
[TOC]
>操作系统笔记十篇:[https://blog.csdn.net/qq\_37205708/article/category/8618355](https://blog.csdn.net/qq_37205708/article/category/8618355)
# 操作系统的基本功能
1.进程管理
进程控制、进程同步、进程通信、死锁处理、处理机调度等。
2.内存管理
内存分配、地址映射、内存保护与共享、虚拟内存等。
3.文件管理
文件存储空间的管理、目录管理、文件读写管理和保护等。
4.设备管理
完成用户的 I/O 请求,方便用户使用各种设备,并提高设备的利用率。
主要包括缓冲管理、设备分配、设备处理、虛拟设备等。
## 系统调用
如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。

Linux 的系统调用主要有以下这些:
| Task | Commands |
| :-: | --- |
| 进程控制 | fork(); exit(); wait(); |
| 进程通信 | pipe(); shmget(); mmap(); |
| 文件操作 | open(); read(); write(); |
| 设备操作 | ioctl(); read(); write(); |
| 信息维护 | getpid(); alarm(); sleep(); |
| 安全 | chmod(); umask(); chown(); |
注意特权指令(privileged instruction)和系统调用(system call)并不是一回事,比如如下一些操作属于特权指令:
- 设置定时器
- 清空内存
- 关闭中断
- 修改设备状态表中的条目
- 接入 I/O 设备
可以把特权指令理解为会引起损害的机器指令,如果在用户模式下试图执行特权指令,那么硬件将不会执行该指令,而是认为该指令非法,并将其以 trap 的形式通知 OS。
*****
**系统调用**提供了进程与操作系统间的接口,其目的就是让用户级空间能够请求系统级的服务。比如编写一个从一个文件读取数据并复制到另一个文件的简单程序,对于交互系统,这过程需要一系列的系统调用:首先在屏幕上写出提示信息,再从键盘上读取定义两个文件名称的字符。这个过程就需要许多 I/O 系统调用。后续也还需要许多各方面的系统调用,从中即可看出,系统调用的作用就是让用户级的进程能够请求操作系统的服务。
## 中断的种类
一般来说,同步中断又称为异常(exception),异步中断称为中断(interrupt)
异常又可分为故障(fault)、陷阱(trap)和终止(abort)三类。
| 类别 | 原因 | 异步/同步 | 返回行为 |
| --- | --- | --- | --- |
| 中断 | 来自IO设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 返回到当前的指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
[https://blog.csdn.net/u014134180/article/details/78418428](https://blog.csdn.net/u014134180/article/details/78418428)
# 进程与线程
## 进程
进程是资源分配的基本单位。
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
## 线程
线程是独立调度的基本单位。
一个进程中可以有多个线程,它们共享进程资源。
QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。

## 区别
Ⅰ 拥有资源
进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
更为具体地说,线程之间共享**堆**和**全局变量**,因为堆是在进程空间中开辟出来的,所以肯定是跨线程共享的;同理,全局变量是整个程序所共享的,也应由线程共享。而每个线程都会独立地维护属于自己的**寄存器**与**栈**。
Ⅱ 调度
线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
Ⅲ 系统开销
由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
Ⅳ 通信方面
线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC。
具体来说,进程间通信一般有以下两种形式:1.共享内存 2.消息传递

- 共享内存模式:建立一块供协作进程共享的内存区域,进程通过向此共享区域读或写入数据来交换信息。
- 消息传递模式:通过在协作进程间交换消息来实现通信。
# 程序在内存中的分布

<span style="font-family: 楷体;font-weight: 700;">代码段 .text</span>
也称文本段(Text Segment),存放着程序的机器码和只读数据,可执行指令就是从这里取得的。如果可能,系统会安排好相同程序的多个运行实体共享这些实例代码。这个段在内存中一般被标记为只读,任何对该区的写操作都会导致段错误(Segmentation Fault)。
<span style="font-family: 楷体;font-weight: 700;">BSS段 .bss</span>
BSS 段通常是指用来存放程序中未初始化的全局变量和静态变量的一块内存区域。BSS 是英文 Block Started by Symbol 的简称。BSS 段属于静态内存分配。
<span style="font-family: 楷体;font-weight: 700;">数据段 .data</span>
数据段(data segment)通常是指用来存放程序中已初始化的全局变量和静态变量的一块内存区域。数据段属于静态内存分配。
<span style="font-family: 楷体;font-weight: 700;">堆 Heap</span>
用来存储程序运行时分配的变量。堆的大小并不固定,可动态扩张或缩减。堆的内存的分配与释放由应用程序控制,通常申请的内存都需要释放,如果没有释放,在程序运行结束后操作系统会自动回收。
<span style="font-family: 楷体;font-weight: 700;">栈 Stack</span>
是一种用来存储函数调用时的临时信息的结构,如函数调用所传递的参数、函数的返回地址、函数的局部变量等。 在程序运行时由编译器在需要的时候分配,在不需要的时候自动清除。
- 所谓 **动态存储区域**:即 堆 栈
- 所谓 **静态存储区域**:即 存储静态变量和全局变量以及代码段的部分
# 死锁
## 必要条件

* 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
* 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
* 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
* 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
## 死锁处理
主要有以下四种方法:
* 鸵鸟策略
* 死锁检测与死锁恢复
* 死锁预防
* 死锁避免
**鸵鸟策略**
把头埋在沙子里,假装根本没发生问题。
因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
**死锁检测与死锁恢复**
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。

上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
[更多内容参考](https://github.com/CyC2018/CS-Notes/blob/master/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%20-%20%E6%AD%BB%E9%94%81.md)
**使用银行家算法来保证资源的合理分配**:[https://blog.csdn.net/qq\_37205708/article/details/86550339](https://blog.csdn.net/qq_37205708/article/details/86550339)
# 内存管理
## 物理地址和虚拟地址
段机制启动、页机制未启动:逻辑地址 -> 段机制处理 \-> 线性地址 = 物理地址
段机制和页机制都启动:逻辑地址 -> 段机制处理 \-> 线性地址 -> 页机制处理 \-> 物理地址
- 逻辑地址:CPU 所生成的地址通常称为逻辑地址(logical address)
- 虚拟地址:一般是指逻辑地址,但是因为对程序员而言可见的只有线性地址,有时候也把线性地址称为虚拟地址(可以理解为我们代码中操作的是虚拟地址)
- 物理地址:内存单元所看到的的地址(即被加载到内存地址寄存器(memory-address register)中的地址)通常被称为物理地址(physical address)
对虚拟地址的解释:
每个进程都认为它有独立的物理地址空间且不会认识到物理内存被虚拟化了。操作系统和硬件负责完成虚拟地址到物理地址的转化。
OS 需要建立一个便于使用的物理内存的抽象,这个抽象便是(虚拟)地址空间。对于进程而言,可见的只是(虚拟)地址空间而不是物理内存,即其使用的地址都是虚拟地址,由 OS 转化为物理地址。
## 分段机制
CPU 把逻辑地址(由段选择子 selector 和段偏移 offset 组成)中的段选择子的内容作为段描述符表的索引,找到表中对应的段描述符,然后把段描述符中保存的段基址加上段偏移值,形成线性地址(Linear Address)。如果不启动分页存储管理机制,则线性地址等于物理地址。
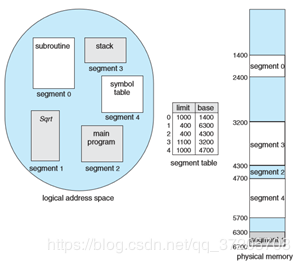
举个例子:
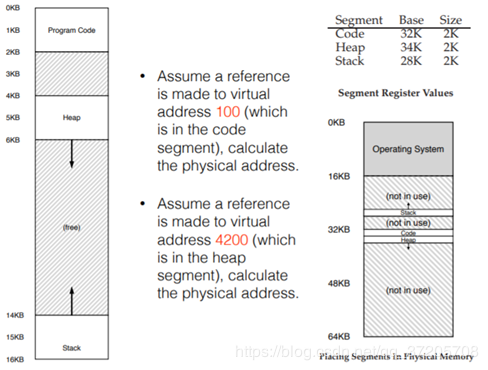
4200 这个逻辑地址(虚拟地址)被划分为段选择子和段偏移:
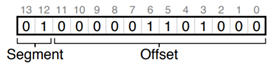
它的段偏移就是 0000 0110 1000, or hex 0x068, or 104 in decimal,段选择子 01 选的是 34K,最后得到对应的物理地址就是 34K+104
- 优点:支持用户视角,实现简单,可以有效利用内存
- 缺点:无法利用碎片,必须搬移内存,造成性能损失(管理空闲空间较难)
## 分页机制
将物理内存分为固定大小的块,称为帧(frame);将逻辑内存也分为同样大小的块,称为页(page)。
每个进程有独立的页表。CPU 生成的地址(虚拟地址)被分为两个部分:页号和偏移,页号作为页表中的索引,页表中的每一项称为页表条目,页表条目存储地址转换的信息。
每新建一个进程 OS 都会为其新建一个页表,即使虚拟地址相同但映射到的物理地址是不同的。页表往往可能很大,所以存储在物理内存中。
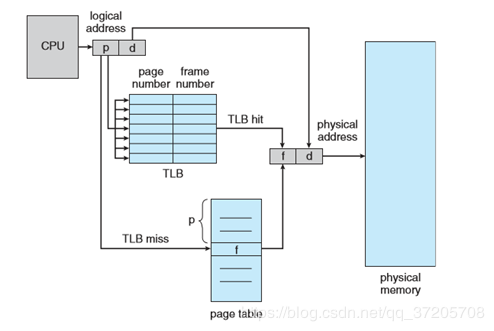
概述一下 TLB和(用于加速地址转换的硬件,可以理解为缓存)页表一起使用的流程:
当 CPU 产生逻辑地址后,其 VPN 提交给 TLB,如果 TLB 命中则得到了帧号并可用来访问内存。如果 TLB 失效,则需要访问页表,同时将页号和帧号增加到 TLB 中。如果 TLB 条目已满,那么 OS 会选择一个来替换,替换策略有多种如 LRU。另外,有的 TLB 允许某些条目固定,即不会替换它们,如内核代码的条目。
更详细的分析见我的 [这篇笔记吧](https://blog.csdn.net/qq_37205708/article/details/86554764)
- 序言 & 更新日志
- H5
- Canvas
- 序言
- Part1-直线、矩形、多边形
- Part2-曲线图形
- Part3-线条操作
- Part4-文本操作
- Part5-图像操作
- Part6-变形操作
- Part7-像素操作
- Part8-渐变与阴影
- Part9-路径与状态
- Part10-物理动画
- Part11-边界检测
- Part12-碰撞检测
- Part13-用户交互
- Part14-高级动画
- CSS
- SCSS
- codePen
- 速查表
- 面试题
- 《CSS Secrets》
- SVG
- 移动端适配
- 滤镜(filter)的使用
- JS
- 基础概念
- 作用域、作用域链、闭包
- this
- 原型与继承
- 数组、字符串、Map、Set方法整理
- 垃圾回收机制
- DOM
- BOM
- 事件循环
- 严格模式
- 正则表达式
- ES6部分
- 设计模式
- AJAX
- 模块化
- 读冴羽博客笔记
- 第一部分总结-深入JS系列
- 第二部分总结-专题系列
- 第三部分总结-ES6系列
- 网络请求中的数据类型
- 事件
- 表单
- 函数式编程
- Tips
- JS-Coding
- Framework
- Vue
- 书写规范
- 基础
- vue-router & vuex
- 深入浅出 Vue
- 响应式原理及其他
- new Vue 发生了什么
- 组件化
- 编译流程
- Vue Router
- Vuex
- 前端路由的简单实现
- React
- 基础
- 书写规范
- Redux & react-router
- immutable.js
- CSS 管理
- React 16新特性-Fiber 与 Hook
- 《深入浅出React和Redux》笔记
- 前半部分
- 后半部分
- react-transition-group
- Vue 与 React 的对比
- 工程化与架构
- Hybird
- React Native
- 新手上路
- 内置组件
- 常用插件
- 问题记录
- Echarts
- 基础
- Electron
- 序言
- 配置 Electron 开发环境 & 基础概念
- React + TypeScript 仿 Antd
- TypeScript 基础
- 样式设计
- 组件测试
- 图标解决方案
- Algorithm
- 排序算法及常见问题
- 剑指 offer
- 动态规划
- DataStruct
- 概述
- 树
- 链表
- Network
- Performance
- Webpack
- PWA
- Browser
- Safety
- 微信小程序
- mpvue 课程实战记录
- 服务器
- 操作系统基础知识
- Linux
- Nginx
- redis
- node.js
- 基础及原生模块
- express框架
- node.js操作数据库
- 《深入浅出 node.js》笔记
- 前半部分
- 后半部分
- 数据库
- SQL
- 面试题收集
- 智力题
- 面试题精选1
- 面试题精选2
- 问答篇
- Other
- markdown 书写
- Git
- LaTex 常用命令