
# 使用 Skip-Gram 嵌入
在之前的秘籍中,我们在训练模型之前决定了我们的文本嵌入。使用神经网络,我们可以使嵌入值成为训练过程的一部分。我们将探索的第一个这样的方法叫做 Skip-Gram 嵌入。
## 做好准备
在此秘籍之前,我们没有考虑与创建单词嵌入相关的单词顺序。 2013 年初,Tomas Mikolov 和谷歌的其他研究人员撰写了一篇关于创建解决这个问题的单词嵌入的论文( [https://arxiv.org/abs/1301.3781](https://arxiv.org/abs/1301.3781) ),他们将他们的方法命名为 word2vec。
基本思想是创建捕获单词关系方面的单词嵌入。我们试图了解各种单词如何相互关联。这些嵌入可能如何表现的一些示例如下:
`king - man + woman = queen`
`India pale ale - hops + malt = stout`
如果我们只考虑它们之间的位置关系,我们可能会实现这样的数字表示。如果我们能够分析足够大的相关文档来源,我们可能会发现在我们的文本中,`king`,`man`和`queen`这两个词在彼此之间相互提及。如果我们也知道`man`和`woman`以不同的方式相关,那么我们可以得出结论,`man`是`king`,因为`woman`是`queen`,依此类推。
为了找到这样的嵌入,我们将使用一个神经网络来预测给定输入字的周围单词。我们可以轻松地切换它并尝试在给定一组周围单词的情况下预测目标单词,但我们将从前面的方法开始。两者都是 word2vec 过程的变体,但是从目标词预测周围词(上下文)的前述方法称为 Skip-Gram 模型。在下一个秘籍中,我们将实现另一个方法,从上下文预测目标词,这称为连续词袋方法(CBOW):
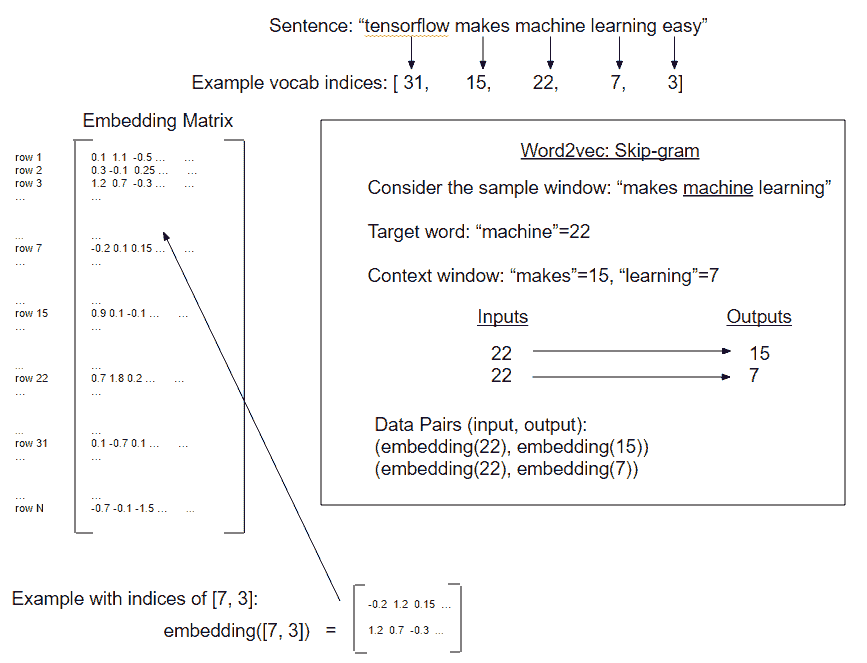
图 4:word2vec 的 Skip-Gram 实现的图示。 Skip-Gram 预测目标词的上下文窗口(每侧窗口大小为 1)。
对于这个秘籍,我们将在康奈尔大学的一组电影评论数据上实现 Skip-Gram 模型( [http://www.cs.cornell.edu/people/pabo/movie-review-data/](http://www.cs.cornell.edu/people/pabo/movie-review-data/) ])。 word2vec 的 CBOW 方法将在下一个秘籍中实现。
## 操作步骤
对于这个秘籍,我们将创建几个辅助函数。这些函数将加载数据,正则化文本,生成词汇表并生成数据批量。只有在这之后我们才开始训练我们的单词嵌入。为了清楚起见,我们不是预测任何目标变量,而是我们将拟合单词嵌入:
1. 首先,我们将加载必要的库并启动图会话:
```py
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import random
import os
import string
import requests
import collections
import io
import tarfile
import urllib.request
from nltk.corpus import stopwords
sess = tf.Session()
```
1. 然后我们声明一些模型参数。我们将一次查看 50 对单词嵌入(批量大小)。每个单词的嵌入大小将是一个长度为 200 的向量,我们只考虑 10,000 个最常用的单词(每隔一个单词将被归类为未知单词)。我们将训练 5 万代,并每 500 代打印一次。然后我们将声明一个我们将在 loss 函数中使用的`num_sampled`变量(我们将在后面解释),并且我们还声明了我们的 Skip-Gram 窗口大小。在这里,我们将窗口大小设置为 2,因此我们将查看目标每侧的周围两个单词。我们将通过名为`nltk`的 Python 包设置我们的停用词。我们还想要一种方法来检查我们的单词嵌入是如何执行的,因此我们将选择一些常见的电影评论单词并从每 2,000 次迭代中打印出最近的邻居单词:
```py
batch_size = 50
embedding_size = 200
vocabulary_size = 10000
generations = 50000
print_loss_every = 500
num_sampled = int(batch_size/2)
window_size = 2
stops = stopwords.words('english')
print_valid_every = 2000
valid_words = ['cliche', 'love', 'hate', 'silly', 'sad']
```
1. 接下来,我们将声明我们的数据加载函数,该函数会检查以确保在下载之前我们没有下载数据。否则,如果之前保存了数据,它将从磁盘加载数据。使用以下代码执行此操作:
```py
def load_movie_data():
save_folder_name = 'temp'
pos_file = os.path.join(save_folder_name, 'rt-polarity.pos')
neg_file = os.path.join(save_folder_name, 'rt-polarity.neg')
# Check if files are already downloaded
if os.path.exists(save_folder_name):
pos_data = []
with open(pos_file, 'r') as temp_pos_file:
for row in temp_pos_file:
pos_data.append(row)
neg_data = []
with open(neg_file, 'r') as temp_neg_file:
for row in temp_neg_file:
neg_data.append(row)
else: # If not downloaded, download and save
movie_data_url = 'http://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz'
stream_data = urllib.request.urlopen(movie_data_url)
tmp = io.BytesIO()
while True:
s = stream_data.read(16384)
if not s:
break
tmp.write(s)
stream_data.close()
tmp.seek(0)
tar_file = tarfile.open(fileobj=tmp, mode='r:gz')
pos = tar_file.extractfile('rt-polaritydata/rt-polarity.pos')
neg = tar_file.extractfile('rt-polaritydata/rt-polarity.neg')
# Save pos/neg reviews
pos_data = []
for line in pos:
pos_data.append(line.decode('ISO-8859-1').encode('ascii',errors='ignore').decode())
neg_data = []
for line in neg:
neg_data.append(line.decode('ISO-8859-1').encode('ascii',errors='ignore').decode())
tar_file.close()
# Write to file
if not os.path.exists(save_folder_name):
os.makedirs(save_folder_name)
# Save files
with open(pos_file, 'w') as pos_file_handler:
pos_file_handler.write(''.join(pos_data))
with open(neg_file, 'w') as neg_file_handler:
neg_file_handler.write(''.join(neg_data))
texts = pos_data + neg_data
target = [1]*len(pos_data) + [0]*len(neg_data)
return(texts, target)
texts, target = load_movie_data()
```
1. 接下来,我们将为文本创建正则化函数。此函数将输入字符串列表并使其为小写,删除标点,删除数字,删除额外的空格,并删除停用词。使用以下代码执行此操作:
```py
def normalize_text(texts, stops):
# Lower case
texts = [x.lower() for x in texts]
# Remove punctuation
texts = [''.join(c for c in x if c not in string.punctuation) for x in texts]
# Remove numbers
texts = [''.join(c for c in x if c not in '0123456789') for x in texts]
# Remove stopwords
texts = [' '.join([word for word in x.split() if word not in (stops)]) for x in texts]
# Trim extra whitespace
texts = [' '.join(x.split()) for x in texts]
return(texts)
texts = normalize_text(texts, stops)
```
1. 为了确保我们所有的电影评论都能提供信息,我们应该确保它们足够长,以包含重要的单词关系。我们会随意将其设置为三个或更多单词:
```py
target = [target[ix] for ix, x in enumerate(texts) if len(x.split()) > 2]
texts = [x for x in texts if len(x.split()) > 2]
```
1. 为了构建我们的词汇表,我们将创建一个函数来创建一个带有计数的单词字典。任何不常见的词都不会使我们的词汇量大小被截止,将被标记为`RARE`。使用以下代码执行此操作:
```py
def build_dictionary(sentences, vocabulary_size):
# Turn sentences (list of strings) into lists of words
split_sentences = [s.split() for s in sentences]
words = [x for sublist in split_sentences for x in sublist]
# Initialize list of [word, word_count] for each word, starting with unknown
count = [['RARE', -1]]
# Now add most frequent words, limited to the N-most frequent (N=vocabulary size)
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
# Now create the dictionary
word_dict = {}
# For each word, that we want in the dictionary, add it, then make it the value of the prior dictionary length
for word, word_count in count:
word_dict[word] = len(word_dict)
return(word_dict)
```
1. 我们需要一个函数将一个句子列表转换为单词索引列表,我们可以将它们传递给嵌入查找函数。使用以下代码执行此操作:
```py
def text_to_numbers(sentences, word_dict):
# Initialize the returned data
data = []
for sentence in sentences:
sentence_data = []
# For each word, either use selected index or rare word index
for word in sentence:
if word in word_dict:
word_ix = word_dict[word]
else:
word_ix = 0
sentence_data.append(word_ix)
data.append(sentence_data)
return data
```
1. 现在我们可以实际创建我们的字典并将我们的句子列表转换为单词索引列表:
```py
word_dictionary = build_dictionary(texts, vocabulary_size)
word_dictionary_rev = dict(zip(word_dictionary.values(), word_dictionary.keys()))
text_data = text_to_numbers(texts, word_dictionary)
```
1. 从前面的单词字典中,我们可以查找我们在步骤 2 中选择的验证字的索引。使用以下代码执行此操作:
```py
valid_examples = [word_dictionary[x] for x in valid_words]
```
1. 我们现在将创建一个将返回 Skip-Gram 批次的函数。我们想训练一对单词,其中一个单词是训练输入(来自我们窗口中心的目标单词),另一个单词是从窗口中选择的。例如,句子`the cat in the hat`可能导致(输入,输出)对,如下所示:(`the`,`in`),(`cat`,`in`),(`the`,`in` ),(`hat`,`in`)如果是目标词,我们每个方向的窗口大小为 2:
```py
def generate_batch_data(sentences, batch_size, window_size, method='skip_gram'):
# Fill up data batch
batch_data = []
label_data = []
while len(batch_data) < batch_size:
# select random sentence to start
rand_sentence = np.random.choice(sentences)
# Generate consecutive windows to look at
window_sequences = [rand_sentence[max((ix-window_size),0):(ix+window_size+1)] for ix, x in enumerate(rand_sentence)]
# Denote which element of each window is the center word of interest
label_indices = [ix if ix<window_size else window_size for ix,x in enumerate(window_sequences)]
# Pull out center word of interest for each window and create a tuple for each window
if method=='skip_gram':
batch_and_labels = [(x[y], x[:y] + x[(y+1):]) for x,y in zip(window_sequences, label_indices)]
# Make it in to a big list of tuples (target word, surrounding word)
tuple_data = [(x, y_) for x,y in batch_and_labels for y_ in y]
else:
raise ValueError('Method {} not implmented yet.'.format(method))
# extract batch and labels
batch, labels = [list(x) for x in zip(*tuple_data)]
batch_data.extend(batch[:batch_size])
label_data.extend(labels[:batch_size])
# Trim batch and label at the end
batch_data = batch_data[:batch_size]
label_data = label_data[:batch_size]
# Convert to numpy array
batch_data = np.array(batch_data)
label_data = np.transpose(np.array([label_data]))
return batch_data, label_data
```
1. 我们现在可以初始化嵌入矩阵,声明占位符,并初始化嵌入查找函数。使用以下代码执行此操作:
```py
embeddings = tf.Variable(tf.random_uniform([vocabulary_size,
embedding_size], -1.0, 1.0))
# Create data/target placeholders
x_inputs = tf.placeholder(tf.int32, shape=[batch_size])
y_target = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Lookup the word embedding:
embed = tf.nn.embedding_lookup(embeddings, x_inputs)
```
1. 损失函数应该是诸如`softmax`之类的东西,它计算预测错误单词类别时的损失。但由于我们的目标有 10,000 个不同的类别,因此非常稀疏。这种稀疏性导致关于模型的拟合或收敛的问题。为了解决这个问题,我们将使用称为噪声对比误差的损失函数。这种 NCE 损失函数通过预测单词类与随机噪声预测将我们的问题转化为二元预测。 `num_sampled`参数指定批量变成随机噪声的程度:
```py
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size,
embedding_size], stddev=1.0 / np.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
inputs=embed,
labels=y_target,
num_sampled=num_sampled,
num_classes=vocabulary_size))
```
1. 现在我们需要创建一种方法来查找附近的单词到我们的验证单词。我们将通过计算验证集和所有单词嵌入之间的余弦相似性来完成此操作,然后我们可以为每个验证字打印出最接近的单词集。使用以下代码执行此操作:
```py
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keepdims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
```
1. 我们现在声明我们的优化函数并初始化我们的模型变量:
```py
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
init = tf.global_variables_initializer()
sess.run(init)
```
1. 现在我们可以训练我们的嵌入并在训练期间打印损失和最接近我们验证集的单词。使用以下代码执行此操作:
```py
loss_vec = []
loss_x_vec = []
for i in range(generations):
batch_inputs, batch_labels = generate_batch_data(text_data, batch_size, window_size)
feed_dict = {x_inputs : batch_inputs, y_target : batch_labels}
# Run the train step
sess.run(optimizer, feed_dict=feed_dict)
# Return the loss
if (i+1) % print_loss_every == 0:
loss_val = sess.run(loss, feed_dict=feed_dict)
loss_vec.append(loss_val)
loss_x_vec.append(i+1)
print("Loss at step {} : {}".format(i+1, loss_val))
# Validation: Print some random words and top 5 related words
if (i+1) % print_valid_every == 0:
sim = sess.run(similarity, feed_dict=feed_dict)
for j in range(len(valid_words)):
valid_word = word_dictionary_rev[valid_examples[j]]
top_k = 5 # number of nearest neighbors
nearest = (-sim[j, :]).argsort()[1:top_k+1]
log_str = "Nearest to {}:".format(valid_word)
for k in range(top_k):
close_word = word_dictionary_rev[nearest[k]]
log_str = "%s %s," % (log_str, close_word)
print(log_str)
```
> 在前面的代码中,我们在调用`argsort`方法之前采用相似矩阵的否定。我们这样做是因为我们想要找到从最高相似度值到最低相似度值的索引,而不是相反。
1. 这导致以下输出:
```py
Loss at step 500 : 13.387781143188477
Loss at step 1000 : 7.240757465362549
Loss at step 49500 : 0.9395825862884521
Loss at step 50000 : 0.30323168635368347
Nearest to cliche: walk, intrigue, brim, eileen, dumber,
Nearest to love: plight, fiction, complete, lady, bartleby,
Nearest to hate: style, throws, players, fearlessness, astringent,
Nearest to silly: delivers, meow, regain, nicely, anger,
Nearest to sad: dizzying, variety, existing, environment, tunney,
```
## 工作原理
我们通过`Skip-Gram`方法在电影评论数据集上训练了一个 word2vec 模型。我们下载了数据,将单词转换为带有字典的索引,并将这些索引号用作嵌入查找,我们对其进行了训练,以便附近的单词可以相互预测。
## 更多
乍一看,我们可能期望验证集的附近单词集合是同义词。事实并非如此,因为很少有同义词实际上在句子中彼此相邻。我们真正得到的是预测我们的数据集中哪些单词彼此接近。我们希望使用这样的嵌入将使预测更容易。
为了使用这些嵌入,我们必须使它们可重用并保存它们。我们将通过实现 CBOW 嵌入在下一个秘籍中执行此操作。
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras