
自动拆分有以下策略。
**1. ConstantSizeRegionSplitPolicy**(了解即可)
在 0.94 版本的时候 HBase 只有一种拆分策略。这个策略非常简单,从名字上就可以看出这个策略就是按照固定大小来拆分 Region。控制它的参数是:
| hbase.hregion.max.filesize | Region 的最大大小。默认是 10GB|
| --- | --- |
当单个 Region 大小超过了 10GB,就会被 HBase 拆分成为 2 个 Region。采用这种策略后的集群中的 Region大小很平均,理想情况下都是5GB。由于这种策略太简单了,所以不再详细解释了。<br/>
**2. IncreasingToUpperBoundRegionSplitPolicy**(0.94 版本后默认,需要掌握理解)。
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。依赖以下公式来计算文件尺寸的上限增长:
```[math]
Math.min(tableRegionsCounts^3 * initialSize,defaultRegionMaxFileSize)
```
`tableRegionCount`:表在所有 RegionServer 上所拥有的 Region 数量总和。
`initialSize`:如果定义了 hbase.increasing.policy.initial.size,则使用这个数值;如果没有定义,就用 memstore 的刷写大小的2倍 ,hbase.hregion.memstore.flush.size * 2。
`defaultRegionMaxFileSize` : ConstantSizeRegionSplitPolicy 所用到的hbase.hregion.max.filesize,即 Region 最大大小。
<br/>
假如 hbase.hregion.memstore.flush.size 定义为 128MB,那么文件尺寸的上限增长将是这样:
( 1 ) 刚 开 始 只 有 一 个 region 的 时 候 , 上 限 是 256MB ,因为 `$ 1^3 *128*2=256MB $`。
(2)当有 2 个 region 的时候,上限是 2GB,因为 `$ 2^3 * 128*2=2048MB $`。
(3)当有 3 个文件的时候,上限是 6.75GB,因为 `$ 3^3 * 128 * 2=6912MB $`。
(4)以此类推,直到计算出来的上限达到 hbase.hregion.max.filesize 所定义region 的 默认的10GB。
走势图如下图:
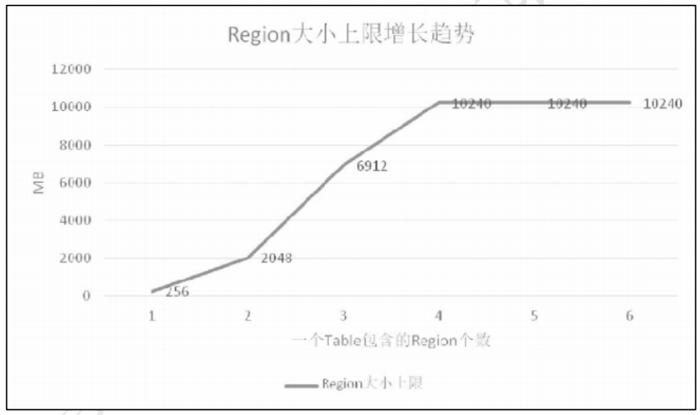
当 Region 个数达到 4 个的时候由于计算出来的上限已经达到了 16GB,已经大于 10GB 了,所以后面当 Region 数量再增加的时候文件大小上限已经不会增加了。在最新的版本里 IncreasingToUpperBoundRegionSplitPolicy 是默认的配置。
<br/>
**3. KeyPrefixRegionSplitPolicy**(扩展内容)
除了简单粗暴地根据大小来拆分,我们还可以自己定义拆分点。KeyPrefixRegionSplitPolicy 是 IncreasingToUpperBoundRegionSplitPolicy 的子类,在前者的基础上,增加了对拆分点(splitPoint,拆分点就是 Region 被拆分处的rowkey)的定义。它保证了有相同前缀的 rowkey 不会被拆分到两个不同的 Region 里面。这个策略用到的参数如下:
| `KeyPrefixRegionSplitPolicy.prefix_length` | rowkey 的前缀长度 |
| --- | --- |
该策略会根据 KeyPrefixRegionSplitPolicy.prefix_length 所定义的长度来截取rowkey 作为分组的依据,同一个组的数据不会被划分到不同的 Region 上。比如rowKey 都是 16 位的,指定前 5 位是前缀,那么前 5 位相同的 rowKey 在进行 region split 的时候会分到相同的 region 中。用默认策略拆分跟用KeyPrefixRegionSplitPolicy 拆分的区别如下:
:-: 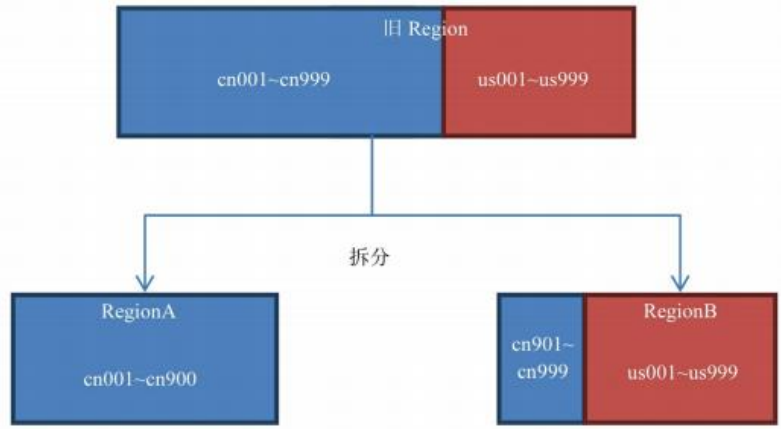
默认策略拆分结果图
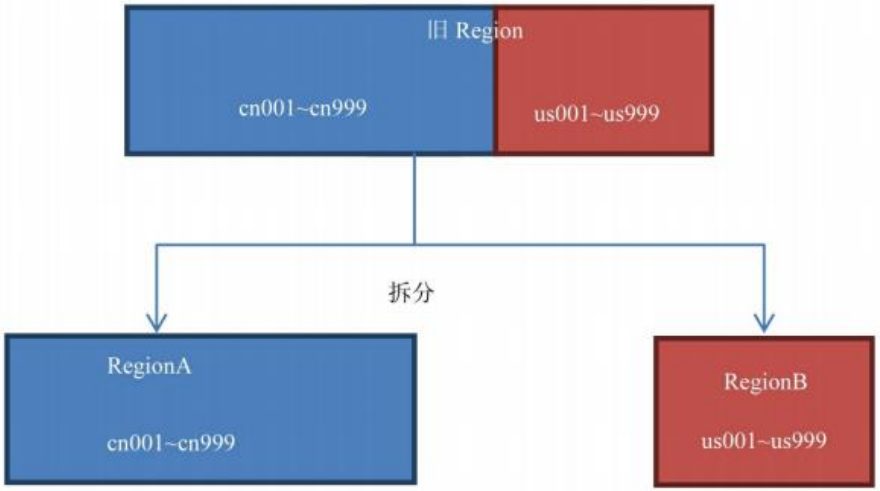
KeyPrefixRegionSplitPolicy(前 2 位)拆分结果图
<br/>
如果你的所有数据都只有一两个前缀,那么 KeyPrefixRegionSplitPolicy 就无效了,此时采用默认的策略较好。如果你的前缀划分的比较细,你的查询就比较容易发生跨 Region 查询的情况,此时采用 KeyPrefixRegionSplitPolicy 较好。<br/>
所以这个策略适用的场景是:数据有多种前缀。查询多是针对前缀,比较少跨越多个前缀来查询数据。
<br/>
**4. DelimitedKeyPrefixRegionSplitPolicy**(扩展内容)
该策略也是继承自 IncreasingToUpperBoundRegionSplitPolicy,它也是根据你的 rowkey 前缀来进行切分的。唯一的不同就是:KeyPrefixRegionSplitPolicy 是根据 rowkey 的固定前几位字符来进行判断,而DelimitedKeyPrefixRegionSplitPolicy是根据分隔符来判断的。有时候 rowkey 的前缀可能不一定都是定长的,比如你拿服务器的名字来当前缀,有的服务器叫 host12 有的叫 host1。这些场景下严格地要求所有前缀都定长可能比较难,而且这个定长如果未来想改也不容易。
DelimitedKeyPrefixRegionSplitPolicy 就给了你一个定义长度字符前缀的自由。使用这个策略需要在表定义中加入以下属性:
```
DelimitedKeyPrefixRegionSplitPolicy.delimiter:前缀分隔符
```
比如你定义了前缀分隔符为`_`,那么 host1_001 和 host12_999 的前缀就分别是 host1 和 host12。
<br/>
**5. BusyRegionSplitPolicy**(扩展内容)
此前的拆分策略都没有考虑热点问题。所谓热点问题就是数据库中的Region 被访问的频率并不一样,某些 Region 在短时间内被访问的很频繁,承载了很大的压力,这些 Region 就是热点 Region。BusyRegionSplitPolicy 就是为了解决这种场景而产生的。它是如何判断哪个 Region 是热点的呢,首先先要介绍它用到的参数:
**`hbase.busy.policy.blockedRequests`**:请求阻塞率,即请求被阻塞的严重程度。取值范围是 0.0~1.0,默认是 0.2,即 20%的请求被阻塞的意思。
**`hbase.busy.policy.minAge`**:拆分最小年龄,当 Region 的年龄比这个小的时候不拆分,这是为了防止在判断是否要拆分的时候出现了短时间的访问频率波峰,结果没必要拆分的 Region 被拆分了,因为短时间的波峰会很快地降回到正常水平。单位毫秒,默认值是 600000,即 10 分钟。
**`hbase.busy.policy.aggWindow`**:计算是否繁忙的时间窗口,单位毫秒,默认值是 300000,即 5 分钟。用以控制计算的频率。计算该 Region 是否繁忙的计算
方法如下:
```
如果"当前时间–上次检测时间>=hbase.busy.policy.aggWindow",则进行如下计算:
这段时间被阻塞的请求/这段时间的总请求=请求的被阻塞率(aggBlockedRate)
如果"aggBlockedRate > hbase.busy.policy.blockedRequests",则判断该 Region为繁忙。
```
如果你的系统常常会出现热点 Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点 Region 来缓解热点 Region 的压力,但是根据热点来拆分 Region 也会带来很多不确定性因素,因为你也不知道下一个被拆分的 Region 是哪个。
<br/>
**6. DisabledRegionSplitPolicy**
这种策略其实不是一种策略。如果你看这个策略的源码会发现就一个方法shouldSplit,并且永远返回 false。所以设置成这种策略就是 Region 永不自动拆分。<br/>
如果使用 DisabledRegionSplitPolicy 让 Region 永不自动拆分之后,你依然可以通过手动拆分来拆分 Region。<br/>
这个策略有什么用?无论你设置了哪种拆分策略,一开始数据进入 Hbase的时候都只会往一个 Region 塞数据。必须要等到一个 Region 的大小膨胀到某个阀值的时候才会根据拆分策略来进行拆分。但是当大量的数据涌入的时候,可能会出现一边拆分一边写入大量数据的情况,由于拆分要占用大量 IO,有可能对数据库造成一定的压力。如果你事先就知道这个 Table 应该按怎样的策略来拆分Region 的话,你也可以事先定义拆分点(SplitPoint)。所谓拆分点就是拆分处的rowkey,比如你可以按 26 个字母来定义 25 个拆分点,这样数据一到 HBase 就会被分配到各自所属的 Region 里面。这时候我们就可以把自动拆分关掉,只用手动拆分。
- Hadoop
- hadoop是什么?
- Hadoop组成
- hadoop官网
- hadoop安装
- hadoop配置
- 本地运行模式配置
- 伪分布运行模式配置
- 完全分布运行模式配置
- HDFS分布式文件系统
- HDFS架构
- HDFS设计思想
- HDFS组成架构
- HDFS文件块大小
- HDFS优缺点
- HDFS Shell操作
- HDFS JavaAPI
- 基本使用
- HDFS的I/O 流操作
- 在SpringBoot项目中的API
- HDFS读写流程
- HDFS写流程
- HDFS读流程
- NN和SNN关系
- NN和SNN工作机制
- Fsimage和 Edits解析
- checkpoint时间设置
- NameNode故障处理
- 集群安全模式
- DataNode工作机制
- 支持的文件格式
- MapReduce分布式计算模型
- MapReduce是什么?
- MapReduce设计思想
- MapReduce优缺点
- MapReduce基本使用
- MapReduce编程规范
- WordCount案例
- MapReduce任务进程
- Hadoop序列化对象
- 为什么要序列化
- 常用数据序列化类型
- 自定义序列化对象
- MapReduce框架原理
- MapReduce工作流程
- MapReduce核心类
- MapTask工作机制
- Shuffle机制
- Partition分区
- Combiner合并
- ReduceTask工作机制
- OutputFormat
- 使用MapReduce实现SQL Join操作
- Reduce join
- Reduce join 代码实现
- Map join
- Map join 案例实操
- MapReduce 开发总结
- Hadoop 优化
- MapReduce 优化需要考虑的点
- MapReduce 优化方法
- 分布式资源调度框架 Yarn
- Yarn 基本架构
- ResourceManager(RM)
- NodeManager(NM)
- ApplicationMaster
- Container
- 作业提交全过程
- JobHistoryServer 使用
- 资源调度器
- 先进先出调度器(FIFO)
- 容量调度器(Capacity Scheduler)
- 公平调度器(Fair Scheduler)
- Yarn 常用命令
- Zookeeper
- zookeeper是什么?
