
[TOC]
# 1. 图常用算子
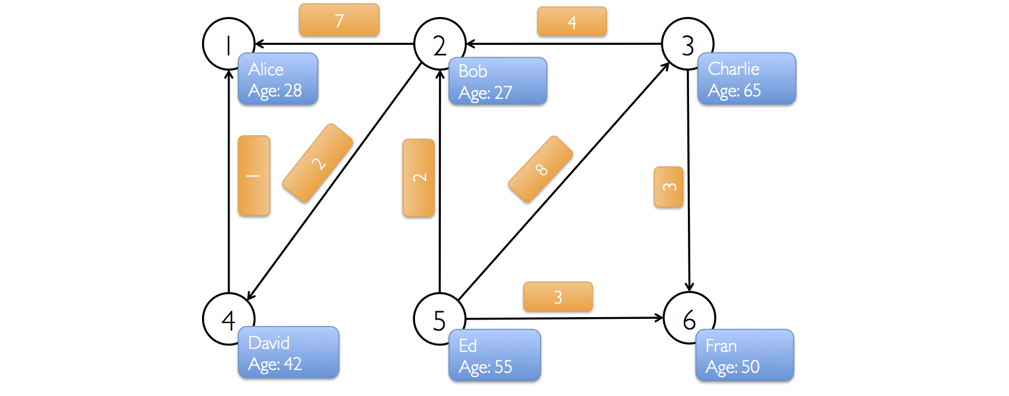
```scala
import org.apache.spark.SparkContext
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object GraphxFun {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getName)
.getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
// 1. 构建点集合
val users: RDD[(Long, (String, Int))] = sc.parallelize(Array(
(1L, ("Alice", 28)),
(2L, ("Bob", 27)),
(3L, ("Charlie", 65)),
(4L, ("David", 42)),
(5L, ("Ed", 55)),
(6L, ("Fran", 50))
))
// 2. 构建边集合
val cntCall: RDD[Edge[Int]] = sc.parallelize(Array(
Edge(2L, 1L, 7),
Edge(2L, 4L, 2),
Edge(3L, 2L, 4),
Edge(3L, 6L, 3),
Edge(4L, 1L, 1),
Edge(5L, 2L, 2),
Edge(5L, 3L, 8),
Edge(5L, 6L, 3)
))
// 3. 构图
val graph: Graph[(String, Int), Int] = Graph(users, cntCall)
graph.triplets.foreach(x => println(x.toString()))
// ((5,(Ed,55)),(3,(Charlie,65)),8)
// ((2,(Bob,27)),(1,(Alice,28)),7)
// ((4,(David,42)),(1,(Alice,28)),1)
// ((3,(Charlie,65)),(2,(Bob,27)),4)
// ((5,(Ed,55)),(2,(Bob,27)),2)
// ((2,(Bob,27)),(4,(David,42)),2)
// ((5,(Ed,55)),(6,(Fran,50)),3)
// ((3,(Charlie,65)),(6,(Fran,50)),3)
println()
/** ********** mapXXX算子 ********************/
// 通过遍历该图的所有顶点,生成一个新的图
// 可以改变顶点的attr,并生成一个新的Graph返回,但顶点的Id改变不了
val graph2: Graph[(VertexId, String), Int] = graph.mapVertices((vertexId, attr) => (vertexId * 100, attr._1))
// 也可以采用如下写法,结果是一样的
// val graph2: Graph[(VertexId, String), Int] = graph.mapVertices({ case (vertexId, (name, age)) => (vertexId * 100, name) })
graph2.triplets.foreach(x => println(x.toString()))
// ((2,(200,Bob)),(1,(100,Alice)),7)
// ((2,(200,Bob)),(4,(400,David)),2)
// ((5,(500,Ed)),(3,(300,Charlie)),8)
// ((3,(300,Charlie)),(2,(200,Bob)),4)
// ((4,(400,David)),(1,(100,Alice)),1)
// ((5,(500,Ed)),(2,(200,Bob)),2)
// ((5,(500,Ed)),(6,(600,Fran)),3)
// ((3,(300,Charlie)),(6,(600,Fran)),3)
println()
// 遍历该图的所有边,生成一个新的图
// 只能改变边的attr,点什么都不能改变
val graph3: Graph[(String, Int), Int] = graph.mapEdges(e => e.attr * 100)
graph3.triplets.foreach(x => println(x.toString()))
// ((2,(Bob,27)),(1,(Alice,28)),700)
// ((2,(Bob,27)),(4,(David,42)),200)
// ((3,(Charlie,65)),(2,(Bob,27)),400)
// ((4,(David,42)),(1,(Alice,28)),100)
// ((5,(Ed,55)),(2,(Bob,27)),200)
// ((3,(Charlie,65)),(6,(Fran,50)),300)
// ((5,(Ed,55)),(3,(Charlie,65)),800)
// ((5,(Ed,55)),(6,(Fran,50)),300)
println()
/** ************ 结构算子 ***************/
// 将该图所有边的方向反转,并生成新的Graph
val graph4: Graph[(String, Int), Int] = graph.reverse
graph4.triplets.foreach(println)
// ((1,(Alice,28)),(2,(Bob,27)),7)
// ((2,(Bob,27)),(3,(Charlie,65)),4)
// ((3,(Charlie,65)),(5,(Ed,55)),8)
// ((1,(Alice,28)),(4,(David,42)),1)
// ((6,(Fran,50)),(5,(Ed,55)),3)
// ((6,(Fran,50)),(3,(Charlie,65)),3)
// ((4,(David,42)),(2,(Bob,27)),2)
// ((2,(Bob,27)),(5,(Ed,55)),2)
println()
// 生成满足顶点条件的子图
val graph6: Graph[(String, Int), Int] = graph.subgraph(vpred = (id, attr) => attr._2 < 65)
graph6.triplets.foreach(println)
// ((5,(Ed,55)),(6,(Fran,50)),3)
// ((2,(Bob,27)),(1,(Alice,28)),7)
// ((2,(Bob,27)),(4,(David,42)),2)
// ((4,(David,42)),(1,(Alice,28)),1)
// ((5,(Ed,55)),(2,(Bob,27)),2)
println()
/** ************* join算子 ****************/
// 构建顶点集合
val vertices: RDD[(VertexId, String)] = sc.parallelize(Array((1L, "kgc.cn"), (2L, "baidu.com"), (3L, "google.com")))
// 内连接,根据顶点Id相等进行join,并生成连接后的图
// id: 图中顶点的Id与vertices顶点Id的交集
// attr: 图中顶点的attr
// company: vertices顶点的attr
val graph7: Graph[(String, Int), Int] = graph.joinVertices(vertices)((id, attr, company) => (id * 100 + "@" + company, attr._2))
graph7.triplets.foreach(println)
// ((3,(300@google.com,65)),(2,(200@baidu.com,27)),4)
// ((3,(300@google.com,65)),(6,(Fran,50)),3)
// ((5,(Ed,55)),(3,(300@google.com,65)),8)
// ((5,(Ed,55)),(6,(Fran,50)),3)
// ((4,(David,42)),(1,(100@kgc.cn,28)),1)
// ((5,(Ed,55)),(2,(200@baidu.com,27)),2)
// ((2,(200@baidu.com,27)),(1,(100@kgc.cn,28)),7)
// ((2,(200@baidu.com,27)),(4,(David,42)),2)
println()
// 外连接,
// Id: 图顶点Id和vertices顶点Id的并集
// attr: 图顶点的attr
// company: vertices顶点attr,图顶点Id不等于vertices中的顶点Id,则company默认为None
val graph8: Graph[(String, Int), Int] = graph.outerJoinVertices(vertices)((id, attr, company) => (id * 100 + "#" + company, attr._2))
graph8.triplets.foreach(println)
// ((4,(400#None,42)),(1,(100#Some(kgc.cn),28)),1)
// ((5,(500#None,55)),(2,(200#Some(baidu.com),27)),2)
// ((5,(500#None,55)),(3,(300#Some(google.com),65)),8)
// ((5,(500#None,55)),(6,(600#None,50)),3)
// ((2,(200#Some(baidu.com),27)),(1,(100#Some(kgc.cn),28)),7)
// ((2,(200#Some(baidu.com),27)),(4,(400#None,42)),2)
// ((3,(300#Some(google.com),65)),(2,(200#Some(baidu.com),27)),4)
// ((3,(300#Some(google.com),65)),(6,(600#None,50)),3)
}
}
```
下面举两个图算子应用的案例,帮助理解算子用途。
<br/>
# 2. 案例一:计算用户的粉丝数量

顶点的入度就是这个用户的粉丝数量。
```scala
import org.apache.spark.SparkContext
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object ComputeFanNum {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getName)
.getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
// 1. 构造顶点RDD
val users: RDD[(Long, (String, Int))] = sc.parallelize(Array(
(1L, ("Alice", 28)),
(2L, ("Bob", 27)),
(3L, ("Charlie", 65)),
(4L, ("David", 55)),
(5L, ("Ed", 55)),
(6L, ("Fran", 50))
))
// 2. 构造边RDD
val cntCall: RDD[Edge[Int]] = sc.parallelize(Array(
Edge(2L, 1L, 7),
Edge(2L, 4L, 2),
Edge(3L, 2L, 4),
Edge(3L, 6L, 3),
Edge(4L, 1L, 1),
Edge(5L, 2L, 2),
Edge(5L, 3L, 8),
Edge(5L, 6L, 3)
))
// 3. 构图
val graph: Graph[(String, Int), Int] = Graph(users, cntCall)
case class User(name: String, age: Int, inDeg: Int, outDeg: Int)
// 将顶点attr转换为User
val initUserGraph: Graph[User, Int] = graph.mapVertices({ case (id, (name, age)) => User(name, age, 0, 0) })
val userGraph: Graph[User, Int] = initUserGraph.outerJoinVertices(initUserGraph.inDegrees)({
case (id, attr, inDegOpt) => User(attr.name, attr.age, inDegOpt.getOrElse(0), 0)
}).outerJoinVertices(initUserGraph.outDegrees)({
case (id, attr, outDegOpt) => User(attr.name, attr.age, attr.inDeg, outDegOpt.getOrElse(0))
})
userGraph.vertices.foreach(x => println(s"用户${x._1}是${x._2.name}他拥有${x._2.inDeg}个粉丝."))
// 用户4是David他拥有1个粉丝.
// 用户1是Alice他拥有2个粉丝.
// 用户6是Fran他拥有2个粉丝.
// 用户3是Charlie他拥有1个粉丝.
// 用户2是Bob他拥有2个粉丝.
// 用户5是Ed他拥有0个粉丝.
}
}
```
<br/>
# 3. 案例二:谁是网络红人
(1)案例数据格式
```txt
((被跟随者), (跟随者))
((User47,86566510),(User83,15647839))
((User47,86566510),(User42,197134784))
((User89,74286565),(User49,19315174))
((User16,22679419),(User69,45705189))
```
(2)案例要求
创建图并计算每个用户的粉丝数量,找出谁才是网络红色。
(3)案例代码
```scala
import org.apache.spark.SparkContext
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import scala.util.matching.Regex
object InternetCelebrityGraphx {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getName)
.getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
// 匹配((User47,86566510),(User83,15647839))的正则表达式
val pattern: Regex = """\(\((User\d+,\d+)\),\((User\d+,\d+)\)\)""".r
// 加载数据文件,分割出(用户名, 用户Id)
val twitters: RDD[(Array[String], Array[String])] = sc.textFile("file:///E:\\hadoop\\input\\twitter_graph_data.txt")
.map(line => line match {
case pattern(followee, follower) => (Some(followee), Some(follower))
case _ => (None, None)
// 将None值过滤
}).filter(x => x._1 != None && x._2 != None)
// 将(User47,86566510)分割出Array(用户名, Id)
.map(x => (x._1.get.split(","), x._2.get.split(",")))
twitters.toDF.show(3)
// +------------------+-------------------+
// | _1| _2|
// +------------------+-------------------+
// |[User47, 86566510]| [User83, 15647839]|
// |[User47, 86566510]|[User42, 197134784]|
// |[User89, 74286565]| [User49, 19315174]|
// +------------------+-------------------+
// 构建顶点RDD
val verts: RDD[(Long, String)] = twitters.flatMap(x => Array((x._1(1).toLong, x._1(0)), (x._2(1).toLong, x._2(0)))).distinct()
verts.toDF.show(3)
// +--------+------+
// | _1| _2|
// +--------+------+
// |38521400|User85|
// |14676022| User0|
// |24741685|User87|
// +--------+------+
// 构建边RDD
val edges: RDD[Edge[String]] = twitters.map(x => Edge(x._2(1).toLong, x._1(1).toLong, "follow"))
// 构建图有可能会出现一种情况, 在边集合中出现的点在点集合中不存在,所以提供一个默认值 ""
val graph: Graph[String, String] = Graph(verts, edges, "")
// 谁是网络红人,就看哪个顶点的入口多,按照降序排序
graph.inDegrees.repartition(1).sortBy(x => x._2, false).toDF.show(5)
// +---------+---+
// | _1| _2|
// +---------+---+
// | 36851222| 56|
// |123004655| 56|
// | 59804598| 54|
// | 63644892| 46|
// | 14444530| 42|
// +---------+---+
}
}
```
- Hadoop
- hadoop是什么?
- Hadoop组成
- hadoop官网
- hadoop安装
- hadoop配置
- 本地运行模式配置
- 伪分布运行模式配置
- 完全分布运行模式配置
- HDFS分布式文件系统
- HDFS架构
- HDFS设计思想
- HDFS组成架构
- HDFS文件块大小
- HDFS优缺点
- HDFS Shell操作
- HDFS JavaAPI
- 基本使用
- HDFS的I/O 流操作
- 在SpringBoot项目中的API
- HDFS读写流程
- HDFS写流程
- HDFS读流程
- NN和SNN关系
- NN和SNN工作机制
- Fsimage和 Edits解析
- checkpoint时间设置
- NameNode故障处理
- 集群安全模式
- DataNode工作机制
- 支持的文件格式
- MapReduce分布式计算模型
- MapReduce是什么?
- MapReduce设计思想
- MapReduce优缺点
- MapReduce基本使用
- MapReduce编程规范
- WordCount案例
- MapReduce任务进程
- Hadoop序列化对象
- 为什么要序列化
- 常用数据序列化类型
- 自定义序列化对象
- MapReduce框架原理
- MapReduce工作流程
- MapReduce核心类
- MapTask工作机制
- Shuffle机制
- Partition分区
- Combiner合并
- ReduceTask工作机制
- OutputFormat
- 使用MapReduce实现SQL Join操作
- Reduce join
- Reduce join 代码实现
- Map join
- Map join 案例实操
- MapReduce 开发总结
- Hadoop 优化
- MapReduce 优化需要考虑的点
- MapReduce 优化方法
- 分布式资源调度框架 Yarn
- Yarn 基本架构
- ResourceManager(RM)
- NodeManager(NM)
- ApplicationMaster
- Container
- 作业提交全过程
- JobHistoryServer 使用
- 资源调度器
- 先进先出调度器(FIFO)
- 容量调度器(Capacity Scheduler)
- 公平调度器(Fair Scheduler)
- Yarn 常用命令
- Zookeeper
- zookeeper是什么?
- zookeeper完全分布式搭建
- Zookeeper特点
- Zookeeper数据结构
- Zookeeper 内部原理
- 选举机制
- stat 信息中字段解释
- 选择机制中的概念
- 选举消息内容
- 监听器原理
- Hadoop 高可用集群搭建
- Zookeeper 应用
- Zookeeper Shell操作
- Zookeeper Java应用
- Hive
- Hive是什么?
- Hive的优缺点
- Hive架构
- Hive元数据存储模式
- 内嵌模式
- 本地模式
- 远程模式
- Hive环境搭建
- 伪分布式环境搭建
- Hive命令工具
- 命令行模式
- 交互模式
- Hive数据类型
- Hive数据结构
- 参数配置方式
- Hive数据库
- 数据库存储位置
- 数据库操作
- 表的创建
- 建表基本语法
- 内部表
- 外部表
- 临时表
- 建表高阶语句
- 表的删除与修改
- 分区表
- 静态分区
- 动态分区
- 分桶表
- 创建分桶表
- 分桶抽样
- Hive视图
- 视图的创建
- 侧视图Lateral View
- Hive数据导入导出
- 导入数据
- 导出数据
- 查询表数据量
- Hive事务
- 事务是什么?
- Hive事务的局限性和特点
- Hive事务的开启和设置
- Hive PLSQL
- Hive高阶查询
- 查询基本语法
- 基本查询
- distinct去重
- where语句
- 列正则表达式
- 虚拟列
- CTE查询
- 嵌套查询
- join语句
- 内连接
- 左连接
- 右连接
- 全连接
- 多表连接
- 笛卡尔积
- left semi join
- group by分组
- having刷选
- union与union all
- 排序
- order by
- sort by
- distribute by
- cluster by
- 聚合运算
- 基本聚合
- 高级聚合
- 窗口函数
- 序列窗口函数
- 聚合窗口函数
- 分析窗口函数
- 窗口函数练习
- 窗口子句
- Hive函数
- Hive函数分类
- 字符串函数
- 类型转换函数
- 数学函数
- 日期函数
- 集合函数
- 条件函数
- 聚合函数
- 表生成函数
- 自定义Hive函数
- 自定义函数分类
- 自定义Hive函数流程
- 添加JAR包的方式
- 自定义临时函数
- 自定义永久函数
- Hive优化
- Hive性能调优工具
- EXPLAIN
- ANALYZE
- Fetch抓取
- 本地模式
- 表的优化
- 小表 join 大表
- 大表 join 大表
- 开启Map Join
- group by
- count(distinct)
- 笛卡尔积
- 行列过滤
- 动态分区调整
- 分区分桶表
- 数据倾斜
- 数据倾斜原因
- 调整Map数
- 调整Reduce数
- 产生数据倾斜的场景
- 并行执行
- 严格模式
- JVM重用
- 推测执行
- 启用CBO
- 启动矢量化
- 使用Tez引擎
- 压缩算法和文件格式
- 文件格式
- 压缩算法
- Zeppelin
- Zeppelin是什么?
- Zeppelin安装
- 配置Hive解释器
- Hbase
- Hbase是什么?
- Hbase环境搭建
- Hbase分布式环境搭建
- Hbase伪分布式环境搭建
- Hbase架构
- Hbase架构组件
- Hbase数据存储结构
- Hbase原理
- Hbase Shell
- 基本操作
- 表操作
- namespace
- Hbase Java Api
- Phoenix集成Hbase
- Phoenix是什么?
- 安装Phoenix
- Phoenix数据类型
- Phoenix Shell
- HBase与Hive集成
- HBase与Hive的对比
- HBase与Hive集成使用
- Hbase与Hive集成原理
- HBase优化
- RowKey设计
- 内存优化
- 基础优化
- Hbase管理
- 权限管理
- Region管理
- Region的自动拆分
- Region的预拆分
- 到底采用哪种拆分策略?
- Region的合并
- HFile的合并
- 为什么要有HFile的合并
- HFile合并方式
- Compaction执行时间
- Compaction相关控制参数
- 演示示例
- Sqoop
- Sqoop是什么?
- Sqoop环境搭建
- RDBMS导入到HDFS
- RDBMS导入到Hive
- RDBMS导入到Hbase
- HDFS导出到RDBMS
- 使用sqoop脚本
- Sqoop常用命令
- Hadoop数据模型
- TextFile
- SequenceFile
- Avro
- Parquet
- RC&ORC
- 文件存储格式比较
- Spark
- Spark是什么?
- Spark优势
- Spark与MapReduce比较
- Spark技术栈
- Spark安装
- Spark Shell
- Spark架构
- Spark编程入口
- 编程入口API
- SparkContext
- SparkSession
- Spark的maven依赖
- Spark RDD编程
- Spark核心数据结构-RDD
- RDD 概念
- RDD 特性
- RDD编程
- RDD编程流程
- pom依赖
- 创建算子
- 转换算子
- 动作算子
- 持久化算子
- RDD 与闭包
- csv/json数据源
- Spark分布式计算原理
- RDD依赖
- RDD转换
- RDD依赖
- DAG工作原理
- Spark Shuffle原理
- Shuffle的作用
- ShuffleManager组件
- Shuffle实践
- RDD持久化
- 缓存机制
- 检查点
- 检查点与缓存的区别
- RDD共享变量
- 广播变量
- 累计器
- RDD分区设计
- 数据倾斜
- 数据倾斜的根本原因
- 定位导致的数据倾斜
- 常见数据倾斜解决方案
- Spark SQL
- SQL on Hadoop
- Spark SQL是什么
- Spark SQL特点
- Spark SQL架构
- Spark SQL运行原理
- Spark SQL编程
- Spark SQL编程入口
- 创建Dataset
- Dataset是什么
- SparkSession创建Dataset
- 样例类创建Dataset
- 创建DataFrame
- DataFrame是什么
- 结构化数据文件创建DataFrame
- RDD创建DataFrame
- Hive表创建DataFrame
- JDBC创建DataFrame
- SparkSession创建
- RDD、DataFrame、Dataset
- 三者对比
- 三者相互转换
- RDD转换为DataFrame
- DataFrame转换为RDD
- DataFrame API
- DataFrame API分类
- Action 操作
- 基础 Dataset 函数
- 强类型转换
- 弱类型转换
- Spark SQL外部数据源
- Parquet文件
- Hive表
- RDBMS表
- JSON/CSV
- Spark SQL函数
- Spark SQL内置函数
- 自定SparkSQL函数
- Spark SQL CLI
- Spark SQL性能优化
- Spark GraphX图形数据分析
- 为什么需要图计算
- 图的概念
- 图的术语
- 图的经典表示法
- Spark Graphix简介
- Graphx核心抽象
- Graphx Scala API
- 核心组件
- 属性图应用示例1
- 属性图应用示例2
- 查看图信息
- 图的算子
- 连通分量
- PageRank算法
- Pregel分布式计算框架
- Flume日志收集
- Flume是什么?
- Flume官方文档
- Flume架构
- Flume安装
- Flume使用过程
- Flume组件
- Flume工作流程
- Flume事务
- Source、Channel、Sink文档
- Source文档
- Channel文档
- Sink文档
- Flume拦截器
- Flume拦截器概念
- 配置拦截器
- 自定义拦截器
- Flume可靠性保证
- 故障转移
- 负载均衡
- 多层代理
- 多路复用
- Kafka
- 消息中间件MQ
- Kafka是什么?
- Kafka安装
- Kafka本地单机部署
- Kafka基本命令使用
- Topic的生产与消费
- 基本命令
- 查看kafka目录
- Kafka架构
- Kafka Topic
- Kafka Producer
- Kafka Consumer
- Kafka Partition
- Kafka Message
- Kafka Broker
- 存储策略
- ZooKeeper在Kafka中的作用
- 副本同步
- 容灾
- 高吞吐
- Leader均衡机制
- Kafka Scala API
- Producer API
- Consumer API
- Kafka优化
- 消费者参数优化
- 生产者参数优化
- Spark Streaming
- 什么是流?
- 批处理和流处理
- Spark Streaming简介
- 流数据处理架构
- 内部工作流程
- StreamingContext组件
- SparkStreaming的编程入口
- WordCount案例
- DStream
- DStream是什么?
- Input DStream与Receivers接收器
- DStream API
- 转换操作
- 输出操作
- 数据源
- 数据源分类
- Socket数据源
- 统计HDFS文件的词频
- 处理状态数据
- SparkStreaming整合SparkSQL
- SparkStreaming整合Flume
- SparkStreaming整合Kafka
- 自定义数据源
- Spark Streaming优化策略
- 优化运行时间
- 优化内存使用
- 数据仓库
- 数据仓库是什么?
- 数据仓库的意义
- 数据仓库和数据库的区别
- OLTP和OLAP的区别
- OLTP的特点
- OLAP的特点
- OLTP与OLAP对比
- 数据仓库架构
- Inmon架构
- Kimball架构
- 混合型架构
- 数据仓库的解决方案
- 数据ETL
- 数据仓库建模流程
- 维度模型
- 星型模式
- 雪花模型
- 星座模型
- 数据ETL处理
- 数仓分层术语
- 数据抽取方式
- CDC抽取方案
- 数据转换
- 常见的ETL工具