
# 使用基于文本的距离
最近邻居比处理数字更通用。只要我们有一种方法来测量特征之间的距离,我们就可以应用最近邻算法。在本文中,我们将介绍如何使用 TensorFlow 测量文本距离。
## 做好准备
在本文中,我们将说明如何在字符串之间使用 TensorFlow 的文本距离度量,Levenshtein 距离(编辑距离)。这将在本章后面重要,因为我们扩展了最近邻方法以包含带有文本的特征。
Levenshtein 距离是从一个字符串到另一个字符串的最小编辑次数。允许的编辑是插入字符,删除字符或用不同的字符替换字符。对于这个秘籍,我们将使用 TensorFlow 的 Levenshtein 距离函数`edit_distance()`。值得说明这个函数的用法,因为它的用法将适用于后面的章节。
> 请注意,TensorFlow 的`edit_distance()`函数仅接受稀疏张量。我们必须创建我们的字符串作为单个字符的稀疏张量。
## 操作步骤
1. 首先,我们将加载 TensorFlow 并初始化图:
```py
import tensorflow as tf
sess = tf.Session()
```
1. 然后,我们将说明如何计算两个单词`'bear'`和`'beer'`之间的编辑距离。首先,我们将使用 Python 的`list()`函数从我们的字符串创建一个字符列表。接下来,我们将从该列表中创建一个稀疏的 3D 矩阵。我们必须告诉 TensorFlow 字符索引,矩阵的形状以及我们在张量中想要的字符。之后,我们可以决定是否要使用总编辑距离`(normalize=False)`或标准化编辑距离`(normalize=True)`,我们将编辑距离除以第二个单词的长度:
```py
hypothesis = list('bear')
truth = list('beers')
h1 = tf.SparseTensor([[0,0,0], [0,0,1], [0,0,2], [0,0,3]],
hypothesis, [1,1,1])
t1 = tf.SparseTensor([[0,0,0], [0,0,1], [0,0,1], [0,0,3],[0,0,4]], truth, [1,1,1])
print(sess.run(tf.edit_distance(h1, t1, normalize=False)))
[[ 2.]]
```
> TensorFlow 的文档将两个字符串视为提议(假设)字符串和基础事实字符串。我们将在这里用`h`和`t`张量继续这个表示法。函数`SparseTensorValue()`是一种在 TensorFlow 中创建稀疏张量的方法。它接受我们希望创建的稀疏张量的索引,值和形状。
1. 接下来,我们将说明如何将两个单词`bear`和`beer`与另一个单词`beers`进行比较。为了达到这个目的,我们必须复制`beers`以获得相同数量的可比词:
```py
hypothesis2 = list('bearbeer')
truth2 = list('beersbeers')
h2 = tf.SparseTensor([[0,0,0], [0,0,1], [0,0,2], [0,0,3], [0,1,0], [0,1,1], [0,1,2], [0,1,3]], hypothesis2, [1,2,4])
t2 = tf.SparseTensor([[0,0,0], [0,0,1], [0,0,2], [0,0,3], [0,0,4], [0,1,0], [0,1,1], [0,1,2], [0,1,3], [0,1,4]], truth2, [1,2,5])
print(sess.run(tf.edit_distance(h2, t2, normalize=True)))
[[ 0.40000001 0.2 ]]
```
1. 在此示例中显示了将一组单词与另一单词进行比较的更有效方法。我们将事先为假设和基本真实字符串创建索引和字符列表:
```py
hypothesis_words = ['bear','bar','tensor','flow']
truth_word = ['beers'']
num_h_words = len(hypothesis_words)
h_indices = [[xi, 0, yi] for xi,x in enumerate(hypothesis_words) for yi,y in enumerate(x)]
h_chars = list(''.join(hypothesis_words))
h3 = tf.SparseTensor(h_indices, h_chars, [num_h_words,1,1])
truth_word_vec = truth_word*num_h_words
t_indices = [[xi, 0, yi] for xi,x in enumerate(truth_word_vec) for yi,y in enumerate(x)]
t_chars = list(''.join(truth_word_vec))
t3 = tf.SparseTensor(t_indices, t_chars, [num_h_words,1,1])
print(sess.run(tf.edit_distance(h3, t3, normalize=True)))
[[ 0.40000001]
[ 0.60000002]
[ 0.80000001]
[ 1\. ]]
```
1. 现在,我们将说明如何使用占位符计算两个单词列表之间的编辑距离。这个概念是一样的,除了我们将`SparseTensorValue()`而不是稀疏张量。首先,我们将创建一个从单词列表创建稀疏张量的函数:
```py
def create_sparse_vec(word_list):
num_words = len(word_list)
indices = [[xi, 0, yi] for xi,x in enumerate(word_list) for yi,y in enumerate(x)]
chars = list(''.join(word_list))
return(tf.SparseTensorValue(indices, chars, [num_words,1,1]))
hyp_string_sparse = create_sparse_vec(hypothesis_words)
truth_string_sparse = create_sparse_vec(truth_word*len(hypothesis_words))
hyp_input = tf.sparse_placeholder(dtype=tf.string)
truth_input = tf.sparse_placeholder(dtype=tf.string)
edit_distances = tf.edit_distance(hyp_input, truth_input, normalize=True)
feed_dict = {hyp_input: hyp_string_sparse,
truth_input: truth_string_sparse}
print(sess.run(edit_distances, feed_dict=feed_dict))
[[ 0.40000001]
[ 0.60000002]
[ 0.80000001]
[ 1\. ]]
```
## 工作原理
在这个秘籍中,我们展示了我们可以使用 TensorFlow 以多种方式测量文本距离。这对于在具有文本特征的数据上执行最近邻居非常有用。当我们执行地址匹配时,我们将在本章后面看到更多内容。
## 更多
我们应该讨论其他文本距离指标。这是一个定义表,描述了两个字符串`s1`和`s2`之间的其他文本距离:
| 名称 | 描述 | 公式 |
| --- | --- | --- |
| 汉明距离 | 相同位置的相等字符的数量。仅在字符串长度相等时有效。 | 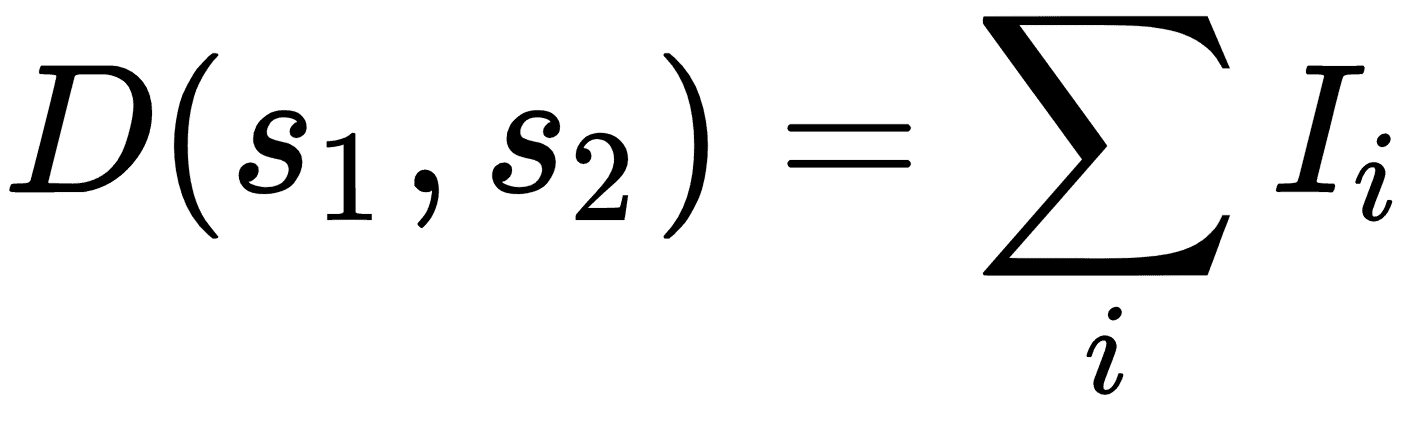,其中`I`是相等字符的指示函数。 |
| 余弦距离 | `k` - 差异的点积除以`k` - 差异的 L2 范数。 | 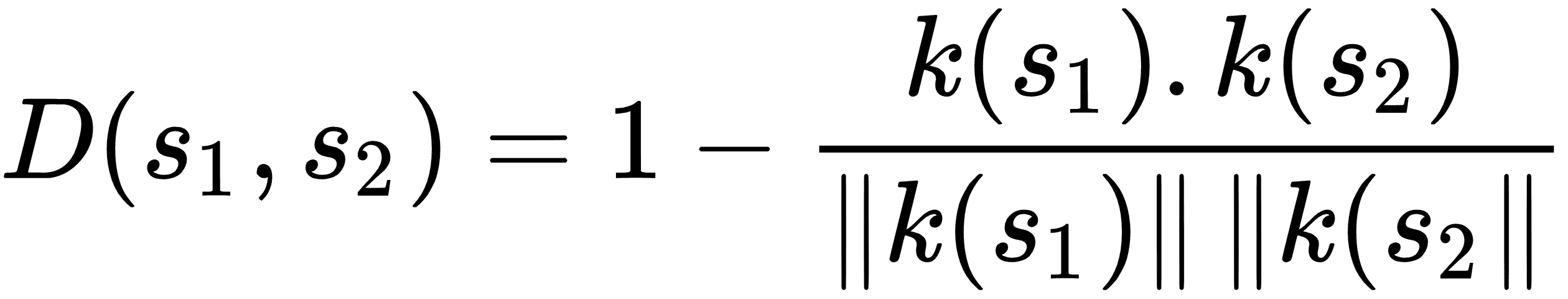 |
| 雅克卡距离 | 共同的字符数除以两个字符串中的字符总和。 | 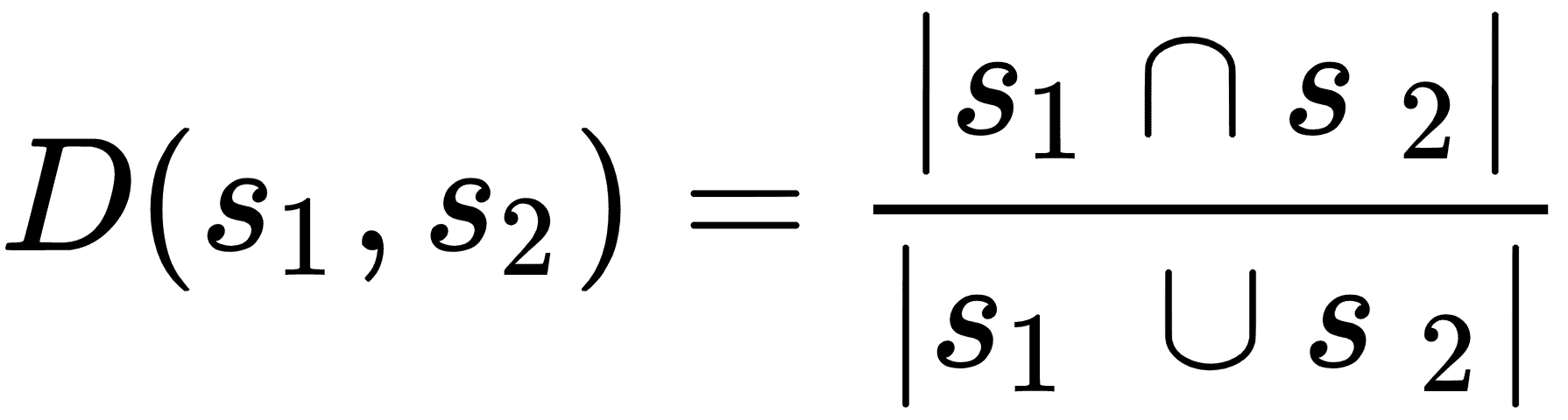 |
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras