
# 训练 Siamese RNN 相似性度量
与许多其他模型相比,RNN 模型的一个重要特性是它们可以处理各种长度的序列。利用这一点,以及它们可以推广到之前未见过的序列这一事实,我们可以创建一种方法来衡量输入的相似序列是如何相互作用的。在这个秘籍中,我们将训练一个 Siamese 相似性 RNN 来测量地址之间的相似性以进行记录匹配。
## 做好准备
在本文中,我们将构建一个双向 RNN 模型,该模型将输入到一个完全连接的层,该层输出一个固定长度的数值向量。我们为两个输入地址创建双向 RNN 层,并将输出馈送到完全连接的层,该层输出固定长度的数字向量(长度 100)。然后我们将两个向量输出与余弦距离进行比较,余弦距离在-1 和 1 之间。我们将输入数据表示为与目标 1 相似,并且目标为-1。余弦距离的预测只是输出的符号(负值表示不相似,正表示相似)。我们可以使用此网络通过从查询地址获取在余弦距离上得分最高的参考地址来进行记录匹配。
请参阅以下网络架构图:
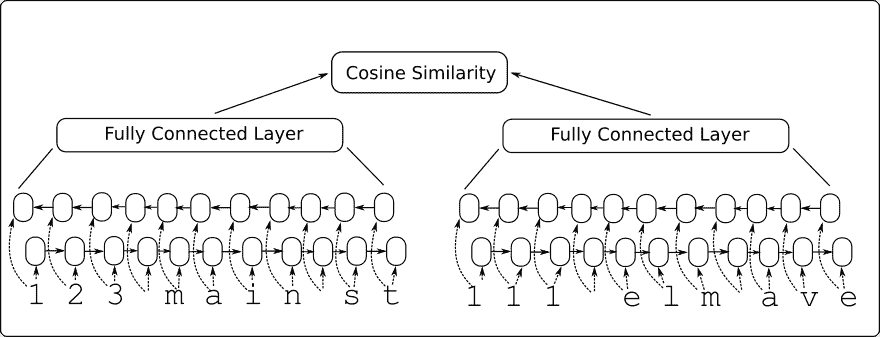
图 8:Siamese RNN 相似性模型架构
这个模型的优点还在于它接受以前没有见过的输入,并且可以将它们与-1 到 1 的输出进行比较。我们将通过选择模型之前未见过的测试地址在代码中显示它并查看它是否可以匹配到类似的地址。
## 操作步骤
1. 我们首先加载必要的库并开始图会话:
```py
import os
import random
import string
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
sess = tf.Session()
```
1. 我们现在设置模型参数如下:
```py
batch_size = 200
n_batches = 300
max_address_len = 20
margin = 0.25
num_features = 50
dropout_keep_prob = 0.8
```
1. 接下来,我们创建 Siamese RNN 相似性模型类,如下所示:
```py
def snn(address1, address2, dropout_keep_prob,
vocab_size, num_features, input_length):
# Define the Siamese double RNN with a fully connected layer at the end
def Siamese_nn(input_vector, num_hidden):
cell_unit = tf.nn.rnn_cell.BasicLSTMCell
# Forward direction cell
lstm_forward_cell = cell_unit(num_hidden, forget_bias=1.0)
lstm_forward_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_forward_cell, output_keep_prob=dropout_keep_prob)
# Backward direction cell
lstm_backward_cell = cell_unit(num_hidden, forget_bias=1.0)
lstm_backward_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_backward_cell, output_keep_prob=dropout_keep_prob)
# Split title into a character sequence
input_embed_split = tf.split(1, input_length, input_vector)
input_embed_split = [tf.squeeze(x, squeeze_dims=[1]) for x in input_embed_split]
# Create bidirectional layer
outputs, _, _ = tf.nn.bidirectional_rnn(lstm_forward_cell,
lstm_backward_cell,
input_embed_split,
dtype=tf.float32)
# Average The output over the sequence
temporal_mean = tf.add_n(outputs) / input_length
# Fully connected layer
output_size = 10
A = tf.get_variable(name="A", shape=[2*num_hidden, output_size],
dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.1))
b = tf.get_variable(name="b", shape=[output_size], dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.1))
final_output = tf.matmul(temporal_mean, A) + b
final_output = tf.nn.dropout(final_output, dropout_keep_prob)
return(final_output)
with tf.variable_scope("Siamese") as scope:
output1 = Siamese_nn(address1, num_features)
# Declare that we will use the same variables on the second string
scope.reuse_variables()
output2 = Siamese_nn(address2, num_features)
# Unit normalize the outputs
output1 = tf.nn.l2_normalize(output1, 1)
output2 = tf.nn.l2_normalize(output2, 1)
