
# 6.3 MPG 模型与并发调度单元
我们首先了解一下调度器的设计原则及一些基本概念来建立对调度器较为宏观的认识。 理解调度器涉及的主要概念包括以下三个:
* G:**G**oroutine,即我们在 Go 程序中使用`go`关键字创建的执行体;
* M:**M**achine,或 worker thread,即传统意义上进程的线程;
* P:**P**rocessor,即一种人为抽象的、用于执行 Go 代码被要求局部资源。只有当 M 与一个 P 关联后才能执行 Go 代码。除非 M 发生阻塞或在进行系统调用时间过长时,没有与之关联的 P。
P 的存在不太好理解,我们暂时先记住这个概念,之后再来回顾这个概念。
## 6.3.1 工作线程的暂止和复始
运行时调度器的任务是给不同的工作线程 (worker thread) 分发可供运行的(ready-to-run)Goroutine。 我们不妨设每个工作线程总是贪心的执行所有存在的 Goroutine,那么当运行进程中存在 n 个线程(M),且 每个 M 在某个时刻有且只能调度一个 G。根据抽屉原理,可以很容易的证明这两条性质:
* 性质 1:当用户态代码创建了p(p\>n)p(p\>n)个 G 时,则必定存在p−np−n个 G 尚未被 M 调度执行;
* 性质 2:当用户态代码创建的 q (q < n) 时,则必定存在 n-q 个 M 不存在正在调度的 G。
这两条性质分别决定了工作线程的**暂止(park)**和**复始(unpark)**。
我们不难发现,调度器的设计需要在性质 1 和性质 2 之间进行权衡: 即既要保持足够的运行工作线程来利用有效硬件并发资源,又要暂止过多的工作线程来节约 CPU 能耗。 如果我们把调度器想象成一个系统,则寻找这个权衡的最优解意味着我们必须求解调度器系统中 每个 M 的状态,即系统的全局状态。这是非常困难的,不妨考虑以下两个难点:
**难点 1: 在多个 M 之间不使用屏障的情况下,得出调度器中多个 M 的全局状态是不可能的。**
我们都知道计算的局部性原理,为了利用这一原理,调度器所需调度的 G 都会被放在每个 M 自身对应的本地队列中。 换句话说,每个 M 都无法直接观察到其他的 M 所具有的 G 的状态,存在多个 M 之间的共识问题。这本质上就是一个分布式系统。 显然,每个 M 都能够连续的获取自身的状态,但当它需要获取整个系统的全局状态时却不容易, 原因在于我们没有一个能够让所有线程都同步的时钟。换句话说, 我们需要依赖屏障来保证多个 M 之间的全局状态同步。更进一步,在不使用屏障的情况下, 能否利用每个 M 在不同时间中记录的本地状态中计算出调度器的全局状态,或者形式化的说: 能否在快速路径(fast path)下计算进程集的全局谓词(global predicates)呢?根据我们在共识技术中的知识,是不可能的。
**难点 2: 为了获得最佳的线程管理,我们必须获得未来的信息,即当一个新的 G 即将就绪(ready)时,则不再暂止一个工作线程。**
举例来说,目前我们的调度器存在 4 个 M,并其中有 3 个 M 正在调度 G,则其中有 1 个 M 处于空闲状态。 这时为了节约 CPU 能耗,我们希望对这个空闲的 M 进行暂止操作。但是,正当我们完成了对此 M 的暂止操作后, 用户态代码正好执行到了需要调度一个新的 G 时,我们又不得不将刚刚暂止的 M 重新启动,这无疑增加了开销。 我们当然有理由希望,如果我们能知晓一个程序生命周期中所有的调度信息, 提前知晓什么时候适合对 M 进行暂止自然再好不过了。 尽管我们能够对程序代码进行静态分析,但这显然是不可能的:考虑一个简单的 Web 服务端程序,每个用户请求 到达后会创建一个新的 G 交于调度器进行调度。但请求到达是一个随机过程,我们只能预测在给定置信区间下 可能到达的请求数,而不能完整知晓所有的调度需求。
那么我们又应该如何设计一个通用且可扩展的调度器呢?我们很容易想到三种平凡的做法:
**设计 1: 集中式管理所有状态**
显然这种做法自然是不可取的,在多个并发实体之间集中管理所有状态这一共享资源,需要锁的支持, 当并发实体的数量增大时,将限制调度器的可扩展性。
**设计 2**: 每当需要就绪一个 G1 时,都让出一个 P,直接切换出 G2,再复始一个 M 来执行 G2。
因为复始的 M 可能在下一个瞬间又没有调度任务,则会发生线程颠簸(thrashing),进而我们又需要暂止这个线程。 另一方面,我们希望在相同的线程内保存维护 G,这种方式还会破坏计算的局部性原理。
**设计 3**: 任何时候当就绪一个 G、也存在一个空闲的 P 时,都复始一个额外的线程,不进行切换。
因为这个额外线程会在没有检查任何工作的情况下立即进行暂止,最终导致大量 M 的暂止和复始行为,产生大量开销。
基于以上考虑,目前的 Go 的调度器实现中设计了工作线程的**自旋(spinning)状态**:
1. 如果一个工作线程的本地队列、全局运行队列或网络轮询器中均没有可调度的任务,则该线程成为自旋线程;
2. 满足该条件、被复始的线程也被称为自旋线程,对于这种线程,运行时不做任何事情。
自旋线程在进行暂止之前,会尝试从任务队列中寻找任务。当发现任务时,则会切换成非自旋状态, 开始执行 Goroutine。而找到不到任务时,则进行暂止。
当一个 Goroutine 准备就绪时,会首先检查自旋线程的数量,而不是去复始一个新的线程。
如果最后一个自旋线程发现工作并且停止自旋时,则复始一个新的自旋线程。 这个方法消除了不合理的线程复始峰值,且同时保证最终的最大 CPU 并行度利用率。
我们可以通过下图来直观理解工作线程的状态转换:
~~~
如果存在空闲的 P,且存在暂止的 M,并就绪 G
+------+
v |
执行 --> 自旋 --> 暂止
^ |
+--------+
如果发现工作
~~~
总的来说,调度器的方式可以概括为:**如果存在一个空闲的 P 并且没有自旋状态的工作线程 M,则当就绪一个 G 时,就复始一个额外的线程 M。**这个方法消除了不合理的线程复始峰值,且同时保证最终的最大 CPU 并行度利用率。
这种设计的实现复杂性表现在进行自旋与非自旋线程状态转换时必须非常小心。 这种转换在提交一个新的 G 时发生竞争,最终导致任何一个工作线程都需要暂止对方。 如果双方均发生失败,则会以半静态 CPU 利用不足而结束调度。
因此,就绪一个 G 的通用流程为:
* 提交一个 G 到 per-P 的本地工作队列
* 执行 StoreLoad 风格的写屏障
* 检查`sched.nmspinning`数量
而从自旋到非自旋转换的一般流程为:
* 减少`nmspinning`的数量
* 执行 StoreLoad 风格的写屏障
* 在所有 per-P 本地任务队列检查新的工作
当然,此种复杂性在全局任务队列对全局队列并不适用的,因为当给一个全局队列提交工作时, 不进行线程的复始操作。
## 6.3.2 主要结构
我们这个部分简单来浏览一遍 M/P/G 的结构,初次阅读此结构会感觉虚无缥缈,不知道在看什么。 事实上,我们更应该直接深入调度器相关的代码来逐个理解每个字段的实际用途。 因此这里仅在每个结构后简单讨论其宏观作用,用作后文参考。 读者可以简单浏览各个字段,为其留下一个初步的印象即可。
### M 的结构
M 是 OS 线程的实体。我们介绍几个比较重要的字段,包括:
* 持有用于执行调度器的 g0
* 持有用于信号处理的 gsignal
* 持有线程本地存储 tls
* 持有当前正在运行的 curg
* 持有运行 Goroutine 时需要的本地资源 p
* 表示自身的自旋和非自旋状态 spining
* 管理在它身上执行的 cgo 调用
* 将自己与其他的 M 进行串联
* 持有当前线程上进行内存分配的本地缓存 mcache
等等其他五十多个字段,包括关于 M 的一些调度统计、调试信息等。
```
// src/runtime/runtime2.go
type m struct {
g0 *g // 用于执行调度指令的 Goroutine
gsignal *g // 处理 signal 的 g
tls [6]uintptr // 线程本地存储
curg *g // 当前运行的用户 Goroutine
p puintptr // 执行 go 代码时持有的 p (如果没有执行则为 nil)
spinning bool // m 当前没有运行 work 且正处于寻找 work 的活跃状态
cgoCallers *cgoCallers // cgo 调用崩溃的 cgo 回溯
alllink *m // 在 allm 上
mcache *mcache
...
}
```
### P 的结构
P 只是处理器的抽象,而非处理器本身,它存在的意义在于实现工作窃取(work stealing)算法。 简单来说,每个 P 持有一个 G 的本地队列。
在没有 P 的情况下,所有的 G 只能放在一个全局的队列中。 当 M 执行完 G 而没有 G 可执行时,必须将队列锁住从而取值。
当引入了 P 之后,P 持有 G 的本地队列,而持有 P 的 M 执行完 G 后在 P 本地队列中没有 发现其他 G 可以执行时,虽然仍然会先检查全局队列、网络,但这时增加了一个从其他 P 的 队列偷取(steal)一个 G 来执行的过程。优先级为本地 > 全局 > 网络 > 偷取。
一个不恰当的比喻:银行服务台排队中身手敏捷的顾客,当一个服务台队列空(没有人)时, 没有在排队的顾客(全局)会立刻跑到该窗口,当彻底没人时在其他队列排队的顾客才会迅速 跑到这个没人的服务台来,即所谓的偷取。
```
type p struct {
id int32
status uint32 // p 的状态 pidle/prunning/...
link puintptr
m muintptr // 反向链接到关联的 m (nil 则表示 idle)
mcache *mcache
pcache pageCache
deferpool [5][]*_defer // 不同大小的可用的 defer 结构池
deferpoolbuf [5][32]*_defer
runqhead uint32 // 可运行的 Goroutine 队列,可无锁访问
runqtail uint32
runq [256]guintptr
runnext guintptr
timersLock mutex
timers []*timer
preempt bool
...
}
```
所以整个结构除去 P 的本地 G 队列外,就是一些统计、调试、GC 辅助的字段了。
### G 的结构
G 既然是 Goroutine,必然需要定义自身的执行栈:
```
type g struct {
stack struct {
lo uintptr
hi uintptr
} // 栈内存:[stack.lo, stack.hi)
stackguard0 uintptr
stackguard1 uintptr
_panic *_panic
_defer *_defer
m *m // 当前的 m
sched gobuf
stktopsp uintptr // 期望 sp 位于栈顶,用于回溯检查
param unsafe.Pointer // wakeup 唤醒时候传递的参数
atomicstatus uint32
goid int64
preempt bool // 抢占信号,stackguard0 = stackpreempt 的副本
timer *timer // 为 time.Sleep 缓存的计时器
...
}
```
除了执行栈之外,还有很多与调试和 profiling 相关的字段。 一个 G 没有什么黑魔法,无非是将需要执行的函数参数进行了拷贝,保存了要执行的函数体的入口地址,用于执行。
### 调度器`sched`结构
调度器,所有 Goroutine 被调度的核心,存放了调度器持有的全局资源,访问这些资源需要持有锁:
* 管理了能够将 G 和 M 进行绑定的 M 队列
* 管理了空闲的 P 链表(队列)
* 管理了 G 的全局队列
* 管理了可被复用的 G 的全局缓存
* 管理了 defer 池
```
type schedt struct {
lock mutex
pidle puintptr // 空闲 p 链表
npidle uint32 // 空闲 p 数量
nmspinning uint32 // 自旋状态的 M 的数量
runq gQueue // 全局 runnable G 队列
runqsize int32
gFree struct { // 有效 dead G 的全局缓存.
lock mutex
stack gList // 包含栈的 Gs
noStack gList // 没有栈的 Gs
n int32
}
sudoglock mutex // sudog 结构的集中缓存
sudogcache *sudog
deferlock mutex // 不同大小的有效的 defer 结构的池
deferpool [5]*_defer
...
}
```
我们已经在[5.2 Go 程序启动引导](https://golang.design/under-the-hood/zh-cn/part1basic/ch05life/boot)中粗略了解到`schedinit`函数, 现在我们来仔细分析里面真正关于调度器的初始化步骤。
```
// runtime/proc.go
func schedinit() {
_g_ := getg()
(...)
// M 初始化
mcommoninit(_g_.m)
(...)
// P 初始化
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
(...)
}
```
```
TEXT runtime·rt0_go(SB),NOSPLIT,$0
(...)
CALL runtime·schedinit(SB) // M, P 初始化
MOVQ $runtime·mainPC(SB), AX
PUSHQ AX
PUSHQ $0
CALL runtime·newproc(SB) // G 初始化
POPQ AX
POPQ AX
(...)
RET
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
GLOBL runtime·mainPC(SB),RODATA,$8
```
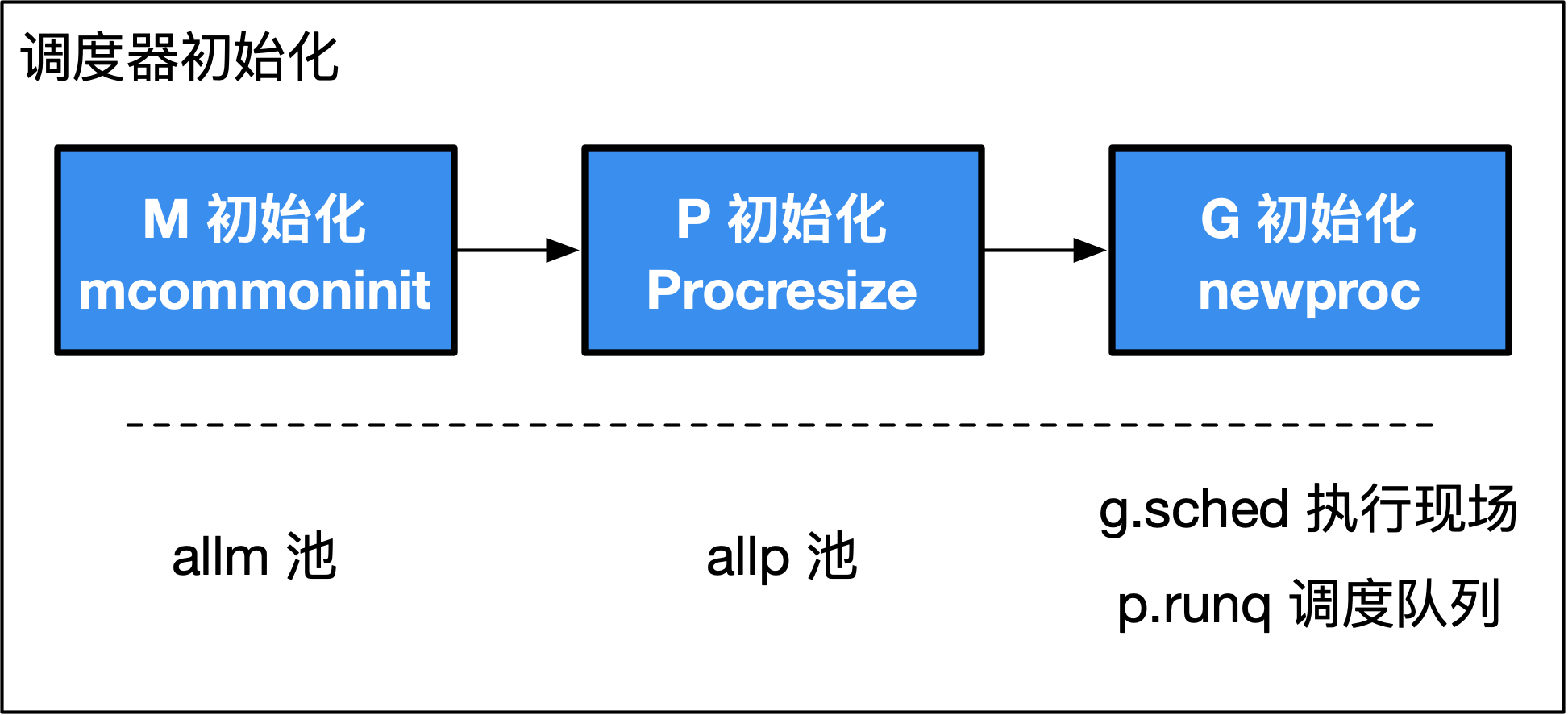**图 1: MPG 初始化过程。M/P/G 彼此的初始化顺序遵循:`mcommoninit`、`procresize`、`newproc`,他们分别负责初始化 M 资源池(`allm`)、P 资源池(`allp`)、G 的运行现场(`g.sched`)以及调度队列(`p.runq`)。**
## 6.3.3 M 初始化
M 其实就是 OS 线程,它只有两个状态:自旋、非自旋。 在调度器初始化阶段,只有一个 M,那就是主 OS 线程,因此这里的`commoninit`仅仅只是对 M 进行一个初步的初始化, 该初始化包含对 M 及用于处理 M 信号的 G 的相关运算操作,未涉及工作线程的暂止和复始。
```
// src/runtime/proc.go
func mcommoninit(mp *m) {
(...)
lock(&sched.lock)
(...)
// mnext 表示当前 m 的数量,还表示下一个 m 的 id
mp.id = sched.mnext
// 增加 m 的数量
sched.mnext++
(...) // 初始化 gsignal,用于处理 m 上的信号
// 添加到 allm 中,从而当它刚保存到寄存器或本地线程存储时候 GC 不会释放 g.m
mp.alllink = allm
// NumCgoCall() 会在没有使用 schedlock 时遍历 allm,等价于 allm = mp
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
(...)
}
```
这里省略了对不影响本节内容的`gsignal`的初始化过程,其作用参见[6.5 信号处理机制](https://golang.design/under-the-hood/zh-cn/part2runtime/ch06sched/signal)。
## 6.3.4 P 初始化
在看`runtime.procresize`函数之前,我们先概览一遍 P 的状态转换图,如图 2 所示。
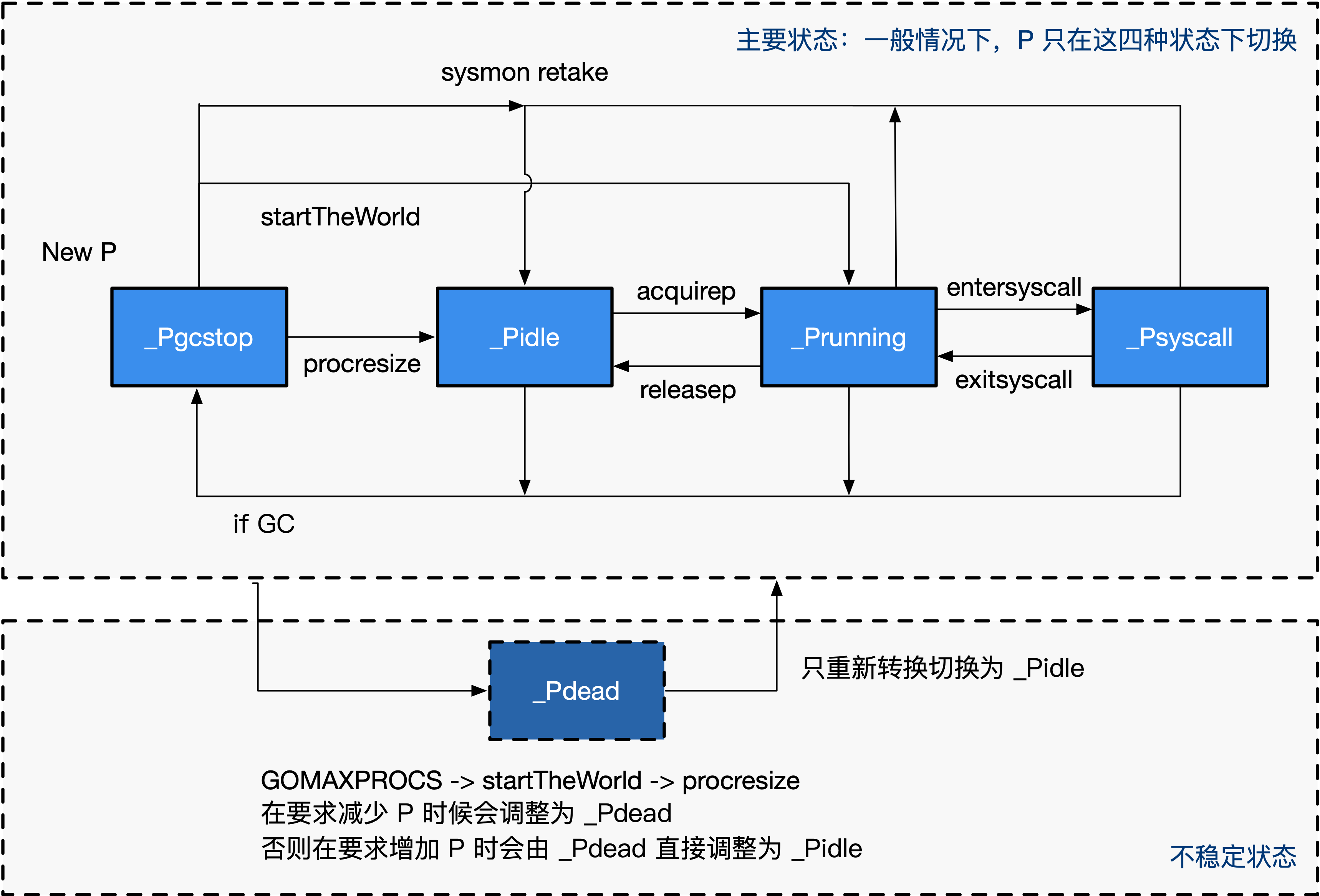**图 2: P 的状态转换图**
通常情况下(在程序运行时不调整 P 的个数),P 只会在四种状态下进行切换。 当程序刚开始运行进行初始化时,所有的 P 都处于`_Pgcstop`状态, 随着 P 的初始化(`runtime.procresize`),会被置于`_Pidle`。
当 M 需要运行时,会`runtime.acquirep`,并通过`runtime.releasep`来释放。 当 G 执行时需要进入系统调用时,P 会被设置为`_Psyscall`, 如果这个时候被系统监控抢夺(`runtime.retake`),则 P 会被重新修改为`_Pidle`。 如果在程序运行中发生 GC,则 P 会被设置为`_Pgcstop`, 并在`runtime.startTheWorld`时重新调整为`_Pidle`或者`_Prunning`。
因为这里我们还在讨论初始化过程,我们先只关注`runtime.procresize`这个函数:
```
func procresize(nprocs int32) *p {
// 获取先前的 P 个数
old := gomaxprocs
(...)
// 更新统计信息,记录此次修改 gomaxprocs 的时间
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
// 必要时增加 allp
// 这个时候本质上是在检查用户代码是否有调用过 runtime.MAXGOPROCS 调整 p 的数量
// 此处多一步检查是为了避免内部的锁,如果 nprocs 明显小于 allp 的可见数量(因为 len)
// 则不需要进行加锁
if nprocs > int32(len(allp)) {
// 此处与 retake 同步,它可以同时运行,因为它不会在 P 上运行。
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
// 如果 nprocs 被调小了,扔掉多余的 p
allp = allp[:nprocs]
} else {
// 否则(调大了)创建更多的 p
nallp := make([]*p, nprocs)
// 将原有的 p 复制到新创建的 new all p 中,不浪费旧的 p
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
// 初始化新的 P
for i := old; i < nprocs; i++ {
pp := allp[i]
// 如果 p 是新创建的(新创建的 p 在数组中为 nil),则申请新的 P 对象
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) // allp[i] = pp
}
_g_ := getg()
// 如果当前正在使用的 P 应该被释放,则更换为 allp[0]
// 否则是初始化阶段,没有 P 绑定当前 P allp[0]
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// 继续使用当前 P
_g_.m.p.ptr().status = _Prunning
(...)
} else {
// 释放当前 P,因为已失效
if _g_.m.p != 0 {
_g_.m.p.ptr().m = 0
}
_g_.m.p = 0
_g_.m.mcache = nil
// 更换到 allp[0]
p := allp[0]
p.m = 0
p.status = _Pidle
acquirep(p) // 直接将 allp[0] 绑定到当前的 M
(...)
}
// 从未使用的 p 释放资源
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// 不能释放 p 本身,因为他可能在 m 进入系统调用时被引用
}
// 清理完毕后,修剪 allp, nprocs 个数之外的所有 P
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}
// 将没有本地任务的 P 放到空闲链表中
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
// 挨个检查 p
p := allp[i]
// 确保不是当前正在使用的 P
if _g_.m.p.ptr() == p {
continue
}
// 将 p 设为 idel
p.status = _Pidle
if runqempty(p) {
// 放入 idle 链表
pidleput(p)
} else {
// 如果有本地任务,则为其绑定一个 M
p.m.set(mget())
// 第一个循环为 nil,后续则为上一个 p
// 此处即为构建可运行的 p 链表
p.link.set(runnablePs)
runnablePs = p
}
}
stealOrder.reset(uint32(nprocs))
atomic.Store((*uint32)(unsafe.Pointer(gomaxprocs)), uint32(nprocs)) // gomaxprocs = nprocs
return runnablePs // 返回所有包含本地任务的 P 链表
}
// 初始化 pp,
func (pp *p) init(id int32) {
// p 的 id 就是它在 allp 中的索引
pp.id = id
// 新创建的 p 处于 _Pgcstop 状态
pp.status = _Pgcstop
(...)
// 为 P 分配 cache 对象
if pp.mcache == nil {
// 如果 old == 0 且 i == 0 说明这是引导阶段初始化第一个 p
if id == 0 {
(...)
pp.mcache = getg().m.mcache // bootstrap
} else {
pp.mcache = allocmcache()
}
}
(...)
}
// 释放未使用的 P,一般情况下不会执行这段代码
func (pp *p) destroy() {
// 将所有 runnable Goroutine 移动至全局队列
for pp.runqhead != pp.runqtail {
// 从本地队列中 pop
pp.runqtail--
gp := pp.runq[pp.runqtail%uint32(len(pp.runq))].ptr()
// push 到全局队列中
globrunqputhead(gp)
}
if pp.runnext != 0 {
globrunqputhead(pp.runnext.ptr())
pp.runnext = 0
}
(...)
// 将当前 P 的空闲的 G 复链转移到全局
gfpurge(pp)
(...)
pp.status = _Pdead
}
```
`procresize`这个函数相对较长,我们来总结一下它主要干了什么事情:
1. 调用时已经 STW,记录调整 P 的时间;
2. 按需调整`allp`的大小;
3. 按需初始化`allp`中的 P;
4. 如果当前的 P 还可以继续使用(没有被移除),则将 P 设置为 \_Prunning;
5. 否则将第一个 P 抢过来给当前 G 的 M 进行绑定
6. 从`allp`移除不需要的 P,将释放的 P 队列中的任务扔进全局队列;
7. 最后挨个检查 P,将没有任务的 P 放入 idle 队列
8. 除去当前 P 之外,将有任务的 P 彼此串联成链表,将没有任务的 P 放回到 idle 链表中
显然,在运行 P 初始化之前,我们刚刚初始化完 M,因此第 7 步中的绑定 M 会将当前的 P 绑定到初始 M 上。 而后由于程序刚刚开始,P 队列是空的,所以他们都会被链接到可运行的 P 链表上处于`_Pidle`状态。
为了向用户层提供对调度器的控制,runtime 包中提供了一些方法达到了这一目的,在本章的最后, 我们来快速过一遍在前面还未提及的在 runtime 包中一些与调度器相关的公共方法。
### 6.3.1 GOMAXPROCS
我们知道在大部分的时间里,P 的数量是不会被动态调整的。 而`runtime.GOMAXPROCS`能够在运行时动态调整 P 的数量,我们就来看看这个调用会做什么事情。
它的代码非常简单:
```
// GOMAXPROCS 设置能够同时执行线程的最大 CPU 数,并返回原先的设定。
// 如果 n < 1,则他不会进行任何修改。
// 机器上的逻辑 CPU 的个数可以从 NumCPU 调用上获取。
// 该调用会在调度器进行改进后被移除。
func GOMAXPROCS(n int) int {
...
// 当调整 P 的数量时,调度器会被锁住
lock(&sched.lock)
ret := int(gomaxprocs)
unlock(&sched.lock)
// 返回原有设置
if n <= 0 || n == ret {
return ret
}
// 停止一切事物,将 STW 的原因设置为 P 被调整
stopTheWorld("GOMAXPROCS")
// STW 后,修改 P 的数量
newprocs = int32(n)
// 重新恢复
// 在这个过程中,startTheWorld 会调用 procresize 进而动态的调整 P 的数量
startTheWorld()
return ret
}
```
可以看到,`GOMAXPROCS`从一出生似乎就被判了死刑,官方的注释已经明确的说明了这个调用 在后续改进调度器后会被移除。
它的过程也非常简单粗暴,调用他必须付出 STW 这种极大的代价。 当 P 被调整为小于 1 或与原有值相同时候,不会产生任何效果,例如:
1
runtime.GOMAXPROCS(runtime.GOMAXPROCS(0))
## 6.3.5 G 初始化
运行完`runtime.procresize`之后,我们知道,主 Goroutine 会以被调度器调度的方式进行运行, 这将由`runtime.newproc`来完成主 Goroutine 的初始化工作。
在看`runtime.newproc`之前,我们先大致浏览一下 G 的各个状态,如图 3 所示。
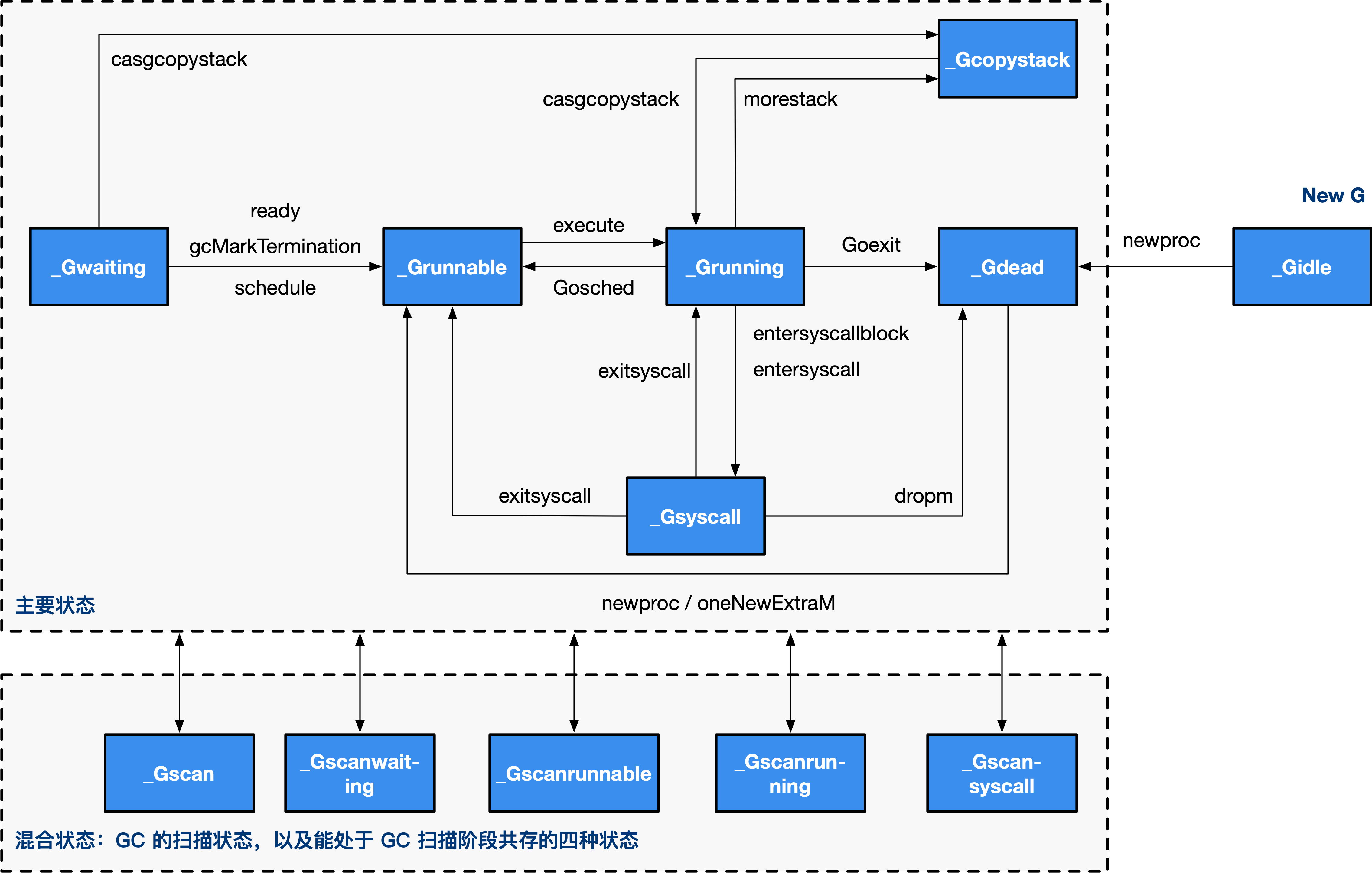**图 3: G 的转状态转换图**
我们接下来就来粗略看一看`runtime.newproc`:
```
//go:nosplit
func newproc(siz int32, fn *funcval) {
// 从 fn 的地址增加一个指针的长度,从而获取第一参数地址
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc() // 获取调用方 PC/IP 寄存器值
// 用 g0 系统栈创建 Goroutine 对象
// 传递的参数包括 fn 函数入口地址, argp 参数起始地址, siz 参数长度, gp(g0),调用方 pc(goroutine)
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}
type funcval struct {
fn uintptr
// 变长大小,fn 的数据在应在 fn 之后
}
// getcallerpc 返回它调用方的调用方程序计数器 PC program conter
//go:noescape
func getcallerpc() uintptr
```
详细的参数获取过程需要编译器的配合,也是实现 Goroutine 的关键。我们来看一下具体的传参过程:
```
package main
func hello(msg string) {
println(msg)
}
func main() {
go hello("hello world")
}
```
```
LEAQ go.string.*+1874(SB), AX // 将 "hello world" 的地址给 AX
MOVQ AX, 0x10(SP) // 将 AX 的值放到 0x10
MOVL $0x10, 0(SP) // 将最后一个参数的位置存到栈顶 0x00
LEAQ go.func.*+67(SB), AX // 将 go 语句调用的函数入口地址给 AX
MOVQ AX, 0x8(SP) // 将 AX 存入 0x08
CALL runtime.newproc(SB) // 调用 newproc
```
这个过程里我们基本上可以看到栈是这样排布的:
~~~
栈布局
| | 高地址
| |
+-----------------+
| &"hello world" |
0x10 +-----------------+ <--- fn + sys.PtrSize
| hello |
0x08 +-----------------+ <--- fn
| siz |
0x00 +-----------------+ SP
| newproc PC |
+-----------------+ callerpc: 要运行的 Goroutine 的 PC
| |
| | 低地址
~~~
从而当`newproc`开始运行时,先获得 siz 作为第一个参数,再获得 fn 作为第二个参数, 然后通过`add`计算出`fn`参数开始的位置。
