
[TOC]
## 数据模型
现在最著名的数据模型可能是SQL。它基于Edgar Codd在1970年提出的关系模型:数据被组织成**关系**(SQL中称作**表**),其中每个关系是**元组**(SQL中称作**行**)的无序集合。
### NoSQL的诞生
采用NoSQL数据库的背后有几个驱动因素,其中包括:
* 需要比关系数据库更好的可扩展性,包括非常大的数据集或非常高的写入吞吐量
* 相比商业数据库产品,免费和开源软件更受偏爱。
* 关系模型不能很好地支持一些特殊的查询操作
* 受挫于关系模型的限制性,渴望一种更具多动态性与表现力的数据模型
### 对象关系不匹配
目前大多数应用程序开发都使用面向对象的编程语言来开发,这导致了对SQL数据模型的普遍批评:如果数据存储在关系表中,那么需要一个笨拙的转换层,处于应用程序代码中的对象和表,行,列的数据库模型之间。模型之间的不连贯有时被称为**阻抗不匹配(impedance mismatch)**
### 多对一和多对多的关系
存储ID还是文本字符串,这是个**副本(duplication)**问题。当使用ID时,对人类有意义的信息(比如单词:Philanthropy)只存储在一处,所有引用它的地方使用ID(ID只在数据库中有意义)。当直接存储文本时,对人类有意义的信息会复制在每处使用记录中
使用ID的好处是,ID对人类没有任何意义,因而永远不需要改变:ID可以保持不变,即使它标识的信息发生变化。任何对人类有意义的东西都可能需要在将来某个时候改变
### 文档模型中的架构灵活性
- 文档数据库有时称为**无模式(schemaless)**,又称为读模式(schema-on-read)(数据的结构是隐含的,只有在数据被读取时才被解释)
- 传统的关系数据库是**写时模式(schema-on-write)**
读时模式类似于编程语言中的动态(运行时)类型检查,而写时模式类似于静态(编译时)类型检查
例子:
把姓名分为first name 和 last name
在文档数据库种只需要改为如下,动态的做一个判断
```
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}
```
在“静态类型”数据库模式中,通常会执行以下 迁移(migration) 操作
```
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL
```
### 使用场景
当由于某种原因(例如,数据是异构的)集合中的项目并不都具有相同的结构时,读时模式更具优势。例如,如果:
* 存在许多不同类型的对象,将每种类型的对象放在自己的表中是不现实的。
* 数据的结构由外部系统决定。你无法控制外部系统且它随时可能变化
## 数据查询语言
关系模型包含了一种查询数据的新方法:SQL是一种**声明式**查询语言,而IMS和CODASYL使用**命令式**代码来查询数据库
命令式
```
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}
```
声明式
```
SELECT * FROM animals WHERE family ='Sharks';
```
声明式查询语言它通常比命令式API更加简洁和容易。但更重要的是,它还隐藏了数据库引擎的实现细节,这使得数据库系统可以在无需对查询做任何更改的情况下进行性能提升
### MapReduce查询
- MapReduce是一个由Google推广的编程模型,用于在多台机器上批量处理大规模的数据【33】。一些NoSQL数据存储(包括MongoDB和CouchDB)支持有限形式的MapReduce,作为在多个文档中执行只读查询的机制
- MapReduce既不是一个声明式的查询语言,也不是一个完全命令式的查询API,而是处于两者之间
### 图数据模型
- 多对多关系是不同数据模型之间具有区别性的重要特征。如果你的应用程序大多数的关系是一对多关系(树状结构化数据),或者大多数记录之间不存在关系,那么使用文档模型是合适的
一个图由两种对象组成:**顶点(vertices)**(也称为**节点(nodes)**或**实体(entities)**),和**边(edges)**( 也称为**关系(relationships)**或**弧 (arcs)**)。多种数据可以被建模为一个图形
有几种不同但相关的方法用来构建和查询图表中的数据
1. 属性图模型
2. 三元组存储(triple-store)模型
#### 属性图模型
在属性图模型中,每个**顶点(vertex)**包括:
* 唯一的标识符
* 一组**出边(outgoing edges)**
* 一组**入边(ingoing edges)**
* 一组属性(键值对)
每条**边(edge)**包括:
* 唯一标识符
* **边的起点/尾部顶点(tail vertex)**
* **边的终点/头部顶点(head vertex)**
* 描述两个顶点之间关系类型的标签
* 一组属性(键值对)
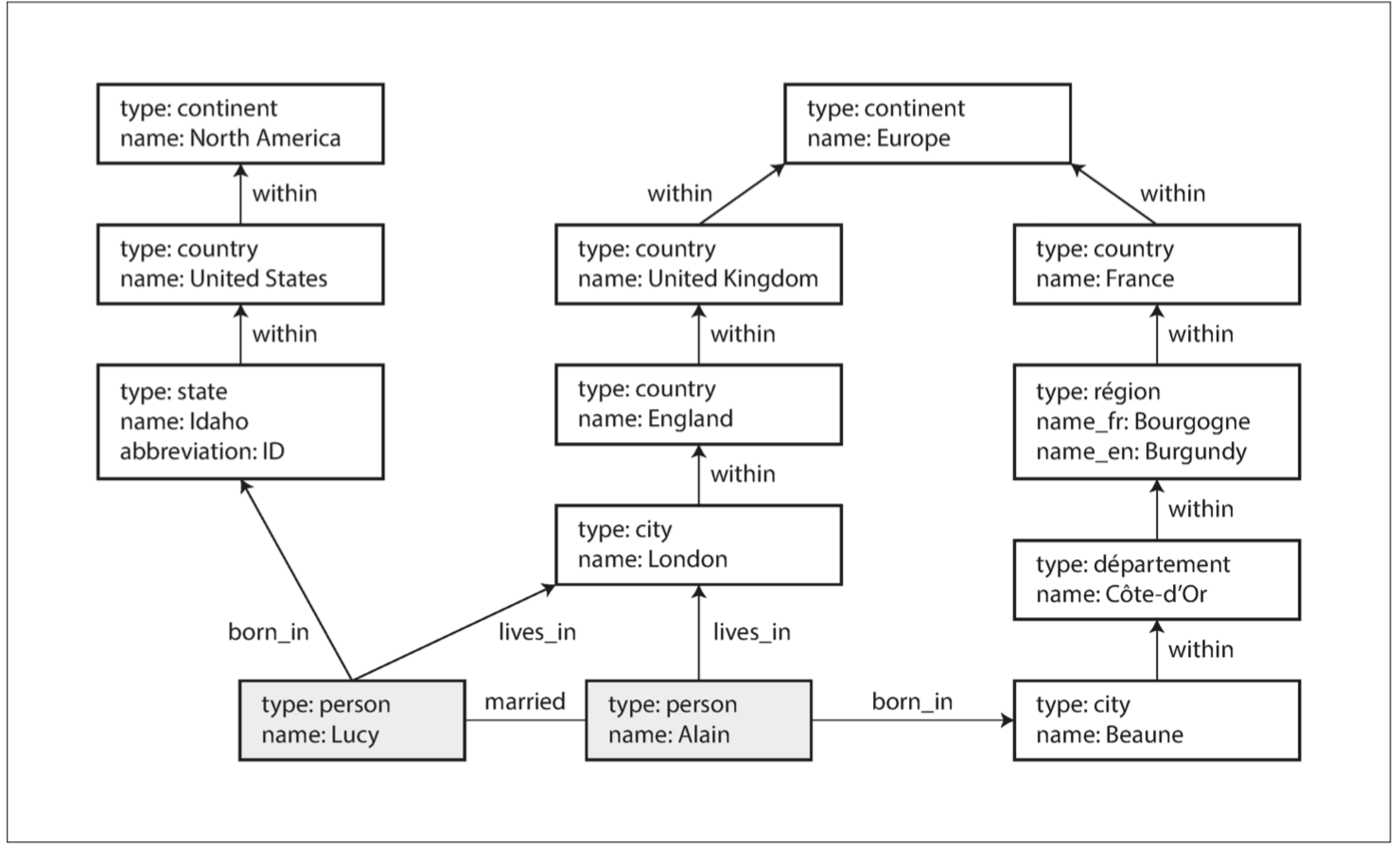
1. 任何顶点都可以有一条边连接到任何其他顶点。没有模式限制哪种事物可不可以关联。
2. 给定任何顶点,可以高效地找到它的入边和出边,从而遍历图,即沿着一系列顶点的路径前后移动。
3. 通过对不同类型的关系使用不同的标签,可以在一个图中存储几种不同的信息,同时仍然保持一个清晰的数据模型。
图表在可演化性是富有优势的:当向应用程序添加功能时,可以轻松扩展图以适应应用程序数据结构的变化
##### Cypher查询语言
Cypher是属性图的声明式查询语言,为Neo4j图形数据库而发明
```
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)
```
美国移民到欧洲的人的Cypher查询
```
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
```
#### 三元组存储triple-store)模型
三元组存储模式大体上与属性图模型相同,用不同的词来描述相同的想法
在三元组存储中,所有信息都以非常简单的三部分表示形式存储(**主语**,**谓语**,**宾语**),例如,三元组 (吉姆, 喜欢 ,香蕉) 中,吉姆 是主语,喜欢 是谓语(动词),香蕉 是对象
- 目录
- Lua
- 常用接口
- 协同程序
- 文件IO
- 错误处理
- 面向对象
- Scheme / Racket
- 技巧
- 如何设计递归
- 导入自定义文件
- []与() 的区别
- 打印函数
- 函数实现设计诀窍
- trace 打印调试信息
- 命令
- racket 运行
- raco 打包
- 语法
- 向量 / 结构体 / cons / list / string?等检查类型
- 符号 / 字符 / 字符串
- if / and / cond 条件分支
- 类型判断 / 等式判断
- local 组织函数
- 测试函数
- Rust
- 命令
- rustup
- Cargo
- rustc
- Rustfmt
- C++
- 快速入门
- 技巧与概念
- pragma comment
- socket 编程
- 编译
- 引入库的 <> 与 "" 的区别
- 语法
- 基础类型
- 运算符表
- 运算符重载
- 命名空间
- const和mutable的使用
- c++1新特性
- nullptr / constexpr (c++ 1x)
- auto / decltype 类型推到 (c++ 1x)
- 循环数组 区间迭代
- if-switch-变量声明强化
- 面向对象
- 原始字符串字面量 R"
- 指针
- 内存泄漏
- 指针与引用的差别
- const修饰指针
- 智能指针
- 数组
- 对象
- 构造函数
- 虚继承/虚基类
- 虚函数和纯虚函数
- 抽象类
- 栈中实例化 / 堆实例化
- 实例类型转换
- 继承 公有 / 私有 / 保护
- 子类调用父类
- 多重继承
- 实例指针(this)
- 友元函数 访问类私有和保护的成员
- 构造函数、explicit、类合成
- 多态的应用
- new和delete的使用
- 函数
- 引用传值/指针传值
- inline函数
- Lambda 表达式
- 模版
- 函数模版
- 类模板
- 容器
- std::array
- std::vector
- std::ist / std::forward_list
- map 各种map
- 各种 set
- 元组
- 正则
- 并发
- thread
- 锁
- 异步访问
- 条件变量
- 原子操作
- 命令
- g++
- make
- vcpkg
- clang++
- pkg-config
- 常用实例
- fork 方式创建后台进程
- 第三方库
- folly 工具库
- QxOrm
- catch 测试框架
- c++ 性能追踪
- gperftools
- gprof
- Qt
- Qt 代码风格
- qt 项目框架
- Qt Design Studio
- 技巧
- 添加 .pri 项目
- 添加子项目
- 加载第三方库
- 中文不乱码
- 信号和槽
- 国际化
- 定制帮助系统
- 多媒体
- 数据验证器
- 伙伴快捷键
- 单词补全
- QPushButton 样式问题
- 为元素添加滚动条
- 指定图标
- 自定义的结构体支持串行化
- 界面数据存储与获取
- 匿名函数
- 预编译
- 升级浏览器内核
- 封装弹窗
- 命令
- qmake
- 命令行编译
- pro 文件
- CONFIG
- TEMPLATE
- windeployqt 打包
- jom
- 知识
- 元对象系统(MOC)
- 对象树与拥有权
- 各个 TextEdit 的区别
- Qt 资源系统
- QSS 查询
- QObject的创建时间
- qt 的继承关系
- 单元测试
- 宏
- 测试类/函数
- GUI测试
- Benchmark测试
- 实例
- 在子项目中创建
- 数据驱动测试程序'
- 模拟GUI事件
- API
- 控件
- QInputDialog
- QIcon
- QFileIconProvider 提供文件icon
- QActionGroup
- QSystemTrayIcon
- QMenu
- QWidget
- QLabel
- QTextBrowser
- QTextEdit
- QPushButton
- QRadioButton
- QDockWidget
- QMainWindow
- QKeySequence 预设快捷键
- QSplashScreen 启动图
- QListWidget
- QTreeWidget
- QTreeView
- QTreeWidgetItem
- QTreeWidgetItemIterator 遍历QTree
- QTableWidget
- QTableView 基类
- QTableWidgetItem
- 条目控件
- 条目的拖拽
- 自定义右键菜单
- 基于条目控件的样式表
- QWebEngineView
- 模型
- QFileSystemModel 文件系统
- QStandardItemModel
- QAbstractItemModel 基类
- QAbstractItemView / QStandardItem
- QSortFilterProxyModel
- 布局
- 布局分类
- QSplitter 分裂器
- QSizePolicy 伸展
- 伸展因子
- 伸展策略
- BoxLayout 布局
- FlowLayout 流式布局
- QGridLayout 栅格布局
- QFormLayout 表单布局
- 文件系统
- QFile
- QFileInfo
- QStorageInfo 分区信息
- QTemporaryDir
- QTemporaryFile
- QDir
- QFileSystemWatcher 监控文件
- QLockFile
- 字节与流
- QByteArray
- QDataStream
- QTextStream
- 进程
- QProcess
- 线程
- QMutex
- QReadWriteLock
- 并发方案
- 继承 QObject [推荐]
- 继承 QThread
- QRunnable与QThreadPool 配合
- QtConcurrent
- Application::postEvent
- 图像
- QPainter
- QPixmap / QBitmap
- QImage
- QPicture
- QImageWriter 创建图片
- QImageReader 读取图片信息
- 命令行工具
- QCommandLineParser
- 关联容器
- QStack
- QVector
- QLinkedList
- QQueue
- QList
- ====== 顺序容器 ======
- QMap
- QHash
- QMultiMap 一key 多value
- QMultiHash 一key多value
- QCache key映射到类
- QPair
- QSet
- ====== 关联容器 ======
- QVariant
- QVariantList
- QVariantMap
- QMetaObject 元对象,反射
- invokeMethod
- 实例
- 反射类名
- 反射实例
- 数据库
- mysql 链接
- sqlite 内存版
- QSqlDatabase 连数据库
- QSqlQuery
- QSqlTableModel 绑定表
- QSqlQueryModel
- 日志
- myMessageOutput 自定义日志格式
- 网络
- QLocalServer/QLocalSocket
- QTcpServer / QTcpSocket
- QNetworkAccessManager 异步API
- QSslSocket
- QUdpSocket
- QUrl
- QUrlQuery
- 系统
- QStandardPaths
- QDesktopServices 桌面服务
- QSysInfo
- 日期和时间
- QDate
- QDateTime
- QTime
- 异常处理
- QException
- 正则
- QRegExp
- 字符串
- QStringRef
- QUuid
- Core
- Q_PROPERTY 属性
- QGlobalStatic
- QSharedData
- QCoreApplication
- 全局 qxxx
- qSort / qStableSort 排序
- qRegisterMetaType 注册自定义类型
- qSetMessagePattern 改qDebug格式
- qInstallMessageHandler
- QCryptographicHash 加密
- QSettings
- QTimer
- QObject
- 设计模式
- 工厂类
- 单例模式
- 第三方库
- FluentUI UI框架
- Felgo 可做移动端
- Dart
- 语法
- 基础类型
- 运算符
- 函数
- 类
- 控制流程语句
- 异常
- 映射
- 异步支持
- Future / Stream
- async/await
- 容器
- Map
- List
- Set
- 库和可见性
- 测试
- pub / pubspec.yaml
- Flutter
- 安装
- 技巧
- 混合开发方案
- State Widget 生命周期
- 与原生通信
- 自动切换Andrio和Ios 主题
- 命令
- flutter
- flutterfire 构建 Firebase
- 常见组件
- 布局
- 响应式
- 交互
- cupertino IOS 风格
- 资源与图片
- Packages
- 路由
- Builder
- streambuilder
- theme
- 三方库
- Getx 状态管理
- shared_preferences 存储
- webview_flutter
- FluroRouter 路由
- 实例
- 放大图片
- Python
- 技巧
- 语法
- 字符串
- 字典
- 装饰器
- 类
- 异常和错误
- 异步 python 3.x
- 场景
- 文件读取
- 内置包
- 包
- 工具类
- Supervisor-Linux/Unix进程管理工具
- 网络
- urllib包
- requests-比urllib2简洁
- BeautifulSoup-解析html
- 数据库/ORM
- pymysql -python3的mysql库
- SQLAlchemy ORM
- 办公
- pdfminer3k-解析pdf
- 测试 & 安全
- faker -测试
- web 框架
- web.py框架
- gui
- easygui_gui模块
- tkinter - 高效简单
- pyqt5 - 控件丰富
- 单元测试
- doctest模块
- unittest模块
- Django框架
- 模型
- pip
- virtualenv 虚拟环境
- Java
- java 数组
- java 类
- java 包
- java 异常
- java String
- java 集合
- PHP
- 常用场景 / 封装
- appkey/secretKey 实例
- https双向认证
- 从字符串中找出高频词
- 操作 HTML DOM
- levenshtein 输出错误,猜测输入的值
- ip 查询
- 配置webhook.php
- php 输出图片
- ignore_user_abort 网页断开有效
- 原生支持异步的方法 exec
- 可自动结束的程序
- 循坏程序
- ===== 函数 / 类封装 ⬇ =======
- 指定月份的第某个月
- 时间类封装 某天的开始与结束
- 数据库链式调用封装
- curl 封装 / 发送文件 / 远程下载到服务器
- 下载进度条 / 断点续传
- 获取 win / linux 的mac地址
- exec 控制 cli 服务器的启动与停止 linux 版本
- 代码规范及技巧
- PHP的优化之道
- PHP 代码简洁之道
- PHP The Right Way
- PHP标准规范
- PSR-3 日志接口规范
- PSR-4 自动加载规范
- PSR-6 缓存接口规范
- PSR-7 HTTP 消息接口规范
- PSR-11 容器接口
- PSR-13 超媒体链接
- PSR-14 事件分发器
- PSR-15 HTTP 请求处理器
- PSR-16 缓存接口
- PSR-17 HTTP 工厂
- PSR-18 HTTP 客户端
- PHP注释规范
- php7+
- PHP WEB框架
- Slim 微型框架
- yaf
- RPC-yar
- 内置函数
- hyperf 高性能框架
- swoole
- 安装
- HttpServer
- WebSocket
- AsyncIO
- Swoole-Crontab
- 异步文件系统IO
- 异步Redis
- 异步MySQL客户端
- process
- Memory 内存操作
- Channel 连接池
- swoole与tp5
- 调试 swoole
- 示例
- websocket 绑定对象方法
- redis 事件订阅发布
- EasySwoole
- 技巧
- 对自定义类优化的方式
- 数据库
- 基础使用
- 定时器
- 自定义命令
- 自定义进程
- 自定义事件
- 异步任务
- Crontab 定时任务
- 日志
- 组件库
- 单例模式
- Di 容器 / 依赖注入
- 协程 / WaitGroup
- 内存 Table
- Csp 并发等待执行
- 队列 Queue
- SplArray
- SplBean 过滤表结构
- 缓存
- 热重启
- 控制器
- TP5
- 验证器
- 内置规则
- 数据库操作
- 数据添加或更新
- 静态增删改查 / 关联操作
- 日志操作
- 路由
- taglib-自制标签
- migrations 数据库迁移
- tp 测试
- TP3.2
- 数据库操作
- 关联表
- 增删改查与验证
- 前置与后置
- 发送邮箱
- Tp6
- 技巧
- 多应用的api版本控制
- phinx 迁移工具
- 单元测试
- 先使用修改器在验证
- 异常统一处理
- thinkcmf
- 快速入门
- 常用插件
- 小程序管理插件
- 手机微信登录插件
- 表单自动生成插件
- phalcon C框架
- 快速入门
- 脚手架教程
- Symfony
- Swoft
- laravel
- webman
- workerman
- Spiral Framework
- composer / C扩展
- 网络 / curl / 文件上传 / jwt 认证
- guzzle [19.8k] http 客户端
- php-curl-class[2.6k] 封装curl为类
- class.upload.php 文件上传
- codeguy/upload 文件上传
- php-jwt 封装 JWT 加解密
- 文本 uuid / 加密整数id / 中文转拼音 / 解析html
- uuid 生成uuid
- hashids 隐藏真实id
- pinyin 中文转拼音
- html-parser 类jquery解析 html
- i18n
- i18n 国际化
- gettext 国际化
- 数据验证 / mock数据 / 媒体类型
- faker 生成验证数据
- Analyzer 检验媒体资源类型
- Valitron [1.3k] 数据验证
- rakit/validation [399 star] 验证数据
- 支付
- OmniPay 多网关支付处理的框架
- 时间
- Carbon [14.6K]
- 日志 monolog / seasLog
- monolog php编写
- SeasLog C扩展
- 办公文件 pdf / word / excel / ppt
- Snappy 一个PDF和图像的生成库
- WKHTMLToPDF HTML转换为PDF
- PHPPdf XML转化为PDF和图片
- PHPWord - 处理Word文档
- PHPExcel 处理Excel文档
- PHPPowerPoint -处理PPT幻灯片
- 性能分析 xhprof
- xhprof - PHP性能追踪及分析工具
- 缓存 yac
- Yac 5.2+ 共享缓存
- 配置 yarconf / 解析 json xml ini yaml
- yarconf 7.0+ 读取配置
- config 解析 json xml ini yaml
- 队列 resque (基于redis) / beanstalkd
- Beanstalkd 队列
- php-resque 基于redis的消息队列
- web ui 管理 / redis / pgsql / mysql / mgdb
- phpRedisAdmin - Redis 管理
- phpPgAdmin - PostgreSQL管理工具
- phpMyAdmin - MySQL管理工具
- rockmongo - MongoDB管理工具
- ORM
- medoo 支持5大数据库
- Redis C 扩展
- mongodb C扩展
- mongo-php-library 官方基于C扩展到的封装
- MongoDB ORM
- ElasticSearch PHP 用于 ElasticSearch 的官方客户端库.
- 调试与性能
- nette/tracy 优化报错
- 状态机
- Finite 有限状态机
- 定时任务
- jobby
- 邮箱
- php-imap 接收邮箱
- PHPMailer 发送邮箱
- Sphinx - 全文索引
- JsonMapper 一个将内嵌JSON结构映射到PHP类上的库
- weichat 封装
- User Agent 检测
- class.upload.php 文件上传
- 官方库
- SPL 数据结构
- SplDoublyLinkedList 链表
- SplStack 栈
- SplQueue 队列
- SplHeap 堆
- SplMaxHeap / SplMInHeap 大排序
- SplObjectStorage 存储对象列表
- SplFixedArray 固定长度的数组
- 预定义接口
- Iterator while迭代
- ArrayAccess 数组式接口
- Serializable 序列化接口
- IteratorAggregate foreach迭代器
- Observer 观察者
- SPL 函数
- spl_autoload_register 自动导入类
- class_parents 返回指定类的父类
- spl_object_hash/spl_object_id
- SPL 常见异常
- SPL 迭代器
- DirectoryIterator 文件目录迭代器
- FilesystemIterator 文件迭代器
- GlobIterator 带匹配的文件系统
- ArrayIterator 把数组改成迭代器
- NoRewindIterator 只遍历一次
- RecursiveArrayIterator 递归迭代
- RecursiveTreeIterator 输出递归树
- SPL 文件处理
- SplFileInfo 文件信息
- SplFileObject 文件操作提供对象
- SplTempFileObject 临时文件
- Ctype 类型检测
- ctype_alnum 是否只有字母和数字
- ctype_alpha 是否是字母
- ctype_cntrl 是否是控制符(\n\t\r)
- ctype_digit 是否是整数
- ctype_lower / ctype_upper 是否是 小/大 写字母
- ctype_graph 是否是可见字符(空格不算可见)
- ctype_print 是否是可见字符(空格算可见)
- ctype_punct 是否是除字母,数字,空格外的特殊字符
- ctype_space 是否是空白字符
- ctype_xdigit 是否包含16进制字符([0-9 和 [A-Fa-f] ])
- 数组
- array_map-针对多个数组
- array_multisort 对二维数组进行排序
- array_filter
- array_walk - 对一个数组操作
- array_walk_recursive 递归
- filter 过滤器函数
- 预定义常量
- filter_has_var 存在指定变量
- filter_var 过滤变量
- filter_var_array
- filter_input_array 过滤外部变量
- filter_input
- 控制输出 flush
- flush 刷新输出缓冲
- 实战
- 安全转义参数
- htmlspecialchars html标签转实体
- addslashes 用反斜线转义(可用于数据库)
- quotemeta 转义特殊字符
- 日期/时间/日历
- format 参数列表 如 Y,m,d
- DateTime 时间函数
- cal_days_in_month 某个月的天数
- date_parse_from_format [函数] 根据日期格式转时间
- 异常处理
- set_error_handler
- set_exception_handler 自定义异常
- URL 处理函数
- get_headers 获取头信息
- http_build_query 数组转 query
- parse_url 解析 URL 返回数组
- urldecode 和 urlencode
- 字符串处理
- strstr 字符串的首次出现
- chunk_split 将字符串分割成小块
- chr / ord 字符与ascii转换
- str_split 将字符串转换为数组
- htmlentities / htmlspecialchars 等 html 编解码
- strip_tags 字符串中去除 HTML 和 PHP 标记
- uniqid 返回唯一值
- preg 函数
- preg_grep 从数组返回匹配的值
- preg_last_error 正则匹配错误
- preg_match / preg_match_all
- preg_replace 正则替换
- preg_replace_callback
- preg_split
- 进制转换
- bin2hex / hex2bin 字符串-16进制
- bindec / decbin 十进制-二进制
- octdec / decoct 八进制-十进制
- base_convert 任意进制转换
- 文件系统函数
- fopen / feof / fclose 适合文件和网页
- fread 按字节读取
- fgets 按行读取
- fwrite 写入文件
- file 一次读取整个内容,行遍历
- fscanf() 每行都根据格式循环输出
- file_get_contents 一次读取所有,返回完整字符串
- flock 文件锁
- disk_total_space 磁盘容量
- 文件 / 路径处理
- scandir 返回指定路径的目录和文件
- glob 使用 * 模糊搜索文件和目录
- is_dir / is_file
- opendir / readdir / closedir 循环输出文件/目录名
- dirname /basename 父路径 / 基础文件
- pathinfo 文件路径的信息
- realpath 真实路径
- copy / rename 复制 / 重命名
- touch / unlink 创建/删除
- file_exists 文件是否存在
- filesize 获取文件大小
- is_readable / is_writable / is_executable
- 文件权限
- fileperms 获取文件权限
- 反射
- ReflectionClass 反射类
- ReflectionExtension 反射扩展
- ReflectionFunctionAbstract
- ReflectionFunction 反射函数
- ReflectionParameter 函数,类的参数
- ReflectionProperty 类属性
- ReflectionType 参数或返回值的类型
- 协议
- php://
- input / output
- stdin / stdout / stderr
- memory / temp
- filter
- ftp:// 和 ftps://
- data://
- glob:// 文件路径模式
- 过滤器
- 字符串过滤器
- 转换过滤器
- stream
- Stream Filters
- Contexts
- socket
- PDO
- PDO::setAttribute 属性
- 加密扩展
- password_hash
- openssl
- 杂项函数
- sys_getloadavg 获取系统的负载
- hrtime 微妙时间戳
- ignore_user_abort
- uniqid
- sleep/usleep
- imap 邮箱
- Session
- Callback 类型
- exec 执行结果以数组返回
- socket_create 操作
- soap 调用 webserver
- C / C++框架 编写扩展
- 原生编译
- 引用 加载动态库(.so) 文件
- 参数、数组和Zvals
- Zephir 开发PHP扩展
- 安装
- 快速入门
- php-cpp C++开发扩展
- 安裝
- 技巧
- 语法
- 变量
- 常数
- 输出和错误
- 函数
- 指定参数
- 调用PHP函数
- Lambda函数
- 构造函数
- 魔术方法
- 基础SPL接口
- 扩展类的魔术方法
- 类属性
- 异常
- 读取php.ini变量
- 扩展回调
- 命名空间
- FFI PHP扩展方式
- pear / pecl
- pecl c 扩展
- 在多 php 版本中指定
- pear php 扩展
- 安装/编译
- oneinstack 一键配置
- lnmp /lamp 脚本安装
- 配置 Let's Encrypt
- 配置 thinkphp
- dnmp docker 安装 LNMP
- ==== php 环境一键安装 ====
- Centos
- Ubuntu
- macOS
- ==== 包安装 ====
- apache
- nginx
- php
- 安装 GD 扩展
- 安装 openssl 模块
- ==== 编译环境安装 ====
- window apache/php
- window nginx/php
- PHPUnit
- 编程写测试
- 添加测试的依赖
- 数据供给器
- 对异常进行测试
- 对输出进行测试
- 基境 测试初始化与还原
- 数据库测试
- php 扩展
- opcache 缓存编译
- 常用正则
- php.ini 最佳实践
- php 调用 jar包
- Golang
- 知识碎片
- 无锁编程
- 调度器
- 预防CSRF攻击
- 避免XSS攻击
- 避免SQL注入
- 存储密码
- 设计模式 / 规范 / 性能 / 技巧
- 设计模式
- 单例模式-数据库单例
- 值选项模式
- 组合模式
- 策略模式
- 规范
- 性能优化
- 技巧
- 高性能
- 字符串拼接性能
- 切片性能及陷阱
- for 和 range 的性能比较
- Reflect 提高反射性能
- 逃逸分析
- 死码消除与调试(debug)模式
- sync.Mpap 与 加锁map
- 项目布局
- 项目布局一
- 项目布局二
- DDD分层架构
- 数据类型
- 切片类型( slice)
- 场景
- 请求/响应/错误码设计
- gin 对 handle的封装
- 带超时的 sync.WaitGroup
- 优雅关闭协程
- 控制协程的并发数量
- 并发非阻塞缓存
- 守护其他进程的代码
- 各类型转 sturct
- 注册为window 的服务
- go 注册
- sc 注册
- nssm 注册
- udp 打洞
- udp 打洞转 tcp
- Reader 用法
- i18n 本土化
- 压缩编译体积
- 第三方库
- 操作 DOM
- goJquery 像 jQuery一样操作DOM
- ORM
- gorose -链式调用
- GORM
- 技巧
- 获取一对多
- dbx 支持缓存全表数据
- sqlx
- 路由 / http客户端 / websocket
- httprouter 实现RESTful 风格
- mux - 路由
- fasthttp 比 net/http 快10倍
- GoRequest http 客户端
- gorilla库 路由 /参数转结构体
- gorilla/mux URL路由和分发器
- gorilla/schema 参数转换为结构
- websocket
- balloons-websocket 封装好的 websocket
- melody 优雅的websocket
- nhooyr-websocket 性能好于gorilla
- gorilla/websocket [14.5K]
- 缓存 / 并发
- go-redis
- gocache 封装 redis,memcached,内存的缓存
- cache2go 带过期回调的缓存
- go-cahce 类memcached 可存文件断电恢复
- tiedot 内存NoSQL数据库
- Gcache 带过期,带操作事件,支持 LFU,LRU ,ARC
- concurrent-map 支持并发的map
- bigcache 分片map缓存,value 只能存byte
- golang-set set的go实现
- atomic 支持更多类型
- conc 更好的结构化并发
- map转struct / 打印结构体
- mapstructure map 转 struct
- litter 优雅打印结构体
- 数据结构
- 结构算法库 Lists / Sets / Stacks / Maps / Trees
- 工具库
- pie 常用数组操作
- lo 类似 Lodash
- 连接池
- go-common-pool
- ants
- 序列化库 json / ini / yaml
- jsoniter 官方更高效的 json 库
- easyjson免运行时反射的json化
- gjson 从json中取值或判断
- simplejson 处理未知结构的json
- props 解析各种 ini / yaml 等
- 支持Unmarshal map 转配置
- viper 11k Star 支持yaml,ini 支持 env ,命令行 等
- hash / uuid
- xxhash 返回整数类型
- uuid
- Log 日志库
- zap 高性能日志
- Logrus 可插拔日志
- GUI
- fyne 简单难看的 GUI
- go-qt
- wails 桌面gui go + vue
- webview 用 html 可直接编译跨平台 app
- vugu vue+WebAssembly
- termui [11.6k]
- 命令行 / TUI
- urfave/cli [14.3k] 命令行
- kingpin 简单强大命令行
- cobra [18.2k] 专业级命令工具
- x-mod/cmd 空格隔离参数
- mpb 进度条
- progressbar 另一个进度条
- rivo/tview [4.5k] 命令行ui
- cute 漂亮的输出
- bubbletea 强大的 TUI
- 检验 validator
- validator
- 定时器
- cron 简单,不可修改的定时器
- cronlib 可修改任务 推荐
- robfig/cron 支持cron 和 固定时间
- 加密库
- thinkoner/openssl 可支持 ECB、CBC等
- 自己封装的加密库
- 身份验证和OAuth
- authboss 认证
- go-oauth2-server 符合规范的OAuth2服务器
- 开源 IM
- tonyboxes/imgo
- GoBelieveIO/im_service
- alberliu/gim [1.2k]
- 流量控制 / 熔断器 / 容错
- hystrix-go
- 示例
- Hello World
- http 示例
- dashboard 可视化
- Sentinel GO 流量控制组件
- QPS
- 热点参数限流
- 熔断降级
- 静态资源打包
- go-bindata 静态资源打包进执行文件
- 爬虫/无头浏览器
- colly [11.9k]
- chromedp 可控制是否显示浏览器[9.6k]
- 实例
- 启动访问某个网站
- 访问网站并且截图
- 设置cookie,保持登录状态
- 下载文件
- emulate 设备模拟
- 代理
- goproxy 代理
- 聊天机器人
- chatbot
- 图像
- imaging 图像处理
- gg 图像处理
- 单元测试
- gomonkey 打桩函数 - 推荐
- goconvey 测试结果带UI
- sqlMock
- redisMock
- httpmock
- Testify 支持断言,写法更简便
- gocheck 测试框架
- faker 生成假数据
- 依赖注入
- fx User开发的依赖注入
- 注册一个http
- 添加 handle
- 添加日志
- 注入接口
- 注入多个接口
- MIME 文件检测
- mimetype 类型检测 [1.2k]
- filetype [1.9k]
- 全文索引
- bleve
- fsnotify 文件监听
- gopay 支付集合
- .env 环境变量
- 哈希算法 转整数
- gopsutil 系统性能数据
- 官方包
- C
- 简单调用 c函数
- c与go 类型转换
- go 类型转C类型
- panic / recover
- panic+recover简化错误处理 模块必学
- error 自定义错误结构体
- unsafe
- archive
- tar
- zip
- bufio
- bytes
- compress 压缩
- gzip
- zlib
- container 数据结构
- heap
- list
- ring
- index/suffixarray 字典树
- Context
- crypto 加密
- rsa
- md5
- sha1
- sha256
- sha512
- tls
- database
- sql
- encoding
- encoding
- base32
- base64
- binary 序列化
- csv
- gob
- hex
- json
- xml
- errors
- expvar - 线性安全全局变量
- flag
- fmt
- 格式化输出格式
- html
- html
- template
- image
- image
- color
- png
- draw 图像合成函数
- gif
- jpeg
- io
- io
- ioutil
- log
- syslog
- math
- math
- rand
- net
- net
- http
- cookiejar 自动存储cookie
- httptest http的mock
- httptrace 追踪http
- httptest
- httputil 反向代理,打印头信息
- pprof
- rpc
- smtp
- url
- textproto
- os
- os
- exec
- signal
- user
- path
- path
- filepath
- plugin
- reflect
- regexp 正则
- runtime
- runtime
- debug
- pprof
- trace
- sort
- strconv
- strings
- sync
- atomic
- testing
- doc
- testing
- quick
- text
- scanner
- template
- time
- unicode / utf8
- unicode
- utf8
- utf16
- embed 嵌入
- js WebAssembly
- 示例
- golang.org/x
- net
- ctxhttp 带 ctx 的请求
- nettest
- netutil
- websocket
- oauth2
- crypto
- ssh
- text
- xorm / xorm+odbc
- go 适配 odbc
- 其他技巧
- 查询条件方法
- 关联查询
- 缓存
- 增删改查前后置的操作
- 同时支持三个数据库需求
- cmd 自动生成结构
- 嵌入 logrus
- web框架 / 微服务框架
- gin 框架
- 语法
- 中间件
- 参数模型绑定
- hmtl 渲染
- JSONP
- BasicAuth 基础认证
- 路由
- 输出格式
- 重定向
- 异步处理
- 静态资源
- 实例
- HelloWorld
- go-gin-example
- gin-vue-admin
- 测试
- beego
- 模型操作
- generate 生成的模型操作
- 一对一查询
- 一对多
- 打印日志
- 路由
- iris web 框架
- kratos bilibili 开源
- gf web/tcp 4.3K集大成框架
- gf-cli 命令行工具
- tcp 组件
- endless 热更新
- echo
- ====== web 库 ======
- Goji微框架
- go-zero [5.2k] web / 微服务框架
- go-micro 14.9K 微服务框架
- 快速开始
- 技巧
- 命令
- micro
- dashboard
- 示例
- HelloWorld
- 用户模块示例
- Jupiter 2.5K 微服务框架
- ====== 微服务 ======
- go-admin
- Gin-Vue-Admin
- gfast
- Simple Admin
- ====== Admin 后台 ======
- RPC / ARPC
- net/rpc
- net/rpc/jsonrpc 不支持http
- RPCX 分布式的RPC
- 元数据 / 分组
- 心跳
- 单服务例子
- 多服务例子
- 异步回调例子
- Fork 发送多个rpc有个成功
- broadcast 广播模式
- UI管理工具
- erpc
- arpc
- tcp / tcp 框架
- 最简单的 tcp 连接
- 面向对象,带有类型的tcp连接
- tcp binary 设置协议头
- 完善的tcp 服务端/客户端管理
- tcp server 框架
- zero - [152]
- xtcp - [101]
- gotcp - [458]
- Zinx - [3K]
- Go Web 编程
- go web
- websocket
- go cli
- godoc
- 约定
- Example
- go build
- buildmode 编译不同结果
- 编译 *.so 的动态链接
- pgp 示例
- 条件编译
- +build 条件编译
- go:build 推荐
- 文件后缀编译
- go:build 条件编译
- mod
- gcflags 逃逸分析等
- asmflags
- -ldflags 编译优化等
- go run
- go install
- go get
- go generate
- go test
- -bench 压测
- http 测试
- fuzz 模糊测试
- go mod
- go tool trace 性能追踪
- go tool pprof 性能追踪[推荐]
- 封装 pprof 可指定端口
- statsviz 运行时统计信息
- go tool dist
- work
- 编译工具
- xgo 一键编译多平台
- goreleaser 快速上传各架构编译到github
- go 国产化编译
- air 监听go,实时编译
- golines 自动换行
- go 支持 oracle
- go 调用dll
- dlv 远程调试
- 服务器
- Git
- 知识
- codeowners 指定目录所属
- 命令
- config
- commit
- rebase 合并 commit
- merge 分支合并
- cherry-pick
- checkout 切换/创建分支
- branch 创建/删除分支
- clone
- diff
- reset
- revert 取消某个提交
- rm / mv
- mergetool 可视化合并冲突
- log / reflog
- stash 搁置
- tag
- show
- pull / fetch
- push
- remote
- submodule 子模块
- shortlog log日志汇总
- archive 打包
- sparse-checkout
- git lfs 管理大文件
- rev-list
- filter-branch 历史中删除不该提交的文件
- bisect 二分查找
- format-patch 导出补丁
- worktree 便捷clone
- 技巧
- HEAD^ / HEAD~ 差别
- git 使用 rsa
- window 重新设置账户密码
- commit 规范
- 生成 Change log
- 规范流程
- commit 图标
- 分支命名
- centos git 服务器
- Nginx
- 技巧
- location 匹配
- 场景
- http 代理 / 超时设置
- 静态站点 / 动静分离
- 负载均衡
- 限流配置
- HTTP/2 服务推送
- 匹配路径跳转
- 缩略图
- 优化
- reuseport 负载均衡 [nginx>1.9]
- linux 内核参数优化
- nginx.conf 配置
- open_file_cache
- 自定义 access.log 格式
- Apache
- 常见场景
- .htaccess 场景
- 切割日志
- 改写重定向权限
- rewrite日志功能
- ip限制
- 目录列表功能
- 响应头的 Server 信息
- 代理 / 重定向
- 配置 https
- 添加响应头信息
- 限制目录访问
- 某目录不解析 php
- 允许跨域
- mpm 三种并行处理模块
- Caddy 类Nginx
- Caddyfile
- Caddyfile 指令
- root
- header
- php_fastcgi
- rewrite / try_files / uri 代理
- redir 重定向
- encode 压缩
- basicauth http认证
- handle / handle_path 类似nginx 的location
- reverse_proxy
- metrics 统计
- 场景
- 设置静态文件
- 自动跳websocket
- 真实域名设置https
- 代理
- php 服务
- 命令
- 监控日志
- OpenResty 带lua 的nginx
- ====== 常用工具 ======
- protobuf 协议
- 安装
- protobuf
- gogo
- protoc 命令
- 语法
- proto3的变化
- 示例
- golang 实现
- grpc
- golang 实现
- ====== 传输协议 ======
- opentracing 标准
- jaeger UI 优化,更简单
- 实例
- 带 context 的追踪
- 以 span 追踪
- http 形式访问
- 使用Inject和在进程之间
- rpcx 调用 [通过 conetxt ]
- rpcx 调用[通过传递 string(tranid,spanid,parentSpanId)]
- Zipkin
- ====== 链路追踪 ======
- jenkins 持续集成/交付
- 推荐设置
- 技巧
- webhook -通过gitlab 触发
- 远程触发编译
- 添加节点
- 构建一个go
- 常用环境变量
- 构建方式
- pipeline
- 设置环境变量
- 实例:Jenkinsfile
- 示例:使用多个agent
- 参数化构建
- MultiJob Project (新版弃用)
- 插件
- Go Plugin 插件
- git 无变化跳过构建
- Folders Plugin 创建任务分组,方便管理
- Multiple SCMs Plugin [新版本弃用]
- 生成时间戳
- FTP 传送到应用服务器
- Publish Over SSH 发送到远程
- 角色及权限管理
- 备份
- pipeline
- blue ocean 可视化 pipeline
- junit 测试报告
- Cobertura Plugin 可视化覆盖率
- cds 持续集成
- Travis CI 教程
- GitLab
- 持续集成 CI/CD
- 安装Runner环境
- .gitlab-ci.yml 配置
- CI/CD Examples
- 备份还原
- Gitea git 自托管
- ====== 持续集成 ======
- Zabbix 服务器监控
- prometheus 时序处理,报警系统
- 概念
- 工作流程(推荐阅读)
- 数据类型
- 作业和实例
- 联合
- 命名
- 安装
- 组件
- prometheus.yml 配置
- 数据模型
- PromQL
- 运算符
- 函数
- 查询
- HTTP API
- 记录规则
- 警报规则
- 配置
- 告警规则
- 示例模板
- Alertmanager
- 配置 Alertmanager
- 实例
- 监控程序启动
- 监控cpu,内存告警
- 服务发现
- 基于文件的服务发现
- 实例
- 导入 prometheus
- 配置三个 node
- go demo
- grafana 图形分析器
- Grafana 变量
- 报警
- 配置邮箱接收
- 配置 webhook
- 通知策略
- 实例
- 开源监控方案
- go+influxdb+grafana 制作日志监控系统
- 数据库中获取数据展示
- goaccess 日志分析工具
- countly-server 网站统计
- go-netflow 监控程序流量
- tproxy 监测 grpc 与mysql 连接
- Monyog 监控mysql
- uptime-kuma 多功能监控
- ====== 监控 ======
- metersphere 测试/压测/报告
- ====== 测试 ======
- beats 轻量型日志采集器
- fluentd 日志处理
- 安装
- 配置文件
- 语法
- 公共参数
- 插件
- 输入插件
- tail 监听文件
- forward 接受到其他fluent
- tcp
- http
- exec 接受程序输出
- monitor_agent 监视器
- 输出插件
- file
- forward 转发到其他fluent
- http
- copy
- roundrobin 轮询输出
- stdout
- elasticsearch
- mongo
- mongo_replset
- 容器开发
- 实例
- HelloWorld
- PHP应用
- apache日志输出到mongod
- Addax 异构数据同步
- 示例
- Hello World
- Elasticsearch
- Loki grafana 的日志收集
- ====== 日志/数据 处理 ======
- Bazel 构建
- Make
- 技巧
- ====== 构建工具 ======
- HAProxy
- 安装与示例
- 配置详解
- 示例
- 搭建L7负载均衡器
- 搭建L4负载均衡器
- 使用Keepalived实现高可用
- Keepalived 虚拟ip
- ====== 负债均衡 ======
- pyroscope-server pprof 定位性能问题
- 示例
- go 示例
- ====== 持续profiling服务 ======
- proxmox 虚拟机管理
- Vagrant
- Docker
- 规范的docker部署案例
- 场景
- phpstorm调用docker
- Docker 命令
- docker push / pull
- docker search
- docker images
- docker rmi
- docker commit 定制镜像
- docker tag 镜像标签
- docker save 导出镜像
- docker history 镜像创建历史
- docker buildx 构建多种系统架构
- ====== 镜像 ======
- docker run
- docker update 更新run的设置
- docker stop / start / restart
- docker pause / unpause 暂停/启动
- docker kill 杀到运行的容器
- docker rm
- docker attach / exec 进入容器
- docker export / import 导入导出
- docker ps 列出容器
- docker port 映射的端口
- docker top 类似top
- docker logs 容器日志
- docker inspect 容器元数据
- docker stats 资源情况
- docker cp 复制目录到容器
- docker diff 容器结构变动
- docker rename 重命名
- ====== 容器管理 ======
- docker login
- docker logout
- ====== Docker Hub ======
- docker swarm 管理集群服务
- docker-machine 模拟安装与使用
- vm 安装和使用
- docker service
- docker node 管理集群节点
- docker stack 文件方式编排
- 示例:部署WordPress
- ====== 集群管理(Swarm) ======
- docker network
- network create
- network connect
- network disconnect
- network inspect 显示细节
- network ls
- network prune 删除所有未使用网络
- network rm
- docker volume
- volume create
- volume inspect 详细信息
- volume ls
- volume prune 修剪
- volume rm
- docker system 系统管理
- system df 磁盘总体情况
- system prune 移除不用资源
- system info 等于 docker info
- system events 等于 docker events
- docker info docker 信息
- Docker-compose
- 命令
- docker 命令转 docker-compose
- Docker-machine 编排
- dokcer-machine create
- 安装
- Dockerfile 文件
- ENTRYPOINT 入口点
- docker-compose.yml
- 指令
- 私有仓库
- docker-registry
- Harbor
- UI界面
- lazydocker docker 命令行ui
- WeaveScope docker网页可视化
- lazykube k8s 界面
- Portainer 单机,集群可视化管理
- Rancher 企业级容器编排
- 实例
- redis 单机
- redis 集群
- docker-compose 搭建 lamp 应用
- php实战项目
- K8S
- 安装
- 容器可ping 外网 / 给容器局域网 ip
- 远程使用docker
- 缩小容器体积
- ====== 虚拟化 ======
- ffmpeg 音视频处理
- 实例
- 查看文件信息
- 转换编码格式
- 调整码率
- 改变分辨率
- 提取音频
- 截图
- 裁剪
- 为音频添加封面
- SRS 流媒体服务器
- ====== 流媒体 ======
- Casbin web访问权限控制
- Model 与常用配置文件
- 示例
- Hello World
- Http 示例
- gin 示例
- Casdoor 集成登录
- ====== web 组件 ======
- semgrep 静态代码扫描工具
- shellcheck 脚本lints
- ====== Lint ======
- Apollo 强大但部署麻烦
- Nacos 简单方便
- ====== 配置中心 ======
- 宝塔 面板安装
- 1Panel 运维管理
- 雷池 站点防护
- ====== Linux 面板 ======
- libreoffice 操作/预览office
- soffice 命令
- linux 中文字体问题
- 示例
- 预览 office(word,ppt,xsl) / pdf
- tika 文档转文字
- tika-server
- tika-app
- 示例
- http 请求获取文本内容
- go 与jar 配合
- ====== 文档 ======
- 禅道
- 快速入门
- ====== 项目管理软件 ======
- buildroot 交叉编译
- CGO 交叉编译实例
- onlyoffice 在线office编辑
- 安装
- 编译
- ubuntu16.04 编译
- 在uos_arm编译[弃]
- 修改字体
- 示例
- Hello-World
- ebpf 性能追踪
- Nexus Repository 统一包管理器
- go
- webdav
- chsrc 镜像自动设置
- 前端
- HTML
- 设计规范
- Web前端兼容性问题
- 手机端
- 尺寸单位
- JS / jQuery 插件
- 轮播图 滑动鼠标
- slick 鼠标滑动事件
- swiper 鼠标滑动 案例丰富
- 时间
- Moment 时间解析模块
- jQuery jquery-date-range-picker 日期区间
- jQuery daterangepicker 日期区间(美观)
- jquery bootstrap-datetimepicker 日期和时间
- 图片
- viewerjs 图片预览 功能全无需jquery
- grade.js 根据图片生成背景色
- js-cloudimage-360-view 360度旋转观看图片的 JS 库
- pagemap 网页右上角缩略图
- JQuery jqzoom.js-类似淘宝的图片放大
- jQuery lightBox-图片顺序预览
- JQuery Jcrop 图像裁剪
- X6 图形绘制工具
- 图形渲染
- D3
- SnapSVG svg 绘制库
- pixijs 绘制 WebGL,Canvas
- gojs
- three.js 做3D VR
- css3d-engine 精简版 treejs
- pano2vr 方便快速的3D-VR
- echarts
- 示例
- 动态时序图
- smoothie.js 监控图
- 工具库
- 下划线库 -有两个库
- licia 常用开发库
- Ramda 函数式库
- API
- 比较运算
- 数学运算
- 逻辑运算
- 字符串
- 函数
- 数组
- 对象
- MOCK
- json-server 伪造 json 接口
- mock.js 随机数据
- 文件上传 / 下载
- [推荐]filepond 文件上传 9.6K start 可编辑图片
- downloadjs 可让ie 支持文件下载重命名
- jQuery 多文件上传进度条 Huploadify
- 单元测试
- mocha 20K
- jest 33.2K
- 匹配器
- cypress 测试
- 视频播放
- flv.js b站开源
- jessibuca 支持webrtc
- 通知
- Pxmu.js 通知,loading 等 [11 star]
- ORM
- typeorm
- 实体
- 一对一等处理
- 查找
- 生成器
- 验证
- sql.js 网页sqlite 数据库
- 示例
- node 使用
- web 使用
- 获取远程库
- 大屏
- 拖拽式 大屏框架
- DataV 基于vue2 大屏
- 加密库
- CryptoJS
- 网页编辑器
- monaco-editor 网页版编辑器
- codemirror
- jQuery
- jQuery springy 关系可视化
- jQuery zTree 树插件
- jQuery select标签中搜索option
- jQuery jQueryUI
- 拖拽和放置
- 缩放
- 特效
- 滑动选择
- 排序
- 折叠面板
- 进度条
- 标签页
- autocomplete 自动完成
- jQuery form 表单提交插件
- jQuery Validate 验证
- 使用方式
- 校验规则
- 实例 validate与 jquery form
- jQuery Cookie
- jQuery Boostrap autocomplete
- jQuery Growl 侧边消息提醒
- jQuery noty 通知
- jQuery Migrate
- Slidev makedown 生成 PPT
- 语法
- makeDown
- Layouts
- theme
- 基础属性
- PlantUML
- components
- prismjs 语法高亮
- introjs 新手引导
- RequireJS 客户端模块管理
- cleave.js 格式化输入框内容
- fusejs 搜索功能
- tesseract.js 文字识别
- fullPage 全屏滚动网站
- mjml 转为相应式邮箱html
- progressJs 头部进度条
- instant.page 链接预加载
- pdf.js
- Yjs 协议编辑
- 前端框架
- layui
- 常用方法
- layui.laytpl 前端模板
- 模块定义
- 常用库
- form_table
- Cron表达式组件
- notify
- layui-soul-table
- xm-select
- tableTree
- croppers 截图上传
- 技巧
- 打开表单
- 表单格式
- layuiAdmin 官方
- LuLu 灵活前端
- ====== 桌面框架 ======
- Frozen UI
- WeChat UI
- MUI 对移动端做了优化
- AUI js 框架
- ====== 移动端 ======
- ficusjs 使用 Web component
- ====== 原生 component ======
- htmlx 无js 页面交互
- CSS
- 知识
- 最佳网页宽度
- 产生空白间隙的原因
- 所有元素平滑动画
- 技巧
- 居中 / 对齐
- 顶端观看显示进度条
- 图片自适应同步的截取
- 元素硬件加速
- 滚动条样式
- 给列表加竖线
- 文字超出隐藏并显示省略号
- 打字效果
- 语法
- translate 移动
- transform 转换
- transition 过渡
- animation 动画
- ====== 动效 ======
- flex
- grid
- ====== 布局 ======
- 函数
- CSS 变量
- vw,ch 等长度
- box-sizing 属性
- ====== 技巧 ======
- Font Awesome 字体
- bootstrap v3
- 样式快速入门
- 基础样式
- 布局
- 文本
- 列表
- 表格
- 表单
- 按钮
- 图片
- 辅助类
- 关闭按钮
- 三角符号
- JavaScript 插件
- 模态框
- 标签页
- tooltip 提示
- 按钮 设置加载
- normalize.css 初始化
- animate.css 动效
- tailwindcss css类样式
- 安装
- 定制
- 配置 文件
- 组件
- 语法
- container 容器
- Box Sizing
- Display
- 浮动 / 清除浮动
- Object 可控替换元素
- overflow 溢出
- Overscroll 滚动区域边界时的行为
- position
- Top / Right / Bottom / Left
- visibility 可见性
- Z-Index
- Flex
- Justify Content 控制flex/grid的主轴
- Align Content
- Align Items
- Grid 网格布局
- Justify Items
- 间距
- 内边距 / 外边距
- space 控制子元素之间的间隔
- water.css [7k] 无需class的框架
- simple.css [2.5k] 无需class的框架
- open-props css变量框架
- ====== css 框架 ======
- Sass/Scss与Less区别
- less 不依赖ruby
- z.less 库- 预定义常用函数
- stylus
- Sass 靠缩进继承
- scss = Sass 3 靠括号继承
- ====== css 库 ======
- jQuery
- 插件
- jQuery 制作插件
- 常用方法
- bind / on / click
- js-ajax-* 实现异步
- 全局body loading 为wj实现
- 根据 event.timeStamp 防抖
- 设置select 的默认值
- 图片放大
- 图片懒加载
- 文件异步下载 / 带百分比
- 文件异步上传 / 带百分比
- 拖拽上传文件
- 常用指令
- AJAX
- 全局 Ajax 事件处理器
- $().ajaxPrefilter ajax前置与后置监听
- $.get
- $.getJSON
- $.getScript
- $.post
- $.ajax
- $().load
- .serialize() / .serializeArray()
- DOM
- .addClass() / .removeClass()
- .hasClass() / .toggleClass()
- .attr() / .removeAttr()
- .prop() / .removeProp()
- .html() / .val() / .text()
- .data() / .removeData()
- .after() / .before()
- .append() / .appendTo()
- .prepend() / .prependTo()
- .clone()
- .detach() / .empty()
- .each() 遍历 jQuery 对象
- .get()
- ====== 元素选择 ======
- .eq() / .first() / .last()
- .filter() / .find() / .has()
- .next() / .prev()
- .parent() / .parents()
- CSS
- .css()
- .height() / .width()
- .innerHeight() / innerWidth()
- .outerHeight() / .outerWidth()
- .position()
- .scrollLeft() / .scrollTop()
- 动画 / 特效
- .animate()
- .delay() / .finish() / .stop()
- .fadeIn() / .fadeOut() / .fadeTo()
- .hide() / .show() / .toggle()
- .slideDown() / .slideUp() 滑动
- 浏览器事件
- .scroll()
- .resize()
- Event 对象
- event.currentTarget
- event.target
- event.data
- event.isDefaultPrevented()
- event.which 按键监听
- event.pageX / event.pageY
- event.preventDefault()
- event.stopPropagation()
- event.timeStamp
- event.result
- event.type
- event.key
- 事件监听
- .on()
- .one() 触发一次
- .trigger()
- .off() 移除事件
- 表单事件
- .blur() / .focus()
- .focusin() / .focusout() 支持冒泡
- .change()
- .select()
- .submit()
- 键盘事件
- .keydown() / .keypress()
- .keyup()
- 鼠标事件
- .click() / .dblclick()
- .contextmenu() 右键
- .hover()
- .mouseup() / .mousedown()
- .mouseenter() / .mouseleave() 鼠标进入 / 移开
- .mousemove() 移动
- .mouseout() / .mouseover() 冒泡移入/移除
- 工具类
- .grep() 过滤数组
- .map() 转为另一个数组
- .merge() 合并数组
- .each() 遍历数组和对象
- .inArray()
- ==== 数组 ====
- $.param / $().serialize / $().serializeArray()
- .extend() 合并对象
- ==== 对象 ====
- .trim() 去掉首尾空格
- .parseHTML() / .parseJSON() /.parseXML()
- ==== 字符串 ====
- .isArray()
- .isEmptyObject()
- .isFunction()
- .isNumeric()
- .isPlainObject()
- .type() 可区分 array 与 object
- ==== 类型判断 ====
- .now() 时间戳
- 函数 compose
- callbacks.add() 添加函数
- callbacks.empty() 清空函数
- callbacks.fire() 调用函数
- JavaScript
- 知识
- 同源限制
- 不同域跨窗口通讯
- typeof / instanceof
- JS 语法树
- 设计模式
- 严格模式
- 性能优化
- scrollHeight 等各中高度
- 技巧 / 场景
- onClickOutside 判断是否在严肃外
- clientX .pageX,screenX,offsetX 区别
- getBoundingClientRect 定位元素
- 下拉示例
- 自定义去除字符
- 打印时间戳
- 类型转换 黑魔法
- 只初始化一次
- 防抖 / 节流
- 动画
- ====== 技巧 ======
- this / bind / call /apply
- 函数式编程 / 柯里化
- compose 函数组合
- 原生面向对象写法
- 示例:canvas小球碰撞
- new 带prototype的函数
- ES5 实现继承
- 大文件断点续传
- ====== 场景 ======
- 插件
- JS 制作插件
- 实例:拖拽列表插件
- 图片/文件拖拽显示信息
- js 原生提示
- 手写签名
- JS 模块
- ES6 [推荐]
- CommonJS 模块
- ES6,7,8语法
- Promise
- Class
- Map / Set
- async / await
- 浏览器对象
- 浏览器环境概述
- window 对象
- Location 对象
- Navigator 对象
- Screen 对象
- XMLHttpRequest 异步请求
- console 对象
- URL 解析
- URL 的编码和解码
- URLSearchParams 对象转url参数
- 标准库 / 对象
- Object 对象
- Number 对象
- Array 数组
- String 对象
- Math 对象
- Date 对象
- RegExp 对象
- JSON 对象
- FormData 对象
- ArrayBuffer / Blob 对象
- File / FileList / FileReader 对象
- TextEncoder / TextDecoder
- DOM
- DOM,Node 接口
- Document 节点
- Element 等节点
- CSS 操作
- 事件
- EventTarget 事件通用接口
- Event 对象
- 鼠标事件
- 键盘事件
- 进度事件 - 加载外部资源
- 触摸
- 实例 手写
- PointerEvents 更通用的touch
- 拖拉事件
- 窗口事件
- 剪贴板事件
- GlobalEventHandlers 接口
- HTML 标签
- <a>
- <img>
- <input> 元素
- Web Api
- Fetch
- Response 对象
- Request 对象
- Headers 对象
- 实例
- POST 请求
- JSON 请求
- 上传文件
- 获取数据流-如图片
- 逐行处理文本文件
- 自定义请求 Request
- sessionStorage / localStorage
- Intersection Observer 元素可见判断
- PerformanceObserver 性能监听
- ResizeObserver 监听元素大小
- TextDecoder / TextEncoder
- Gamepad 游戏手柄
- geolocation 地理位置
- 网页可见性 状态监听
- Notification 系统通知
- 画中画API
- Pointer events 指针事件
- Vibration API 震动
- Audio API 声音
- Web Share API
- WebCodecs API 帧和音频块的访问
- Mutation Observer 监视 DOM 变动
- 数据类型
- TypeScript
- 技巧
- 声明文件
- 全局变量
- npm 包中使用
- UMD 库
- 模块插件
- tsconfig.json
- 语法
- 基础类型
- 装饰器(decorators)
- 命名空间
- 模块
- 高级类型
- 类型兼容性
- 接口
- 类
- 函数
- 泛型
- Record
- 高级类型
- ====== 基础 ======
- SVG
- 语法
- js 操作 SVG
- canvas
- 绘制矩形
- 绘制路径
- 绘制直线
- 绘制圆弧
- 绘制贝塞尔曲线
- 绘制文本
- 绘制图片
- 样式与颜色
- 状态的保存和恢复
- 变形
- 平移
- 旋转
- 变形矩阵
- 合成
- 裁剪路径
- 动画
- WebSocket
- 库
- websocketd
- socket.io
- WebGL
- twgljs 轻量级库
- WebRTC
- WebRTC 使用流程
- 概念
- 处理浏览器中的媒体
- 两种传输方式示例 视频 / 文本 / 流文本
- 需要信令通道
- 教程
- 媒体设备
- 对等连接入门
- 远程流
- 数据通道
- TURN服务器
- API 接口
- RTCPeerConnection
- getUserMedia
- 示例
- examples
- php 实现服务器与web端
- 捕获窗口
- 捕获摄像头
- 本地使用 RTCPeerConnection
- DataChannel
- 远程点对点
- 第三方库
- SimpleWebRTC [4.5k]
- webRTC.io [1.6k]
- ==== 视频聊天 ====
- peerjs 点对点链接
- 点对点传输文字
- 第三方项目
- p2p.chat
- im
- WebAssembly
- 示例
- hello-world go版
- SSE (EventSource)
- 示例
- Web Workers 多线程
- 示例
- 通用的异步 eval()
- Service Worker API
- PWA 提升WebApp
- Broadcast Channel 广播
- IndexedDB
- 库
- Dexie.js 封装 IndexedDb
- ZangoDB
- JsStore 带SQL语法
- lovefield 仿 SQL [6.8k]
- ====== 进阶 ======
- NodejS
- npm 插件
- mongoose 操作 mongodb
- sequelize 数据库orm
- pm2 启动 node
- nodemon 监控文件变化自动重启
- cookie-parser 设置 cookie
- Puppeteer 控制浏览器
- Robotjs 桌面自动化
- anyproxy 代理
- pkg 编译成二进制
- 文件操作
- 网络操作
- 进程管理
- Express 框架
- 模块化编程
- Koa web 框架
- Deno 代替node
- bun
- 命令
- bunfig.toml
- 接口
- API
- Bun APIs
- Web APIs
- Node Js
- ====== 后端 ======
- Vue
- 问题
- 运行网页,但是报缺少 Node 的相关库
- 技巧
- 异步加载
- 动画,与动画库的使用
- webpack 构建多页面
- vue3.0 语法
- reactive,ref,watchEffect
- 生命周期函数
- computed 与 watch
- 子组件
- TypeScript
- 性能优化
- 测试 Vitest
- 路由
- 动画
- Suspense 异步加载组件
- directives 自定义指令
- vue 库
- axios 请求
- vue cli 3.0 配置
- qrcode.vue 二维码
- Vue-router
- vue-i18n
- VeeValidate
- vueuse
- 存储 useLocalStorage 等
- ref 的 各种undo,redo
- ====== State ======
- useActiveElement
- useDraggable
- useDropZone 可拖动到区域
- useElementBounding
- useElementSize width,height
- 元素可见性
- useMouseInElement
- useWindowScroll
- useWindowSize
- useTextareaAutosize 自动增高
- useTitle
- useUrlSearchParams url参数
- onClickOutside 元素外点击
- useFocus / useFocusWithin 元素是否激活
- ====== Elements ======
- useClipboard
- ColorMode 切换主题
- useEventListener
- useFileSystemAccess 文件信息
- useObjectUrl 查看文件内容
- useFullscreen
- useMediaControls 媒体内容
- usePermission 权限
- useWebNotification
- useWebWorker
- ====== Browser ======
- onKeyStroke 监听键盘
- onLongPress 长按时长
- useDevicesList 媒体设备
- useDisplayMedia 使用设备源
- useGeolocation 定位
- useInfiniteScroll 下拉滚动
- useKeyModifier 按键监听
- useMouse
- useNavigatorLanguage 语言
- useNetwork
- usePageLeave
- useSpeechRecognition 语音
- useTextSelection 选中文字
- ====== Sensors ======
- ====== Component ======
- useVirtualList 虚拟列表,高性能
- ======== 工具库 ========
- watchDeep 监听深度对象
- watchDebounced 防抖
- watchOnce 监听一次
- watchThrottled 节流
- useDebounceFn /useThrottleFn 防抖函数
- useEventBus 通知
- ====== watch ======
- useArrayDifference
- ====== Array ======
- useDateFormat 当前时间
- useTimeAgo 多久前
- ====== time ======
- useAsyncValidator 验证
- useChangeCase 单词切换
- useCookies
- useQRCode 二维码
- useSortable 拖拽排序
- ====== Integrations ======
- ====== 工具库 ======
- better-scroll 更好的无滚动条插件
- vue-infinite-scroll 下拉加载
- vue-infinite-loading 上拉刷新,功能强
- vue-lazyload 图片懒加载 -vue2.0
- Vue.Draggable 拖住div
- vue-fullpage
- form-generator 表单生成器[UI版]
- vue-form-making element-ui 可视化表单
- vue-cron Cron表达式组件
- vue-good-table 表单组件
- vxe-table
- skeletonreact 骨架屏
- ======== UI 库 ========
- vuex 状态管理
- 在多页面中使用
- 创建 store.js
- Pinia 状态管理
- pinia-plugin-persist-uni 适配 uni
- hello world 实例
- ======== 状态库 ========
- Nuxt 集成服务器渲染,ui框架等
- vue-element-admin
- ant-design
- d2-admin vue+ElementUI 后台框架
- vuetifyjs 37.4k
- 特性
- 别名
- 全局配置
- 字体图标
- i18n
- scss
- 主题
- 辅助类
- 组件
- v-spacer 空白弹框
- v-item-group
- v-hover 悬停事件
- v-list
- 指令
- v-ripple
- v-scroll
- ======== 框架 ========
- React
- 第三方库
- ChatUI
- wasp 快速制作前后端
- react-query
- use-immer 优雅更新state对象
- motion.dev 动画库
- 语法
- hook
- 自定义 hook
- useEffect
- useMemo 缓存计算结果
- useSyncExternalStore 获取外部数据
- useCallback
- useDeferredValue
- 组件
- StrictMode 严格模式
- Suspense 加载前的提示
- API
- 组合 vs 继承
- 状态提升
- 表单
- 列表 & Key
- 条件渲染
- 事件处理
- State
- 组件 & Props
- JSX
- Context 深层传递参数
- ref 更新不触发刷新
- Next.js
- Routing
- pages
- layout
- Routing
- Error Page
- Loading
- Link
- Parallel Routes
- layou 布局
- 环境变量
- API 路由
- Svelte
- 示例
- 编译为一个web Component
- Web Components
- 示例
- template 方式
- javascript 方式
- 鸿蒙
- 安装
- 示例
- Hello World
- 目录说明
- resources 目录
- ArkTS 语言
- 组件
- 状态管理
- LocalStorage 页面级状态
- AppStorage 全局状态
- emitter 事件监听
- PersistentStorage 持久化
- Environment
- ASK UI 框架
- 布局
- 组件
- ====== 框架 ======
- React Native
- 基础知识
- Electron 桌面应用
- 快速入门
- 技巧
- 内置模块
- app 模块
- BrowserWindow
- Menu 菜单
- globalShortcut (全局快捷键)
- Shell
- dialog 对话框
- tray 系统托盘
- webContents 渲染以及控制 web 页面
- ipcMain / ipcRenderer (进程间的通讯)
- clipboard 剪切板
- webview
- protocol 自定义协议
- desktopCapturer 获取其他软件信息
- 常用包
- electron-settings 设置管理器
- electron-log
- electron-builder 打包[推荐]
- electron-packager 打包
- electron-updater 升级
- electron-store 以文件形式缓存配置
- menubar 托盘菜单栏
- photon 桌面 UI 构建
- React Desktop macOS和Windows的UI工具包
- chrome-tabs
- xel 界面ui
- electron-util 常用包
- electronic-vue
- wails go实现的跨平台
- Runtime
- Events
- Log
- window 窗口
- Dialog 对话框
- Menu 菜单
- Browser 浏览器
- Clipboard 剪贴板
- Screen
- app 参数
- tauri 桌面开发
- 系统APi
- weex 跨平台vue 开发
- weex-ui 第三方 ui 库
- wexx-bindingx 动画效果
- wails go版pc端
- uniapp
- 插件 / 资源
- [通用] 更好的下拉刷新,上拉加载
- [app] 全量更新 app-简单
- [app] 可增量更新
- 登录/注册模板(含微信等第三方登录)
- 导航栏
- uni-form 表单校验
- combox 自动完成
- uni-data-checkbox
- uni-data-picker
- uni-loadmore 上拉加载更多
- uni-row 布局
- uni-dateformat 日期格式化,倒计时
- uni-file-picker 文件上传
- uni-search-bar 搜索栏
- uni-segmented-control 分段器
- UI 框架
- uni-框架
- ColorUI-UniApp
- uView UI 更多功能
- 快速入门
- 设计图尺寸
- 设置开发/生产模式
- 设置 scss 等样式
- 生命周期
- 组件/标签的变化
- template 与 block
- NPM支持
- 资源路径
- css 相关
- js 导出模块
- 使用 TypeScript
- 组件管理
- 事件处理器
- vuex
- 配置
- pages.json
- easycom
- package.json
- uni.scss
- App.vue
- main.js
- 生命周期
- 应用生命周期
- 页面生命周期
- 组件生命周期
- Vue
- 事件处理器
- 表单使用 v-model
- 组件的props
- 组件的ref
- 组件的.sync 子组件prop通知父组件
- 原生组件
- button
- page-meta
- navigation-bar
- custom-tab-bar
- open-data
- 运营服务
- 统一推送uniPush
- 运营统计
- 制作统一发行页面
- API
- 媒体
- uni.compressImage 压缩图片
- 设备
- 陀螺仪
- 系统信息
- 网络状态
- 罗盘
- 加速度计
- 拨打电话
- 扫码
- 剪贴板
- 屏幕亮度
- 手机振动
- 蓝牙
- 生物认证
- 键盘
- 界面
- 弹出菜单
- 设置导航条
- 设置 tabBar
- 背景/下拉背景
- 动画
- 滚动页面
- 网络字体
- 下拉刷新
- 节点信息
- 节点布局相交状态
- 文件
- 绘画
- 第三方服务
- 获取服务供应商
- 登录
- 检测是否登录
- 微信登录
- 信息获取
- 获取手机号
- 手机号一键登录
- 支付
- 推送
- 模板消息-小程序
- 授权
- 小程序设置界面
- 收货地址
- 打开其他小程序
- 模版消息
- 订阅消息
- 小程序更新
- App 更新
- 调试
- 统计 - uni 对程序的统计
- 广告
- 页面通讯 / 全局事件监听
- 公用模块 / 全局变量
- uni_modules
- datacom
- 自动化测试
- wexx / nvue
- HTML5+
- 国际化
- 微信小程序
- ====== 平台相关 ======
- webpack
- loader 插件
- babel-loader ES6 转为 ES5等
- html-loader
- css-loader
- postcss-loader 对 css 进行后处理
- less-loader
- url-loader 过小生成 base64位图片
- file-loader 引入图片
- image-webpack-loader 图片压缩
- 引入模块-并对模板赋值
- esbuild
- Api
- Build API
- 高级配置
- 语法
- gulpjs 构建工具
- 快速入门
- 语法
- 常用插件
- css 插件
- js 插件
- 图片 插件
- 自动刷新页面
- 示例
- 编译sass
- 监听 css变化
- 监听 文件变化,刷新页面
- 多页面示例
- 模版
- rollup 0配置打包脚本
- lerna 管理包含多个软件包
- 命令
- 快速入门
- vite
- 功能
- 命令行
- vite
- 插件
- 兼容传统浏览器插件
- 示例
- 普通 html, 支持 import
- ====== 构建工具 ======
- npm
- npm 插件制作发布
- cnpm - 淘宝的 npm 镜像
- npx
- yarn
- 命令
- plugin
- .yarnrc.yml
- pnpm
- 命令选项
- Bower 浏览器管理插件
- ====== 包管理 ======
- SEO 优化
- ====== 性能与优化 ======
- vConsole
- 远程调试移动设备网页
- chil 远程调试网页
- 远程调试 Android 设备网页
- selenium 自动测试
- selenium IDE
- selenium Python
- 常用技巧
- 定位 元素 / 一组元素
- 控制浏览器操作
- WebDriver常用方法
- 鼠标事件
- 键盘事件
- 获取断言信息
- 设置元素等待 -等待某条件成立后在执行
- 多表单切换
- 多窗口切换
- 警告框处理
- 下拉框选择
- 文件上传
- cookie操作
- 调用JavaScript代码
- 窗口截图
- 关闭浏览器
- Chrome headless 无界面模式
- CukeTest 可测桌面应用
- 语法
- Tree 结构的选择
- 数据驱动测试用例
- 模型管理器
- 批量运行工具
- 常用工具函数
- Cucumber API
- this.attach 在执行后进行截图
- 每个场景后截图至报告
- 模拟桌面操作API
- 模拟 Ctrl+A
- 禁用中文输入法
- ====== 使用工具 ======
- 谷歌浏览器插件
- 概念
- manifest.json
- popup
- background
- content
- plasmo 浏览器插件框架
- 示例
- Popup
- options 选项页
- newtab 新标签
- background
- messaging 通信
- content
- Tab pages
- storage
- Env
- package 转 manifest
- Assets
- Icon
- lang
- 谷歌接口
- extension
- browserAction
- tabs
- contextMenus
- notifications
- omnibox
- 互相通信概览
- 长连接和短连接
- windows
- storage
- webRequest
- cookies
- runtime 插件相关
- manifest
- ====== 浏览器插件======
- chrome
- puppeteer js控制chrome
- DevTools protocol 通过websocket控制
- 命令行
- go 版本
- ====== chrome 控制 ======
- XPath
- 软件
- jetbrains / Intellij IDEA
- 常用插件
- Git Commit Message Helper
- Chinese (Simplified) 中文组件
- Php Inspections (EA Extended)
- redis simple -redis 客户端
- plantuml-integration uml 绘制
- 制作插件
- 连接远程docker
- 配置vagrant虚拟机
- 保存监听 eslint
- uni-app 代码提示
- docker 使用 phpstorm/php-71-apache-xdebug
- php 本地debug / 远程debug
- php 代码检测
- grumphp 限制 commit 提交
- vs code
- C++ 配置
- Go 配置
- Qt 配置
- visual studio
- 使用 Clang/LLVM
- 运行Qt
- 内网部署vs及插件
- 插件
- ReSharper C++
- Clang Power Tools
- Sublime Text配置
- github
- gource 通过 git 生成 动画
- thefuck 出现错误使用 fuck
- tldr 简化 man 函数
- postman
- Apache JMeter 并发测试工具
- Chrome
- 控制台
- Apche Directory Studio - LDAP软件
- sokit 端口监听 转发. socket 测试工具
- wireshark 抓包工具
- Ventoy 多系统合一启动盘制作工具
- UserLAnd 手机安装linux
- termux 手机安装 linux
- sharemouse 跨系统操作
- Microsoft Garage Mouse 多windows跨键盘
- syncthing 分布式同步
- D盾
- openArk
- 搭建 shandowsocks
- google云 搭建
- 亚马逊云 搭建
- 终端走代理
- 一键 ss 脚本
- ⬇⬇⬇⬇⬇ 无界面软件 ⬇⬇⬇⬇⬇⬇
- sqlmap 防sql 注入的测试
- scrcpy 手机投屏
- sftpgo 跨平台 ftp
- frp 内网穿透
- AWS 亚马逊
- 小米路由AX3600
- upx 压缩可执行文件
- firebase 赛博菩萨软件
- 安卓
- adb
- emulator 虚拟器
- 安卓抓包
- MAC
- php 环境配置 2.0版
- pear / pecl 安装
- Mac 配置 Python 和Python3
- 配置 Oh My Zsh+ iTerm2
- iTerm2 自动登陆 ssh
- 配置 Vim
- brew
- 创建 brew 包
- MAME 街机模拟器
- php-osx mac 安装php
- 破解 wifi
- iOS注册美区Apple ID教程
- Window
- 常见问题
- 打不开微软商店
- cmd 命令
- cmd 运用场景
- 复制目录
- 删除目录下的所有文件
- < 交互时可自动输入
- 查看端口占用的pid
- 当前目录管理员身份运行
- 批处理命令
- echo / rem 注释
- pause 暂停
- call 调用其他 bat
- goto
- set 设置变量
- 获取命令行参数
- 常用命令
- tasklist 查看进程
- taskkill 进程操作
- ipconfig
- nslookup 域名解析
- netstat
- route 路由信息
- arp 查看ip使用情况
- findstr
- robocopy
- SpaceSniffer 检查磁盘文件暂用大小
- choco win包管理神器
- 创建 choco 包
- 实例
- nupkg 常用函数
- WSL 2 -方便win docker
- Sysinternals 微软工具箱
- Autologon 免密登录
- Psexec 远程执行工具
- Autoruns 查看启动项
- AdExplorer / AdInsight AD与LDAP查看器
- BgInfo 电脑信息生成到桌面
- LogonSessions 列出登录时间
- PsInfo 系统信息
- PsKill 终止(本地或远程)进程
- PsPing Tcp ping
- PsLoggedOn 显示登录的用户
- PsPasswd 更改本地或远程的密码
- PsShutdown 关闭或重启(本地或远程)电脑
- RDCMan 批量管理远程
- TcpView 列出套接字
- ZoomIt 屏幕缩放
- scoop 包管理器
- 添加ftp 服务
- vcpkg c++包管理器
- 升级 TLS
- clumsy 模拟不稳定网络环境
- Dependencies 查看 exe 依赖的dll
- portableapps 软件装U盘
- mobaXterm 类Xshell
- mouse without borders 共享键鼠
- IIS
- dumpbin 类似 linux 的 ldd
- Linux
- 知识碎片
- profile 与 bashrc
- /etc/init.d/functions 公共函数
- 实例
- &>file、2>&1、1>&2、/dev/null
- 管道和重定向
- 守护进程脚本
- 几个重要的信号
- cli a-z 常用命令注解
- 选项优先级
- 使用场景
- 创建用户,给root权限
- 设置服务器时间
- [自制] 批量操作多节点的脚本
- 引用环境变量替换文字模版
- umount 挂载硬盘
- 内核版本/系统版本信息
- 设置静态 IP
- 常用命令
- 文本 / 文件 / 目录
- egrep = grep -E 查看文件内容
- grep 查看文件内容
- awk 对文本每行处理
- sed 处理文本文件
- xargs 多行转换
- find 文件查找
- locate 比find 更快的索引
- wc 统计文字
- tr 替换与清除
- cut 按列切分
- tee
- 守护进程
- systemd 定时器
- systemctl 守护进程
- systemctl
- Unit.server 配置
- 实例
- 讲解 sshd 配置
- 实例 配置 go-web
- Type=forking 的使用
- journalctl 日志管理
- systemd-analyze 启动耗时
- hostnamectl 主机信息
- localectl 查看本地化设置
- timedatectl 查看当前时区设置
- loginctl 查看用户信息
- goreman 服务管理 [神器][golang]
- supervisor [python]
- supervisord [golang][带GUI]
- chkconfig 开启启动管理
- 标准 init.d 模版
- httpd 开启启动
- 调试工具
- strace 调试脚本
- pstack 跟踪进程栈
- perf 性能分析工具
- stress 压力测试
- ab 压测工具
- ldd 查看执行文件的依赖
- readelf 动态库的真实版本
- patchelf 强制指定LB_LIBRARY_PATH
- tcpdump
- gdb 调试利器
- lsof 查看当前系统文件
- ss 网络端口查询
- free 内存情况
- iotop 查看进程 IO
- iftop 网络 IO 监控
- tc 模拟弱网
- 运维工具
- ansible 批量执行多服务器
- awx UI管理工具
- expect - 自动交互脚本
- envsubst 替换模版中的环境变量
- top / uptime
- sshpass 非交互密码登录
- bash-completion 命令补全
- 查看硬件信息
- lscpu 显示cpu型号
- arch 查看架构
- uname 查看系统版本
- cat /proc/meminfo 查看内存信息
- lsb_release 系统信息
- arch cpu架构
- ulimit
- 网络工具
- nmcli 配置静态网络
- nmap 端口扫描
- 磁盘管理
- df 磁盘使用情况
- du 统计文件占用
- 管理用户/组
- useradd
- usermod
- userdel
- groups 查看
- groupadd
- groupmod
- groupdel
- passwd
- openssh
- ssh openssh-client包
- 客户端配置文件
- sshd openssh-server包
- openssl 使用 openssl 包
- 实例
- 服务器证书 .key 与 .pem
- 客户端证书
- 同时生成服务端与客户端证书
- 登录方式
- ssh-keygen 秘钥登录
- ssh-agent / ssh-add 秘钥记住密码
- 证书登录
- 端口转发
- scp
- rsync 增量同步
- sftp
- gcc
- 静态库
- 动态库(共享库)
- 安全
- firewall-cmd 防火墙
- iptables
- asd 内存硬盘
- ln
- tar
- diff
- watch
- patch
- Curl
- wget
- Vim
- Tmux
- NFS 文件共享
- ftp
- logrotate linux 日志切割
- NFS 网络文件
- manpages-zh 中文man
- Bash 脚本
- 快速入门
- 知识点
- $()与反引号区别
- 检查返回值
- !$ / !*
- shell替换上一条命名的变量
- bash 最简单 kv 数据库
- echo / printf / 快捷键
- Bash 的模式扩展
- 引号和转义
- 变量
- 常见变量
- 字符串操作
- 算术运算
- 参数
- getopts Bash内置
- getopt 基本也自带
- env / shift / exit
- read 用户输入值
- 条件判断
- select 菜单选择
- 循环
- 数组循环
- 花括号迭代
- seq 设置起始增量
- 函数
- 数组
- set 命令
- 脚本调用堆栈
- mktemp 命令,trap 命令
- Bash 启动环境
- 命令提示符
- 颜色
- 第三方脚本
- trash.sh 删除进回车站
- centos 7
- 安装 gui
- yum
- 切换 yum 源
- 建立 yum 仓库
- rpm
- .src.rpm 包含源码的rpm包
- rpm2cpio 只获取 rpm 包内文件
- rpmbuild 制作 rpm 包
- rpmbuid 命令
- 布局说明
- 变量说明
- macros rpmbuild 宏文件
- Group 分组
- 实例
- 通用模版
- nginx 实例
- 注册为 systemctl 服务
- 一个同时匹配 rpm 与deb 的脚本
- 支持 jenkins
- ubuntu
- 安装图形化
- 美化界面
- apt
- dpkg
- 制作 deb 包
- UOS
- 数据库
- 知识
- CTE 创建SQL变量
- 自联结
- 临时函数
- over 窗口函数
- mysql / sqlServer / oracle 共性
- 创建一个大量表的sql
- 开源库
- readyset 自动缓存
- ODBC
- Centos 安裝 ODBC
- Windows 安装 ODBC
- Mysql / MariaDB
- 安装
- windows
- linux 编译安装
- 精简大小
- mariadb-win-my.ini 配置文件
- 场景
- 数据库远程登录
- 打印全部日志
- 开启慢查询
- 清除/关闭 查询缓存
- 查看 cpu 占用过高
- 取消严格模式
- 修改/忘记 密码
- 主从复制
- 服务无法启动
- mysql 分区
- 备份还原
- 基于 时间/位置 恢复
- 完整的 mysqldump 备份与恢复示例
- crontab定时备份脚本
- 新账号设置只读权限
- 技巧
- 查看性能情况
- sql 技巧
- my.cnf 文件读取优先级
- conf 文件优先级
- MySQL 函数
- 运算符
- 字符串函数
- 数字函数
- 日期函数
- 高级函数
- 可执行命令
- Mariabackup 热备份工具
- mysqlslap 性能测试工具
- mysqladmin
- mysqlcheck 修复/优化/分析表
- mysqld_safe
- mysqldump
- mysqlbinlog 操作记录
- 第三方库
- soar sql检查
- soar-web web-ui 版本
- vitess 集群化
- 字段类型说明
- kingshard mysql 代理选择使用主或从执行 sql
- PostgreSQL
- 安装
- 场景
- 问题
- 重置密码
- 批量mock数据
- 命令行
- psql
- pg_dump / pg_dumpall
- pg_restore
- pgbench
- createuser 创建用户
- 技巧
- USING 关联表
- 查看表结构
- 物化视图(读多写少缓存)
- Notify-Listen
- 语法
- 数据类型
- 数值类型
- 数组类型
- JSON 类型
- HSTORE 键值对存储
- 枚举类型
- 组合类型
- 范围类型
- tsvector 文本搜索类型
- 函数和操作符
- php 原生中文分词
- 外部数据源
- mysql 数据源
- mongo数据源
- 文件源监控
- redis_fdw
- file_fdw
- 增删改查
- 表操作
- 模式操作
- 表继承
- WITH 查询
- 树结构表
- 分表
- CHECK 检查约束
- 域类型
- 图数据库
- 索引类型
- 数据库操作
- EXPLAIN
- 高可用
- 插件
- pglogical 订阅发布-逻辑复制
- 订阅发布
- PostGIS 几何空间,地理
- TimescaleDB 时序
- pg_stat_statements
- pgcrypto
- pg_trgm 索引前后模糊查找
- Citus 水平扩展
- uuid-ossp
- pg_jieba 中文分词
- pgpool-II 主从和负债均衡和缓存
- 三方库
- postgrest
- 配置文件
- RESET API 参数
- 客户端封装请求
- preset go实现
- pgx 三方库
- ParadeDB 可媲美 Elasticsearch
- Oracle
- pkg-config 安装
- SQL Server
- sqlite
- 扩展
- FTS5 全文索引
- 内存数据库
- JSON 处理
- R-Tree 地理位置
- WebAssembly 版
- 库
- 示例
- rqlited 分布式sqlite
- ==== 关系型数据库 ====
- TiDB mysql 协议 可分布式
- CockroachDB postgresql 协议
- go-实例
- FerretDB -MongoDB协议,go 实现
- ==== golang 实现====
- MemSQL
- 示例
- go
- VoltDB
- 示例
- golang
- ==== 内存关系型数据库 ====
- 金仓数据库 仿Pgsql
- 安装
- 技巧
- 配置 odbc
- 问题
- SQL 语法
- 调用
- goalng 调用
- php 调用
- 达梦数据库 仿oracle
- sql 语法
- php 注意事项
- pdo thinkphp6 迁移工具适配器
- OceanBase 阿里
- ==== 国产化数据库 ====
- clickhouse
- Hbase
- ==== 列数据库 ====
- MongoDB
- 技巧
- 打开慢查询
- 场景
- 删除对象数组中的某条记录
- 用户认证
- 索引 设置过期索引 / 全文检索
- 自增id
- 数据库/表操作
- 原子操作
- 固定集合 | 用于存放日志
- 多表关系
- 分片(分布式集群)
- 3.x 版本
- 4.2 版本 [ 4.0集群切片增加不会转义数据 ]
- 搭建集群
- 删除切片
- 设置 Balancer 运行时间
- 以文件方式启动,推荐配置
- mongo分片集群添加登录认证
- 数据备份
- GridFS 文件存储
- golang 操作 mongo
- MapReduce 统计
- Redis
- 字符串 / 列表 / Hash / Set / Zet / 基数统计算法
- 队列 /订阅发布 php实例
- 事务 / bitmap 位图 / 地理位置
- 管道 / 分布式锁
- 备份与恢复 / 性能测试
- 设置密码 / 模糊查询
- 性能优化
- 监听过期 key
- docker 集群
- php 连接集群
- 单机测试集群 (官方一键安装)
- 生成环境 官方集群
- Codis 分布式 Redis 解决方案
- 主从模式 / 哨兵模式
- Memcached
- LevelDB kv 存储 google开源
- golang 示例
- dragonfly 内存型,兼容Redis与Memcached
- RethinkDB
- ==== 非关系型数据库 ====
- influxdb 数据库(用于日志存储)
- ==== 时序数据库 ====
- neo4j
- 安装
- Cypher查询语言
- 示例
- go
- ==== 图形数据库 ====
- zincsearch 轻量级全文搜索引擎 [go实现]
- 索引
- 数据
- 搜索
- Elasticsearch 全文搜索引擎
- index(索引)操作
- type(表)操作
- ElasticHD 可视化 docke 安装
- elasticsearch-head 可视化
- 集群部署
- 支持 php
- 增删改查
- 封装成 mdel
- gofound- go 实现的全文索引
- sphinx
- 示例
- 快速入门
- ==== 轻量级全文搜索引擎 ====
- undb 网页数据-带RESTAPI
- 消息队列
- RabbitMQ
- Direct 直发模式 php 版
- Fanout 分发模式 php 版
- Topic 模糊模式 php 版
- Zeromq
- go-zmq4 使用教程
- NSQ [2.7k] go实现的,部署简单
- nats
- Kafka
- 分布式对象存储
- minio 分布式对象存储
- 将MySQL / MongoDB 等 备份存储到MinIO Server
- 通过 nginx 代理 调用 monio
- hadoop 分布式 分布式存储
- 伪分布式版
- 集群版
- go 调用
- Hadoop Shell命令
- WebHDFS REST API (使用curl)
- JuiceFS 分布式文件存储
- 安装
- 示例
- SQLite 和阿里云 OSS 对象
- 服务发现
- Consul [21.9K]
- 安装
- etcd [35.6k]
- 命令
- etcdctl
- 示例
- go 操作 etcd
- go 服务发现实现
- 搭建etcd集群
- 搭建单机集群
- 架构设计
- 软件架构
- DDD分层
- Go示例
- 分层架构
- 事件驱动架构
- 微核架构(插件架构)
- 微服务架构
- 微服务三剑客
- 熔断
- 限流
- 负载均衡
- API 网关
- 云架构 - 最容易扩展的架构
- 数据库设计
- dept_code 具有层级关系的子层级
- 数据库规范
- slq 优化
- 索引失效的场景
- 认证
- 开放平台认证
- 双因素认证
- APP 的 token 认证
- JWT - JSON Web Token 验证
- OAuth 2.0
- HTTP 接口设计
- 签名设计
- Go 签名验证
- PHP 签名验证
- 幂等性设计
- 接口限流
- 原子计数器
- 漏桶算法
- 令牌桶算法-常用
- 网关层限流
- RPC
- json-rpc_2.0 规范
- HTTPS 升级指南
- 快速入门
- Let's Encrypt 免费证书
- RESTful 规范
- 设计API
- 常用状态码
- 缓存
- 压缩
- 安全
- API版本控制
- 内容协商
- application/vnd.api+json 响应格式(太啰嗦,不推荐)
- JAX-RS 2.0 [Java API]
- API文档
- apidoc [8.6k]生成文档
- showdoc [7.8k]技术文档、API 文档
- swagger
- OpenAPI
- go-swagger
- meta
- route
- parameters
- response
- model
- 示例
- swag go的实现
- hello world
- gin 集成
- 组件文档
- docsify 运行时解析
- dumi 为组件开发
- yaml / toml 等配置文件
- yaml 配置文件用法
- toml
- 持续集成
- 概念
- Jenkins 和 Gitlab 交互
- README 规范
- 徽章
- 代理
- Connect 代理
- 分布式系统
- 分布式 ID 生成器
- 雪花算法
- UUID
- NanoID
- 分布式锁
- 延时(定时)任务系统
- 分布式搜索引擎
- 负载均衡
- 分布式配置管理
- 分布式爬虫
- 分布式事务管理器
- 加密
- PGP
- GPG 命令
- 示例
- 生成 pgp 证书
- golang 示例
- monorepos 多子模块管理
- 相关工具
- 管理最佳实践
- 发布方式
- 服务器分批
- 业务分批
- 通用代码技巧
- 日志平台设计
- ELK 组合
- PaaS架构教程
- 邮箱协议
- 软件开发模式
- 敏捷开发
- 自动生成更新日志
- git-chglog 2.7k
- git-cliff 9.1k
- 概念
- 系统
- 进程
- Poll 与 Epoll
- 文件描述符
- 管道符
- 进程与线程的区别
- 进程状态
- 死锁 / 活锁
- 文件锁
- 孤儿进程 / 僵尸进程
- 进程间通信
- 共享内存
- Cgroups 资源隔离-docker基础
- Namespaces 资源隔离
- 内存堆栈
- POSIX
- umask 文件创建掩码
- sendfile 优化文件传输
- 加密
- 证书相关(如:ssl,pem 等)
- 网络
- HTTP
- 状态码
- 请求方法
- 响应头信息
- http缓存相关
- IP / 子网掩码 / 网关
- 大端序/小端序
- cookie-http-only
- 静态网站
- hugo 48.4K 静态网页
- hexo 31.7K 创建博客
- 开源协议说明
- 正则
- IP 说明
- 0.0.0.0
- 255.255.255.255 广播
- 127.0.0.1
- 224.0.0.1 组播(多播)
- golang 示例
- 169.254.x.x
- 私有地址
- 视频课程
- go 微服务抢红包
- 计算机组成原理+操作系统+计算机网络
- 计算机组成
- 计算机总线
- 存储器
- 高速缓存
- 计算机的指令系统
- 计算机的控制器
- 计算机的运算器
- 计算机指令的执行过程
- 进制运算
- 三种编码方式 原码 / 补码 / 反码
- 定点数 / 浮点数
- 浮点数的运算
- 操作系统
- 进程
- 进程实体
- 五状态模型
- 进程同步
- 线程同步
- Linux的进程管理
- 进程调度
- 死锁
- 存储管理
- 内存分配与回收
- 页式存储管理
- 虚拟内存
- Linux的内存管理
- 页内碎片与页外碎片
- Budy内存管理算法
- Linux交换空间
- 文件管理
- 文件的逻辑结构
- 辅存的存储空间分配
- 文件系统
- 文件系统分类
- EXT文件系统
- 设备管理
- 广义的O设备
- lO设备的缓冲区
- SPOOLing技术
- 线程同步
- 互斥量(锁)
- 自旋锁
- 读写锁
- 条件变量
- 线程同步
- fork 创建进程
- Unix域套接字
- 计算机网络
- ISP
- OSI 七层模型
- 网络拓扑
- 网络层 IP
- IP
- 传输层 UDP/TCP
- UDP
- TCP
- 可靠传输
- 流量控制
- 拥塞控制
- 三次握手
- 四次挥手
- 应用层
- DNS 域名解析
- DHCP 协议
- HTTP 协议
- 编译原理/操作系统/图形学
- 一.计算机
- 汇编
- 中断和中断向量
- 三.编译原理
- 编译器和解释器
- 编译流程
- 四.词法
- 流
- 词法
- 用状态机提取词语(lexer)
- 完整的词法分析器-多状态机合并
- 五.抽象语法树
- 抽象语法树的继承 (parser)
- 递归法求抽象语法树
- 表达式树的验证
- 块和语句
- 六.三地址代码
- 基于 SDD 的翻译
- 词法作用域与符号表
- 符号表
- 三地址表示
- 翻译的整体过程和表达式
- 七. 创建虚拟机
- 用虚拟机执行程序
- 将三地址代码转为指令
- 八.操作系统
- 内核
- 九.程序
- 抽象-进程
- 线程
- 竞争条件和临界区
- 信号量与互斥量
- 十.调度
- 调度
- 优先队列
- 十一.内存
- 分层存储
- 垃圾回收
- 地址空间
- 虚拟内存,页面,MMU
- 程序对内存的管理
- 垃圾回收
- 引用计数
- 标记,扫地,整理
- 分代算法
- 十二.文件系统
- 文件系统和磁盘
- 文件
- 共享文件和目录
- VFS和基于日志的文件系统
- epoll与select
- 十三.图形学
- 向量
- 向量的叉积与点积
- 圆的世界
- 矩阵运算
- 三角形网络
- 渲染图形
- 十四.WebGL
- 绘制2D图形
- GLSL
- 图形渲染管道
- 球面的坐标
- Go微服务入门到容器化实践,落地可观测的微服务电商项目
- 第一章 学习指南
- 第二章 微服务与DDD
- 第四章 注册配置中心实现
- 第六章 熔断/限流/负载均衡
- 熔断
- 安装 Hystrix Dashboard
- 限流
- 负载均衡
- 书籍
- linux鸟哥的私房菜
- 目录
- 数据结构和算法(Golang实现)
- 递归和尾递归
- 算法复杂度及渐进符号
- 链表
- 字典
- 树
- 分治法应用
- 快速排序
- 归并排序
- 排序算法
- 冒泡排序 最差,不推荐
- 选择排序
- 插入排序
- 希尔排序
- 归并排序
- 优先队列及堆排序
- 快速排序
- 查找算法
- 哈希表:散列查找
- 二叉查找树
- AVL树 比二叉树低的树
- 2-3树和左倾红黑树
- 2-3-4树和普通红黑树
- labuladong的算法小抄
- 第零章、必读系列
- 学习算法和刷题的框架思维
- 动态规划解题套路框架
- 回溯算法解题套路框架
- BFS 算法解题套路框架
- 二分搜索
- 滑动窗口算法
- 股票买卖问题
- 常见知识
- 搜索引擎背后的经典数据结构和算法
- 架构师之路
- 消息系统
- QQ状态同步究竟是推还是拉
- 在线消息可靠传递
- 分布式ID生成方法
- 负载均衡
- 数据库与缓存
- 数据库软件架构
- 高并并发下 - 为表新增字段
- 数据库垂直拆分
- 数据平滑数据迁移
- 数据库秒级平滑扩容
- 计数系统架构实践
- 应用层/安全层/传输层协议选型
- MQ 消息队列
- 到底什么时候该使用MQ
- 实现延迟消息
- 实现消息必达
- 定时任务触发(如用户离线判断)
- 超高并发的无锁缓存
- 连接池实现
- TCP/IP 详情卷一
- IP:网际协议
- Ping 程序
- UDP 用户数据报协议
- TCP的超时与重传
- Go 语言圣经
- 入门
- 锁的原理
- 互斥锁
- Goroutines和线程
- 小团队构建大网站:中小研发团队架构实践
- 企业中体架构
- 消息中间键 RabbitMQ
- Redis
- 任务调度Job
- 应用监控系统 Metrics
- 集中式日志ELK
- 搜索服务Solr
- 分布式协调器 ZooKeeper
- Jenkins 自动构建
- 单点登录
- 企业支付网关
- 研发团队文化是怎么“长”出来的
- HTDP 程序设计方法
- 第二章 数、表达式和简单程序
- 第七章 数据混合与区分
- 第九章 复合数据类型
- 第十章 表的进一步处理
- 第十一章 处理任意大的自然数
- 第十二章 三论符合函数
- 第十三章 用 list 构造表
- 第十四章 再论自引用数据的定义
- 第十六章 反复精化设计
- 第十七章 处理两种复杂数据
- 第十八章局部定义和词汇的范围
- 代码大全
- 第三章 三思而后行:前期准备
- 架构的典型组成部分
- 花费在前期准备上的时间长度
- 第五章 软件构造中的设计
- 理想的设计特征
- 设计的层次
- 常见设计模式
- 第六章 可以工作的类
- 好的抽象
- 良好的类接口
- 有关设计和实现的问题
- 构造函数
- 第七章 高质量的子程序
- 好的子程序名
- 如何使用子程序参数
- 宏子程序和内联子程序
- 第十章 使用变量的一般事项
- 持续性
- 绑定时间
- 第十一章 变量名的力量
- 选择好变量名的注意事项
- 为特定类型的数据命名
- 非正式命名规则
- 第十二章基本的数据类型
- 字符和字符串
- 布尔
- 枚举
- 第十三章 不常见的数据类型
- 结构体
- 指针 [推荐反复查看]
- 第十五章 使用条件语句
- 第十六章 控制控制
- goto
- 第十七章 不常见的控制结构
- 递归
- 第十八章 表驱动法
- 直接访问表
- 索引表访问
- 阶梯访问表
- 第十九章 一般控制问题
- 减少嵌套层次
- 复杂度的重要性
- 第二十二章 开发者测试
- 第二十四章 重构
- 重构的理由
- 特定的重构
- 语句级的重构
- 子程序级重构
- 类实现的重构
- 类接口的重构
- 系统级重构
- 安全的重构
- 第26章 代码调整方式
- 循环
- 表达式
- 将子程
- 变得越多,事情反而没变
- 计算机程序的构造和解释(SICP)
- 第一章 构造过程抽象
- 1.1 程序设计的基本元素
- 1.3 用高阶函数做抽象
- 函数式编程指北
- 第二章 一等公民的函数
- 第三章 纯函数的好处
- 第四章 柯里化(curry)
- 第五章 代码组合(compose)
- 范畴学
- 习题
- 第六章 示例应用
- 声明式代码
- 实例项目:获取图片
- 第七章 Hindley-Milner 类型签名
- 第八章 特百惠
- functor / Maybe
- 纯错误处理
- 包裹函数 - IO
- 异步任务
- 练习
- 第九章 Monad
- pointed functor
- chain
- 练习
- Applicative Functor
- 设计数据密集型应用
- 第一章 可靠性,可扩展性,可维护性
- 第二章 数据模型与查询语言
- 第三章 数据与索引
- 第四章 编码与演化
- 第五章 复制
- 第六章 分区
- 第七章 事务
- 第八章 分布式系统的麻烦
- 第九章 一致性与共识
- Unix 编程艺术
- 一.哲学
- 十一:最小立异原则
- 十二.优化
- 十三:复杂度
- 十九:开放源码:在Uniⅸ新社区 中编程
- 设计模式
- 创建型模式
- 简单工厂方法模式
- php 示例
- go 示例
- 抽象工厂模式
- php 示例
- go 示例
- 生成器模式
- php 示例
- go 示例
- 原型模式 - 克隆
- php 示例
- go 示例
- 单例模式
- php 示例
- go 示例
- 结构型模式
- 适配器模式
- php 示例
- go 示例
- 桥接模式 [❤❤]
- php 示例
- go 示例
- 组合模式
- php 示例
- go 示例
- 装饰模式 - 钩子 [❤❤❤]
- php 示例
- go 示例
- 外观模式
- php 示例
- go 示例
- 享元模式
- go 示例
- 代理模式 [❤❤❤]
- php 示例
- go 示例
- 行为模式
- 责任链模式[❤❤❤]
- php 示例
- go 示例
- 命令模式
- php 示例
- go 示例
- 迭代器模式
- php 示例
- go 示例
- 中介者模式
- php 示例
- go 示例
- 备忘录模式
- php 示例
- go 示例
- 观察者(发布订阅)模式[❤❤❤]
- php 示例
- go 示例
- 状态模式 - 状态机
- php 示例
- go 示例
- 策略模式[❤❤❤]
- php 示例
- go 示例
- 模板方法[❤❤❤]
- php 示例
- go 示例
- 访问者模式
- php 示例
- go 示例
- 数据结构
- 数组
- 双指针
- 字符串
- 找子串
- 栈 / 队列
- 循环队列
- 列表 List
- 排序算法
- 链表
- 遍历
- 翻转链表
- 树
- 二叉树
- 二叉树遍历
- DFS 深度优先
- BFS 广度优先
- 示例
- 二叉树的最大深度
- 对称二叉树
- 将有序数组转换为二叉搜索树
- 算法
- 查找算法
- KMP 算法
- 跳表
- Sunday算法
- 动态规划
- 爬楼梯
- 最大子序和
- 零钱问题
- 分布式算法
- Raft
- hashicorp/raft go 实现
- 贝叶斯算法
- python 示例
- 人工智能
- 知识
- 基础概念与入门案例
- 语言模型
- 注意力机制
- Transformers pipelines
- 开源项目
- DiffBIR 图片项目
- TokenFlow 视频语言渲染
- ProPainter 去除视频人物
- CodeFormer 图片画质增强
- yolov5 物品识别
- 训练自己的模型
- Donut 无需OCR识别图片内容
- ott 翻译
- VideoPipe 视频物品识别
- 基础库
- PyTorch
- 安装
- TensorFlow
- 大语言模型架构
- Awesome
- JittorLLMs
- ollama
- huggingface
- transformers
- pipeline 的处理流程
- 离线模式
- 模型处理
- 示例
- 常用 pipelines
- 使用gpt2
- 翻译
- Q&A
- 汇编
- MIPS
- 指令集
- 加载/保存 指令集
- 算术指令集
- 控制流 指令集
- SS, SP, BP 三个寄存器
- 音视频
- 知识
- 几种浏览器播放RTSP视频流解决方案
- 流媒体播放格式
- 流媒体传输协议(rtp/rtcp/rtsp/rtmp/)
- 常用工具/库
- EasyDarwin
- EasyDarwin RTSP流媒体服务器-GO
- EasyPusher
- EasyDSS 非开源 RTMP
- EasyScreenLive 录制推流
- ZLMediaKit 流媒体服务框架 c++
- 基于ZLMediaKit的UI
- lal 流媒体服务器 GOLANG
- go2rtc 支持各种流媒体协议
- RTP/RTCP
- RTP
- RTCP
- RTSP
- 知识
- RTSP/RTP 交错传输方式
- RTP timestamp
- rtsp组播
- 语法
- OPTIONS 询问
- DESCRIBE 询问SDP
- SETUP 设置传输模式
- PLAY 启动
- PAUSE 暂停
- TEARDOWN 终止
- SET_PARAMETER 生成一个I帧
- GET_PARAMETER 查询参数状态
- RTSP 响应状态码
- 示例
- ffmpeg 推流到rtsp服务器基于udp
- ffplay 拉取rtsp流,基于udp
- ============
- ffmpeg 推流到rtsp服务器基于tcp
- ffplay 拉取基于TCP的rtsp流
- ===========
- EasyScreenLive 推送rtsp服务器 基于tcp
- RTMP
- 术语
- 消息和块的区别
- 协议流程
- 分块
- RTMP消息格式
- RTMP消息类型
- 视频协议
- H.264
- STUN / TURN
- MCU合流
- SDP协议
- SIP