
# CI/CD development documentation
> 原文:[https://docs.gitlab.com/ee/development/cicd/](https://docs.gitlab.com/ee/development/cicd/)
* [CI Architecture overview](#ci-architecture-overview)
* [Job scheduling](#job-scheduling)
* [Communication between Runner and GitLab server](#communication-between-runner-and-gitlab-server)
* [`Ci::RegisterJobService`](#ciregisterjobservice)
# CI/CD development documentation[](#cicd-development-documentation "Permalink")
此处列出了特定于 CI / CD 的开发指南.
如果要创建新的 CI / CD 模板,请阅读[GitLab CI / CD 模板的开发指南](templates.html) .
## CI Architecture overview[](#ci-architecture-overview "Permalink")
以下是 CI 体系结构的简化图. 为了集中在主要组件上,省略了一些细节.
[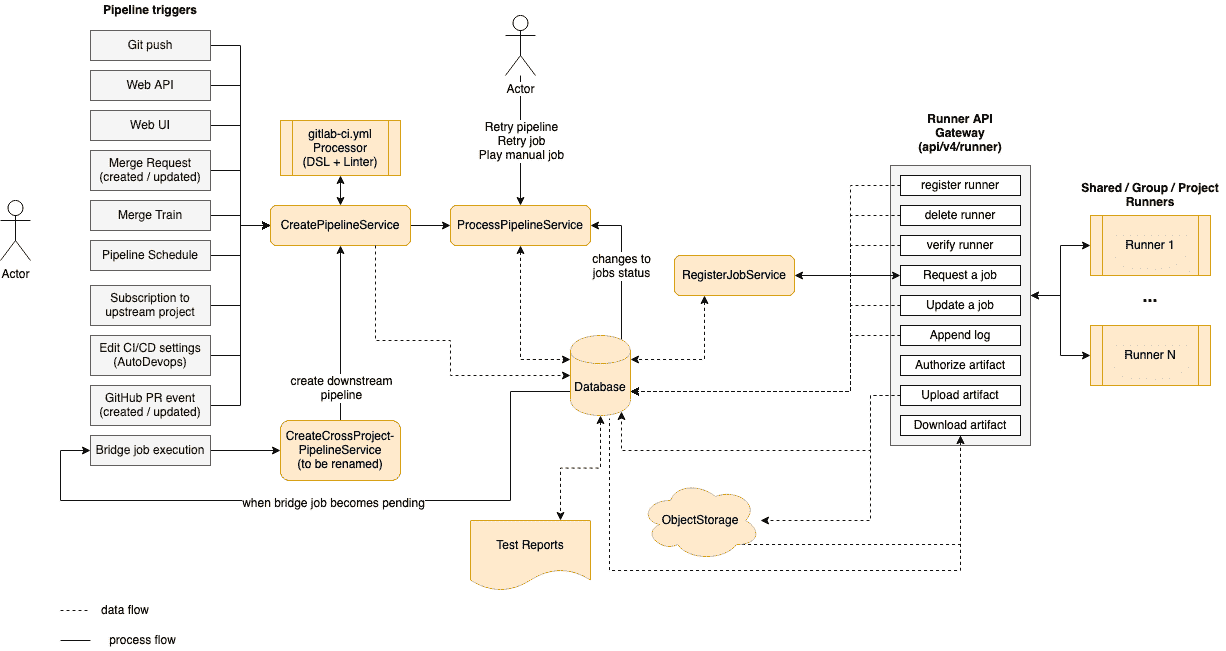](img/ci_architecture.png)
在左侧,我们有一些事件可以根据各种事件触发管道(由用户或自动化触发):
* `git push`是触发管道的最常见事件.
* The [Web API](../../api/pipelines.html#create-a-new-pipeline).
* 用户单击 UI 中的"运行管道"按钮.
* [创建或更新合并请求时](../../ci/merge_request_pipelines/index.html#pipelines-for-merge-requests) .
* 将 MR 添加到[合并列车时](../../ci/merge_request_pipelines/pipelines_for_merged_results/merge_trains/index.html#merge-trains-premium) .
* A [scheduled pipeline](../../ci/pipelines/schedules.html#pipeline-schedules).
* 当项目被[订阅到上游项目时](../../ci/multi_project_pipelines.html#trigger-a-pipeline-when-an-upstream-project-is-rebuilt) .
* 启用[自动 DevOps 时](../../topics/autodevops/index.html) .
* 当 GitHub 集成用于[外部请求请求时](../../ci/ci_cd_for_external_repos/index.html#pipelines-for-external-pull-requests) .
* 当上游管道包含[桥接作业时](../../ci/yaml/README.html#trigger) ,该[作业](../../ci/yaml/README.html#trigger)会触发下游管道.
触发任何这些事件将调用[`CreatePipelineService`](https://gitlab.com/gitlab-org/gitlab/-/blob/master/app/services/ci/create_pipeline_service.rb) ,后者将输入事件数据并触发用户,然后尝试创建管道.
`CreatePipelineService`很大程度上依赖于[`YAML Processor`](https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/ci/yaml_processor.rb)组件,该组件负责将 YAML Blob 作为输入并返回管道的抽象数据结构(包括阶段和所有作业). 该组件还可以在处理 YAML 时验证其结构,并返回任何语法或语义错误. 在`YAML Processor`组件中,我们定义了[所有](../../ci/yaml/README.html)可用于构建管道[的关键字](../../ci/yaml/README.html) .
`CreatePipelineService`接收`YAML Processor`返回的抽象数据结构,然后将其转换为持久化模型(管道,阶段,作业等). 之后,就可以处理管道了. 处理管道意味着按执行顺序(阶段或 DAG)运行作业,直到以下任一情况为止:
* 所有预期的作业均已执行.
* 故障会中断管道执行.
处理管道的组件是[`ProcessPipelineService`](https://gitlab.com/gitlab-org/gitlab/-/blob/master/app/services/ci/process_pipeline_service.rb) ,它负责将所有管道的作业移至完成状态. 创建管道时,其所有作业最初都处于`created`状态. 该服务根据流水线结构查看在`created`阶段可以处理哪些作业. 然后,它们将它们移到`pending`状态,这意味着它们现在[可以被 Runner 拾取](#job-scheduling) . 执行作业后,它可以成功完成或失败. 管道中作业的每个状态转换都会再次触发此服务,该服务会寻找下一个要转换为完成的作业. 在此过程中, `ProcessPipelineService`更新作业,阶段和整个管道的状态.
在图的右侧,我们有一个列表[运动员](../../ci/runners/README.html#configuring-gitlab-runners)连接到 GitLab 实例. 这些可以是共享运行者,组运行者或项目特定的运行者. Runners 与 Rails 服务器之间的通信通过一组 API 端点(称为`Runner API Gateway` .
我们可以注册,删除和验证运行器,这也将导致对数据库的读/写查询. 连接了 Runner 之后,它会继续询问要执行的下一个作业. 这将调用[`RegisterJobService`](https://gitlab.com/gitlab-org/gitlab/blob/master/app/services/ci/register_job_service.rb) ,后者将选择下一个作业并将其分配给 Runner. 此时,作业将转换为`running`状态,由于状态更改,该状态再次触发`ProcessPipelineService` . 有关更多详细信息,请参阅" [作业调度"](#job-scheduling) .
在执行作业时,运行程序将日志以及任何可能需要存储的工件发送回服务器. 此外,作业可能依赖于先前作业中的工件才能运行. 在这种情况下,Runner 将使用专用的 API 端点下载它们.
工件存储在对象存储中,而元数据保留在数据库中. 工件的重要示例是报表(JUnit,SAST,DAST 等),这些报表在合并请求中进行了解析和呈现.
作业状态转换并非全部自动化. 用户可以运行[手动作业](../../ci/yaml/README.html#whenmanual) ,取消管道,重试特定的失败作业或整个管道. 导致作业更改状态的任何事件都将触发`ProcessPipelineService` ,因为它负责跟踪整个管道的状态.
一种特殊类型的作业是[桥接作业](../../ci/yaml/README.html#trigger) ,当过渡到`pending`状态时,该[作业](../../ci/yaml/README.html#trigger)在服务器端执行. 这项工作负责创建下游管道,例如多项目或子管道. 每次触发下游管道时,工作流程循环都将从`CreatePipelineService`重新开始.
## Job scheduling[](#job-scheduling "Permalink")
创建管道时,将为所有阶段一次创建所有作业,初始状态为`created` . 这使得可视化管道的全部内容成为可能.
跑步者将不会看到具有`created`状态的作业. 为了能够将作业分配给 Runner,该作业必须首先转换为`pending`状态,这在以下情况下可能发生:
1. 作业是在管道的第一阶段创建的.
2. 该作业需要手动启动,并且已被触发.
3. 前一阶段的所有作业均已成功完成. 在这种情况下,我们将所有工作从下一阶段过渡到`pending` .
4. 该作业使用`needs:`指定了 DAG 依赖项`needs:`并且所有依赖项都已完成.
连接了 Runner 时,它将通过连续轮询服务器来请求下一个`pending`作业运行.
**注意:** Runner 用于与 GitLab 交互的 API 端点在[`lib/api/runner.rb`](https://gitlab.com/gitlab-org/gitlab/blob/master/lib/api/runner.rb)中定义
服务器收到请求后,将根据[`Ci::RegisterJobService`算法](#ciregisterjobservice)选择`pending`作业,然后将其分配并发送给 Runner.
在当前阶段完成所有作业后,服务器通过将其状态更改为" `pending` ",从下一阶段"解锁"所有作业. 现在,当 Runner 请求新作业时,可以由调度算法选择这些内容,并像这样继续进行,直到完成所有阶段.
### Communication between Runner and GitLab server[](#communication-between-runner-and-gitlab-server "Permalink")
使用注册令牌[注册](https://docs.gitlab.com/runner/register/)了 Runner 之后,服务器便知道其可以执行的作业类型. 这取决于:
* 它注册的赛跑者类型为:
* 共享跑步者
* 团体赛跑者
* 项目特定的跑步者
* 任何关联的标签.
跑步者通过请求作业执行`POST /api/v4/jobs/request`来启动通信. 尽管轮询通常每隔几秒钟发生一次,但如果作业队列不变,我们将通过 HTTP 标头利用缓存来减少服务器端的工作量.
该 API 端点运行[`Ci::RegisterJobService`](https://gitlab.com/gitlab-org/gitlab/blob/master/app/services/ci/register_job_service.rb) ,该命令:
1. 从`pending`作业池中选择要运行的下一个作业
2. 分配给跑步者
3. 通过 API 响应将其呈现给 Runner
### `Ci::RegisterJobService`[](#ciregisterjobservice "Permalink")
此服务使用 3 个顶级查询来收集大多数作业,并且根据 Runner 注册到的级别选择它们:
* 选择共享的 Runner(实例级别)的作业
* 选择组级别运行器的作业
* 选择项目亚军的工作
This list of jobs is then filtered further by matching tags between job and Runner tags.
**注意:**如果作业包含标签,则与**所有**标签都不匹配的跑步者将不会选择该作业. 跑步者可能具有比该工作定义的标签更多的标签,但反之则没有.
最后,如果 Runner 仅能选择带标签的作业,则所有未带标签的作业都会被过滤掉.
在这一点上,我们遍历剩余的`pending`作业,然后尝试根据其他策略分配"可以选择" Runner 可以选择的第一个作业. 例如,标记为`protected`运行者只能选择针对受保护的分支(例如生产部署)运行的作业.
当我们增加池中的"奔跑者"数量时,如果将同一工作分配给不同"奔跑者",也会增加发生冲突的机会. 为防止这种情况,我们会适当地挽救冲突错误并在列表中分配下一个作业.
- GitLab Docs
- Installation
- Requirements
- GitLab cloud native Helm Chart
- Install GitLab with Docker
- Installation from source
- Install GitLab on Microsoft Azure
- Installing GitLab on Google Cloud Platform
- Installing GitLab on Amazon Web Services (AWS)
- Analytics
- Code Review Analytics
- Productivity Analytics
- Value Stream Analytics
- Kubernetes clusters
- Adding and removing Kubernetes clusters
- Adding EKS clusters
- Adding GKE clusters
- Group-level Kubernetes clusters
- Instance-level Kubernetes clusters
- Canary Deployments
- Cluster Environments
- Deploy Boards
- GitLab Managed Apps
- Crossplane configuration
- Cluster management project (alpha)
- Kubernetes Logs
- Runbooks
- Serverless
- Deploying AWS Lambda function using GitLab CI/CD
- Securing your deployed applications
- Groups
- Contribution Analytics
- Custom group-level project templates
- Epics
- Manage epics
- Group Import/Export
- Insights
- Issues Analytics
- Iterations
- Public access
- SAML SSO for GitLab.com groups
- SCIM provisioning using SAML SSO for GitLab.com groups
- Subgroups
- Roadmap
- Projects
- GitLab Secure
- Security Configuration
- Container Scanning
- Dependency Scanning
- Dependency List
- Static Application Security Testing (SAST)
- Secret Detection
- Dynamic Application Security Testing (DAST)
- GitLab Security Dashboard
- Offline environments
- Standalone Vulnerability pages
- Security scanner integration
- Badges
- Bulk editing issues and merge requests at the project level
- Code Owners
- Compliance
- License Compliance
- Compliance Dashboard
- Create a project
- Description templates
- Deploy Keys
- Deploy Tokens
- File finder
- Project integrations
- Integrations
- Atlassian Bamboo CI Service
- Bugzilla Service
- Custom Issue Tracker service
- Discord Notifications service
- Enabling emails on push
- GitHub project integration
- Hangouts Chat service
- Atlassian HipChat
- Irker IRC Gateway
- GitLab Jira integration
- Mattermost Notifications Service
- Mattermost slash commands
- Microsoft Teams service
- Mock CI Service
- Prometheus integration
- Redmine Service
- Slack Notifications Service
- Slack slash commands
- GitLab Slack application
- Webhooks
- YouTrack Service
- Insights
- Issues
- Crosslinking Issues
- Design Management
- Confidential issues
- Due dates
- Issue Boards
- Issue Data and Actions
- Labels
- Managing issues
- Milestones
- Multiple Assignees for Issues
- Related issues
- Service Desk
- Sorting and ordering issue lists
- Issue weight
- Associate a Zoom meeting with an issue
- Merge requests
- Allow collaboration on merge requests across forks
- Merge Request Approvals
- Browser Performance Testing
- How to create a merge request
- Cherry-pick changes
- Code Quality
- Load Performance Testing
- Merge Request dependencies
- Fast-forward merge requests
- Merge when pipeline succeeds
- Merge request conflict resolution
- Reverting changes
- Reviewing and managing merge requests
- Squash and merge
- Merge requests versions
- Draft merge requests
- Members of a project
- Migrating projects to a GitLab instance
- Import your project from Bitbucket Cloud to GitLab
- Import your project from Bitbucket Server to GitLab
- Migrating from ClearCase
- Migrating from CVS
- Import your project from FogBugz to GitLab
- Gemnasium
- Import your project from GitHub to GitLab
- Project importing from GitLab.com to your private GitLab instance
- Import your project from Gitea to GitLab
- Import your Jira project issues to GitLab
- Migrating from Perforce Helix
- Import Phabricator tasks into a GitLab project
- Import multiple repositories by uploading a manifest file
- Import project from repo by URL
- Migrating from SVN to GitLab
- Migrating from TFVC to Git
- Push Options
- Releases
- Repository
- Branches
- Git Attributes
- File Locking
- Git file blame
- Git file history
- Repository mirroring
- Protected branches
- Protected tags
- Push Rules
- Reduce repository size
- Signing commits with GPG
- Syntax Highlighting
- GitLab Web Editor
- Web IDE
- Requirements Management
- Project settings
- Project import/export
- Project access tokens (Alpha)
- Share Projects with other Groups
- Snippets
- Static Site Editor
- Wiki
- Project operations
- Monitor metrics for your CI/CD environment
- Set up alerts for Prometheus metrics
- Embedding metric charts within GitLab-flavored Markdown
- Embedding Grafana charts
- Using the Metrics Dashboard
- Dashboard YAML properties
- Metrics dashboard settings
- Panel types for dashboards
- Using Variables
- Templating variables for metrics dashboards
- Prometheus Metrics library
- Monitoring AWS Resources
- Monitoring HAProxy
- Monitoring Kubernetes
- Monitoring NGINX
- Monitoring NGINX Ingress Controller
- Monitoring NGINX Ingress Controller with VTS metrics
- Alert Management
- Error Tracking
- Tracing
- Incident Management
- GitLab Status Page
- Feature Flags
- GitLab CI/CD
- GitLab CI/CD pipeline configuration reference
- GitLab CI/CD include examples
- Introduction to CI/CD with GitLab
- Getting started with GitLab CI/CD
- How to enable or disable GitLab CI/CD
- Using SSH keys with GitLab CI/CD
- Migrating from CircleCI
- Migrating from Jenkins
- Auto DevOps
- Getting started with Auto DevOps
- Requirements for Auto DevOps
- Customizing Auto DevOps
- Stages of Auto DevOps
- Upgrading PostgreSQL for Auto DevOps
- Cache dependencies in GitLab CI/CD
- GitLab ChatOps
- Cloud deployment
- Docker integration
- Building Docker images with GitLab CI/CD
- Using Docker images
- Building images with kaniko and GitLab CI/CD
- GitLab CI/CD environment variables
- Predefined environment variables reference
- Where variables can be used
- Deprecated GitLab CI/CD variables
- Environments and deployments
- Protected Environments
- GitLab CI/CD Examples
- Test a Clojure application with GitLab CI/CD
- Using Dpl as deployment tool
- Testing a Phoenix application with GitLab CI/CD
- End-to-end testing with GitLab CI/CD and WebdriverIO
- DevOps and Game Dev with GitLab CI/CD
- Deploy a Spring Boot application to Cloud Foundry with GitLab CI/CD
- How to deploy Maven projects to Artifactory with GitLab CI/CD
- Testing PHP projects
- Running Composer and NPM scripts with deployment via SCP in GitLab CI/CD
- Test and deploy Laravel applications with GitLab CI/CD and Envoy
- Test and deploy a Python application with GitLab CI/CD
- Test and deploy a Ruby application with GitLab CI/CD
- Test and deploy a Scala application to Heroku
- GitLab CI/CD for external repositories
- Using GitLab CI/CD with a Bitbucket Cloud repository
- Using GitLab CI/CD with a GitHub repository
- GitLab Pages
- GitLab Pages
- GitLab Pages domain names, URLs, and baseurls
- Create a GitLab Pages website from scratch
- Custom domains and SSL/TLS Certificates
- GitLab Pages integration with Let's Encrypt
- GitLab Pages Access Control
- Exploring GitLab Pages
- Incremental Rollouts with GitLab CI/CD
- Interactive Web Terminals
- Optimizing GitLab for large repositories
- Metrics Reports
- CI/CD pipelines
- Pipeline Architecture
- Directed Acyclic Graph
- Multi-project pipelines
- Parent-child pipelines
- Pipelines for Merge Requests
- Pipelines for Merged Results
- Merge Trains
- Job artifacts
- Pipeline schedules
- Pipeline settings
- Triggering pipelines through the API
- Review Apps
- Configuring GitLab Runners
- GitLab CI services examples
- Using MySQL
- Using PostgreSQL
- Using Redis
- Troubleshooting CI/CD
- GitLab Package Registry
- GitLab Container Registry
- Dependency Proxy
- GitLab Composer Repository
- GitLab Conan Repository
- GitLab Maven Repository
- GitLab NPM Registry
- GitLab NuGet Repository
- GitLab PyPi Repository
- API Docs
- API resources
- .gitignore API
- GitLab CI YMLs API
- Group and project access requests API
- Appearance API
- Applications API
- Audit Events API
- Avatar API
- Award Emoji API
- Project badges API
- Group badges API
- Branches API
- Broadcast Messages API
- Project clusters API
- Group clusters API
- Instance clusters API
- Commits API
- Container Registry API
- Custom Attributes API
- Dashboard annotations API
- Dependencies API
- Deploy Keys API
- Deployments API
- Discussions API
- Dockerfiles API
- Environments API
- Epics API
- Events
- Feature Flags API
- Feature flag user lists API
- Freeze Periods API
- Geo Nodes API
- Group Activity Analytics API
- Groups API