- zookeeper完全分布式搭建
- Zookeeper特点
- Zookeeper数据结构
- Zookeeper 内部原理
- 选举机制
- stat 信息中字段解释
- 选择机制中的概念
- 选举消息内容
- 监听器原理
- Hadoop 高可用集群搭建
- Zookeeper 应用
- Zookeeper Shell操作
- Zookeeper Java应用
- Hive
- Hive是什么?
- Hive的优缺点
- Hive架构
- Hive元数据存储模式
- 内嵌模式
- 本地模式
- 远程模式
- Hive环境搭建
- 伪分布式环境搭建
- Hive命令工具
- 命令行模式
- 交互模式
- Hive数据类型
- Hive数据结构
- 参数配置方式
- Hive数据库
- 数据库存储位置
- 数据库操作
- 表的创建
- 建表基本语法
- 内部表
- 外部表
- 临时表
- 建表高阶语句
- 表的删除与修改
- 分区表
- 静态分区
- 动态分区
- 分桶表
- 创建分桶表
- 分桶抽样
- Hive视图
- 视图的创建
- 侧视图Lateral View
- Hive数据导入导出
- 导入数据
- 导出数据
- 查询表数据量
- Hive事务
- 事务是什么?
- Hive事务的局限性和特点
- Hive事务的开启和设置
- Hive PLSQL
- Hive高阶查询
- 查询基本语法
- 基本查询
- distinct去重
- where语句
- 列正则表达式
- 虚拟列
- CTE查询
- 嵌套查询
- join语句
- 内连接
- 左连接
- 右连接
- 全连接
- 多表连接
- 笛卡尔积
- left semi join
- group by分组
- having刷选
- union与union all
- 排序
- order by
- sort by
- distribute by
- cluster by
- 聚合运算
- 基本聚合
- 高级聚合
- 窗口函数
- 序列窗口函数
- 聚合窗口函数
- 分析窗口函数
- 窗口函数练习
- 窗口子句
- Hive函数
- Hive函数分类
- 字符串函数
- 类型转换函数
- 数学函数
- 日期函数
- 集合函数
- 条件函数
- 聚合函数
- 表生成函数
- 自定义Hive函数
- 自定义函数分类
- 自定义Hive函数流程
- 添加JAR包的方式
- 自定义临时函数
- 自定义永久函数
- Hive优化
- Hive性能调优工具
- EXPLAIN
- ANALYZE
- Fetch抓取
- 本地模式
- 表的优化
- 小表 join 大表
- 大表 join 大表
- 开启Map Join
- group by
- count(distinct)
- 笛卡尔积
- 行列过滤
- 动态分区调整
- 分区分桶表
- 数据倾斜
- 数据倾斜原因
- 调整Map数
- 调整Reduce数
- 产生数据倾斜的场景
- 并行执行
- 严格模式
- JVM重用
- 推测执行
- 启用CBO
- 启动矢量化
- 使用Tez引擎
- 压缩算法和文件格式
- 文件格式
- 压缩算法
- Zeppelin
- Zeppelin是什么?
- Zeppelin安装
- 配置Hive解释器
- Hbase
- Hbase是什么?
- Hbase环境搭建
- Hbase分布式环境搭建
- Hbase伪分布式环境搭建
- Hbase架构
- Hbase架构组件
- Hbase数据存储结构
- Hbase原理
- Hbase Shell
- 基本操作
- 表操作
- namespace
- Hbase Java Api
- Phoenix集成Hbase
- Phoenix是什么?
- 安装Phoenix
- Phoenix数据类型
- Phoenix Shell
- HBase与Hive集成
- HBase与Hive的对比
- HBase与Hive集成使用
- Hbase与Hive集成原理
- HBase优化
- RowKey设计
- 内存优化
- 基础优化
- Hbase管理
- 权限管理
- Region管理
- Region的自动拆分
- Region的预拆分
- 到底采用哪种拆分策略?
- Region的合并
- HFile的合并
- 为什么要有HFile的合并
- HFile合并方式
- Compaction执行时间
- Compaction相关控制参数
- 演示示例
- Sqoop
- Sqoop是什么?
- Sqoop环境搭建
- RDBMS导入到HDFS
- RDBMS导入到Hive
- RDBMS导入到Hbase
- HDFS导出到RDBMS
- 使用sqoop脚本
- Sqoop常用命令
- Hadoop数据模型
- TextFile
- SequenceFile
- Avro
- Parquet
- RC&ORC
- 文件存储格式比较
- Spark
- Spark是什么?
- Spark优势
- Spark与MapReduce比较
- Spark技术栈
- Spark安装
- Spark Shell
- Spark架构
- Spark编程入口
- 编程入口API
- SparkContext
- SparkSession
- Spark的maven依赖
- Spark RDD编程
- Spark核心数据结构-RDD
- RDD 概念
- RDD 特性
- RDD编程
- RDD编程流程
- pom依赖
- 创建算子
- 转换算子
- 动作算子
- 持久化算子
- RDD 与闭包
- csv/json数据源
- Spark分布式计算原理
- RDD依赖
- RDD转换
- RDD依赖
- DAG工作原理
- Spark Shuffle原理
- Shuffle的作用
- ShuffleManager组件
- Shuffle实践
- RDD持久化
- 缓存机制
- 检查点
- 检查点与缓存的区别
- RDD共享变量
- 广播变量
- 累计器
- RDD分区设计
- 数据倾斜
- 数据倾斜的根本原因
- 定位导致的数据倾斜
- 常见数据倾斜解决方案
- Spark SQL
- SQL on Hadoop
- Spark SQL是什么
- Spark SQL特点
- Spark SQL架构
- Spark SQL运行原理
- Spark SQL编程
- Spark SQL编程入口
- 创建Dataset
- Dataset是什么
- SparkSession创建Dataset
- 样例类创建Dataset
- 创建DataFrame
- DataFrame是什么
- 结构化数据文件创建DataFrame
- RDD创建DataFrame
- Hive表创建DataFrame
- JDBC创建DataFrame
- SparkSession创建
- RDD、DataFrame、Dataset
- 三者对比
- 三者相互转换
- RDD转换为DataFrame
- DataFrame转换为RDD
- DataFrame API
- DataFrame API分类
- Action 操作
- 基础 Dataset 函数
- 强类型转换
- 弱类型转换
- Spark SQL外部数据源
- Parquet文件
- Hive表
- RDBMS表
- JSON/CSV
- Spark SQL函数
- Spark SQL内置函数
- 自定SparkSQL函数
- Spark SQL CLI
- Spark SQL性能优化
- Spark GraphX图形数据分析
- 为什么需要图计算
- 图的概念
- 图的术语
- 图的经典表示法
- Spark Graphix简介
- Graphx核心抽象
- Graphx Scala API
- 核心组件
- 属性图应用示例1
- 属性图应用示例2
- 查看图信息
- 图的算子
- 连通分量
- PageRank算法
- Pregel分布式计算框架
- Flume日志收集
- Flume是什么?
- Flume官方文档
- Flume架构
- Flume安装
- Flume使用过程
- Flume组件
- Flume工作流程
- Flume事务
- Source、Channel、Sink文档
- Source文档
- Channel文档
- Sink文档
- Flume拦截器
- Flume拦截器概念
- 配置拦截器
- 自定义拦截器
- Flume可靠性保证
- 故障转移
- 负载均衡
- 多层代理
- 多路复用
- Kafka
- 消息中间件MQ
- Kafka是什么?
- Kafka安装
- Kafka本地单机部署
- Kafka基本命令使用
- Topic的生产与消费
- 基本命令
- 查看kafka目录
- Kafka架构
- Kafka Topic
- Kafka Producer
- Kafka Consumer
- Kafka Partition
- Kafka Message
- Kafka Broker
- 存储策略
- ZooKeeper在Kafka中的作用
- 副本同步
- 容灾
- 高吞吐
- Leader均衡机制
- Kafka Scala API
- Producer API
- Consumer API
- Kafka优化
- 消费者参数优化
- 生产者参数优化
- Spark Streaming
- 什么是流?
- 批处理和流处理
- Spark Streaming简介
- 流数据处理架构
- 内部工作流程
- StreamingContext组件
- SparkStreaming的编程入口
- WordCount案例
- DStream
- DStream是什么?
- Input DStream与Receivers接收器
- DStream API
- 转换操作
- 输出操作
- 数据源
- 数据源分类
- Socket数据源
- 统计HDFS文件的词频
- 处理状态数据
- SparkStreaming整合SparkSQL
- SparkStreaming整合Flume
- SparkStreaming整合Kafka
- 自定义数据源
- Spark Streaming优化策略
- 优化运行时间
- 优化内存使用
- 数据仓库
- 数据仓库是什么?
- 数据仓库的意义
- 数据仓库和数据库的区别
- OLTP和OLAP的区别
- OLTP的特点
- OLAP的特点
- OLTP与OLAP对比
- 数据仓库架构
- Inmon架构
- Kimball架构
- 混合型架构
- 数据仓库的解决方案
- 数据ETL
- 数据仓库建模流程
- 维度模型
- 星型模式
- 雪花模型
- 星座模型
- 数据ETL处理
- 数仓分层术语
- 数据抽取方式
- CDC抽取方案
- 数据转换
- 常见的ETL工具