
# 堆叠多个 LSTM 层
正如我们可以增加神经网络或 CNN 的深度,我们可以增加 RNN 网络的深度。在这个秘籍中,我们应用了一个三层深度的 LSTM 来改进我们的莎士比亚语言生成。
## 做好准备
我们可以通过将它们叠加在一起来增加循环神经网络的深度。从本质上讲,我们将获取目标输出并将其输入另一个网络。
要了解这对于两层的工作原理,请参见下图:
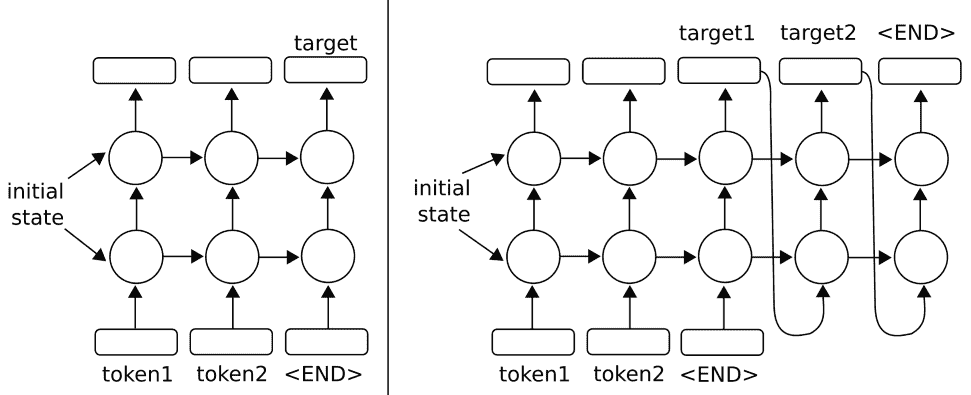
图 5:在上图中,我们扩展了单层 RNN,使它们具有两层。对于原始的单层版本,请参阅上一章简介中的绘图。左侧架构说明了使用多层 RNN 预测输出序列中的一个输出的方法。正确的架构显示了使用多层 RNN 预测输出序列的方法,该输出序列使用输出作为输入
TensorFlow 允许使用`MultiRNNCell()`函数轻松实现多个层,该函数接受 RNN 单元列表。有了这种行为,很容易用`MultiRNNCell([rnn_cell(num_units) for n in num_layers])`单元格从 Python 中的一个单元格创建多层 RNN。
对于这个秘籍,我们将执行我们在之前的秘籍中执行的相同的莎士比亚预测。将有两个变化:第一个变化将是具有三个堆叠的 LSTM 模型而不是仅一个层,第二个变化将是进行字符级预测而不是单词。进行字符级预测会将我们潜在的词汇量大大减少到只有 40 个字符(26 个字母,10 个数字,1 个空格和 3 个特殊字符)。
## 操作步骤
我们将说明本节中的代码与上一节的不同之处,而不是重新使用所有相同的代码。有关完整代码,请参阅 [https://github.com/nfmcclure/tensorflow_cookbook](https://github.com/nfmcclure/tensorflow_cookbook) 上的 GitHub 仓库或 [https://github.com/PacktPublishing/TensorFlow-Machine-的 Packt 仓库 Learning-Cookbook-Second-Edition](https://github.com/PacktPublishing/TensorFlow-Machine-Learning-Cookbook-Second-Edition) 。
1. 我们首先需要设置模型的层数。我们将此作为参数放在脚本的开头,并使用其他模型参数:
```py
num_layers = 3
min_word_freq = 5
```
```py
rnn_size = 128
epochs = 10
```
1. 第一个主要变化是我们将按字符加载,处理和提供文本,而不是按字词加载。为了实现这一点,在清理文本之后,我们可以使用 Python 的`list()`命令逐个字符地分隔整个文本:
```py
s_text = re.sub(r'[{}]'.format(punctuation), ' ', s_text)
s_text = re.sub('s+', ' ', s_text ).strip().lower()
# Split up by characters
char_list = list(s_text)
```
1. 我们现在需要更改 LSTM 模型,使其具有多个层。我们接受`num_layers`变量并使用 TensorFlow 的`MultiRNNCell()`函数创建一个多层 RNN 模型,如下所示:
```py
class LSTM_Model():
def __init__(self, rnn_size, num_layers, batch_size, learning_rate,
training_seq_len, vocab_size, infer_sample=False):
self.rnn_size = rnn_size
self.num_layers = num_layers
self.vocab_size = vocab_size
self.infer_sample = infer_sample
self.learning_rate = learning_rate
...
self.lstm_cell = tf.contrib.rnn.BasicLSTMCell(rnn_size)
self.lstm_cell = tf.contrib.rnn.MultiRNNCell([self.lstm_cell for _ in range(self.num_layers)])
self.initial_state = self.lstm_cell.zero_state(self.batch_size, tf.float32)
self.x_data = tf.placeholder(tf.int32, [self.batch_size, self.training_seq_len])
self.y_output = tf.placeholder(tf.int32, [self.batch_size, self.training_seq_len])
```
> 请注意,TensorFlow 的`MultiRNNCell()`函数接受 RNN 单元列表。在这个项目中,RNN 层都是相同的,但您可以列出您希望堆叠在一起的任何 RNN 层。
1. 其他一切基本相同。在这里,我们可以看到一些训练输出:
```py
Building Shakespeare Vocab by Characters
Vocabulary Length = 40
Starting Epoch #1 of 10
Iteration: 9430, Epoch: 10, Batch: 889 out of 950, Loss: 1.54
Iteration: 9440, Epoch: 10, Batch: 899 out of 950, Loss: 1.46
Iteration: 9450, Epoch: 10, Batch: 909 out of 950, Loss: 1.49
thou art more than the
to be or not to the serva
wherefore art thou dost thou
Iteration: 9460, Epoch: 10, Batch: 919 out of 950, Loss: 1.41
Iteration: 9470, Epoch: 10, Batch: 929 out of 950, Loss: 1.45
Iteration: 9480, Epoch: 10, Batch: 939 out of 950, Loss: 1.59
Iteration: 9490, Epoch: 10, Batch: 949 out of 950, Loss: 1.42
```
1. 以下是最终文本输出的示例:
```py
thou art more fancy with to be or not to be for be wherefore art thou art thou
```
1. 最后,以下是我们如何绘制几代的训练损失:
```py
plt.plot(train_loss, 'k-')
plt.title('Sequence to Sequence Loss')
plt.xlabel('Generation')
plt.ylabel('Loss')
plt.show()
```
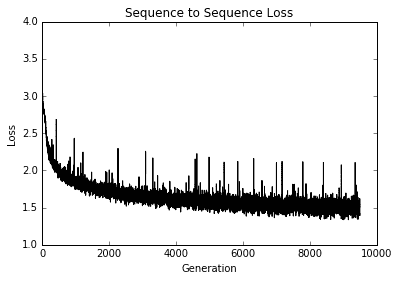
图 6:多层 LSTM 莎士比亚模型的训练损失与世代的关系图
## 工作原理
TensorFlow 只需一个 RNN 单元列表即可轻松将 RNN 层扩展到多个层。对于这个秘籍,我们使用与上一个秘籍相同的莎士比亚数据,但是用字符而不是单词处理它。我们通过三层 LSTM 模型来生成莎士比亚文本。我们可以看到,在仅仅 10 个周期之后,我们就能够以文字的形式产生古老的英语。
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras