
## 新建、索引和删除文档
新建、索引和删除请求都是**写(write)**操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
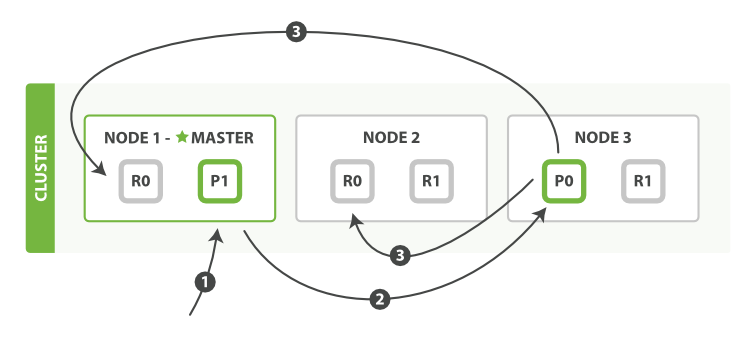
下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
1. 客户端给`Node 1`发送新建、索引或删除请求。
2. 节点使用文档的`_id`确定文档属于分片`0`。它转发请求到`Node 3`,分片`0`位于这个节点上。
3. `Node 3`在主分片上执行请求,如果成功,它转发请求到相应的位于`Node 1`和`Node 2`的复制节点上。当所有的复制节点报告成功,`Node 3`报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
有很多可选的请求参数允许你更改这一过程。你可能想牺牲一些安全来提高性能。这一选项很少使用因为Elasticsearch已经足够快,不过为了内容的完整我们将做一些阐述。
### `replication`
复制默认的值是`sync`。这将导致主分片得到复制分片的成功响应后才返回。
如果你设置`replication`为`async`,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
上面的这个选项不建议使用。默认的`sync`复制允许Elasticsearch强制反馈传输。`async`复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。
### `consistency`
默认主分片在尝试写入时需要**规定数量(quorum)**或过半的分片(可以是主节点或复制节点)可用。这是防止数据被写入到错的网络分区。规定的数量计算公式如下:
int( (primary + number_of_replicas) / 2 ) + 1
`consistency`允许的值为`one`(只有一个主分片),`all`(所有主分片和复制分片)或者默认的`quorum`或过半分片。
注意`number_of_replicas`是在索引中的的设置,用来定义复制分片的数量,而不是现在活动的复制节点的数量。如果你定义了索引有3个复制节点,那规定数量是:
int( (primary + 3 replicas) / 2 ) + 1 = 3
但如果你只有2个节点,那你的活动分片不够规定数量,也就不能索引或删除任何文档。
### `timeout`
当分片副本不足时会怎样?Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置`timeout`参数让它终止的更早:`100`表示100毫秒,`30s`表示30秒。
> 注意:
> 新索引默认有`1`个复制分片,这意味着为了满足`quorum`的要求**需要**两个活动的分片。当然,这个默认设置将阻止我们在单一节点集群中进行操作。为了避开这个问题,规定数量只有在`number_of_replicas`大于一时才生效。
- Introduction
- 入门
- 是什么
- 安装
- API
- 文档
- 索引
- 搜索
- 聚合
- 小结
- 分布式
- 结语
- 分布式集群
- 空集群
- 集群健康
- 添加索引
- 故障转移
- 横向扩展
- 更多扩展
- 应对故障
- 数据
- 文档
- 索引
- 获取
- 存在
- 更新
- 创建
- 删除
- 版本控制
- 局部更新
- Mget
- 批量
- 结语
- 分布式增删改查
- 路由
- 分片交互
- 新建、索引和删除
- 检索
- 局部更新
- 批量请求
- 批量格式
- 搜索
- 空搜索
- 多索引和多类型
- 分页
- 查询字符串
- 映射和分析
- 数据类型差异
- 确切值对决全文
- 倒排索引
- 分析
- 映射
- 复合类型
- 结构化查询
- 请求体查询
- 结构化查询
- 查询与过滤
- 重要的查询子句
- 过滤查询
- 验证查询
- 结语
- 排序
- 排序
- 字符串排序
- 相关性
- 字段数据
- 分布式搜索
- 查询阶段
- 取回阶段
- 搜索选项
- 扫描和滚屏
- 索引管理
- 创建删除
- 设置
- 配置分析器
- 自定义分析器
- 映射
- 根对象
- 元数据中的source字段
- 元数据中的all字段
- 元数据中的ID字段
- 动态映射
- 自定义动态映射
- 默认映射
- 重建索引
- 别名
- 深入分片
- 使文本可以被搜索
- 动态索引
- 近实时搜索
- 持久化变更
- 合并段
- 结构化搜索
- 查询准确值
- 组合过滤
- 查询多个准确值
- 包含,而不是相等
- 范围
- 处理 Null 值
- 缓存
- 过滤顺序
- 全文搜索
- 匹配查询
- 多词查询
- 组合查询
- 布尔匹配
- 增加子句
- 控制分析
- 关联失效
- 多字段搜索
- 多重查询字符串
- 单一查询字符串
- 最佳字段
- 最佳字段查询调优
- 多重匹配查询
- 最多字段查询
- 跨字段对象查询
- 以字段为中心查询
- 全字段查询
- 跨字段查询
- 精确查询
- 模糊匹配
- Phrase matching
- Slop
- Multi value fields
- Scoring
- Relevance
- Performance
- Shingles
- Partial_Matching
- Postcodes
- Prefix query
- Wildcard Regexp
- Match phrase prefix
- Index time
- Ngram intro
- Search as you type
- Compound words
- Relevance
- Scoring theory
- Practical scoring
- Query time boosting
- Query scoring
- Not quite not
- Ignoring TFIDF
- Function score query
- Popularity
- Boosting filtered subsets
- Random scoring
- Decay functions
- Pluggable similarities
- Conclusion
- Language intro
- Intro
- Using
- Configuring
- Language pitfalls
- One language per doc
- One language per field
- Mixed language fields
- Conclusion
- Identifying words
- Intro
- Standard analyzer
- Standard tokenizer
- ICU plugin
- ICU tokenizer
- Tidying text
- Token normalization
- Intro
- Lowercasing
- Removing diacritics
- Unicode world
- Case folding
- Character folding
- Sorting and collations
- Stemming
- Intro
- Algorithmic stemmers
- Dictionary stemmers
- Hunspell stemmer
- Choosing a stemmer
- Controlling stemming
- Stemming in situ
- Stopwords
- Intro
- Using stopwords
- Stopwords and performance
- Divide and conquer
- Phrase queries
- Common grams
- Relevance
- Synonyms
- Intro
- Using synonyms
- Synonym formats
- Expand contract
- Analysis chain
- Multi word synonyms
- Symbol synonyms
- Fuzzy matching
- Intro
- Fuzziness
- Fuzzy query
- Fuzzy match query
- Scoring fuzziness
- Phonetic matching
- Aggregations
- overview
- circuit breaker fd settings
- filtering
- facets
- docvalues
- eager
- breadth vs depth
- Conclusion
- concepts buckets
- basic example
- add metric
- nested bucket
- extra metrics
- bucket metric list
- histogram
- date histogram
- scope
- filtering
- sorting ordering
- approx intro
- cardinality
- percentiles
- sigterms intro
- sigterms
- fielddata
- analyzed vs not
- 地理坐标点
- 地理坐标点
- 通过地理坐标点过滤
- 地理坐标盒模型过滤器
- 地理距离过滤器
- 缓存地理位置过滤器
- 减少内存占用
- 按距离排序
- Geohashe
- Geohashe
- Geohashe映射
- Geohash单元过滤器
- 地理位置聚合
- 地理位置聚合
- 按距离聚合
- Geohash单元聚合器
- 范围(边界)聚合器
- 地理形状
- 地理形状
- 映射地理形状
- 索引地理形状
- 查询地理形状
- 在查询中使用已索引的形状
- 地理形状的过滤与缓存
- 关系
- 关系
- 应用级别的Join操作
- 扁平化你的数据
- Top hits
- Concurrency
- Concurrency solutions
- 嵌套
- 嵌套对象
- 嵌套映射
- 嵌套查询
- 嵌套排序
- 嵌套集合
- Parent Child
- Parent child
- Indexing parent child
- Has child
- Has parent
- Children agg
- Grandparents
- Practical considerations
- Scaling
- Shard
- Overallocation
- Kagillion shards
- Capacity planning
- Replica shards
- Multiple indices
- Index per timeframe
- Index templates
- Retiring data
- Index per user
- Shared index
- Faking it
- One big user
- Scale is not infinite
- Cluster Admin
- Marvel
- Health
- Node stats
- Other stats
- Deployment
- hardware
- other
- config
- dont touch
- heap
- file descriptors
- conclusion
- cluster settings
- Post Deployment
- dynamic settings
- logging
- indexing perf
- rolling restart
- backup
- restore
- conclusion