
:-: 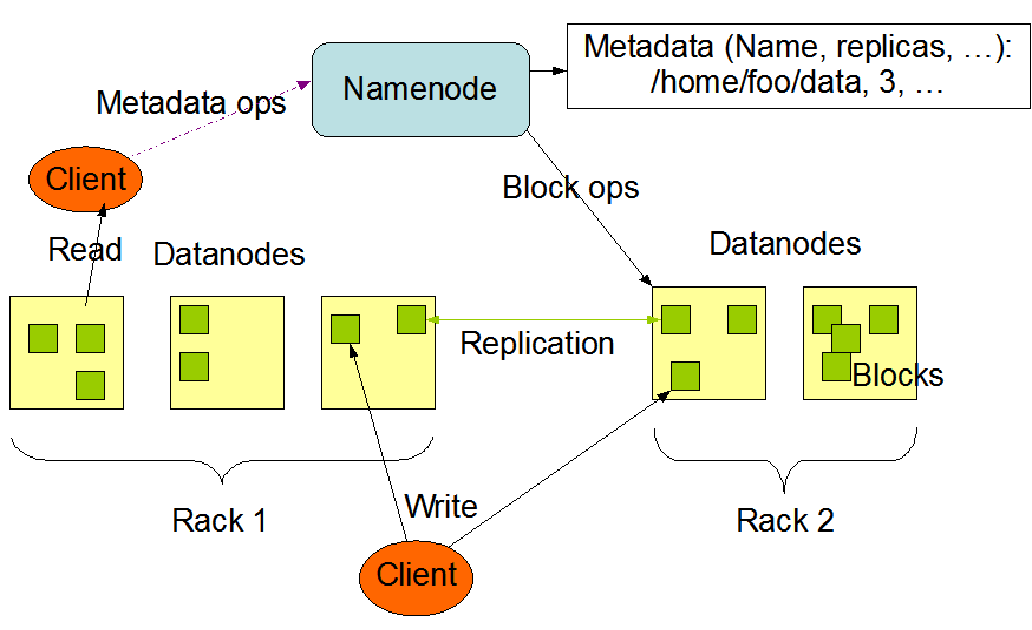
hdfs组成架构
架构主要由四个部分组成,分别为 HDFS Client、NameNode、DataNode 和Secondary NameNode。
<br/>
结合前面安装环境启动的进程,HDSF 启动的时候有 NameNode、DataNode 和 Secondary NameNode进程。
<br/>
**1. Client**:就是客户端,自己编写的代码+Hadoop API。其主要功能:
(1)进行文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block,然后进行存储。
(2)当我们要查询一个文件时,与 NameNode 交互,获取文件的位置信息。
(3)与 DataNode 交互,读取或者写入数据。
(4)Client 提供一些命令来管理 HDFS,比如启动或者关闭 HDFS。
(5)Client 可以通过一些命令来访问 HDFS。
<br/>
**2. NameNode**:就是 Master,它是一个主管、管理者。也叫 HDFS 的元数据节点。集群中只能有一个活动的 NameNode 对外提供服务。
(1)管理 HDFS 的名称空间(文件目录树);HDFS 很方便的一点就是对于用户来说很友好,用户不考虑细节的话,看到的目录结构和我们使用 Window 和Linux 文件系统很像。
(2)管理数据块(Block)映射信息及副本信息;一个文件对应的块的名字以及块被存储在哪里,以及每一个文件备份多少都是由 NameNode 来管理。
(3)处理客户端读写请求。
<br/>
**3. DataNode**:就是 Slave。实际存储数据块的节点,根据 NameNode 下达的命令,DataNode 执行实际的操作。
(1)存储实际的数据块。
(2)根据NameNode的命令执行数据块的读/写操作。
<br/>
**4. Secondary NameNode**:并非 NameNode 的热备。当 NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。它的功能如下:
(1)辅助 NameNode,分担其工作量。
(2)定期合并 Fsimage 和 Edits,并推送给 NameNode。
(3)在紧急情况下,可辅助恢复 NameNode。
Secondary NameNode 的工作与 HDFS 设计是相关的,主要针对元数据设计的。它维护了两种文件 **Fsimage** 和 **Edits**。
<br/>
Fsimage 镜像文件,是元数据在某个时间段的快照,Edits 记录了生成快照之后的一系列操作。<br/>
HDFS 在最初格式化启动时,创建 Edits 和 Fsimage 文件,并在内存中维护一版元数据信息,这时候,Fsimage 和内存中的元数据信息是相同的。后续每一次客户端操作时,会先记录客户端执行的操作到 Edits 文件中,然后再更新内存中对应的目录树结构,比如用户删除一个文件,会先在 Edits 文件中记录一个 delete 操作,然后在内存中真正删除文件。<br/>
也就是说,内存中的元数据信息是完整的。前面生成的快照 Fsimage 只是元数据的一部分,执行完 Edits 文件中相关操作才能与内存中元数据相同。<br/>
为什么要这么设计呢?