- Import API
- Issue Boards API
- Group Issue Boards API
- Issues API
- Epic Issues API
- Issues Statistics API
- Jobs API
- Keys API
- Labels API
- Group Labels API
- License
- Licenses API
- Issue links API
- Epic Links API
- Managed Licenses API
- Markdown API
- Group and project members API
- Merge request approvals API
- Merge requests API
- Project milestones API
- Group milestones API
- Namespaces API
- Notes API
- Notification settings API
- Packages API
- Pages domains API
- Pipeline schedules API
- Pipeline triggers API
- Pipelines API
- Project Aliases API
- Project import/export API
- Project repository storage moves API
- Project statistics API
- Project templates API
- Projects API
- Protected branches API
- Protected tags API
- Releases API
- Release links API
- Repositories API
- Repository files API
- Repository submodules API
- Resource label events API
- Resource milestone events API
- Resource weight events API
- Runners API
- SCIM API
- Search API
- Services API
- Application settings API
- Sidekiq Metrics API
- Snippets API
- Project snippets
- Application statistics API
- Suggest Changes API
- System hooks API
- Tags API
- Todos API
- Users API
- Project-level Variables API
- Group-level Variables API
- Version API
- Vulnerabilities API
- Vulnerability Findings API
- Wikis API
- GraphQL API
- Getting started with GitLab GraphQL API
- GraphQL API Resources
- API V3 to API V4
- Validate the .gitlab-ci.yml (API)
- User Docs
- Abuse reports
- User account
- Active sessions
- Deleting a User account
- Permissions
- Personal access tokens
- Profile preferences
- Threads
- GitLab and SSH keys
- GitLab integrations
- Git
- GitLab.com settings
- Infrastructure as code with Terraform and GitLab
- GitLab keyboard shortcuts
- GitLab Markdown
- AsciiDoc
- GitLab Notification Emails
- GitLab Quick Actions
- Autocomplete characters
- Reserved project and group names
- Search through GitLab
- Advanced Global Search
- Advanced Syntax Search
- Time Tracking
- GitLab To-Do List
- Administrator Docs
- Reference architectures
- Reference architecture: up to 1,000 users
- Reference architecture: up to 2,000 users
- Reference architecture: up to 3,000 users
- Reference architecture: up to 5,000 users
- Reference architecture: up to 10,000 users
- Reference architecture: up to 25,000 users
- Reference architecture: up to 50,000 users
- Troubleshooting a reference architecture set up
- Working with the bundled Consul service
- Configuring PostgreSQL for scaling
- Configuring GitLab application (Rails)
- Load Balancer for multi-node GitLab
- Configuring a Monitoring node for Scaling and High Availability
- NFS
- Working with the bundled PgBouncer service
- Configuring Redis for scaling
- Configuring Sidekiq
- Admin Area settings
- Continuous Integration and Deployment Admin settings
- Custom instance-level project templates
- Diff limits administration
- Enable and disable GitLab features deployed behind feature flags
- Geo nodes Admin Area
- GitLab Pages administration
- Health Check
- Job logs
- Labels administration
- Log system
- PlantUML & GitLab
- Repository checks
- Repository storage paths
- Repository storage types
- Account and limit settings
- Service templates
- System hooks
- Changing your time zone
- Uploads administration
- Abuse reports
- Activating and deactivating users
- Audit Events
- Blocking and unblocking users
- Broadcast Messages
- Elasticsearch integration
- Gitaly
- Gitaly Cluster
- Gitaly reference
- Monitoring GitLab
- Monitoring GitLab with Prometheus
- Performance Bar
- Usage statistics
- Object Storage
- Performing Operations in GitLab
- Cleaning up stale Redis sessions
- Fast lookup of authorized SSH keys in the database
- Filesystem Performance Benchmarking
- Moving repositories managed by GitLab
- Run multiple Sidekiq processes
- Sidekiq MemoryKiller
- Switching to Puma
- Understanding Unicorn and unicorn-worker-killer
- User lookup via OpenSSH's AuthorizedPrincipalsCommand
- GitLab Package Registry administration
- GitLab Container Registry administration
- Replication (Geo)
- Geo database replication
- Geo with external PostgreSQL instances
- Geo configuration
- Using a Geo Server
