
[TOC]
原文地址:[linux--Flex and Bison](https://blog.csdn.net/qq_38880380/article/details/99447017#121_flex_8)
# 1 介绍
## 1.1 概述
* Flex and bison就是lex and yacc的升级版。Lex 代表 Lexical Analyzar。Yacc 代表 Yet Another Compiler Compiler。
* Flex和bison是两个用来生成程序的工具,它们生成的程序分别叫做词法分析器和语法分析器。
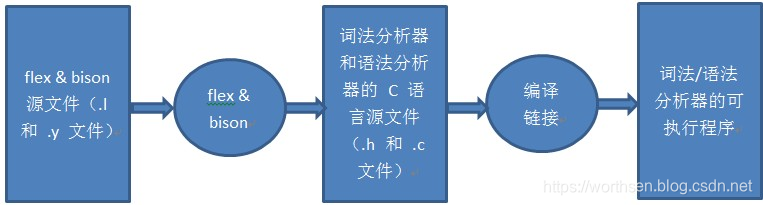
* Flex生成的词法分析器将输入拆分成一个个记号(token),bison生成的语法分析器根据已有的规则,分析这些token的组合,是否符合语法规范。
## 1.2 理解
### 1.2.1 flex
> flex用于分词,它比较好理解
> flex的规则文件以.l为后缀名,生成的文件为lex.yy.c
> 规则文件分为3个部分,每个部分之间用%%分割
* 声明部分
声明部分可以进行声明和选项设置
另外,如果有被%{和%}包围的部分,里面的内容会被完整地复制到 lex.yy.c 的开头,通常会用来放置include、define的信息
例如:
%{
#include
%}
* 规则部分
这部分主要描述规则,格式是:
正则表达式 {匹配到之后执行的C代码}
例如:
\[0-9\] {printf(“NUMBER %s\\n”,yytext);}
行首不可留白
* C代码部分
这部分是C代码,它们会被复制到 lex.yy.c的最末
通常用于一些未定义接口的定义,例如
int yywrap()
{
return 1;
}
### 1.2.2 bison
> bison的规则文件以.y为后缀,生成的文件为 xxx.tab.c和xxx.tab.h
> 规则文件也分为3个部分
* 声明部分和C代码部分
和flex一样,可以进行声明和选项设置,C代码则是拷贝到文件末
声明部分同时也可以写%{%}
在这之后,一般还要进行token设置
token用于标记语法解析中用到的基本语素,教程里称之为“记号”,语法是:
%token 记号
例如
%token NUMBER
一行可以声明多个记号,例如
%token ADD SUB MUL DIV
记号大概就是每个语法树的节点,比如一个变量、一个数字/字符串常量、一个运算符
这些记号将被用于规则部分
通常是:flex中匹配到某个词,然后{return NUMBER;}返回一个记号,然后在bison的规则中查找应该进行的动作
* 规则部分
## 1.3 应用
* 桌面计算器bc
* 工具eqn和pic,用于数学方程式和复杂图片的排版预处理器
* 用于特定应用设计的大量领域特定语言
* PCC,在许多unix系统中被使用的可移植的C编译器
* flex自身
* SQL数据库语言翻译器
## 1.4 编译器的定义与需求
* 编译器是将一种程序语言(源程序:source language)翻译为另一种程序语言(目标程序:target language)的计算机程序。一般来说,源程序为高级语言,而目标语言则是汇编语言或机器码。
* 早期的计算机程序员们用机器码写程序,编程十分耗时耗力,也非常容易出错,很快程序员们发明了汇编语言,提高了编程的速度和准确度,但编写起来还是不容易,且程序严格依赖于特定的机器,很难移植和重复利用。
* 上世纪50~60年代,第一批高级语言及编译器被开发出来,程序的文法非常接近于数学公式以及自然语言,使得编写、阅读和维护程序的难度大为降低,程序编制的速度、规模和稳定性都有了质的飞跃。
* 可以说是编译器的产生带来了计算机行业的飞跃发展,所以开发编译器是非常有必要的。
# 2 词法分析与语法分析
## 2.1 词法分析
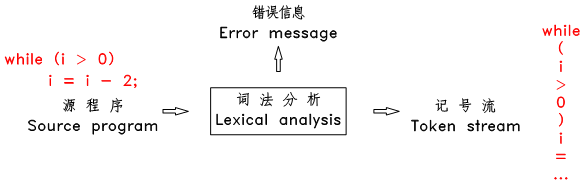
### 2.1.1 基本概念
> 词法分析也称为 分词 ,此阶段编译器从左向右扫描源文件,将其字符流分割成一个个的 词 ( token 、 记号 )。所谓 token ,就是源文件中不可再进一步分割的一串字符
一般来说程序语言中的 token 有:常数(整数、小数、字符、字符串等),操作符(算术操作符、比较操作符、逻辑操作符),分隔符(逗号、分号、括号等),保留字,标识符(变量名、函数名、类名等)等。如:
* 3 和 255 是整数常数 token
* “Fred” 和 “wilma” 是字符串 token
* numTickets 和 queue 是标识符 token
* while 是 T\_WHILE token
上述的 3 、 “Fred” 和 while 等称为 token 的 字面值 。有些类别的 token 只有一个字面值,如保留字和分隔符类的 token,其他类别的 token 则有不同字面值,如整数常数 token 。下面是一些典型的 token 及其字面值:
~~~
TOKEN-TYPE TOKEN-VALUE
-----------------------------------------------
T_IF if
T_WHILE while
T_ASSIGN =
T_GREATTHAN >
T_GREATEQUAL >=
T_IDENTIFIER name / numTickets / ...
T_INTEGERCONSTANT 100 / 1 / 12 / ....
T_STRINGCONSTANT "This is a string" / "hello" / ...
~~~
编译器中的 token 中一般用一个 struct 来表示:
~~~
typedef enum {
T_IF, T_WHILE, T_ADD, T_INTCONSTANT, T_STRINGCONSTANT, T_IDENTIFIER, ...
} TokenType;
typedef struct _Token {
TokenType type;
union {
char *stringval;
int *intval;
double *doubleval;
} value;
} TokenRecord;
~~~
词法分析器每扫描到一个完整的 token 后,立即 新建一个 TokenRecord ,将此 token 的类型记录在此结构的**type**域中,将其字面值记录在**value**域中对应的子域内,并将此 TokenRecord 结构传递给下一阶段的语法分析模块使用,然后接着扫描下一个 token 。这样从语法分析模块的角度来看,源程序就变成了一个连续的 token stream 了。
### 2.1.2 分词方法
> 分词扫描的方法有直接扫描法和正则表达式匹配扫描法
#### 2.1.2.1 直接扫描法
* 直接扫描法的思路非常简单,每轮扫描,根据第一个字符判断属于哪种类型的 token 然后采取不同的策略扫描出一个完整的 token ,再接着进行下一轮扫描。
* 直接扫描法思路简单,代码量非常少。但缺点是速度慢,对标识符类型的 token 需要进行至少 2 次扫描,且需进行字符串查找和比较。而且不容易扩展,只适用于语法简单的语言。目前一般的编译器都是采用基于正则表达式匹配的分词扫描法。
#### 2.1.2.2 正则表达式
正则表达式一般都采用一些简写的方式,最常见的有:
* 特殊字符
以下 11 个字符:
~~~
* [ ] ^ $ . | ? * + ( )
~~~
被保留作特殊用途,如果想使用这些字符的字面值,需要在前面加反斜杠 “\\” 转义。另外,一些不便书写的字符可以通过在前面加 “\\” 转义,如 \\n 和 \\t 分别表示换行符和制表符。
* 字符集
如: \[abferx\] ,用方括号括起来的字符,表示匹配这些字符中的其中一个,相当于 (a|b|f|e|r|x) 。方括号内的特殊字符不需要转义( \[ \] - ^ 除外),如 \[af({\] 表示 匹配 “a”, “f”, “{”, “(” 中的其中一个。方扩号内可以使用 “-“ 来定义一个范围,且可以定义多个范围,如 \[0-9\] 表示匹配单个数字, \[a-zA-Z\] 表示匹配单个字母。
* 取反字符集
如: \[^abc\] ,在方括号内的第一个字符为 ^ ,表示这是一个取反字符集,表示匹配一个不在方括号内部的字符。
* \*、?和+
\* 表示匹配前面的字符(或者由括号括起来的表达式、方括号括起来的字符集)0次或多次;
? 表示匹配前面的字符(或者由括号括起来的表达式、方括号括起来的字符集)0次或1次;
\+ 表示匹配前面的字符(或者由括号括起来的表达式、方括号括起来的字符集)1次或多次。
* ”.” 通配符
. 表示匹配除换行符外的任意字符一次。
正则表达式可以用来表示源程序中的 token ,如:
整数 : \[0-9\]+
小数 : \[0-9\]+.\[0-9\]\*
字符串 : \\”\[^\\”\]*\\”
标识符 : \[\_a-zA-Z\]\[\_a-zA-Z0-9\]*
关键字 if : if
### 2.1.3 有限状态自动机(FA)
* 有限状态自动机(finate automaton)是用来判断字符串(句子)是否和正则表达式匹配的假想机器,它有一个字母表 Σ 、一个状态集合 S ,一个转换函数 T ,当它处于某个状态时,若它读入了一个字符(必须是字母表里的字符),则会根据当前状态和读入的字符自动转换到另一个状态,它有一个初始状态,还有一些所谓的接受状态。
* 它的工作过程是:首先自动机处于初始状态,之后它开始读入字符串,每读入一个字符,它都根据当前状态和读入字符转换到下一状态,直到字符串结束,若此时自动机处于其接受状态,则表示该字符串被此自动机接受。如下图:
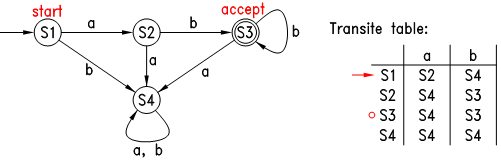
* 上图中圆圈表示各种状态,各箭头及签头上的字符表示状态的转换表,自动机只有一个初始状态,用一个不含字符的箭头指向此状态,可以认为此为自动机的入口,自动机可以有一个或多个接受状态,用双圆圈表示。上图中的自动机的字母表为 {a, b},初始状态为 S1 ,当它读入一个 a 后,就转到状态 S2 ,若读入的是 b ,则转到 S4,然后一个接一个字符的转换其状态,若字符结束时自动机处在其接受状态,则表示此字符串被其接受。经过观察可知,此图中的自动机能接受的字符串为 “ab”, “abb”, “abbb”, … ,也就是说,**此自动机与正则表达式 ab+ 是等价的**。
* 简单的有限状态自动机可以通过 与、连接和重复 搭建出复杂的自动机。数学家们已经证明了:任何一个正则表达式都有一个等价的有限状态自动机,任何一个有限状态自动机也有一个等价的正则表达式。
* 可以看出有限状态自动机的判断速度是非常快的,它只要求对字符串扫描一遍就可以了,显然比直接扫描法要快多了。
* 总而言之,正则表达式的匹配判断可以通过构造有限状态自动机来进行,以上仅介绍了构造有限状态自动机的大体思路:先构造基本的自动机,再根据正则表达式的结构搭建出复杂的自动机。构造有限状态自动机的具体算法十分复杂,这里不再深入介绍了,还是借用前人已经做好的工具吧,下面,将介绍如何使用 flex 来进行基于正则匹配的词法分析。
### 2.1.4 用 flex 做词法分析
#### 2.1.4.1 介绍
flex 是一个快速词法分析生成器,它可以将用户用正则表达式写的分词匹配模式构造成一个有限状态自动机(一个C函数),目前很多编译器都采用它来生成词法分析器。
#### 2.1.4.2 用法
* 安装 flex
~~~
sudo apt-get install flex
或者下载相应版本的安装文件安装
~~~
* 然后新建一个文本文件,输入以下内容:
~~~
%%
[0-9]+ printf("?");
# return 0;
. ECHO;
%%
int main(int argc, char* argv[]) {
yylex();
return 0;
}
int yywrap() {
return 1;
}
~~~
将此文件另存为 hide-digits.l 。注意此文件中的 %% 必须在本行的最前面(即 %% 前面不能有任何空格)。
* 之后,在终端输入:
~~~
flex hide-digits.l
~~~
* 此时目录下多了一个 “lex.yy.c” 文件,把这个 C 文件编译并运行一遍:
~~~
gcc -o hide-digits lex.yy.c
./hide-digits
~~~
* 然后在终端不停的敲入任意键并回车,可以发现,敲入的内容中,除数字外的字符都被原样的输出了,而每串数字字符都被替换成 ? 了。最后敲入 # 后程序退出了。如下:
~~~
eruiewdkfj
eruiewdkfj
1245
?
fdsaf4578
fdsaf?
...
#
~~~
* 当在命令行中运行 flex 时,第二个命令行参数(此处是 hide-digits.l )是提供给 flex 的分词模式文件, 此模式文件中主要是用户用正则表达式写的分词匹配模式,用flex 会将这些正则表达式翻译成 C 代码格式的函数 yylex ,并输出到 lex.yy.c 文件中,该函数可以看成一个有限状态自动机。
* 当在命令行中运行 flex 时,第二个命令行参数(此处是 hide-digits.l )是提供给 flex 的分词模式文件, 此模式文件中主要是用户用正则表达式写的分词匹配模式,用flex 会将这些正则表达式翻译成 C 代码格式的函数 yylex ,并输出到 lex.yy.c 文件中,该函数可以看成一个有限状态自动机。
* 下面再来详细解释一下 hide-digits.l 文件中的代码,首先第一段是:
~~~
%%
[0-9]+ printf("?");
# return 0;
. ECHO;
%%
~~~
* flex 模式文件中,用%% 和 %%做分割, 上面分割的内容被称为 规则(rules),本文件中每一行都是一条规则,每条规则由 匹配模式(pattern) 和 事件(action) 组成, 模式在前面,用正则表达式表示,事件在后面,即 C 代码。每当一个模式被匹配到时,后面的 C 代码被执行。
* flex 会将本段内容翻译成一个名为 yylex 的函数,该函数的作用就是扫描输入文件(默认情况下为标准输入),当扫描到一个完整的、最长的、可以和某条规则的正则表达式所匹配的字符串时,该函数会执行此规则后面的 C 代码。如果这些 C 代码中没有 return 语句,则执行完这些 C 代码后, yylex 函数会继续运行,开始下一轮的扫描和匹配。
* 当有多条规则的模式被匹配到时, yylex 会选择匹配长度最长的那条规则,如果有匹配长度相等的规则,则选择排在最前面的规则。
~~~
int main(int argc, char *argv[]) {
yylex();
return 0;
}
int yywrap() { return 1; }
~~~
* 第二段中的 main 函数是程序的入口, flex 会将这些代码原样的复制到 lex.yy.c 文件的最后面。最后一行的 yywrap 函数, flex 要求有这么一个函数。
#### 2.1.4.3 示例
* word-spliter.l
~~~
%{
#define T_WORD 1
int numChars = 0, numWords = 0, numLines = 0;
%}
WORD ([^ \t\n\r\a]+)
%%
\n { numLines++; numChars++; }
{WORD} { numWords++; numChars += yyleng; return T_WORD; }
<<EOF>> { return 0; }
. { numChars++; }
%%
int main() {
int token_type;
while (token_type = yylex()) {
printf("WORD:\t%s\n", yytext);
}
printf("\nChars\tWords\tLines\n");
printf("%d\t%d\t%d\n", numChars, numWords, numLines);
return 0;
}
int yywrap() {
return 1;
}
~~~
本例中使用到了 flex 提供的两个全局变量 yytext 和 yyleng,分别用来表示刚刚匹配到的字符串以及它的长度
* 编译执行
~~~
flex word-spliter.l
gcc -o word-spliter lex.yy.c
./word-spliter < word-spliter.l
输出:
WORD: %{
WORD: #define
...
WORD: }
Chars Words Lines
470 70 27
~~~
可见此程序其实就是一个原始的分词器,它将输入文件分割成一个个的 WORD 再输出到终端,同时统计输入文件中的字符数、单词数和行数。此处的 WORD 指一串连续的非空格字符。
* 扩展
(1) 列出所需的所有类型的 token;
(2) 为每种类型的 token 分配一个唯一的编号,同时写出此 token 的正则表达式;
(3) 写出每种 token 的 rule (相应的 pattern 和 action )。
第 1 类为单字符运算符,一共 15 种:
~~~
+ * - / % = , ; ! < > ( ) { }
~~~
第 2 类为双字符运算符和关键字,一共 16 种:
~~~
<=, >=, ==, !=, &&, ||
void, int, while, if, else, return, break, continue, print, readint
~~~
第 3 类为整数常量、字符串常量和标识符(变量名和函数名),一共 3 种。
* 拓展后
~~~
%{
#include "token.h"
int cur_line_num = 1;
void init_scanner();
void lex_error(char* msg, int line);
%}
/* Definitions, note: \042 is '"' */
INTEGER ([0-9]+)
UNTERM_STRING (\042[^\042\n]*)
STRING (\042[^\042\n]*\042)
IDENTIFIER ([_a-zA-Z][_a-zA-Z0-9]*)
OPERATOR ([+*-/%=,;!<>(){}])
SINGLE_COMMENT1 ("//"[^\n]*)
SINGLE_COMMENT2 ("#"[^\n]*)
%%
[\n] { cur_line_num++; }
[ \t\r\a]+ { /* ignore all spaces */ }
{SINGLE_COMMENT1} { /* skip for single line comment */ }
{SINGLE_COMMENT2} { /* skip for single line commnet */ }
{OPERATOR} { return yytext[0]; }
"<=" { return T_Le; }
">=" { return T_Ge; }
"==" { return T_Eq; }
"!=" { return T_Ne; }
"&&" { return T_And; }
"||" { return T_Or; }
"void" { return T_Void; }
"int" { return T_Int; }
"while" { return T_While; }
"if" { return T_If; }
"else" { return T_Else; }
"return" { return T_Return; }
"break" { return T_Break; }
"continue" { return T_Continue; }
"print" { return T_Print; }
"readint" { return T_ReadInt; }
{INTEGER} { return T_IntConstant; }
{STRING} { return T_StringConstant; }
{IDENTIFIER} { return T_Identifier; }
<<EOF>> { return 0; }
{UNTERM_STRING} { lex_error("Unterminated string constant", cur_line_num); }
. { lex_error("Unrecognized character", cur_line_num); }
%%
int main(int argc, char* argv[]) {
int token;
init_scanner();
while (token = yylex()) {
print_token(token);
puts(yytext);
}
return 0;
}
void init_scanner() {
printf("%-20s%s\n", "TOKEN-TYPE", "TOKEN-VALUE");
printf("-------------------------------------------------\n");
}
void lex_error(char* msg, int line) {
printf("\nError at line %-3d: %s\n\n", line, msg);
}
int yywrap(void) {
return 1;
}
~~~
上面这个文件中,需要注意的是,正则表达式中,用双引号括起来的字符串就是原始字符串,里面的特殊字符是不需要转义的,而双引号本身必须转义(必须用 \\” 或 \\042 ),这是 flex 中不同于常规的正则表达式的一个特性。
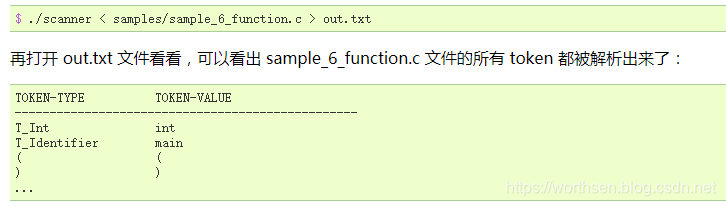
除单字符运算符外的 token 的编号则在下面这个 token.h 文件,该文件中同时提供了一个 print\_token 函数,可以根据 token 的编号打印其名称。
~~~
#ifndef TOKEN_H
#define TOKEN_H
typedef enum {
T_Le = 256, T_Ge, T_Eq, T_Ne, T_And, T_Or, T_IntConstant,
T_StringConstant, T_Identifier, T_Void, T_Int, T_While,
T_If, T_Else, T_Return, T_Break, T_Continue, T_Print,
T_ReadInt
} TokenType;
static void print_token(int token) {
static char* token_strs[] = {
"T_Le", "T_Ge", "T_Eq", "T_Ne", "T_And", "T_Or", "T_IntConstant",
"T_StringConstant", "T_Identifier", "T_Void", "T_Int", "T_While",
"T_If", "T_Else", "T_Return", "T_Break", "T_Continue", "T_Print",
"T_ReadInt"
};
if (token < 256) {
printf("%-20c", token);
} else {
printf("%-20s", token_strs[token-256]);
}
}
#endif
~~~
* makefile
~~~
out: scanner
scanner: lex.yy.c token.h
gcc -o $@ $<
lex.yy.c: scanner.l
flex $<
~~~
## 2.2 语法分析
### 2.2.1 上下文无关语法
> * 上下文无关文法可以采用递归的形式推导,比正则表达式的表达能力要强大的多。
> * 为什么要把这种语法称为上下文本无关语法呢?这是由其产生式的固定形式 A -> u 所决定的,事实上,还有所谓的上下文有关语法,其产生式的形式为 v A w -> v u w ,也就是说只有 A 的上下文分别为 v 和 w 时,才能应用该产生式。上下文本无关语法其实是上下文有关语法中的一种特例,也就是 v 和 w 分别为空串时的特例。
~~~
终结符集合 T (terminal set) : 一个有限集合,其元素称为 终结符(terminal) 。
非终结符集合 N (non-terminal set) : 一个有限集合,与 T 无公共元素,其元素称为 非终结符(non-terminal) 。
符号集合 V (alphabet) : T 和 N 的并集,其元素称为 符号(symbol) 。因此终结符和非终结符都是符号。符号可用字母:A, B, C, X, Y, Z, a, b, c 等表示。
符号串(a string of symbols) : 一串符号,如 X1 X2 ... Xn 。只有终结符的符号串称为 句子(sentence)。 空串 (不含任何符号)也是一个符号串,用 ε 表示。符号串一般用小写字母 u, v, w 表示。
产生式(production) : 一个描述符号串如何转换的规则。对于上下文本无关语法,其固定形式为: A -> u ,其中 A 为非终结符, u 为一个符号串。
产生式集合 P (production set) : 一个由有限个产生式组成的集合。
展开(expand) : 一个动作:将一个产生式 A -> u 应用到一个含有 A 的符号串 vAw 上,用 u 代替该符号串中的 A ,得到一个新的符号串 vuw 。
折叠(reduce) : 一个动作:将一个产生式 A -> u 应用到一个含有 u 的符号串 vuw 上,用 A 代替该符号串中的 u ,得到一个新的符号串 vAw 。
起始符号 S (start symbol) : N 中的一个特定的元素。
推导(derivate) : 一个过程:从一个符号串 u 开始,应用一系列的产生式,展开到另一个的符号串 v。若 v 可以由 u 推导得到,则可写成: u => v 。
上下文本无关语法 G (context-free grammar, CFG) : 一个 4 元组: (T, N, P, S) ,其中 T 为终结符集合, N 为非终结符集合, P 为产生式集合, S 为起始符号。一个句子如果能从语法 G 的 S 推导得到,可以直接称此句子由语法 G 推导得到,也可称此句子符合这个语法,或者说此句子属于 G 语言。 G 语言( G language) 就是语法 G 推导出来的所有句子的集合,有时也用 G 代表这个集合。
解析(parse) : 也称为分析,是一个过程:给定一个句子 s 和语法 G ,判断 s 是否属于 G ,如果是,则找出从起始符号推导得到 s 的全过程。推导过程中的任何符号串(包括起始符号和最终的句子)都称为 中间句子(working string) 。
~~~
一个上下文无关语法 G 就是由一个终结符集合 T ,一个非终结符集合 N ( N 和 T 不相交),一个产生式集合 P ,以及一个起始符号 S (S ∈ N)组成。由语法 G 推导(产生)出来的所有的句子的集合称为 G 语言。因此一个语法可以代表一个句子集合,也就是一个语言。
终结符和非终结符统称为符号,符号一般用字母 A, B, X, Y, a, b 表示,符号串一般用小写字母 u, v 表示。产生式的形式为 A -> u ,其中 A 为非终结符, u 为一个符号串。
下面再来看一个例子:
~~~
S –> AB
A –> aA | ε
B –> b | bB
~~~
这里面的第二行中的 ε 表示一个空句子,表示 A 可以用一个空句子来代替。
经过观察可知,这个语法所能推导出的所有句子的集合为:
~~~
A : { ε, a, aa, aaa, ... }
B : { b, bb, bbb, ... }
S : { b, bb, bbb, ..., ab, abb, ..., aab, aabb, ... }
~~~
因此 S 相当于正则表达式 a\*b+ 。
再来看一个稍微复杂的例子:
~~~
Expr -> Expr op Expr | (Expr) | number
op -> + - * /
~~~
其中的 number 是词法分析得到的一个 token ,它在词法分析中用正则表达式 \[0-9\]+ 表示。
经过观察可知,此语法可以推导出所有的整数算术表达式:
~~~
Expr : { 123, 25 + 24, 78 - 34, 12 * ( 23 + 9 ), ... }
~~~
可以看出,上下文无关文法可以采用递归的形式推导,比正则表达式的表达能力要强大的多。
### 2.2.2 分析树和抽象语法树
> 语法分析不但要判断给定的句子是否符合语法结构,而且还要分析出该句子符合哪些结构
以上面表达式语法为例,给定一个句子 12 + 53 ,经过观察,发现此句子可以按以下方式被推导出来:
~~~
Expr ==> Expr + Expr ==> number + Expr ==> number + number ==> 12 + 53
~~~
以上推导过程可以用分析树来表示:
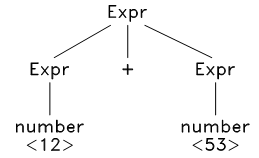
再看一个稍微长的句子: 12 + ( 53 - 7 ) ,其分析树如下:
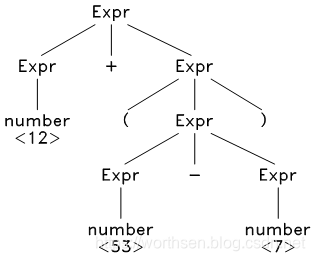
可以去掉此分析树中一些多余的节点,并进一步浓缩,得到抽象语法树:
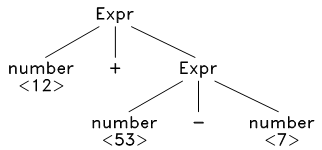
对于这种树状结构,可以采用递归的方式加以分析,从而生成目标代码。
再看一个句子: 12 + 53 \* 7 ,这时候问题来了,我们发现它可以由两种不同的方式推导出来:
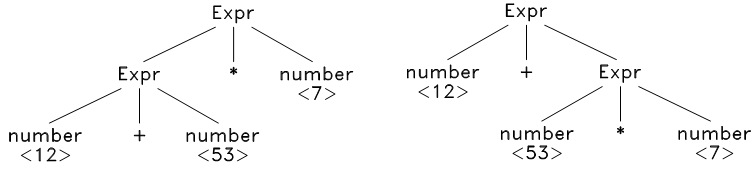
这就是语法的歧义性,所谓**歧义**(ambiguity),就是指对于一个符合语法结构的句子,它可以由两种不同的方式被推导出来。
消除歧义的方法之一是改写语法,将有歧义的产生式改写成无歧义的,这种改写非常困难,而且改写后的产生式往往和原产生式相差很大,可读性非常差。另一种方法就是引入 优先级 ,不需要改写语法,当推导过程中出现歧义的时候(也就是出现两种不同的推导方式的时候),利用符号的优先级来选择需要的推导方式
### 2.2.3 分析方法简介
分析可以采用 自顶向下分析 或 自底向上分析 两种方法。
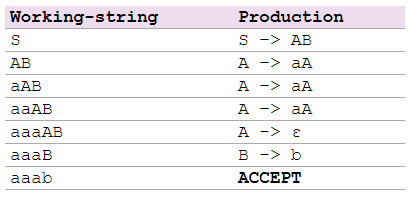
* 自顶向下分析
**自顶向下分析就是从起始符号开始,不断的挑选出合适的产生式,将中间句子中的非终结符的展开,最终展开到给定的句子。**
~~~
S –> AB
A –> aA | ε
B –> b | bB
~~~

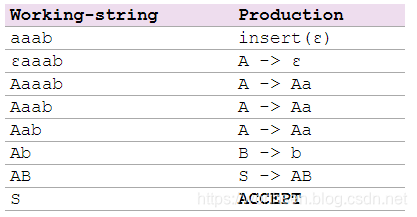
* 自底向上分析
**自底向上分析的顺序和自顶向下分析的顺序刚好相反,从给定的句子开始,不断的挑选出合适的产生式,将中间句子中的子串折叠为非终结符,最终折叠到起始符号。**
~~~
S –> AB
A –> Aa | ε
B –> b | bB
~~~

### 2.2.4 自顶向下分析
* **LL(1) 分析法**是一种自顶向下分析方法,它通过精心构造语法规则而使得每个推导步可以直接挑选出合适的产生式。
* LL(1) 分析法的优点
不需要回溯,构造方法较简单,且分析速度非常快,每读到第一个符号就可以预测出整个产生式来。
* LL(1) 分析法的缺点
**对语法的限制太强**,它要求同一个非终结符的不同产生式的首字符集合互不相交,能满足此要求的语法相当少,而将一个不满足此要求的语法改写到满足要求也相当不容易。因此, LL(1) 分析法目前已经应用的比较少了。
### 2.2.5 自底向上分析
* 自底向上分析法的解析力量比自顶向下分析法要**强大**的多,和自顶向下分析法相比,它可以解析更为复杂、更为广泛的语法。但自底向上分析法的构造过程也复杂的多, LL(1) 法程序的手写难度不大,但自底向上分析法程序的手写难度却相当之大。幸运的是,目前有一些非常强大的分析器构造工具(如**bison**),可以将用户定义的语法规则转化成一个自底向上分析器,使得编写语法分析器变得非常简单。
* 典型的自底向上分析法有**LR 分析法**。
* LR(1) 的构造过程用代码来实现这个构造流程还是很不容易的,不过已经有了非常优秀的工具可以利用了,那就是 bison。
### 2.2.6 用 bison 做词法分析
#### 2.2.6.1 介绍
bison 读取用户提供的语法的产生式,生成一个 C 语言格式的 LALR(1) 动作表,并将其包含进一个名为 yyparse 的 C 函数,这个函数的作用就是利用这个动作表来解析 token stream ,而这个 token stream 是由 flex 生成的词法分析器扫描源程序得到。
#### 2.2.6.2 用法
* 安装bison
~~~
sudo apt-get install bison
或者下载相应版本的安装文件安装
~~~
* 安装完成后,新建一个文本文件,输入以下内容:
~~~
%{
#include "y.tab.h"
%}
%%
[0-9]+ { yylval = atoi(yytext); return T_NUM; }
[-/+*()\n] { return yytext[0]; }
. { return 0; /* end when meet everything else */ }
%%
int yywrap(void) {
return 1;
}
~~~
将此文件另存为 calc.l 。注意此文件中的 %% 、 %{ 、 %} 的前面不能有任何空格。
* 再新建一个文本文件,输入以下内容:
~~~
%{
#include <stdio.h>
void yyerror(const char* msg) {}
%}
%token T_NUM
%left '+' '-'
%left '*' '/'
%%
S : S E '\n' { printf("ans = %d\n", $2); }
| /* empty */ { /* empty */ }
;
E : E '+' E { $$ = $1 + $3; }
| E '-' E { $$ = $1 - $3; }
| E '*' E { $$ = $1 * $3; }
| E '/' E { $$ = $1 / $3; }
| T_NUM { $$ = $1; }
| '(' E ')' { $$ = $2; }
;
%%
int main() {
return yyparse();
}
~~~
将此文件另存为 calc.y 。注意此文件中的 %% 、 %{ 、 %} 的前面也不能有任何空格。
* 将前面两个文件都放在终端的当前目录,再在终端输入:
~~~
bison -vdty calc.y
~~~
此时可以发现终端下多了三个文件: y.tab.h, y.tab.c, y.output 。
* 再在终端输入:
~~~
flex calc.l
~~~
此时终端下又多了一个文件: lex.yy.c 。
* 最后将 y.tab.c 和 lex.yy.c 一起编译并运行一遍:
~~~
gcc -o calc y.tab.c lex.yy.c
./calc
~~~
* 然后在终端输入算术表达式并回车:
~~~
1+2+3
ans = 6
2*(2+7)+8
ans = 26
~~~
可以发现回车后,终端会自动输出算术表达式的结果。这个程序就是一个简单的支持加、减、乘、除以及括号的整数计算器。想象一下,如果用 C 语言手工编写一个同样功能的程序,那代码量肯定很大吧。
#### 2.2.6.2 示例
* 词法分析文件: scanner.l
~~~
%{
#define YYSTYPE char *
#include "y.tab.h"
int cur_line = 1;
void yyerror(const char *msg);
void unrecognized_char(char c);
void unterminate_string();
#define _DUPTEXT {yylval = strdup(yytext);}
%}
/* note \042 is '"' */
WHITESPACE ([ \t\r\a]+)
SINGLE_COMMENT1 ("//"[^\n]*)
SINGLE_COMMENT2 ("#"[^\n]*)
OPERATOR ([+*-/%=,;!<>(){}])
INTEGER ([0-9]+)
IDENTIFIER ([_a-zA-Z][_a-zA-Z0-9]*)
UNTERM_STRING (\042[^\042\n]*)
STRING (\042[^\042\n]*\042)
%%
\n { cur_line++; }
{WHITESPACE} { /* ignore every whitespace */ }
{SINGLE_COMMENT1} { /* skip for single line comment */ }
{SINGLE_COMMENT2} { /* skip for single line comment */ }
{OPERATOR} { return yytext[0]; }
"int" { return T_Int; }
"void" { return T_Void; }
"return" { return T_Return; }
"print" { return T_Print; }
"readint" { return T_ReadInt; }
"while" { return T_While; }
"if" { return T_If; }
"else" { return T_Else; }
"break" { return T_Break; }
"continue" { return T_Continue; }
"<=" { return T_Le; }
">=" { return T_Ge; }
"==" { return T_Eq; }
"!=" { return T_Ne; }
"&&" { return T_And; }
"||" { return T_Or; }
{INTEGER} { _DUPTEXT return T_IntConstant; }
{STRING} { _DUPTEXT return T_StringConstant; }
{IDENTIFIER} { _DUPTEXT return T_Identifier; }
{UNTERM_STRING} { unterminate_string(); }
. { unrecognized_char(yytext[0]); }
%%
int yywrap(void) {
return 1;
}
void unrecognized_char(char c) {
char buf[32] = "Unrecognized character: ?";
buf[24] = c;
yyerror(buf);
}
void unterminate_string() {
yyerror("Unterminate string constant");
}
void yyerror(const char *msg) {
fprintf(stderr, "Error at line %d:\n\t%s\n", cur_line, msg);
exit(-1);
}
~~~
* 语法分析文件: parser.y
~~~
%{
#include <stdio.h>
#include <stdlib.h>
void yyerror(const char*);
#define YYSTYPE char *
int ii = 0, itop = -1, istack[100];
int ww = 0, wtop = -1, wstack[100];
#define _BEG_IF {istack[++itop] = ++ii;}
#define _END_IF {itop--;}
#define _i (istack[itop])
#define _BEG_WHILE {wstack[++wtop] = ++ww;}
#define _END_WHILE {wtop--;}
#define _w (wstack[wtop])
%}
%token T_Int T_Void T_Return T_Print T_ReadInt T_While
%token T_If T_Else T_Break T_Continue T_Le T_Ge T_Eq T_Ne
%token T_And T_Or T_IntConstant T_StringConstant T_Identifier
%left '='
%left T_Or
%left T_And
%left T_Eq T_Ne
%left '<' '>' T_Le T_Ge
%left '+' '-'
%left '*' '/' '%'
%left '!'
%%
Program:
/* empty */ { /* empty */ }
| Program FuncDecl { /* empty */ }
;
FuncDecl:
RetType FuncName '(' Args ')' '{' VarDecls Stmts '}'
{ printf("ENDFUNC\n\n"); }
;
RetType:
T_Int { /* empty */ }
| T_Void { /* empty */ }
;
FuncName:
T_Identifier { printf("FUNC @%s:\n", $1); }
;
Args:
/* empty */ { /* empty */ }
| _Args { printf("\n\n"); }
;
_Args:
T_Int T_Identifier { printf("\targ %s", $2); }
| _Args ',' T_Int T_Identifier
{ printf(", %s", $4); }
;
VarDecls:
/* empty */ { /* empty */ }
| VarDecls VarDecl ';' { printf("\n\n"); }
;
VarDecl:
T_Int T_Identifier { printf("\tvar %s", $2); }
| VarDecl ',' T_Identifier
{ printf(", %s", $3); }
;
Stmts:
/* empty */ { /* empty */ }
| Stmts Stmt { /* empty */ }
;
Stmt:
AssignStmt { /* empty */ }
| PrintStmt { /* empty */ }
| CallStmt { /* empty */ }
| ReturnStmt { /* empty */ }
| IfStmt { /* empty */ }
| WhileStmt { /* empty */ }
| BreakStmt { /* empty */ }
| ContinueStmt { /* empty */ }
;
AssignStmt:
T_Identifier '=' Expr ';'
{ printf("\tpop %s\n\n", $1); }
;
PrintStmt:
T_Print '(' T_StringConstant PActuals ')' ';'
{ printf("\tprint %s\n\n", $3); }
;
PActuals:
/* empty */ { /* empty */ }
| PActuals ',' Expr { /* empty */ }
;
CallStmt:
CallExpr ';' { printf("\tpop\n\n"); }
;
CallExpr:
T_Identifier '(' Actuals ')'
{ printf("\t$%s\n", $1); }
;
Actuals:
/* empty */ { /* empty */ }
| Expr PActuals { /* empty */ }
;
ReturnStmt:
T_Return Expr ';' { printf("\tret ~\n\n"); }
| T_Return ';' { printf("\tret\n\n"); }
;
IfStmt:
If TestExpr Then StmtsBlock EndThen EndIf
{ /* empty */ }
| If TestExpr Then StmtsBlock EndThen Else StmtsBlock EndIf
{ /* empty */ }
;
TestExpr:
'(' Expr ')' { /* empty */ }
;
StmtsBlock:
'{' Stmts '}' { /* empty */ }
;
If:
T_If { _BEG_IF; printf("_begIf_%d:\n", _i); }
;
Then:
/* empty */ { printf("\tjz _elIf_%d\n", _i); }
;
EndThen:
/* empty */ { printf("\tjmp _endIf_%d\n_elIf_%d:\n", _i, _i); }
;
Else:
T_Else { /* empty */ }
;
EndIf:
/* empty */ { printf("_endIf_%d:\n\n", _i); _END_IF; }
;
WhileStmt:
While TestExpr Do StmtsBlock EndWhile
{ /* empty */ }
;
While:
T_While { _BEG_WHILE; printf("_begWhile_%d:\n", _w); }
;
Do:
/* empty */ { printf("\tjz _endWhile_%d\n", _w); }
;
EndWhile:
/* empty */ { printf("\tjmp _begWhile_%d\n_endWhile_%d:\n\n",
_w, _w); _END_WHILE; }
;
BreakStmt:
T_Break ';' { printf("\tjmp _endWhile_%d\n", _w); }
;
ContinueStmt:
T_Continue ';' { printf("\tjmp _begWhile_%d\n", _w); }
;
Expr:
Expr '+' Expr { printf("\tadd\n"); }
| Expr '-' Expr { printf("\tsub\n"); }
| Expr '*' Expr { printf("\tmul\n"); }
| Expr '/' Expr { printf("\tdiv\n"); }
| Expr '%' Expr { printf("\tmod\n"); }
| Expr '>' Expr { printf("\tcmpgt\n"); }
| Expr '<' Expr { printf("\tcmplt\n"); }
| Expr T_Ge Expr { printf("\tcmpge\n"); }
| Expr T_Le Expr { printf("\tcmple\n"); }
| Expr T_Eq Expr { printf("\tcmpeq\n"); }
| Expr T_Ne Expr { printf("\tcmpne\n"); }
| Expr T_Or Expr { printf("\tor\n"); }
| Expr T_And Expr { printf("\tand\n"); }
| '-' Expr %prec '!' { printf("\tneg\n"); }
| '!' Expr { printf("\tnot\n"); }
| T_IntConstant { printf("\tpush %s\n", $1); }
| T_Identifier { printf("\tpush %s\n", $1); }
| ReadInt { /* empty */ }
| CallExpr { /* empty */ }
| '(' Expr ')' { /* empty */ }
;
ReadInt:
T_ReadInt '(' T_StringConstant ')'
{ printf("\treadint %s\n", $3); }
;
%%
int main() {
return yyparse();
}
~~~
* makefile 文件: makefile
~~~
OUT = tcc
TESTFILE = test.c
SCANNER = scanner.l
PARSER = parser.y
CC = gcc
OBJ = lex.yy.o y.tab.o
TESTOUT = $(basename $(TESTFILE)).asm
OUTFILES = lex.yy.c y.tab.c y.tab.h y.output $(OUT)
.PHONY: build test simulate clean
build: $(OUT)
test: $(TESTOUT)
simulate: $(TESTOUT)
python pysim.py $< -a
clean:
rm -f *.o $(OUTFILES)
$(TESTOUT): $(TESTFILE) $(OUT)
./$(OUT) < $< > $@
$(OUT): $(OBJ)
$(CC) -o $(OUT) $(OBJ)
lex.yy.c: $(SCANNER) y.tab.c
flex $<
y.tab.c: $(PARSER)
bison -vdty $<
~~~
* 测试文件: test.c
~~~
#include "for_gcc_build.hh" // only for gcc, TinyC will ignore it.
int main() {
int i;
i = 0;
while (i < 10) {
i = i + 1;
if (i == 3 || i == 5) {
continue;
}
if (i == 8) {
break;
}
print("%d! = %d", i, factor(i));
}
return 0;
}
int factor(int n) {
if (n < 2) {
return 1;
}
return n * factor(n - 1);
}
~~~
# 3 TinyC 编译器要点
## 3.1 编译器的工作流程图
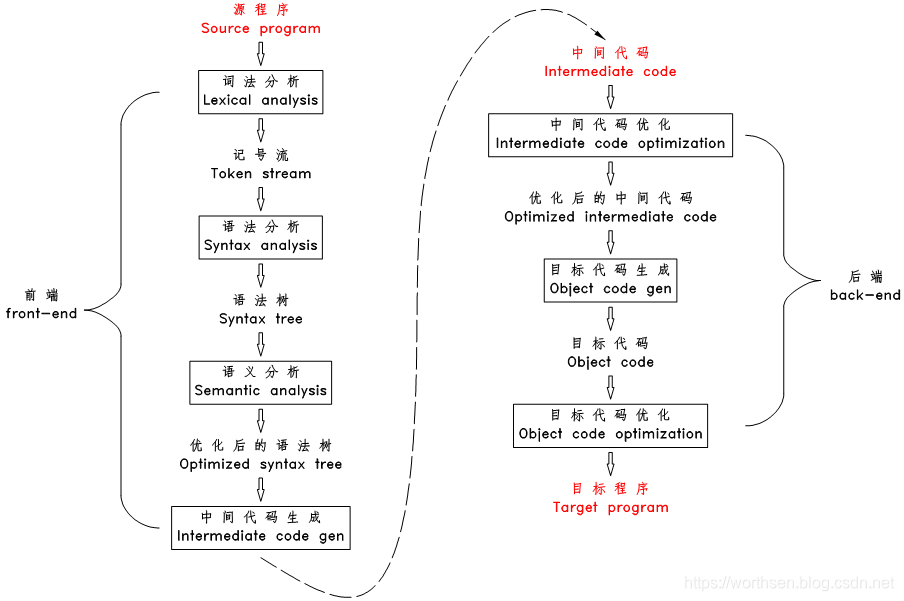
## 3.2 编译器的工作流程
### 3.2.1 词法分析
编译器扫描源文件的字符流,过滤掉字符流中的空格、注释等,并将其分割为一个个的词(或称为记号、token,下文中都将称为 token )
eg:
~~~
a = value + sum(5, 123);
~~~
被拆分为11个 token
~~~
a 标识符
= 赋值运算符
value 标识符
+ 加号
sum 标识符
( 左括号
5 整数
, 逗号
123 整数
) 右括号
; 分号
~~~
### 3.2.2 语法分析
> 根据语法规则将这些记号构造出**语法树**
词法分析完成后,上面的字符流就被转换为 token 流了
~~~
ID<a> '=' ID<value> '+' ID<sum> '(' NUM<5> ',' NUM<123> ')' ';'
~~~
上面的 ID 表示这一个标识符类型的 token ,其内容为 a。
接下来,根据语言的语法规则来解析这个 token 流。首先,这是一个语句。而TinyC 中只有四种语句:赋值语句,函数调用语句, if 语句和 while 语句。把这四种语句的语法结构和这个 token 流对比一下发现只有赋值语句的结构才能和它匹配:
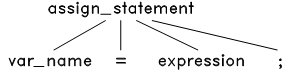
于是将此语法结构应用到 token 流上,把源程序的等号两边的内容分别放在该语法结构树的对应节点上,生成语法树如下:
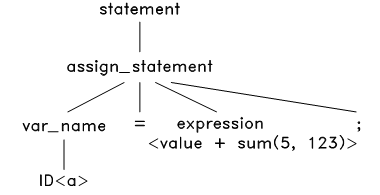
接下来,对这个语法树上的 expresion 进行解析。TinyC中的表达式有很多种,包括:变量表达式、数字表达式、加法表达式、减法表达式等等。经过对比,发现只有加法表达式的结构才能匹配这个 ,于是将加法表达式的语法结构应用到此表达式上,生成:
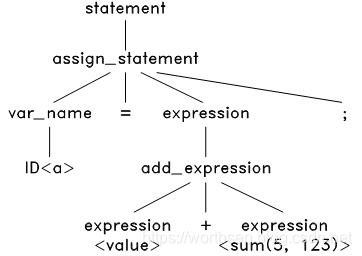
然后,解析这个语法树上的 和 ,经过对比,发现只有变量表达式和函数调用表达式的结构能匹配成功,应用后,得到:
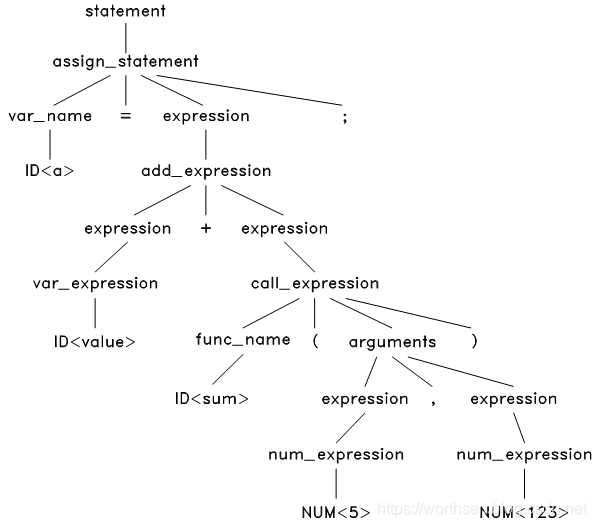
这个语法树中,有些节点是可以去掉的,如 assign expression 中的 ‘=’ 和 ‘;’ ,既然我们已经知道这是一个赋值表达式,那么这两个节点是不必要的了,我们去掉这样的节点,同时对语法树进一步浓缩,可以得到最终的抽象语法树
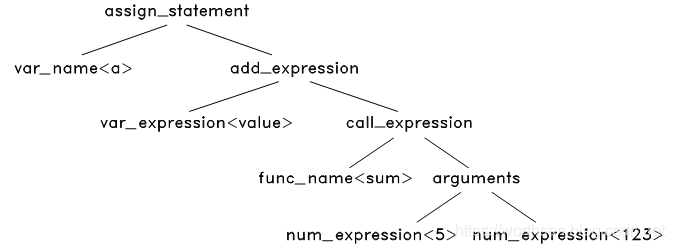
### 3.2.3 语义分析
> 对语法树的各个节点之间的关系进行检查,检查语义规则是否被违背,同时对语法树进行必要的优化
语义分析阶段,编译器开始对语法树进行一次或多次的遍历,检查程序的语义规则。主要包括声明检查和类型检查,如上一个赋值语句中,就需要检查:
* 语句中的变量 a 和 value 、函数 sum 是否被声明过
* sum 函数的参数数量和类型是否与其声明的参数数量及类型匹配
* 加号运算的两个操作数的类型是否匹配(sum 函数的返回值类型是否和变量 value 匹配)
* 赋值运算符两边的操作数的类型是否匹配
语义检查时,也会对语法树进行一些优化,比如将只含常量的表达式先计算出来,如:
~~~
a = 1 + 2 * 9;
会被优化成:
a = 19;
~~~
语义分析完成后,源程序的结构解析完成,所有编译期错误都已被排除,所有使用到的变量名和函数名都绑定到其声明位置(地址)了,至此编译器可以说是真正理解了源程序,可以开始进行代码生成和代码优化了。
### 3.2.4 中间代码生成
> 遍历语法树的节点,将各节点转化为中间代码,并按特定的顺序拼装起来
一般的编译器并不直接生成目标代码,而是先生成某种中间代码,然后再生成目标代码。生成中间代码
* 一个是为了降低编译器开发的难度,中间代码既有部分高级语言特性、又有接近机器语言操作的中间代码,将高级语言翻译成中间代码、将此中间代码再翻译成目标代码的难度都比直接将高级语言翻译成目标代码的难度要低。
* 二是为了增加编译器的模块化、可移植性和可扩展性,一般来说,中间代码既独立于任何高级语言,也独立于任何目标机器架构,这就为开发出适应性广泛的编译器提供了媒介。
* 三是为了代码优化,一般来说,计算机直接生成的代码比人手写的汇编要庞大、重复很多,计算机科学家们对一些具有固定格式的中间代码(最典型的是三地址中间码)的进行大量的研究工作,提出了很多广泛应用的、效率非常高的优化算法,可以对中间代码进行优化,比直接对目标代码进行优化的效果要好很多。
以上述语法树为例说明中间代码生成的方法
~~~
首先从根节点 assign_statement 开始:
GEN_CODE( assign_statement<a = value + sum(5, 123);> )
对于赋值语句,先将其右边的表达式翻译成 Pcode ,再在最后加一个 pop var_name 就可以了,如下:
GEN_CODE( add_expression<value + sum(5, 123)> )
pop a
对于加法表达式,将两个操作符翻译成 Pcode ,再加上 add ,如下:
GEN_CODE( var_expression<value> )
GEN_CODE( call_expression<sum(5, 123)> )
add
pop a
对于变量表达式,直接翻译成 push var_name ,对于函数调用表达式,将其参数翻译成 Pcode ,再加上 $func_name,如下:
push value
GEN_CODE( arguments<5, 123> )
$sum
add
pop a
最后将各参数翻译成 Pcode ,最终得到:
push value
push 5
push 123
$sum
add
pop a
~~~
从以上过程可以看出,代码生成的算法是一个递归的算法,递归的遍历语法树,将语法树上的一些节点替换成中间代码块,再根据特定的规则和顺序将这些中间代码块拼装起来。
### 3.2.5 中间代码优化
在本阶段,编译器对中间代码进行优化,尝试生成体积最小、最快、最有效率的代码。常见的优化方法有:
* 去除永远都不会被执行的代码区
* 去掉未被使用到的变量
* 优化循环体,将每次循环中的运行结果不变的语句移到循环的最外面
* 算术表达式优化,将乘 1 和 加 0 等操作去掉,将乘 2 优化成左移 1 位等
### 3.2.6 目标代码生成
编译器根据中间代码和目标机器架构生成目标代码,由于大部分中间代码接近低级语言,这一步的难度较低。比如 Pcode 中,很多 Pcode 命令可以用一组 x86 指令代替,如:
~~~
; ------------------------------------------------
; Pcode
push 3
; x86
PUSH DWORD 3
; ------------------------------------------------
; Pcode
push a
; x86
PUSH DWORD [EBP - 12] ; 假定a的地址为 EBP - 12
; ------------------------------------------------
; Pcode
add
; x86
POP EAX
ADD [ESP], EAX
~~~
### 3.2.7 目标代码优化
* 本阶段,编译器利用目标机器的提供的特性对目标代码做进一步的优化,如利用 CPU 的流水线,利用 CPU 的多核等,生成最终的目标代码。
### 3.2.8 编译过程的错误检查
* 在词法、语法和语义分析的过程中,都伴随着错误检查,词法错误主要是字符错误(如非法字符、未结束的注释、未结束的字符串等),语法错误主要是格式错误(如语句后未加分号、不匹配的括号等),最常发生的是语义错误(如变量名错误、表达式类型错误、函数参数不匹配等)。编译器不仅检查错误,还需要精确定位出错误发生的位置,协助编程人员修改。
* 错误检查和代码优化是编译器中两个很重要的步骤,也是最难实现的部分,前者定位出所有的编译期错误所在,协助程序员写出正确的程序,后者则保证生成高效的目标程序,这两点是早期编译器获得广泛接受的基石。
### 3.2.9 编译器的遍数
从词法分析到语法分析生成语法树一般只需要对源文件进行一遍扫描就可以了,生成语法树后,语义检查、代码优化的过程中可能需要对语法树进行反复的遍历,5 、 6 遍,甚至 8 遍都是有可能的。但有些语言(如 C 语言)也可能 1 遍就编译完成,其语义检查和代码生成可以在语法分析的同时同步进行,此时一般无任何代码优化。
- 序
- 第1章 Linux下开发FPGA
- 1.1 Linux下安装diamond
- 1.2 使用轻量级linux仿真工具iverilog
- 1.3 使用linux shell来读写串口
- 1.4 嵌入式上的linux
- 设备数教程
- linux C 标准库文档
- linux 网络编程
- 开机启动流程
- 1.5 linux上实现与树莓派,FPGA等通信的串口脚本
- 第2章 Intel FPGA的使用
- 2.1 特别注意
- 2.2 高级应用开发流程
- 2.2.1 生成二进制bit流rbf
- 2.2.2 制作Preloader Image
- 2.2.2.1 生成BSP文件
- 2.2.2.2 编译preloader和uboot
- 2.2.2.3 更新SD的preloader和uboot
- 2.3 HPS使用
- 2.3.1 通过JTAG下载代码
- 2.3.2 HPS软件部分开发
- 2.3 quartus中IP核的使用
- 2.3.1 Intel中RS232串口IP的使用
- 2.4 一些问题的解决方法
- 2.4.1 关于引脚的复用的综合出错
- 第3章 关于C/C++的一些语法
- 3.1 C中数组作为形参不传长度
- 3.2 汇编中JUMP和CALL的区别
- 3.3 c++中map的使用
- 3.4 链表的一些应用
- 3.5 vector的使用
- 3.6 使用C实现一个简单的FIFO
- 3.6.1 循环队列
- 3.7 C语言不定长参数
- 3.8 AD采样计算同频信号的相位差
- 3.9 使用C实现栈
- 3.10 增量式PID
- 第4章 Xilinx的FPGA使用
- 4.1 Alinx使用中的一些问题及解决方法
- 4.1.1 在Genarate Bitstream时提示没有name.tcl
- 4.1.2 利用verilog求位宽
- 4.1.3 vivado中AXI写DDR说明
- 4.1.4 zynq中AXI GPIO中断问题
- 4.1.5 关于时序约束
- 4.1.6 zynq的PS端利用串口接收电脑的数据
- 4.1.7 SDK启动出错的解决方法
- 4.1.8 让工具综合是不优化某一模块的方法
- 4.1.9 固化程序(双核)
- 4.1.10 分配引脚时的问题
- 4.1.11 vivado仿真时相对文件路径的问题
- 4.2 GCC使用Attribute分配空间给变量
- 4.3 关于Zynq的DDR写入byte和word的方法
- 4.4 常用模块
- 4.4.1 I2S接收串转并
- 4.5 时钟约束
- 4.5.1 时钟约束
- 4.6 VIVADO使用
- 4.6.1 使用vivado进行仿真
- 4.7 关于PicoBlaze软核的使用
- 4.8 vivado一些IP的使用
- 4.8.1 float-point浮点单元的使用
- 4.10 zynq的双核中断
- 第5章 FPGA的那些好用的工具
- 5.1 iverilog
- 5.2 Arduino串口绘图器工具
- 5.3 LabVIEW
- 5.4 FPGA开发实用小工具
- 5.5 Linux下绘制时序图软件
- 5.6 verilog和VHDL相互转换工具
- 5.7 linux下搭建轻量易用的verilog仿真环境
- 5.8 VCS仿真verilog并查看波形
- 5.9 Verilog开源的综合工具-Yosys
- 5.10 sublim text3编辑器配置verilog编辑环境
- 5.11 在线工具
- 真值表 -> 逻辑表达式
- 5.12 Modelsim使用命令仿真
- 5.13 使用TCL实现的个人仿真脚本
- 5.14 在cygwin下使用命令行下载arduino代码到开发板
- 5.15 STM32开发
- 5.15.1 安装Atollic TrueSTUDIO for STM32
- 5.15.2 LED闪烁吧
- 5.15.3 模拟U盘
- 第6章 底层实现
- 6.1 硬件实现加法的流程
- 6.2 硬件实现乘法器
- 6.3 UART实现
- 6.3.1 通用串口发送模块
- 6.4 二进制数转BCD码
- 6.5 基本开源资源
- 6.5.1 深度资源
- 6.5.2 FreeCore资源集合
- 第7章 常用模块
- 7.1 温湿度传感器DHT11的verilog驱动
- 7.2 DAC7631驱动(verilog)
- 7.3 按键消抖
- 7.4 小脚丫数码管显示
- 7.5 verilog实现任意人数表决器
- 7.6 基本模块head.v
- 7.7 四相八拍步进电机驱动
- 7.8 单片机部分
- 7.8.1 I2C OLED驱动
- 第8章 verilog 扫盲区
- 8.1 时序电路中数据的读写
- 8.2 从RTL角度来看verilog中=和<=的区别
- 8.3 case和casez的区别
- 8.4 关于参数的传递与读取(paramter)
- 8.5 关于符号优先级
- 第9章 verilog中的一些语法使用
- 9.1 可综合的repeat
- 第10章 system verilog
- 10.1 简介
- 10.2 推荐demo学习网址
- 10.3 VCS在linux上环境的搭建
- 10.4 deepin15.11(linux)下搭建system verilog的vcs仿真环境
- 10.5 linux上使用vcs写的脚本仿真管理
- 10.6 system verilog基本语法
- 10.6.1 数据类型
- 10.6.2 枚举与字符串
- 第11章 tcl/tk的使用
- 11.1 使用Tcl/Tk
- 11.2 tcl基本语法教程
- 11.3 Tk的基本语法
- 11.3.1 建立按钮
- 11.3.2 复选框
- 11.3.3 单选框
- 11.3.4 标签
- 11.3.5 建立信息
- 11.3.6 建立输入框
- 11.3.7 旋转框
- 11.3.8 框架
- 11.3.9 标签框架
- 11.3.10 将窗口小部件分配到框架/标签框架
- 11.3.11 建立新的上层窗口
- 11.3.12 建立菜单
- 11.3.13 上层窗口建立菜单
- 11.3.14 建立滚动条
- 11.4 窗口管理器
- 11.5 一些学习的脚本
- 11.6 一些常用的操作语法实现
- 11.6.1 删除同一后缀的文件
- 11.7 在Lattice的Diamond中使用tcl
- 第12章 FPGA的重要知识
- 12.1 面积与速度的平衡与互换
- 12.2 硬件原则
- 12.3 系统原则
- 12.4 同步设计原则
- 12.5 乒乓操作
- 12.6 串并转换设计技巧
- 12.7 流水线操作设计思想
- 12.8 数据接口的同步方法
- 第13章 小项目
- 13.1 数字滤波器
- 13.2 FIFO
- 13.3 一个精简的CPU( mini-mcu )
- 13.3.1 基本功能实现
- 13.3.2 中断添加
- 13.3.3 使用中断实现流水灯(实际硬件验证)
- 13.3.4 综合一点的应用示例
- 13.4.5 使用flex开发汇编编译器
- 13.4.5 linux--Flex and Bison
- 13.4 有符号数转单精度浮点数
- 13.5 串口调试FPGA模板