现在我们知道`newproc`会获取需要执行的 Goroutine 要执行的函数体的地址、 参数起始地址、参数长度、以及 Goroutine 的调用地址。 然后在 g0 系统栈上通过`newproc1`创建并初始化新的 Goroutine ,下面我们来看`newproc1`。
```
// 创建一个运行 fn 的新 g,具有 narg 字节大小的参数,从 argp 开始。
// callerps 是 go 语句的起始地址。新创建的 g 会被放入 g 的队列中等待运行。
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg() // 因为是在系统栈运行所以此时的 g 为 g0
(...)
_g_.m.locks++ // 禁止这时 g 的 m 被抢占因为它可以在一个局部变量中保存 p
siz := narg
siz = (siz + 7) &^ 7
(...)
// 获得 p
_p_ := _g_.m.p.ptr()
// 根据 p 获得一个新的 g
newg := gfget(_p_)
// 初始化阶段,gfget 是不可能找到 g 的
// 也可能运行中本来就已经耗尽了
if newg == nil {
// 创建一个拥有 _StackMin 大小的栈的 g
newg = malg(_StackMin)
// 将新创建的 g 从 _Gidle 更新为 _Gdead 状态
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // 将 Gdead 状态的 g 添加到 allg,这样 GC 不会扫描未初始化的栈
}
(...)
// 计算运行空间大小,对齐
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
// 确定 sp 和参数入栈位置
sp := newg.stack.hi - totalSize
spArg := sp
(...)
// 处理参数,当有参数时,将参数拷贝到 Goroutine 的执行栈中
if narg > 0 {
// 从 argp 参数开始的位置,复制 narg 个字节到 spArg(参数拷贝)
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
// 栈到栈的拷贝。
// 如果启用了 write barrier 并且 源栈为灰色(目标始终为黑色),
// 则执行 barrier 拷贝。
// 因为目标栈上可能有垃圾,我们在 memmove 之后执行此操作。
if writeBarrier.needed && !_g_.m.curg.gcscandone {
f := findfunc(fn.fn)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
if stkmap.nbit > 0 {
// 我们正位于序言部分,因此栈 map 索引总是 0
bv := stackmapdata(stkmap, 0)
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)
}
}
}
// 清理、创建并初始化的 g 的运行现场
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum 从而前一个指令还在相同的函数内
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
// 初始化 g 的基本状态
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp) // 调试相关,追踪调用方
newg.startpc = fn.fn // 入口 pc
(...)
newg.gcscanvalid = false
// 现在将 g 更换为 _Grunnable 状态
casgstatus(newg, _Gdead, _Grunnable)
// 分配 goid
if _p_.goidcache == _p_.goidcacheend {
// Sched.goidgen 为最后一个分配的 id,相当于一个全局计数器
// 这一批必须为 [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// 启动时 sched.goidgen=0, 因此主 Goroutine 的 goid 为 1
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
(...)
// 将这里新创建的 g 放入 p 的本地队列或直接放入全局队列
// true 表示放入执行队列的下一个,false 表示放入队尾
runqput(_p_, newg, true)
// 如果有空闲的 P、且 spinning 的 M 数量为 0,且主 Goroutine 已经开始运行,则进行唤醒 p
// 初始化阶段 mainStarted 为 false,所以 p 不会被唤醒
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
releasem(_g_.m)
}
//go:nosplit
func releasem(mp *m) {
_g_ := getg()
mp.locks--
if mp.locks == 0 && _g_.preempt {
// 如果我们在 newstack 中清除了抢占请求,则恢复抢占请求
_g_.stackguard0 = stackPreempt
}
}
```
创建 G 的过程也是相对比较复杂的,我们来总结一下这个过程:
1. 首先尝试从 P 本地 gfree 链表或全局 gfree 队列获取已经执行过的 g
2. 初始化过程中程序无论是本地队列还是全局队列都不可能获取到 g,因此创建一个新的 g,并为其分配运行线程(执行栈),这时 g 处于`_Gidle`状态
3. 创建完成后,g 被更改为`_Gdead`状态,并根据要执行函数的入口地址和参数,初始化执行栈的 SP 和参数的入栈位置,并将需要的参数拷贝一份存入执行栈中
4. 根据 SP、参数,在`g.sched`中保存 SP 和 PC 指针来初始化 g 的运行现场
5. 将调用方、要执行的函数的入口 PC 进行保存,并将 g 的状态更改为`_Grunnable`
6. 给 Goroutine 分配 id,并将其放入 P 本地队列的队头或全局队列(初始化阶段队列肯定不是满的,因此不可能放入全局队列)
7. 检查空闲的 P,将其唤醒,准备执行 G,但我们目前处于初始化阶段,主 Goroutine 尚未开始执行,因此这里不会唤醒 P。
值得一提的是,`newproc`是由`go:nosplit`修饰的函数(见[6.8 协作与抢占](https://golang.design/under-the-hood/zh-cn/part2runtime/ch06sched/preemption)), 因此这个函数在执行过程中不会发生扩张和抢占,这个函数中的每一行代码都是深思熟虑过、确保能够在有限的栈空间内 完成执行。
## 小结
我们已经分析完了整个运行链条:`mcommoninit`–>`procresize`–>`newproc`。
在调度器的初始化过程中,首先通过`mcommoninit`对 M 的信号 G 进行初始化。 而后通过`procresize`创建与 CPU 核心数 (或与用户指定的 GOMAXPROCS) 相同的 P。 最后通过`newproc`创建包含可以运行要执行函数的执行栈、运行现场的 G,并将创建的 G 放入刚创建好的 P 的本地可运行队列(第一个入队的 G,也就是主 Goroutine 要执行的函数体), 完成 G 的创建。
调度器的设计还是相当巧妙的。它通过引入一个 P,巧妙的减缓了全局锁的调用频率,进一步压榨了机器的性能。 Goroutine 本身也不是什么黑魔法,运行时只是将其作为一个需要运行的入口地址保存在了 G 中, 同时对调用的参数进行了一份拷贝。我们说 P 是处理器自身的抽象,但 P 只是一个纯粹的概念。相反,M 才是运行代码的真身。
- 第一部分 :基础篇
- 第1章 Go语言的前世今生
- 1.2 Go语言综述
- 1.3 顺序进程通讯
- 1.4 Plan9汇编语言
- 第2章 程序生命周期
- 2.1 从go命令谈起
- 2.2 Go程序编译流程
- 2.3 Go 程序启动引导
- 2.4 主Goroutine的生与死
- 第3 章 语言核心
- 3.1 数组.切片与字符串
- 3.2 散列表
- 3.3 函数调用
- 3.4 延迟语句
- 3.5 恐慌与恢复内建函数
- 3.6 通信原语
- 3.7 接口
- 3.8 运行时类型系统
- 3.9 类型别名
- 3.10 进一步阅读的参考文献
- 第4章 错误
- 4.1 问题的演化
- 4.2 错误值检查
- 4.3 错误格式与上下文
- 4.4 错误语义
- 4.5 错误处理的未来
- 4.6 进一步阅读的参考文献
- 第5章 同步模式
- 5.1 共享内存式同步模式
- 5.2 互斥锁
- 5.3 原子操作
- 5.4 条件变量
- 5.5 同步组
- 5.6 缓存池
- 5.7 并发安全散列表
- 5.8 上下文
- 5.9 内存一致模型
- 5.10 进一步阅读的文献参考
- 第二部分 运行时篇
- 第6章 并发调度
- 6.1 随机调度的基本概念
- 6.2 工作窃取式调度
- 6.3 MPG模型与并发调度单
- 6.4 调度循环
- 6.5 线程管理
- 6.6 信号处理机制
- 6.7 执行栈管理
- 6.8 协作与抢占
- 6.9 系统监控
- 6.10 网络轮询器
- 6.11 计时器
- 6.12 非均匀访存下的调度模型
- 6.13 进一步阅读的参考文献
- 第7章 内存分配
- 7.1 设计原则
- 7.2 组件
- 7.3 初始化
- 7.4 大对象分配
- 7.5 小对象分配
- 7.6 微对象分配
- 7.7 页分配器
- 7.8 内存统计
- 第8章 垃圾回收
- 8.1 垃圾回收的基本想法
- 8.2 写屏幕技术
- 8.3 调步模型与强弱触发边界
- 8.4 扫描标记与标记辅助
- 8.5 免清扫式位图技术
- 8.6 前进保障与终止检测
- 8.7 安全点分析
- 8.8 分代假设与代际回收
- 8.9 请求假设与实务制导回收
- 8.10 终结器
- 8.11 过去,现在与未来
- 8.12 垃圾回收统一理论
- 8.13 进一步阅读的参考文献
- 第三部分 工具链篇
- 第9章 代码分析
- 9.1 死锁检测
- 9.2 竞争检测
- 9.3 性能追踪
- 9.4 代码测试
- 9.5 基准测试
- 9.6 运行时统计量
- 9.7 语言服务协议
- 第10章 依赖管理
- 10.1 依赖管理的难点
- 10.2 语义化版本管理
- 10.3 最小版本选择算法
- 10.4 Vgo 与dep之争
- 第12章 泛型
- 12.1 泛型设计的演进
- 12.2 基于合约的泛型
- 12.3 类型检查技术
- 12.4 泛型的未来
- 12.5 进一步阅读的的参考文献
- 第13章 编译技术
- 13.1 词法与文法
- 13.2 中间表示
- 13.3 优化器
- 13.4 指针检查器
- 13.5 逃逸分析
- 13.6 自举
- 13.7 链接器
- 13.8 汇编器
- 13.9 调用规约
- 13.10 cgo与系统调用
- 结束语: Go去向何方?