- Updating the Geo nodes
- Geo with Object storage
- Docker Registry for a secondary node
- Geo for multiple nodes
- Geo security review (Q&A)
- Location-aware Git remote URL with AWS Route53
- Tuning Geo
- Removing secondary Geo nodes
- Geo data types support
- Geo Frequently Asked Questions
- Geo Troubleshooting
- Geo validation tests
- Disaster Recovery (Geo)
- Disaster recovery for planned failover
- Bring a demoted primary node back online
- Automatic background verification
- Rake tasks
- Back up and restore GitLab
- Clean up
- Namespaces
- Maintenance Rake tasks
- Geo Rake Tasks
- GitHub import
- Import bare repositories
- Integrity check Rake task
- LDAP Rake tasks
- Listing repository directories
- Praefect Rake tasks
- Project import/export administration
- Repository storage Rake tasks
- Generate sample Prometheus data
- Uploads migrate Rake tasks
- Uploads sanitize Rake tasks
- User management
- Webhooks administration
- X.509 signatures
- Server hooks
- Static objects external storage
- Updating GitLab
- GitLab release and maintenance policy
- Security
- Password Storage
- Custom password length limits
- Restrict allowed SSH key technologies and minimum length
- Rate limits
- Webhooks and insecure internal web services
- Information exclusivity
- How to reset your root password
- How to unlock a locked user from the command line
- User File Uploads
- How we manage the TLS protocol CRIME vulnerability
- User email confirmation at sign-up
- Security of running jobs
- Proxying assets
- CI/CD Environment Variables
- Contributor and Development Docs
- Contribute to GitLab
- Community members & roles
- Implement design & UI elements
- Issues workflow
- Merge requests workflow
- Code Review Guidelines
- Style guides
- GitLab Architecture Overview
- CI/CD development documentation
- Database guides
- Database Review Guidelines
- Database Review Guidelines
- Migration Style Guide
- What requires downtime?
- Understanding EXPLAIN plans
- Rake tasks for developers
- Mass inserting Rails models
- GitLab Documentation guidelines
- Documentation Style Guide
- Documentation structure and template
- Documentation process
- Documentation site architecture
- Global navigation
- GitLab Docs monthly release process
- Telemetry Guide
- Usage Ping Guide
- Snowplow Guide
- Experiment Guide
- Feature flags in development of GitLab
- Feature flags process
- Developing with feature flags
- Feature flag controls
- Document features deployed behind feature flags
- Frontend Development Guidelines
- Accessibility & Readability
- Ajax
- Architecture
- Axios
- Design Patterns
- Frontend Development Process
- DropLab
- Emojis
- Filter
- Frontend FAQ
- GraphQL
- Icons and SVG Illustrations
- InputSetter
- Performance
- Principles
- Security
- Tooling
- Vuex
- Vue
- Geo (development)
- Geo self-service framework (alpha)
- Gitaly developers guide
- GitLab development style guides
- API style guide
- Go standards and style guidelines
- GraphQL API style guide
- Guidelines for shell commands in the GitLab codebase
- HTML style guide
- JavaScript style guide
- Migration Style Guide
- Newlines style guide
- Python Development Guidelines
- SCSS style guide
- Shell scripting standards and style guidelines
- Sidekiq debugging
- Sidekiq Style Guide
- SQL Query Guidelines
- Vue.js style guide
- Instrumenting Ruby code
- Testing standards and style guidelines
- Flaky tests
- Frontend testing standards and style guidelines
- GitLab tests in the Continuous Integration (CI) context
- Review Apps
- Smoke Tests
- Testing best practices
- Testing levels
- Testing Rails migrations at GitLab
- Testing Rake tasks
- End-to-end Testing
- Beginner's guide to writing end-to-end tests
- End-to-end testing Best Practices
- Dynamic Element Validation
- Flows in GitLab QA
- Page objects in GitLab QA
- Resource class in GitLab QA
- Style guide for writing end-to-end tests
- Testing with feature flags
- Translate GitLab to your language
- Internationalization for GitLab
- Translating GitLab
- Proofread Translations
- Merging translations from CrowdIn
- Value Stream Analytics development guide
- GitLab subscription
- Activate GitLab EE with a license