首先,为什么不直接更新Fsimage,而是要新添加Edits文件。这里就需要明确Fsimage里面存的是元数据目录树信息,其实是一个内存对象序列化后的内容。要更新这个文件,首先得反序列化对象加载到内存中,在实际工作,这个文件很大,序列化和反序列化过程会很繁重,速度会很慢。而 Edits 文件只需要 append操作记录即可。这样既保证了元数据不会丢失,也提高了性能。<br/>
SecondaryNameNode 具体干什么事情?
当 HDFS 运行一段时间后,需要重启动时,<ins>需要将Fsimage加载到内存中,并把Eidts文件中的操作执行一遍,才是完整的元数据信息</ins>。假如操作记录比较频繁或者长时间没有重启过,Edits 文件会很大。重启的时候合并Fsimage+Edits文件的操作也是很耗时的,增加了启动时间。SecondaryNameNode就是解决这种问题的,它是一个独立的进程,<ins>定期(满足一定条件)会将 Fsimage+Edits 合并成一个新的 Fsimage,减少 HDFS 重启时间</ins>。
- Hadoop
- hadoop是什么?
- Hadoop组成
- hadoop官网
- hadoop安装
- hadoop配置
- 本地运行模式配置
- 伪分布运行模式配置
- 完全分布运行模式配置
- HDFS分布式文件系统
- HDFS架构
- HDFS设计思想
- HDFS组成架构
- HDFS文件块大小
- HDFS优缺点
- HDFS Shell操作
- HDFS JavaAPI
- 基本使用
- HDFS的I/O 流操作
- 在SpringBoot项目中的API
- HDFS读写流程
- HDFS写流程
- HDFS读流程
- NN和SNN关系
- NN和SNN工作机制
- Fsimage和 Edits解析
- checkpoint时间设置
- NameNode故障处理
- 集群安全模式
- DataNode工作机制
- 支持的文件格式
- MapReduce分布式计算模型
- MapReduce是什么?
- MapReduce设计思想
- MapReduce优缺点
- MapReduce基本使用
- MapReduce编程规范
- WordCount案例
- MapReduce任务进程
- Hadoop序列化对象
- 为什么要序列化
- 常用数据序列化类型
- 自定义序列化对象
- MapReduce框架原理
- MapReduce工作流程
- MapReduce核心类
- MapTask工作机制
- Shuffle机制
- Partition分区
- Combiner合并
- ReduceTask工作机制
- OutputFormat
- 使用MapReduce实现SQL Join操作
- Reduce join
- Reduce join 代码实现
- Map join
- Map join 案例实操
- MapReduce 开发总结
- Hadoop 优化
- MapReduce 优化需要考虑的点
- MapReduce 优化方法
- 分布式资源调度框架 Yarn
- Yarn 基本架构
- ResourceManager(RM)
- NodeManager(NM)
- ApplicationMaster
- Container
- 作业提交全过程
- JobHistoryServer 使用
- 资源调度器
- 先进先出调度器(FIFO)
- 容量调度器(Capacity Scheduler)
- 公平调度器(Fair Scheduler)
- Yarn 常用命令
- Zookeeper
- zookeeper是什么?
- zookeeper完全分布式搭建
- Zookeeper特点
- Zookeeper数据结构
- Zookeeper 内部原理
- 选举机制
- stat 信息中字段解释
- 选择机制中的概念
- 选举消息内容
- 监听器原理
- Hadoop 高可用集群搭建
- Zookeeper 应用
- Zookeeper Shell操作
- Zookeeper Java应用
- Hive
- Hive是什么?
- Hive的优缺点
- Hive架构
- Hive元数据存储模式
- 内嵌模式
- 本地模式
- 远程模式
- Hive环境搭建
- 伪分布式环境搭建
- Hive命令工具
- 命令行模式
- 交互模式
- Hive数据类型
- Hive数据结构
- 参数配置方式
- Hive数据库
- 数据库存储位置
- 数据库操作
- 表的创建
- 建表基本语法
- 内部表
- 外部表
- 临时表
- 建表高阶语句
- 表的删除与修改
- 分区表
- 静态分区
- 动态分区
- 分桶表
- 创建分桶表
- 分桶抽样
- Hive视图
- 视图的创建
- 侧视图Lateral View
- Hive数据导入导出
- 导入数据
- 导出数据
- 查询表数据量
- Hive事务
- 事务是什么?
- Hive事务的局限性和特点
- Hive事务的开启和设置
- Hive PLSQL
- Hive高阶查询
- 查询基本语法
- 基本查询
- distinct去重
- where语句
- 列正则表达式
- 虚拟列
- CTE查询
- 嵌套查询
- join语句
- 内连接
- 左连接
- 右连接
- 全连接
- 多表连接
- 笛卡尔积
- left semi join
- group by分组
- having刷选
- union与union all
- 排序
- order by
- sort by
- distribute by
- cluster by
- 聚合运算
- 基本聚合
- 高级聚合
- 窗口函数
- 序列窗口函数
- 聚合窗口函数
- 分析窗口函数
- 窗口函数练习
- 窗口子句
- Hive函数
- Hive函数分类
- 字符串函数
- 类型转换函数
- 数学函数
- 日期函数
- 集合函数
- 条件函数
- 聚合函数
- 表生成函数
- 自定义Hive函数
- 自定义函数分类
- 自定义Hive函数流程
- 添加JAR包的方式
- 自定义临时函数
- 自定义永久函数
- Hive优化
- Hive性能调优工具
- EXPLAIN
- ANALYZE
- Fetch抓取
- 本地模式
- 表的优化
- 小表 join 大表
- 大表 join 大表
- 开启Map Join
- group by
- count(distinct)
- 笛卡尔积
- 行列过滤
- 动态分区调整
- 分区分桶表
- 数据倾斜
- 数据倾斜原因
- 调整Map数
- 调整Reduce数
- 产生数据倾斜的场景
- 并行执行
- 严格模式
- JVM重用
- 推测执行
- 启用CBO
- 启动矢量化
- 使用Tez引擎
- 压缩算法和文件格式
- 文件格式
- 压缩算法
- Zeppelin
- Zeppelin是什么?
- Zeppelin安装
- 配置Hive解释器
- Hbase
- Hbase是什么?
- Hbase环境搭建
- Hbase分布式环境搭建
- Hbase伪分布式环境搭建
- Hbase架构
- Hbase架构组件
- Hbase数据存储结构
- Hbase原理
- Hbase Shell
- 基本操作
- 表操作
- namespace
- Hbase Java Api
- Phoenix集成Hbase
- Phoenix是什么?
- 安装Phoenix
- Phoenix数据类型
- Phoenix Shell
- HBase与Hive集成
- HBase与Hive的对比
- HBase与Hive集成使用
- Hbase与Hive集成原理
- HBase优化
- RowKey设计
- 内存优化
- 基础优化
- Hbase管理
- 权限管理
- Region管理
- Region的自动拆分
- Region的预拆分
- 到底采用哪种拆分策略?
- Region的合并
- HFile的合并
- 为什么要有HFile的合并
- HFile合并方式
- Compaction执行时间
- Compaction相关控制参数
- 演示示例
- Sqoop
- Sqoop是什么?
- Sqoop环境搭建
- RDBMS导入到HDFS
- RDBMS导入到Hive
- RDBMS导入到Hbase
- HDFS导出到RDBMS
- 使用sqoop脚本
- Sqoop常用命令
- Hadoop数据模型
- TextFile
- SequenceFile
- Avro
- Parquet
- RC&ORC
- 文件存储格式比较
- Spark
- Spark是什么?
- Spark优势
- Spark与MapReduce比较
- Spark技术栈
- Spark安装
- Spark Shell
- Spark架构
- Spark编程入口
- 编程入口API
- SparkContext
- SparkSession
- Spark的maven依赖
- Spark RDD编程
- Spark核心数据结构-RDD
- RDD 概念
- RDD 特性
- RDD编程
- RDD编程流程
- pom依赖
- 创建算子
- 转换算子
- 动作算子
- 持久化算子
- RDD 与闭包
- csv/json数据源
- Spark分布式计算原理
- RDD依赖
- RDD转换
- RDD依赖
- DAG工作原理
- Spark Shuffle原理
- Shuffle的作用
- ShuffleManager组件
- Shuffle实践
- RDD持久化
- 缓存机制
- 检查点
- 检查点与缓存的区别
- RDD共享变量
- 广播变量
- 累计器
- RDD分区设计
- 数据倾斜
- 数据倾斜的根本原因
- 定位导致的数据倾斜
- 常见数据倾斜解决方案
- Spark SQL
- SQL on Hadoop
- Spark SQL是什么
- Spark SQL特点
- Spark SQL架构
- Spark SQL运行原理
- Spark SQL编程
- Spark SQL编程入口
- 创建Dataset
- Dataset是什么
- SparkSession创建Dataset
- 样例类创建Dataset
- 创建DataFrame
- DataFrame是什么
- 结构化数据文件创建DataFrame
- RDD创建DataFrame
- Hive表创建DataFrame
- JDBC创建DataFrame
- SparkSession创建
- RDD、DataFrame、Dataset
- 三者对比
- 三者相互转换
- RDD转换为DataFrame
- DataFrame转换为RDD
- DataFrame API
- DataFrame API分类
- Action 操作
- 基础 Dataset 函数
- 强类型转换
- 弱类型转换
- Spark SQL外部数据源
- Parquet文件
- Hive表
- RDBMS表
- JSON/CSV
- Spark SQL函数
- Spark SQL内置函数
- 自定SparkSQL函数
- Spark SQL CLI
- Spark SQL性能优化
- Spark GraphX图形数据分析
- 为什么需要图计算
- 图的概念
- 图的术语
- 图的经典表示法
- Spark Graphix简介
- Graphx核心抽象
- Graphx Scala API
- 核心组件
- 属性图应用示例1
- 属性图应用示例2
- 查看图信息
- 图的算子
- 连通分量
- PageRank算法
- Pregel分布式计算框架
- Flume日志收集
- Flume是什么?
- Flume官方文档
- Flume架构
- Flume安装
- Flume使用过程
- Flume组件
- Flume工作流程
- Flume事务
- Source、Channel、Sink文档
- Source文档
- Channel文档
- Sink文档
- Flume拦截器
- Flume拦截器概念
- 配置拦截器
- 自定义拦截器
- Flume可靠性保证
- 故障转移
- 负载均衡
- 多层代理
- 多路复用
- Kafka
- 消息中间件MQ
- Kafka是什么?
- Kafka安装
- Kafka本地单机部署
- Kafka基本命令使用
- Topic的生产与消费
- 基本命令
- 查看kafka目录
- Kafka架构
- Kafka Topic
- Kafka Producer
- Kafka Consumer
- Kafka Partition
- Kafka Message
- Kafka Broker
- 存储策略
- ZooKeeper在Kafka中的作用
- 副本同步
- 容灾
- 高吞吐
- Leader均衡机制
- Kafka Scala API
- Producer API
- Consumer API
- Kafka优化
- 消费者参数优化
- 生产者参数优化
- Spark Streaming
- 什么是流?
- 批处理和流处理
- Spark Streaming简介
- 流数据处理架构
- 内部工作流程
- StreamingContext组件
- SparkStreaming的编程入口
- WordCount案例
- DStream
- DStream是什么?
- Input DStream与Receivers接收器
- DStream API
- 转换操作
- 输出操作
- 数据源
- 数据源分类
- Socket数据源
- 统计HDFS文件的词频
- 处理状态数据
- SparkStreaming整合SparkSQL
- SparkStreaming整合Flume
- SparkStreaming整合Kafka
- 自定义数据源
- Spark Streaming优化策略
- 优化运行时间
- 优化内存使用
- 数据仓库
- 数据仓库是什么?
- 数据仓库的意义
- 数据仓库和数据库的区别
- OLTP和OLAP的区别
- OLTP的特点
- OLAP的特点
- OLTP与OLAP对比
- 数据仓库架构
- Inmon架构
- Kimball架构
- 混合型架构
- 数据仓库的解决方案
- 数据ETL
- 数据仓库建模流程
- 维度模型
- 星型模式
- 雪花模型
- 星座模型
- 数据ETL处理
- 数仓分层术语
- 数据抽取方式
- CDC抽取方案
- 数据转换
- 常见的ETL工具