
# 理解线性回归中的损失函数
了解损失函数在算法收敛中的作用非常重要。在这里,我们将说明 L1 和 L2 损失函数如何影响线性回归中的收敛。
## 做好准备
我们将使用与先前秘籍中相同的虹膜数据集,但我们将更改损失函数和学习率以查看收敛如何变化。
## 操作步骤
我们按如下方式处理秘籍:
1. 程序的开始与上一个秘籍相同,直到我们达到我们的损失函数。我们加载必要的库,启动会话,加载数据,创建占位符,并定义我们的变量和模型。需要注意的一点是,我们正在提取学习率和模型迭代。我们这样做是因为我们希望显示快速更改这些参数的效果。使用以下代码:
```py
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn import datasets
sess = tf.Session()
iris = datasets.load_iris()
x_vals = np.array([x[3] for x in iris.data])
y_vals = np.array([y[0] for y in iris.data])
batch_size = 25
learning_rate = 0.1 # Will not converge with learning rate at 0.4
iterations = 50
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
A = tf.Variable(tf.random_normal(shape=[1,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
model_output = tf.add(tf.matmul(x_data, A), b)
```
1. 我们的损失函数将变为 L1 损失(`loss_l1`),如下所示:
```py
loss_l1 = tf.reduce_mean(tf.abs(y_target - model_output))
```
1. 现在,我们通过初始化变量,声明我们的优化器以及通过训练循环迭代数据来恢复。请注意,我们也在节省每一代的损失来衡量收敛。使用以下代码:
```py
init = tf.global_variables_initializer()
sess.run(init)
my_opt_l1 = tf.train.GradientDescentOptimizer(learning_rate)
train_step_l1 = my_opt_l1.minimize(loss_l1)
loss_vec_l1 = []
for i in range(iterations):
rand_index = np.random.choice(len(x_vals), size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step_l1, feed_dict={x_data: rand_x, y_target: rand_y})
temp_loss_l1 = sess.run(loss_l1, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec_l1.append(temp_loss_l1)
if (i+1)%25==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b)))
plt.plot(loss_vec_l1, 'k-', label='L1 Loss')
plt.plot(loss_vec_l2, 'r--', label='L2 Loss')
plt.title('L1 and L2 Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('L1 Loss')
plt.legend(loc='upper right')
plt.show()
```
## 工作原理
在选择损失函数时,我们还必须选择适合我们问题的相应学习率。在这里,我们将说明两种情况,一种是首选 L2,另一种是首选 L1。
如果我们的学习率很小,我们的收敛会花费更多时间。但是如果我们的学习速度太大,我们的算法就会遇到问题从不收敛。下面是当学习率为 0.05 时,虹膜线性回归问题的 L1 和 L2 损失的损失函数图:
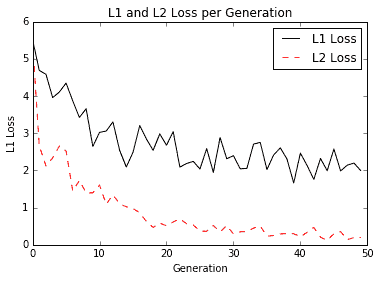
图 5:虹膜线性回归问题的学习率为 0.05 的 L1 和 L2 损失
学习率为 0.05 时,似乎 L2 损失是首选,因为它会收敛到较低的损失。下面是我们将学习率提高到 0.4 时的损失函数图:
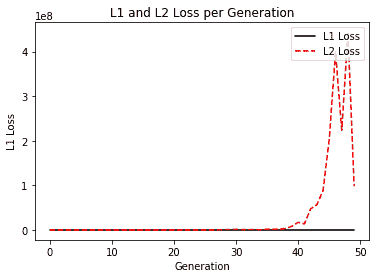
图 6:虹膜线性回归问题的 L1 和 L2 损失,学习率为 0.4;请注意,由于 y 轴的高比例,L1 损失不可见
在这里,我们可以看到高学习率可以在 L2 范数中超调,而 L1 范数收敛。
## 更多
为了理解正在发生的事情,我们应该看看大学习率和小学习率如何影响 L1 规范和 L2 规范。为了使这个可视化,我们查看两个规范的学习步骤的一维表示,如下所示:
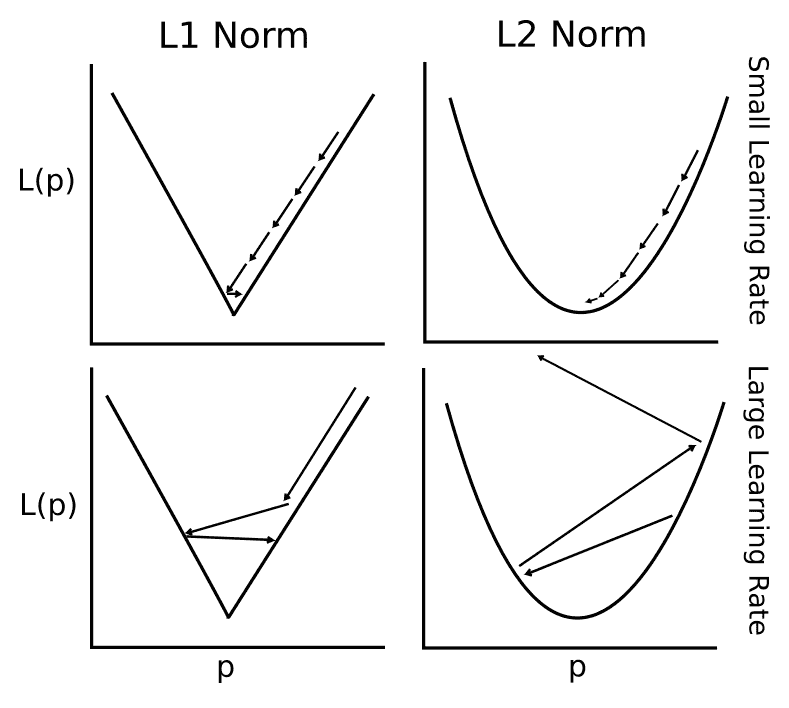
图 7:学习率越来越高的 L1 和 L2 规范会发生什么
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras