAXPROCS 的数量,于是:
```
$ go test -v -run=none -bench=. -count=10 -cpu=2,4,8,16,32,64,128,256,512 | tee bench.txt
```
运行完毕后,再使用 benchstat 工具对测试结果从统计意义上消除系统误差:
```
$ benchstat bench.txt
name time/op
LoadStoreCollision/*map_test.MutexMap-2 42.7ns ± 1%
LoadStoreCollision/*map_test.MutexMap-4 60.0ns ± 2%
LoadStoreCollision/*map_test.MutexMap-8 76.5ns ± 5%
LoadStoreCollision/*map_test.MutexMap-16 90.7ns ± 3%
LoadStoreCollision/*map_test.MutexMap-32 94.2ns ± 6%
LoadStoreCollision/*map_test.MutexMap-64 109ns ± 1%
LoadStoreCollision/*map_test.MutexMap-128 134ns ±14%
LoadStoreCollision/*map_test.MutexMap-256 175ns ±16%
LoadStoreCollision/*map_test.MutexMap-512 223ns ± 6%
LoadStoreCollision/*map_test.RWMutexMap-2 123ns ± 8%
LoadStoreCollision/*map_test.RWMutexMap-4 140ns ± 8%
LoadStoreCollision/*map_test.RWMutexMap-8 141ns ± 4%
LoadStoreCollision/*map_test.RWMutexMap-16 133ns ± 6%
LoadStoreCollision/*map_test.RWMutexMap-32 126ns ± 7%
LoadStoreCollision/*map_test.RWMutexMap-64 131ns ±15%
LoadStoreCollision/*map_test.RWMutexMap-128 152ns ± 5%
LoadStoreCollision/*map_test.RWMutexMap-256 152ns ± 6%
LoadStoreCollision/*map_test.RWMutexMap-512 164ns ± 3%
LoadStoreCollision/*sync.Map-2 33.7ns ± 3%
LoadStoreCollision/*sync.Map-4 14.9ns ± 4%
LoadStoreCollision/*sync.Map-8 9.67ns ± 7%
LoadStoreCollision/*sync.Map-16 7.24ns ± 6%
LoadStoreCollision/*sync.Map-32 6.44ns ± 4%
LoadStoreCollision/*sync.Map-64 6.45ns ± 2%
LoadStoreCollision/*sync.Map-128 6.67ns ± 8%
LoadStoreCollision/*sync.Map-256 6.69ns ± 3%
LoadStoreCollision/*sync.Map-512 6.19ns ± 1%
```
我们将这个结果进行可视化,如图 1 所示,展现了`sync.Map`与其他两种实现下,随并发数量 n 变化 而产生的性能对比:
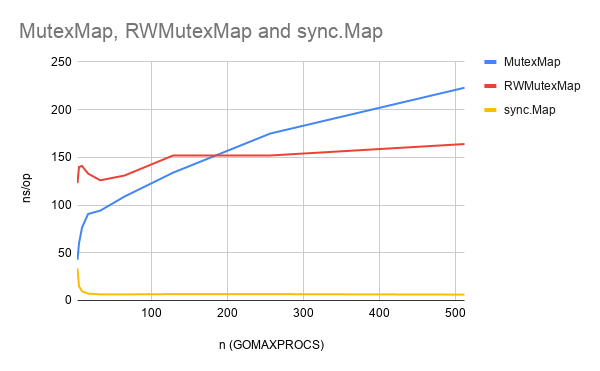**图1:`MutexMap`、`RWMutexMap`与`sync.Map`之间写少读多场景下的性能对比**
从图 1 中我们可以非常直观的看出,随着并发数量的增加,`sync.Map`在多读场景下始终保持非常优秀的性能,而`Mutex`/`RWMutex`则随着并发数量的增加导致性能稳步的下降,耗时越来越多。 因此,`sync.Map`针对读多写少的场景下确实存在非常强的优化。那么这究竟是如何做到的呢?接下来我们就来就据此逐步展开讨论`sync.Map`的优化设计。
## 5.7.2 结构
既然是并发安全,因此 sync.Map 一定会包含 Mutex。那么宣称的多次读场景下的优化一定是使用了某种特殊的 机制来保证安全的情况下可以不再使用 Mutex。
```
// Map 是一种并发安全的 map[interface{}]interface{},在多个 goroutine 中没有额外的锁条件
// 读取、存储和删除操作的时间复杂度平均为常量
//
// Map 类型非常特殊,大部分代码应该使用原始的 Go map。它具有单独的锁或协调以获得类型安全且更易维护。
//
// Map 类型针对两种常见的用例进行优化:
// 1. 给定 key 只会产生写一次但是却会多次读,类似乎只增的缓存
// 2. 多个 goroutine 读、写以及覆盖不同的 key
// 这两种情况下,与单独使用 Mutex 或 RWMutex 的 map 相比,会显著降低竞争情况
//
// 零值 Map 为空且可以直接使用,Map 使用后不能复制
type Map struct {
mu Mutex
// read 包含 map 内容的一部分,这些内容对于并发访问是安全的(有或不使用 mu)。
//
// read 字段 load 总是安全的,但是必须使用 mu 进行 store。
//
// 存储在 read 中的 entry 可以在没有 mu 的情况下并发更新,
// 但是更新已经删除的 entry 需要将 entry 复制到 dirty map 中,并使用 mu 进行删除。
read atomic.Value // 只读
// dirty 含了需要 mu 的 map 内容的一部分。为了确保将 dirty map 快速地转为 read map,
// 它还包括了 read map 中所有未删除的 entry。
//
// 删除的 entry 不会存储在 dirty map 中。在 clean map 中,被删除的 entry 必须被删除并添加到 dirty 中,
// 然后才能将新的值存储为它
//
// 如果 dirty map 为 nil,则下一次的写行为会通过 clean map 的浅拷贝进行初始化
dirty map[interface{}]*entry
// misses 计算了从 read map 上一次更新开始的 load 数,需要 lock 以确定 key 是否存在。
//
// 一旦发生足够的 misses 足以囊括复制 dirty map 的成本,dirty map 将被提升为 read map(处于未修改状态)
// 并且 map 的下一次 store 将生成新的 dirty 副本。
misses int
}
```
在这个结构中,可以看到`read`和`dirty`分别对应两个`map`,但`read`的结构比较特殊,是一个`atomic.Value`类型。
从`misses`的描述中可以大致看出 sync.Map 的思路是发生足够多的读时,就将 dirty map 复制一份到 read map 上。 从而实现在 read map 上的读操作不再需要昂贵的 Mutex 操作。
## 5.7.3 写操作 Store
我们先来看看`Store()`。
```
// Store 存储 key 对应的 value
func (m *Map) Store(key, value interface{}) {
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 修改一个已经存在的值
// 读取 read map 中的值
// 如果读到了,则尝试更新 read map 的值,如果更新成功,则直接返回,否则还要继续处理(当且仅当要更新的值被标记为删除)
// 如果没读到,则还要继续处理(read map 中不存在)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
(...)
}
```
可以看到,首先发生的是更新已经存在值的情况: 更新操作直接更新 read map 中的值,如果成功则不需要进行任何操作,如果没有成功才继续处理。
我们来看一下`tryStore`。
```
// tryStore 在 entry 还没有被删除的情况下存储其值
//
// 如果 entry 被删除了,则 tryStore 返回 false 且不修改 entry
func (e *entry) tryStore(i *interface{}) bool {
for {
// 读取 entry
p := atomic.LoadPointer(&e.p)
// 如果 entry 已经删除,则无法存储,返回
if p == expunged {
return false
}
// 交换 p 和 i 的值,如果成功则立即返回
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}
```
从`tryStore`可以看出,在更新操作中只要没有发生 key 的删除情况,即值已经在 dirty map 中标记为删除, 更新操作一定只更新到 read map 中,不涉及与 dirty map 之间的数据同步。
我们继续看`Store()`剩下的部分。下面的情况就相对复杂一些了,在锁住结构后, 要做的第一件事情就是更新刚才读过的 read map。刚才我们仅仅只是修改一个已经存在的值, 现在我们面临三种情况:
**情况1**
```
// Store 存储 key 对应的 value
func (m *Map) Store(key, value interface{}) {
(...)
m.mu.Lock()
// 经过刚才的一系列操作,read map 可能已经更新了
// 因此需要再读一次
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
// 修改一个已经存在的值
if e.unexpungeLocked() {
// 说明 entry 先前是被标记为删除了的,现在我们又要存储它,只能向 dirty map 进行更新了
m.dirty[key] = e
}
// 无论先前删除与否,都要更新 read map
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
(...)
} else {
(...)
}
m.mu.Unlock()
}
```
这种情况下,本质上还分两种情况:
1. 可能因为是一个已经删除的值(之前的`tryStore`失败)
2. 可能先前仅保存在 dirty map 然后同步到了 read map(这是可能的,我们后面读 Load 时再来分析 dirty map 是如何同步到 read map 的)
对于第一种而言,我们需要重新将这个已经删除的值标记为没有删除,然后将这个值同步回 dirty map(删除操作只删除 dirty map,之后再说) 对于第二种状态,我们直接更新 read map,不需要打扰 dirty map。
**情况2**
```
// Store 存储 key 对应的 value
func (m *Map) Store(key, value interface{}) {
(...)
if e, ok := read.m[key]; ok {
(...)
} else if e, ok := m.dirty[key]; ok {
e.storeLocked(&value) // 更新 dirty map 的值即可
} else {
(...)
}
m.mu.Unlock()
}
```
我们发现 read map 中没有想要更新的值,那么看一下 dirty map 有没有,结果发现是有的, 那么我们直接修改 dirty map,不去打扰 read map。
**情况3**
```
// Store 存储 key 对应的 value
func (m *Map) Store(key, value interface{}) {
(...)
if e, ok := read.m[key]; ok {
(...)
} else if e, ok := m.dirty[key]; ok {
(...)
} else {
// 如果 dirty map 里没有 read map 没有的值(两者相同)
if !read.amended {
// 首次添加一个新的值到 dirty map 中
// 确保已被分配并标记为 read map 是不完备的(dirty map 有 read map 没有的)
m.dirtyLocked()
// 更新 amended,标记 read map 中缺少了值(标记为两者不同)
m.read.Store(readOnly{m: read.m, amended: true})
}
// 不管 read map 和 dirty map 相同与否,正式保存新的值
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
// 只是简单的创建一个 entry
// entry 是一个对应于 map 中特殊 key 的 slot
type entry struct {
// p 指向 interface{} 类型的值,用于保存 entry
//
// 如果 p == nil,则 entry 已被删除,且 m.dirty == nil
//
// 如果 p == expunged, 则 entry 已经被删除,m.dirty != nil ,则 entry 不在 m.dirty 中
//
// 否则,entry 仍然有效,且被记录在 m.read.m[key] ,但如果 m.dirty != nil,则在 m.dirty[key] 中
//
// 一个 entry 可以被原子替换为 nil 来删除:当 m.dirty 下一次创建时,它会自动将 nil 替换为 expunged 且
// 让 m.dirty[key] 成为未设置的状态。
//
// 与一个 entry 关联的值可以被原子替换式的更新,提供的 p != expunged。如果 p == expunged,
// 则与 entry 关联的值只能在 m.dirty[key] = e 设置后被更新,因此会使用 dirty map 来查找 entry。
p unsafe.Pointer // *interface{}
}
func newEntry(i interface{}) *entry {
return &entry{p: unsafe.Pointer(&i)}
}
```
read map 和 dirty map 都没有,只能是存储一个新值了。当然,在更新之前 我们还要再检查一下 read map 和 dirty map 的状态。 如果 read map 和 dirty map 中存储的内容是相同的,那么我们这次存储新的数据 只会存储在 dirty map 中,因此会造成 read map 和 dirty map 的不一致。
read map 和 dirty map 相同的情况,首先调用`dirtyLocked()`。
```
func (m *Map) dirtyLocked() {
// 如果 dirty map 为空,则一切都很好,返回
if m.dirty != nil {
return
}
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 创建一个与 read map 大小一样的 dirty map
m.dirty = make(map[interface{}]*entry, len(read.m))
// 依次将 read map 的值复制到 dirty map 中。
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
// 获取 entry 的值
p := atomic.LoadPointer(&e.p)
// 如果 entry 值是 nil
for p == nil {
// 检查是否被标记为已经删除
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
// 成功交换,说明被标记为删除
return true
}
// 删除操作失败,说明 expunged 是 nil,则重新读取一下
p = atomic.LoadPointer(&e.p)
}
// 直到读到的 p不为 nil 时,则判断是否是标记为删除的对象
return p == expunged
}
```
这个步骤中将 read map 中没有被标记为删除的值全部同步到了 dirty map 中。 然后将 dirty map 标记为与 read map 不同,因为接下来我们马上要把向 dirty map 存值了。
好了,至此我们完成了整个存储过程。小结一下:
1. 存储过程遵循互不影响的原则,如果在 read map 中读到,则只更新 read map,如果在 dirty map 中读到,则只更新 dirty map。
2. 优先从 read map 中读,更新失败才读 dirty map。
3. 存储新值的时候,如果 dirty map 中没有 read map 中的值,那么直接将整个 read map 同步到 dirty map。这时原来的 dirty map 被彻底覆盖(一些值依赖 GC 进行清理)。
## 5.7.4 读操作 Load
Load 的操作就是从 dirty map 或者 read map 中查找所存储的值。
```
// Load 返回了存储在 map 中对应于 key 的值 value,如果不存在则返回 nil
// ok 表示了值能否在 map 中找到
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 拿到只读 read map
read, _ := m.read.Load().(readOnly)
// 从只读 map 中读 key 对应的 value
e, ok := read.m[key]
// 如果在 read map 中找不到,且 dirty map 包含 read map 中不存在的 key,则进一步查找
if !ok && read.amended {
m.mu.Lock()
// 锁住后,再读一次 read map
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 如果这时 read map 确实读不到,且 dirty map 与 read map 不一致
if !ok && read.amended {
// 则从 dirty map 中读
e, ok = m.dirty[key]
// 无论 entry 是否找到,记录一次 miss:该 key 会采取 slow path 进行读取,直到
// dirty map 被提升为 read map。
m.missLocked()
}
m.mu.Unlock()
}
// 如果 read map 或者 dirty map 中找不到 key,则确实没找到,返回 nil 和 false
if !ok {
return nil, false
}
// 如果找到了,则返回读到的值
return e.load()
}
func (e *entry) load() (value interface{}, ok bool) {
// 读 entry 的值
p := atomic.LoadPointer(&e.p)
// 如果值为 nil 或者已经删除
if p == nil || p == expunged {
// 则读不到
return nil, false
}
// 否则读值
return *(*interface{})(p), true
}
```
可以看到:
1. 如果 read map 中已经找到了该值,则不需要去访问 dirty map(慢)。
2. 但如果没找到,且 dirty map 与 read map 没有差异,则也不需要去访问 dirty map。
3. 如果 dirty map 和 read map 有差异,则我们需要锁住整个 Map,然后再读取一次 read map 来防止并发导致的上一次读取失误
4. 如果锁住后,确实 read map 读取不到且 dirty map 和 read map 一致,则不需要去读 dirty map 了,直接解锁返回。
5. 如果锁住后,read map 读不到,且 dirty map 与 read map 不一致,则该 key 可能在 dirty map 中,我们需要从 dirty map 中读取,并记录一次 miss(在 read map 中 miss)。
当记录 miss 时,涉及`missLocked`操作:
```
// 此方法调用时,整个 map 是锁住的
func (m *Map) missLocked() {
// 增加一次 miss
m.misses++
// 如果 miss 的次数小于 dirty map 的 key 数
// 则直接返回
if m.misses < len(m.dirty) {
return
}
// 否则将 dirty map 同步到 read map 去
m.read.Store(readOnly{m: m.dirty})
// 清空 dirty map
m.dirty = nil
// miss 计数归零
m.misses = 0
}
```
可以看出,miss 如果大于了 dirty 所存储的 key 数时,会将 dirty map 同步到 read map,并将自身清空,miss 计数归零。
## 5.7.5 删除操作 Delete
再来看删除操作。
`
// Delete 删除 key 对应的 value
func (m *Map) Delete(key interface{}) {
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 从 read map 中读取需要删除的 key
e, ok := read.m[key]
// 如果 read map 中没找到,且 read map 与 dirty map 不一致
// 说明要删除的值在 dirty map 中
if !ok && read.amended {
// 在 dirty map 中需要加锁
m.mu.Lock()
// 再次读 read map
read, _ = m.read.Load().(readOnly)
// 从 read map 中取值
e, ok = read.m[key]
// 没取到,read map 和 dirty map 不一致
if !ok && read.amended {
// 删除 dierty map 的值
delete(m.dirty, key)
}
m.mu.Unlock()
}``
// 如果 read map 中找到了
if ok {
// 则执行删除
e.delete()
}
}
func (e *entry) delete() (hadValue bool) {
for {
// 读取 entry 的值
p := atomic.LoadPointer(&e.p)
// 如果 p 等于 nil,或者 p 已经标记删除
if p == nil || p == expunged {
// 则不需要删除
return false
}
// 否则,将 p 的值与 nil 进行原子换
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
// 删除成功(本质只是解除引用,实际上是留给 GC 清理)
return true
}
}
}
```
从实现上来看,删除操作相对简单,当需要删除一个值时,移除 read map 中的值,本质上仅仅只是解除对变量的引用。 实际的回收是由 GC 进行处理。 如果 read map 中并未找到要删除的值,才会去尝试删除 dirty map 中的值。
## 5.7.6 迭代操作 Range
有了上面的存取基础,这时候来看 Range 一切都显得很自然:
```
// Range 为每个 key 顺序的调用 f。如果 f 返回 false,则 range 会停止迭代。
//
// Range 的时间复杂度可能会是 O(N) 即便是 f 返回 false。
func (m *Map) Range(f func(key, value interface{}) bool) {
// 读取 read map
read, _ := m.read.Load().(readOnly)
// 如果 read map 和 dirty map 不一致,则需要进一步操作
if read.amended {
m.mu.Lock()
// 再读一次,如果还是不一致,则将 dirty map 提升为 read map
read, _ = m.read.Load().(readOnly)
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 在 read 变量中读(可能是 read map ,也可能是 dirty map 同步过来的 map)
for k, e := range read.m {
// 读 readOnly,load 会检查该值是否被标记为删除
v, ok := e.load()
// 如果已经删除,则跳过
if !ok {
continue
}
// 如果 f 返回 false,则停止迭代
if !f(k, v) {
break
}
}
}
```
既然要 Range 整个 map,则需要考虑 dirty map 与 read map 不一致的问题,如果不一致,则直接将 dirty map 同步到 read map 中。
## 5.7.7 读写操作 LoadOrStore
```
// LoadOrStore 在 key 已经存在时,返回存在的值,否则存储当前给定的值
// loaded 为 true 表示 actual 读取成功,否则为 false 表示 value 存储成功
func (m *Map) LoadOrStore(key, value interface{}) (actual interface{}, loaded bool) {
// 读 read map
read, _ := m.read.Load().(readOnly)
// 如果 read map 中已经读到
if e, ok := read.m[key]; ok {
// 尝试存储(可能 key 是一个已删除的 key)
actual, loaded, ok := e.tryLoadOrStore(value)
// 如果存储成功,则直接返回
if ok {
return actual, loaded
}
}
// 否则,涉及 dirty map,加锁
m.mu.Lock()
// 再读一次 read map
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
// 如果 read map 中已经读到,则看该值是否被删除
if e.unexpungeLocked() {
// 没有被删除,则通过 dirty map 存
m.dirty[key] = e
}
actual, loaded, _ = e.tryLoadOrStore(value)
} else if e, ok := m.dirty[key]; ok { // 如果 read map 没找到, dirty map 找到了
// 尝试 laod or store,并记录 miss
actual, loaded, _ = e.tryLoadOrStore(value)
m.missLocked()
} else { // 否则就是存一个新的值
// 如果 read map 和 dirty map 相同,则开始标记不同
if !read.amended {
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
// 存到 dirty map 中去
m.dirty[key] = newEntry(value)
actual, loaded = value, false
}
m.mu.Unlock()
// 返回存取状态
return actual, loaded
}
```
我们已经看过 Load 或 Store 的单独过程了,`LoadOrStore`方法无非是两则的结合,比较简单,这里就不再细说了。
## 5.7.8 小结
我们来回顾一下 sync.Map 中 read map 和 dirty map 的同步过程:
1. 当 Store 一个新值会发生:read map –> dirty map
2. dirty map –> read map:当 read map 进行 Load 失败 len(dirty map) 次之后发生
因此,无论是存储还是读取,read map 中的值一定能在 dirty map 中找到。无论两者如何同步,sync.Map 通过 entry 指针操作, 保证数据永远只有一份,一旦 read map 中的值修改,dirty map 中保存的指针就能直接读到修改后的值。
当存储新值时,一定发生在 dirty map 中。当读取旧值时,如果 read map 读到则直接返回,如果没有读到,则尝试加锁去 dirty map 中取。 这也就是官方宣称的 sync.Map 适用于一次写入多次读取的情景。
- 第一部分 :基础篇
- 第1章 Go语言的前世今生
- 1.2 Go语言综述
- 1.3 顺序进程通讯
- 1.4 Plan9汇编语言
- 第2章 程序生命周期
- 2.1 从go命令谈起
- 2.2 Go程序编译流程
- 2.3 Go 程序启动引导
- 2.4 主Goroutine的生与死
- 第3 章 语言核心
- 3.1 数组.切片与字符串
- 3.2 散列表
- 3.3 函数调用
- 3.4 延迟语句
- 3.5 恐慌与恢复内建函数
- 3.6 通信原语
- 3.7 接口
- 3.8 运行时类型系统
- 3.9 类型别名
- 3.10 进一步阅读的参考文献
- 第4章 错误
- 4.1 问题的演化
- 4.2 错误值检查
- 4.3 错误格式与上下文
- 4.4 错误语义
- 4.5 错误处理的未来
- 4.6 进一步阅读的参考文献
- 第5章 同步模式
- 5.1 共享内存式同步模式
- 5.2 互斥锁
- 5.3 原子操作
- 5.4 条件变量
- 5.5 同步组
- 5.6 缓存池
- 5.7 并发安全散列表
- 5.8 上下文
- 5.9 内存一致模型
- 5.10 进一步阅读的文献参考
- 第二部分 运行时篇
- 第6章 并发调度
- 6.1 随机调度的基本概念
- 6.2 工作窃取式调度
- 6.3 MPG模型与并发调度单
- 6.4 调度循环
- 6.5 线程管理
- 6.6 信号处理机制
- 6.7 执行栈管理
- 6.8 协作与抢占
- 6.9 系统监控
- 6.10 网络轮询器
- 6.11 计时器
- 6.12 非均匀访存下的调度模型
- 6.13 进一步阅读的参考文献
- 第7章 内存分配
- 7.1 设计原则
- 7.2 组件
- 7.3 初始化
- 7.4 大对象分配
- 7.5 小对象分配
- 7.6 微对象分配
- 7.7 页分配器
- 7.8 内存统计
- 第8章 垃圾回收
- 8.1 垃圾回收的基本想法
- 8.2 写屏幕技术
- 8.3 调步模型与强弱触发边界
- 8.4 扫描标记与标记辅助
- 8.5 免清扫式位图技术
- 8.6 前进保障与终止检测
- 8.7 安全点分析
- 8.8 分代假设与代际回收
- 8.9 请求假设与实务制导回收
- 8.10 终结器
- 8.11 过去,现在与未来
- 8.12 垃圾回收统一理论
- 8.13 进一步阅读的参考文献
- 第三部分 工具链篇
- 第9章 代码分析
- 9.1 死锁检测
- 9.2 竞争检测
- 9.3 性能追踪
- 9.4 代码测试
- 9.5 基准测试
- 9.6 运行时统计量
- 9.7 语言服务协议
- 第10章 依赖管理
- 10.1 依赖管理的难点
- 10.2 语义化版本管理
- 10.3 最小版本选择算法
- 10.4 Vgo 与dep之争
- 第12章 泛型
- 12.1 泛型设计的演进
- 12.2 基于合约的泛型
- 12.3 类型检查技术
- 12.4 泛型的未来
- 12.5 进一步阅读的的参考文献
- 第13章 编译技术
- 13.1 词法与文法
- 13.2 中间表示
- 13.3 优化器
- 13.4 指针检查器
- 13.5 逃逸分析
- 13.6 自举
- 13.7 链接器
- 13.8 汇编器
- 13.9 调用规约
- 13.10 cgo与系统调用
- 结束语: Go去向何方?