# Return cosine distance
# in this case, the dot product of the norms is the same.
dot_prod = tf.reduce_sum(tf.mul(output1, output2), 1)
return dot_prod
```
> 请注意,使用变量范围在两个地址输入的 Siamese 网络的两个部分之间共享参数。另外,请注意,余弦距离是通过归一化向量的点积来实现的。
1. 现在我们将声明我们的预测函数,它只是余弦距离的符号,如下所示:
```py
def get_predictions(scores):
predictions = tf.sign(scores, name="predictions")
return predictions
```
1. 现在我们将如前所述声明我们的`loss`函数。请记住,我们希望为错误留下边距(类似于 SVM 模型)。我们还将有一个真正的积极和真正的消极的损失期限。使用以下代码进行损失:
```py
def loss(scores, y_target, margin):
# Calculate the positive losses
pos_loss_term = 0.25 * tf.square(tf.sub(1., scores))
pos_mult = tf.cast(y_target, tf.float32)
# Make sure positive losses are on similar strings
positive_loss = tf.mul(pos_mult, pos_loss_term)
# Calculate negative losses, then make sure on dissimilar strings
neg_mult = tf.sub(1., tf.cast(y_target, tf.float32))
negative_loss = neg_mult*tf.square(scores)
# Combine similar and dissimilar losses
loss = tf.add(positive_loss, negative_loss)
# Create the margin term. This is when the targets are 0, and the scores are less than m, return 0\.
# Check if target is zero (dissimilar strings)
target_zero = tf.equal(tf.cast(y_target, tf.float32), 0.)
# Check if cosine outputs is smaller than margin
less_than_margin = tf.less(scores, margin)
# Check if both are true
both_logical = tf.logical_and(target_zero, less_than_margin)
both_logical = tf.cast(both_logical, tf.float32)
# If both are true, then multiply by (1-1)=0\.
multiplicative_factor = tf.cast(1\. - both_logical, tf.float32)
total_loss = tf.mul(loss, multiplicative_factor)
# Average loss over batch
avg_loss = tf.reduce_mean(total_loss)
return avg_loss
```
1. 我们声明`accuracy`函数如下:
```py
def accuracy(scores, y_target):
predictions = get_predictions(scores)
correct_predictions = tf.equal(predictions, y_target)
accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32))
return accuracy
```
1. 我们将通过在地址中创建拼写错误来创建类似的地址。我们将这些地址(参考地址和拼写错误地址)表示为类似:
```py
def create_typo(s):
rand_ind = random.choice(range(len(s)))
s_list = list(s)
s_list[rand_ind]=random.choice(string.ascii_lowercase + '0123456789')
s = ''.join(s_list)
return s
```
1. 我们将生成的数据将是街道号码,`street_names`和街道后缀的随机组合。名称和后缀来自以下列表:
```py
street_names = ['abbey', 'baker', 'canal', 'donner', 'elm', 'fifth', 'grandvia', 'hollywood', 'interstate', 'jay', 'kings']
street_types = ['rd', 'st', 'ln', 'pass', 'ave', 'hwy', 'cir', 'dr', 'jct']
```
1. 我们生成测试查询和引用如下:
```py
test_queries = ['111 abbey ln', '271 doner cicle',
'314 king avenue', 'tensorflow is fun']
test_references = ['123 abbey ln', '217 donner cir', '314 kings ave', '404 hollywood st', 'tensorflow is so fun']
```
> 请注意,最后一个查询和引用不是模型之前会看到的地址,但我们希望它们将是模型最终看到的最相似的地址。
1. 我们现在将定义如何生成一批数据。我们的批量数据将是 50%类似的地址(参考地址和拼写错误地址)和 50%不同的地址。我们通过占用地址列表的一半并将目标移动一个位置(使用`numpy.roll()`函数)来生成不同的地址:
```py
def get_batch(n):
# Generate a list of reference addresses with similar addresses that have
# a typo.
numbers = [random.randint(1, 9999) for i in range(n)]
streets = [random.choice(street_names) for i in range(n)]
street_suffs = [random.choice(street_types) for i in range(n)]
full_streets = [str(w) + ' ' + x + ' ' + y for w,x,y in zip(numbers, streets, street_suffs)]
typo_streets = [create_typo(x) for x in full_streets]
reference = [list(x) for x in zip(full_streets, typo_streets)]
# Shuffle last half of them for training on dissimilar addresses
half_ix = int(n/2)
bottom_half = reference[half_ix:]
true_address = [x[0] for x in bottom_half]
typo_address = [x[1] for x in bottom_half]
typo_address = list(np.roll(typo_address, 1))
bottom_half = [[x,y] for x,y in zip(true_address, typo_address)]
reference[half_ix:] = bottom_half
# Get target similarities (1's for similar, -1's for non-similar)
target = [1]*(n-half_ix) + [-1]*half_ix
reference = [[x,y] for x,y in zip(reference, target)]
return reference
```
1. 接下来,我们定义地址词汇表并指定如何将地址热编码为索引:
```py
vocab_chars = string.ascii_lowercase + '0123456789 '
vocab2ix_dict = {char:(ix+1) for ix, char in enumerate(vocab_chars)}
vocab_length = len(vocab_chars) + 1
# Define vocab one-hot encoding
def address2onehot(address,
vocab2ix_dict = vocab2ix_dict,
max_address_len = max_address_len):
# translate address string into indices
address_ix = [vocab2ix_dict[x] for x in list(address)]
# Pad or crop to max_address_len
address_ix = (address_ix + [0]*max_address_len)[0:max_address_len]
return address_ix
```
1. 处理完词汇后,我们将开始声明我们的模型占位符和嵌入查找。对于嵌入查找,我们将使用单一矩阵作为查找矩阵来使用单热编码嵌入。使用以下代码:
```py
address1_ph = tf.placeholder(tf.int32, [None, max_address_len], name="address1_ph")
address2_ph = tf.placeholder(tf.int32, [None, max_address_len], name="address2_ph")
y_target_ph = tf.placeholder(tf.int32, [None], name="y_target_ph")
dropout_keep_prob_ph = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Create embedding lookup
identity_mat = tf.diag(tf.ones(shape=[vocab_length]))
address1_embed = tf.nn.embedding_lookup(identity_mat, address1_ph)
address2_embed = tf.nn.embedding_lookup(identity_mat, address2_ph)
```
1. 我们现在将声明`model`,`batch_accuracy`,`batch_loss`和`predictions`操作如下:
```py
# Define Model
text_snn = model.snn(address1_embed, address2_embed, dropout_keep_prob_ph,
vocab_length, num_features, max_address_len)
# Define Accuracy
batch_accuracy = model.accuracy(text_snn, y_target_ph)
# Define Loss
batch_loss = model.loss(text_snn, y_target_ph, margin)
# Define Predictions
predictions = model.get_predictions(text_snn)
```
1. 最后,在我们开始训练之前,我们将优化和初始化操作添加到图中,如下所示:
```py
# Declare optimizer
optimizer = tf.train.AdamOptimizer(0.01)
# Apply gradients
train_op = optimizer.minimize(batch_loss)
# Initialize Variables
init = tf.global_variables_initializer()
sess.run(init)
```
1. 我们现在将遍历训练世代并跟踪损失和准确率:
```py
train_loss_vec = []
train_acc_vec = []
for b in range(n_batches):
# Get a batch of data
batch_data = get_batch(batch_size)
# Shuffle data
np.random.shuffle(batch_data)
# Parse addresses and targets
input_addresses = [x[0] for x in batch_data]
target_similarity = np.array([x[1] for x in batch_data])
address1 = np.array([address2onehot(x[0]) for x in input_addresses])
address2 = np.array([address2onehot(x[1]) for x in input_addresses])
train_feed_dict = {address1_ph: address1,
address2_ph: address2,
y_target_ph: target_similarity,
dropout_keep_prob_ph: dropout_keep_prob}
_, train_loss, train_acc = sess.run([train_op, batch_loss, batch_accuracy],
feed_dict=train_feed_dict)
# Save train loss and accuracy
train_loss_vec.append(train_loss)
train_acc_vec.append(train_acc)
```
1. 经过训练,我们现在处理测试查询和引用,以了解模型的执行方式:
```py
test_queries_ix = np.array([address2onehot(x) for x in test_queries])
test_references_ix = np.array([address2onehot(x) for x in test_references])
num_refs = test_references_ix.shape[0]
best_fit_refs = []
for query in test_queries_ix:
test_query = np.repeat(np.array([query]), num_refs, axis=0)
test_feed_dict = {address1_ph: test_query,
address2_ph: test_references_ix,
y_target_ph: target_similarity,
dropout_keep_prob_ph: 1.0}
test_out = sess.run(text_snn, feed_dict=test_feed_dict)
best_fit = test_references[np.argmax(test_out)]
best_fit_refs.append(best_fit)
print('Query Addresses: {}'.format(test_queries))
print('Model Found Matches: {}'.format(best_fit_refs))
```
1. 这导致以下输出:
```py
Query Addresses: ['111 abbey ln', '271 doner cicle', '314 king avenue', 'tensorflow is fun']
Model Found Matches: ['123 abbey ln', '217 donner cir', '314 kings ave', 'tensorflow is so fun']
```
## 更多
我们可以从测试查询和参考中看到模型不仅能够识别正确的参考地址,而且还能够推广到非地址短语。我们还可以通过查看训练期间的损失和准确率来了解模型的执行情况:
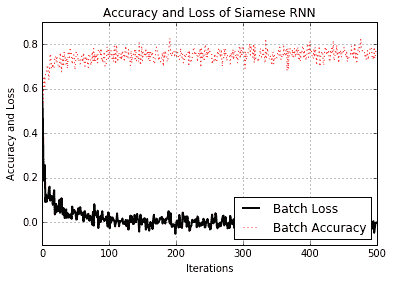
图 9:训练期间 Siamese RNN 相似性模型的准确率和损失
请注意,我们没有为此练习指定测试集。这是因为我们如何生成数据。我们创建了一个批量函数,每次调用它时都会创建新的批量数据,因此模型始终可以看到新数据。因此,我们可以使用批量损失和精度作为测试损失和准确率的替代项。但是,对于一组有限的实际数据,情况永远不会如此,因为我们总是需要训练和测试集来判断模型的表现。
- TensorFlow 入门
- 介绍
- TensorFlow 如何工作
- 声明变量和张量
- 使用占位符和变量
- 使用矩阵
- 声明操作符
- 实现激活函数
- 使用数据源
- 其他资源
- TensorFlow 的方式
- 介绍
- 计算图中的操作
- 对嵌套操作分层
- 使用多个层
- 实现损失函数
- 实现反向传播
- 使用批量和随机训练
- 把所有东西结合在一起
- 评估模型
- 线性回归
- 介绍
- 使用矩阵逆方法
- 实现分解方法
- 学习 TensorFlow 线性回归方法
- 理解线性回归中的损失函数
- 实现 deming 回归
- 实现套索和岭回归
- 实现弹性网络回归
- 实现逻辑回归
- 支持向量机
- 介绍
- 使用线性 SVM
- 简化为线性回归
- 在 TensorFlow 中使用内核
- 实现非线性 SVM
- 实现多类 SVM
- 最近邻方法
- 介绍
- 使用最近邻
- 使用基于文本的距离
- 使用混合距离函数的计算
- 使用地址匹配的示例
- 使用最近邻进行图像识别
- 神经网络
- 介绍
- 实现操作门
- 使用门和激活函数
- 实现单层神经网络
- 实现不同的层
- 使用多层神经网络
- 改进线性模型的预测
- 学习玩井字棋
- 自然语言处理
- 介绍
- 使用词袋嵌入
- 实现 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 进行预测
- 使用 doc2vec 进行情绪分析
- 卷积神经网络
- 介绍
- 实现简单的 CNN
- 实现先进的 CNN
- 重新训练现有的 CNN 模型
- 应用 StyleNet 和 NeuralStyle 项目
- 实现 DeepDream
- 循环神经网络
- 介绍
- 为垃圾邮件预测实现 RNN
- 实现 LSTM 模型
- 堆叠多个 LSTM 层
- 创建序列到序列模型
- 训练 Siamese RNN 相似性度量
- 将 TensorFlow 投入生产
- 介绍
- 实现单元测试
- 使用多个执行程序
- 并行化 TensorFlow
- 将 TensorFlow 投入生产
- 生产环境 TensorFlow 的一个例子
- 使用 TensorFlow 服务
- 更多 TensorFlow
- 介绍
- 可视化 TensorBoard 中的图
- 使用遗传算法
- 使用 k 均值聚类
- 求解常微分方程组
- 使用随机森林
- 使用 TensorFlow 和 Keras