
# TensorFlow 如何工作
起初,TensorFlow 中的计算可能看起来不必要地复杂化。但有一个原因:由于 TensorFlow 如何处理计算,开发更复杂的算法相对容易。该秘籍将指导我们完成 TensorFlow 算法的伪代码。
## 做好准备
目前,TensorFlow 在 Linux,macOS 和 Windows 上受支持。本书的代码已经在 Linux 系统上创建和运行,但也应该在任何其他系统上运行。该书的代码可在 GitHub 的 [https://github.com/nfmcclure/tensorflow_cookbook](https://github.com/nfmcclure/tensorflow_cookbook) 以及 Packt 仓库中找到: [https://github.com/PacktPublishing/TensorFlow-Machine -Learning-Cookbook-Second-Edition](https://github.com/PacktPublishing/TensorFlow-Machine-Learning-Cookbook-Second-Edition) 。
在本书中,我们只关注 TensorFlow 的 Python 库包装器,尽管 TensorFlow 的大多数原始核心代码都是用 C ++编写的。本书将使用 Python 3.6+( [https://www.python.org](https://www.python.org) )和 TensorFlow 1.10.0+( [https://www.tensorflow.org](https://www.tensorflow.org) )。虽然 TensorFlow 可以在 CPU 上运行,但是如果在 GPU 上处理,大多数算法运行得更快,并且在具有 Nvidia Compute Capability v4.0 +(推荐 v5.1)的显卡上支持。
TensorFlow 的流行 GPU 是 Nvidia Tesla 架构和具有至少 4 GB 视频 RAM 的 Pascal 架构。要在 GPU 上运行,您还需要下载并安装 Nvidia CUDA 工具包以及版本 5.x +( [https://developer.nvidia.com/cuda-downloads](https://developer.nvidia.com/cuda-downloads) )。
本章中的一些秘籍将依赖于当前安装的 SciPy,NumPy 和 scikit-learn Python 包。这些随附的软件包也包含在 Anaconda 软件包中[ [https://www.continuum.io/downloads](https://www.continuum.io/downloads) )。
## 操作步骤
在这里,我们将介绍 TensorFlow 算法的一般流程。大多数秘籍将遵循以下大纲:
1. 导入或生成数据集:我们所有的机器学习算法都依赖于数据集。在本书中,我们将生成数据或使用外部数据集源。有时,最好依赖生成的数据,因为我们只想知道预期的结果。大多数情况下,我们将访问给定秘籍的公共数据集。有关访问这些数据集的详细信息,请参见本章第 8 节的其他资源。
2. 转换和正则化数据:通常,输入数据集不会出现在图片中。 TensorFlow 期望我们需要转换 TensorFlow,以便它们获得可接受的形状。数据通常不在我们的算法所期望的正确维度或类型中。在我们使用之前,我们必须转换数据。大多数算法也期望归一化数据,我们也会在这里看一下。 TensorFlow 具有内置函数,可以为您正则化数据,如下所示:
```py
import tensorflow as tf
data = tf.nn.batch_norm_with_global_normalization(...)
```
1. 将数据集划分为训练集,测试集和验证集:我们通常希望在我们训练过的不同集上测试我们的算法。此外,许多算法需要超参数调整,因此我们留出一个验证集来确定最佳的超参数集。
2. 设置算法参数(超参数):我们的算法通常有一组参数,我们在整个过程中保持不变。例如,这可以是我们选择的迭代次数,学习率或其他固定参数。将这些一起初始化是一种良好的做法,以便读者或用户可以轻松找到它们,如下所示:
```py
learning_rate = 0.01
batch_size = 100
iterations = 1000
```
1. 初始化变量和占位符:TensorFlow 依赖于知道它能够和不能修改的内容。 TensorFlow 将在优化期间修改/调整变量(模型权重/偏差)以最小化损失函数。为此,我们通过占位符提供数据。我们需要初始化变量和占位符的大小和类型,以便 TensorFlow 知道会发生什么。 TensorFlow 还需要知道期望的数据类型。对于本书的大部分内容,我们将使用`float32`。 TensorFlow 还提供`float64`和`float16`。请注意,用于精度的更多字节会导致算法速度变慢,但使用较少会导致精度降低。请参阅以下代码:
```py
a_var = tf.constant(42)
x_input = tf.placeholder(tf.float32, [None, input_size])
y_input = tf.placeholder(tf.float32, [None, num_classes])
```
1. 定义模型结构:在获得数据并初始化变量和占位符之后,我们必须定义模型。这是通过构建计算图来完成的。我们将在[第 2 章](../Text/10.html),TensorFlow 方法中更详细地讨论计算图 TensorFlow 秘籍中的运算中的计算图。此示例的模型将是线性模型(`y = mx + b`):
```py
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix)
```
1. 声明损失函数:定义模型后,我们必须能够评估输出。这是我们宣布损失函数的地方。损失函数非常重要,因为它告诉我们预测距实际值有多远。在[第 2 章](../Text/10.html),TensorFlow 方法中的实现反向传播秘籍中更详细地探讨了不同类型的损失函数。在这里,我们实现了 n 点的均方误差,即:
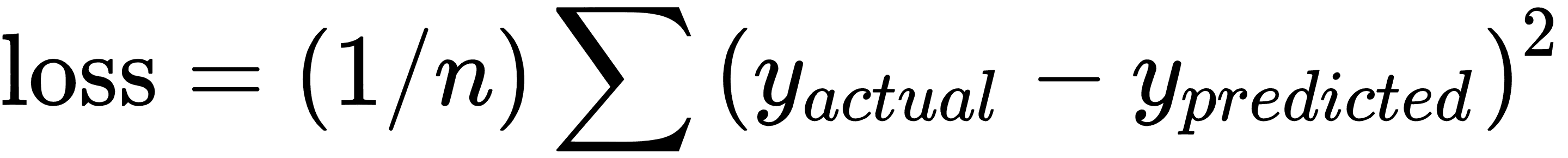
```py
loss = tf.reduce_mean(tf.square(y_actual - y_pred))
```
1. 初始化和训练模型:现在我们已经完成了所有工作,我们需要创建图实例,通过占位符输入数据,让 TensorFlow 更改变量以更好地预测我们的训练数据。这是初始化计算图的一种方法:
```py
with tf.Session(graph=graph) as session:
...
session.run(...)
...
Note that we can also initiate our graph with:
session = tf.Session(graph=graph)
session.run(...)
```
1. 评估模型:一旦我们构建并训练了模型,我们应该通过查看通过某些指定标准对新数据的处理程度来评估模型。我们对训练和测试装置进行评估,这些评估将使我们能够看到模型是否过拟合。我们将在后面的秘籍中解决这个问题。
2. 调整超参数:大多数情况下,我们希望根据模型的表现返回并更改一些超参数。然后,我们使用不同的超参数重复前面的步骤,并在验证集上评估模型。
3. 部署/预测新结果:了解如何对新数据和未见数据进行预测也很重要。一旦我们对他们进行了训练,我们就可以对所有模型进行此操作。
## 工作原理
在 TensorFlow 中,我们必须先设置数据,变量,占位符和模型,然后才能告诉程序训练和更改变量以改进预测。 TensorFlow 通过计算图完成此任务。这些计算图是没有递归的有向图,这允许计算并行性。为此,我们需要为 TensorFlow 创建一个最小化的损失函数。 TensorFlow 通过修改计算图中的变量来实现此目的。 TensorFlow 知道如何修改变量,因为它跟踪模型中的计算并自动计算变量梯度(如何更改每个变量)以最小化损失。因此,我们可以看到进行更改和尝试不同数据源是多么容易。
## 另见
有关 TensorFlow 的更多介绍和资源,请参阅官方文档和教程:
* 一个更好的起点是官方 Python API 文档: [https://www.tensorflow.org/api_docs/python/](https://www.tensorflow.org/api_docs/python/)
* 还有教程: [https://www.tensorflow.org/tutorials/](https://www.tensorflow.org/tutorials/)
* TensorFlow 教程,项目,演示文稿和代码仓库的非官方集合: [https://github.com/jtoy/awesome-tensorflow](https://github.com/jtoy/awesome-tensorflow)
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras