
# 使用词袋嵌入
在本节中,我们将首先向您展示如何使用 TensorFlow 中的词袋嵌入。这种映射是我们在介绍中介绍的。在这里,我们将向您展示如何使用此类嵌入进行垃圾邮件预测。
## 做好准备
为了说明如何在文本数据集中使用词袋,我们将使用来自 UCI 机器学习数据仓库的垃圾邮件电话文本数据库( [https://archive.ics.uci.edu/ml/数据集/短信+垃圾邮件+收集](https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection))。这是垃圾邮件或非垃圾邮件(火腿)的电话短信集合。我们将下载此数据,将其存储以备将来使用,然后继续使用词袋方法来预测文本是否为垃圾邮件。将在词袋算法上运行的模型将是没有隐藏层的逻辑模型。我们将使用批量大小为 1 的随机训练,并在最后的保持测试集上计算精度。
## 操作步骤
对于这个例子,我们将首先获取数据,正则化和分割文本,通过嵌入函数运行它,并训练逻辑函数来预测垃圾邮件:
1. 第一项任务是为此任务导入必要的库。在通常的库中,我们需要一个`.zip`文件库来解压缩来自 UCI 机器学习网站的数据,我们从中检索它:
```py
import tensorflow as tf
import matplotlib.pyplot as plt
import os
import numpy as np
import csv
import string
import requests
import io
from zipfile import ZipFile
from tensorflow.contrib import learn
sess = tf.Session()
```
1. 我们不会在每次运行脚本时下载文本数据,而是保存它并检查文件之前是否已保存。如果我们想要更改脚本的参数,这可以防止我们反复下载数据。下载此数据后,我们将提取输入和目标数据,并将目标更改为`1`以查找垃圾邮件,将`0`更改为火腿:
```py
save_file_name = os.path.join('temp','temp_spam_data.csv')
if os.path.isfile(save_file_name):
text_data = []
with open(save_file_name, 'r') as temp_output_file:
reader = csv.reader(temp_output_file)
for row in reader:
text_data.append(row)
else:
zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip'
r = requests.get(zip_url)
z = ZipFile(io.BytesIO(r.content))
file = z.read('SMSSpamCollection')
# Format Data
text_data = file.decode()
text_data = text_data.encode('ascii',errors='ignore')
text_data = text_data.decode().split('\n')
text_data = [x.split('\t') for x in text_data if len(x)>=1]
# And write to csv
with open(save_file_name, 'w') as temp_output_file:
writer = csv.writer(temp_output_file)
writer.writerows(text_data)
texts = [x[1] for x in text_data]
target = [x[0] for x in text_data]
# Relabel 'spam' as 1, 'ham' as 0
target = [1 if x=='spam' else 0 for x in target]
```
1. 为了减少潜在的词汇量,我们将文本正则化。为此,我们消除了文本中大小写和数字的影响。使用以下代码:
```py
# Convert to lower case
texts = [x.lower() for x in texts]
# Remove punctuation
texts = [''.join(c for c in x if c not in string.punctuation) for x in texts]
# Remove numbers
texts = [''.join(c for c in x if c not in '0123456789') for x in texts]
# Trim extra whitespace
texts = [' '.join(x.split()) for x in texts]
```
1. 我们还必须确定最大句子大小。为此,我们将查看数据集中文本长度的直方图。我们可以看到一个很好的截止可能是 25 个字左右。使用以下代码:
```py
# Plot histogram of text lengths
text_lengths = [len(x.split()) for x in texts]
text_lengths = [x for x in text_lengths if x < 50]
plt.hist(text_lengths, bins=25)
plt.title('Histogram of # of Words in Texts')
sentence_size = 25
min_word_freq = 3
```
由此,我们将得到以下绘图:
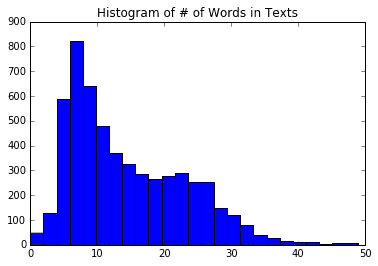
图 1:数据中每个文本中单词数的直方图。
We use this to establish a maximum length of words to consider in each text. We set this to 25 words, but it can easily be set to 30 or 40 as well.
1. TensorFlow 有一个内置的处理工具,用于确定名为`VocabularyProcessor()`的词汇嵌入,它位于`learn.preprocessing`库中。请注意,您可能会使用此函数获得已弃用的警告:
```py
vocab_processor = learn.preprocessing.VocabularyProcessor(sentence_size, min_frequency=min_word_freq)
vocab_processor.fit_transform(texts)
transformed_texts = np.array([x for x in vocab_processor.transform(texts)])
embedding_size = len(np.unique(transformed_texts))
```
1. 现在我们将数据分成 80-20 训练和测试集:
```py
train_indices = np.random.choice(len(texts), round(len(texts)*0.8), replace=False)
test_indices = np.array(list(set(range(len(texts))) - set(train_indices)))
texts_train = [x for ix, x in enumerate(texts) if ix in train_indices]
texts_test = [x for ix, x in enumerate(texts) if ix in test_indices]
target_train = [x for ix, x in enumerate(target) if ix in train_indices]
target_test = [x for ix, x in enumerate(target) if ix in test_indices]
```
1. 接下来,我们声明单词的嵌入矩阵。句子词将被翻译成指数。这些索引将被转换为一个热编码的向量,我们可以使用单位矩阵创建,这将是我们的单词嵌入的大小。我们将使用此矩阵查找每个单词的稀疏向量,并将它们一起添加到稀疏句子向量中。使用以下代码执行此操作:
```py
identity_mat = tf.diag(tf.ones(shape=[embedding_size]))
```
1. 由于我们最终会执行逻辑回归来预测垃圾邮件的概率,因此我们需要声明逻辑回归变量。然后我们也可以声明我们的数据占位符。值得注意的是,`x_data`输入占位符应该是整数类型,因为它将用于查找我们的单位矩阵的行索引。 TensorFlow 要求此查找为整数:
```py
A = tf.Variable(tf.random_normal(shape=[embedding_size,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Initialize placeholders
x_data = tf.placeholder(shape=[sentence_size], dtype=tf.int32)
y_target = tf.placeholder(shape=[1, 1], dtype=tf.float32)
```
1. 现在我们将使用 TensorFlow 的嵌入查找函数,它将句子中单词的索引映射到我们单位矩阵的单热编码向量。当我们有这个矩阵时,我们通过总结上述单词向量来创建句子向量。使用以下代码执行此操作:
```py
x_embed = tf.nn.embedding_lookup(identity_mat, x_data)
x_col_sums = tf.reduce_sum(x_embed, 0)
```
1. 现在我们为每个句子都有固定长度的句子向量,我们想要进行逻辑回归。为此,我们需要声明实际的模型操作。由于我们一次只做一个数据点(随机训练),我们将扩展输入的维度并对其进行线性回归操作。请记住,TensorFlow 具有包含 sigmoid 函数的 loss 函数,因此我们不需要在此输出中包含它:
```py
x_col_sums_2D = tf.expand_dims(x_col_sums, 0)
model_output = tf.add(tf.matmul(x_col_sums_2D, A), b)
```
1. 我们现在将声明损失函数,预测操作和优化函数来训练模型。使用以下代码执行此操作:
```py
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=model_output, labels=y_target))
# Prediction operation
prediction = tf.sigmoid(model_output)
# Declare optimizer
my_opt = tf.train.GradientDescentOptimizer(0.001)
train_step = my_opt.minimize(loss)
```
1. 接下来,我们将在开始训练生成之前初始化图变量:
```py
init = tf.global_variables_initializer()
sess.run(init)
```
1. 现在我们将开始对句子进行迭代。 TensorFlow 的`vocab_processor.fit()`函数是一次运行一个句子的生成器。我们将利用这一优势,以便我们可以对物流模型进行随机训练。为了更好地了解准确率趋势,我们将保留过去 50 个训练步骤的平均值。如果我们只是绘制当前的一个,我们会看到 1 或 0,这取决于我们是否预测训练数据是否正确。使用以下代码执行此操作:
```py
loss_vec = []
train_acc_all = []
train_acc_avg = []
for ix, t in enumerate(vocab_processor.fit_transform(texts_train)):
y_data = [[target_train[ix]]]
sess.run(train_step, feed_dict={x_data: t, y_target: y_data})
temp_loss = sess.run(loss, feed_dict={x_data: t, y_target: y_data})
loss_vec.append(temp_loss)
if (ix+1)%10==0:
print('Training Observation #{}: Loss= {}'.format(ix+1, temp_loss))
# Keep trailing average of past 50 observations accuracy
# Get prediction of single observation
[[temp_pred]] = sess.run(prediction, feed_dict={x_data:t, y_target:y_data})
# Get True/False if prediction is accurate
train_acc_temp = target_train[ix]==np.round(temp_pred)
train_acc_all.append(train_acc_temp)
if len(train_acc_all) >= 50:
train_acc_avg.append(np.mean(train_acc_all[-50:]))
```
1. 这导致以下输出:
```py
Starting Training Over 4459 Sentences.
Training Observation #10: Loss = 5.45322
Training Observation #20: Loss = 3.58226
Training Observation #30: Loss = 0.0
...
Training Observation #4430: Loss = 1.84636
Training Observation #4440: Loss = 1.46626e-05
Training Observation #4450: Loss = 0.045941
```
1. 为了获得测试集的准确率,我们重复前面的过程,但仅限于预测操作,而不是测试集的训练操作:
```py
print('Getting Test Set Accuracy')
test_acc_all = []
for ix, t in enumerate(vocab_processor.fit_transform(texts_test)):
y_data = [[target_test[ix]]]
if (ix+1)%50==0:
print('Test Observation #{}'.format(ix+1))
# Keep trailing average of past 50 observations accuracy
# Get prediction of single observation
[[temp_pred]] = sess.run(prediction, feed_dict={x_data:t, y_target:y_data})
# Get True/False if prediction is accurate
test_acc_temp = target_test[ix]==np.round(temp_pred)
test_acc_all.append(test_acc_temp)
print('\nOverall Test Accuracy: {}'.format(np.mean(test_acc_all)))
Getting Test Set Accuracy For 1115 Sentences.
Test Observation #10
Test Observation #20
Test Observation #30
...
Test Observation #1000
Test Observation #1050
Test Observation #1100
Overall Test Accuracy: 0.8035874439461883
```
## 工作原理
在本例中,我们使用了来自 UCI 机器学习库的垃圾邮件文本数据。我们使用 TensorFlow 的词汇处理函数来创建标准化词汇表来处理和创建句子向量,这些句子向量是每个文本的单词向量的总和。我们使用这个句子向量与逻辑回归并获得 80%准确率模型来预测特定文本是否是垃圾邮件。
## 更多
值得一提的是限制句子(或文本)大小的动机。在此示例中,我们将文本大小限制为 25 个单词。这是词袋的常见做法,因为它限制了文本长度对预测的影响。你可以想象,如果我们找到一个单词,例如`meeting`,它可以预测文本是火腿(而不是垃圾邮件),那么垃圾邮件可能会通过在最后输入该单词的多次出现来实现。实际上,这是目标数据不平衡的常见问题。在这种情况下可能会出现不平衡的数据,因为垃圾邮件可能很难找到,而火腿可能很容易找到。由于这个事实,我们创建的词汇可能严重偏向于我们数据的火腿部分中表示的单词(更多火腿意味着更多的单词在火腿中表示而不是垃圾邮件)。如果我们允许无限长度的文本,那么垃圾邮件发送者可能会利用这一点并创建非常长的文本,这些文本在我们的逻辑模型中触发非垃圾邮件词因素的概率更高。
在下一节中,我们将尝试通过使用单词出现的频率来更好地解决此问题,以确定单词嵌入的值。
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras