
## 1.2 统计数据能为我们做什么?
我们可以用统计数据做三件主要的事情:
* _ 描述 _:这个世界是复杂的,我们经常需要用我们能够理解的简单方式来描述它。
* _ 决定 _:我们通常需要根据数据做出决定,通常是在面临不确定性的情况下。
* _ 预测 _:我们经常希望根据我们对以前情况的了解来预测新的情况。
让我们来看一个实际的例子,集中在一个我们很多人都感兴趣的问题上:我们如何决定吃什么是健康的?
有许多不同的指导来源,从政府饮食指南到饮食书籍,再到博客。
让我们专注于一个特定的问题:我们饮食中的饱和脂肪是不是一件坏事?
我们回答这个问题的一种方法是常识。
如果我们吃脂肪,那么它会在我们的身体里直接变成脂肪,对吗?
我们都看过脂肪堵塞动脉的照片,所以吃脂肪会阻塞动脉,对吗?
我们回答这个问题的另一种方法是听取权威人士的意见。美国食品药品监督管理局的饮食指南作为其关键建议之一,“健康的饮食模式限制饱和脂肪的摄入”。你可能希望这些指南是基于良好的科学,在某些情况下是这样的,但正如尼娜·泰克罗兹在她的书中概述的那样。”大脂肪惊喜”(Teicholz,2014 年),这一特别建议似乎更多地基于营养研究人员的教条,而不是实际证据。
最后,我们可以看看实际的科学研究。让我们先看一个名为“纯粹研究”的大型研究,该研究对 18 个不同国家的 135000 多人的饮食和健康结果(包括死亡)进行了调查。在该数据集的一项分析中(发表于 2017 年的《柳叶刀》(The Lancet)(HTG1));Dehghan 等人(2017 年)),纯研究人员报告了一项分析,分析了不同种类的宏量营养素(包括饱和脂肪和碳水化合物)的摄入与跟踪调查期间死亡的可能性之间的关系。对受试者进行了中位数为 7.4 年的跟踪调查,这意味着研究中一半受试者的跟踪调查时间不足,一半受试者的跟踪调查时间超过 7.4 年。图[1.1](#fig:PureDeathSatFat)描绘了研究中的一些数据(摘自论文),显示了饱和脂肪和碳水化合物摄入与任何原因死亡风险之间的关系。
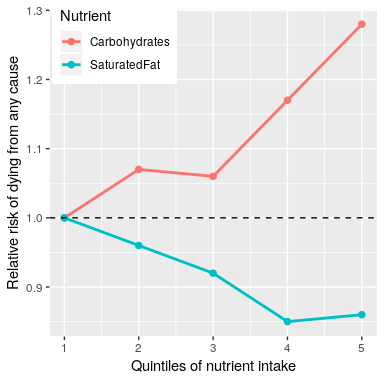
图 1.1 纯研究的数据图,显示了任何原因导致的死亡与饱和脂肪和碳水化合物的相对摄入量之间的关系。
这个图是以十个数字为基础的。为了获得这些数据,研究人员将 135335 名研究参与者(我们称之为“样本”)分成 5 组(“五分位数”),根据他们对任何一种营养素的摄入量对其进行排序;第一个五分位数包含 20%的最低摄入量的人,第五个五分位数包含 20%的最低摄入量的人。五分位数含有最高摄入量的 20%。然后,研究人员计算了在被跟踪期间,每个研究小组中的人死亡的频率。这个数字用死亡的相对风险(与最低五分位数相比)来表示这一点:如果这个数字大于 1,这意味着这个群体中的人比最低五分位数中的人死亡的可能性高 _,而如果这个数字小于 1,这意味着死亡的可能性比最低五分位数中的人高 _。也就是说,小组中的人死亡的可能性要小一些。这个数字非常清楚:在研究过程中,摄入饱和脂肪越多的人死亡的可能性就越小,而且吃得越多,这种影响就越大。碳水化合物的情况正好相反,一个人吃的碳水化合物越多,他们在研究中死亡的可能性就越大。这个例子显示了我们如何使用统计数据来描述复杂的数据集,用一组简单得多的数字来描述;如果我们必须同时查看来自每个研究参与者的数据,我们将被数据超载,很难看到 EME 当它们被更简单地描述时。
图[1.1](#fig:PureDeathSatFat)中的数字似乎表明,随着饱和脂肪的摄入,死亡人数减少,而随着碳水化合物的摄入,死亡人数增加,但我们也知道,数据中存在很多不确定性;有些人即使吃低碳水化合物的饮食,也会过早死亡,同样,有些人甚至会因摄入低碳水化合物的食物而死亡。他吃了很多碳水化合物,但活到了成熟的老年。考虑到这种变异性,我们想 _ 决定 _ 我们在数据中看到的关系是否足够大,如果饮食和寿命之间没有真正的关系,我们就不会期望它们随机发生。统计数据为我们提供了做出这些决定的工具,通常外界认为这是统计数据的主要目的。但正如我们将在书中看到的,基于模糊证据的黑白决策的需要常常导致研究人员误入歧途。
基于这些数据,我们还想对未来的结果做出预测。例如,一家人寿保险公司可能想利用某个人摄入脂肪和碳水化合物的数据来预测他们的寿命。预测的一个重要方面是,它要求我们将已有的数据归纳为其他情况,通常是在将来;如果我们的结论仅限于某一特定时间研究中的特定人员,那么该研究就不会非常有用。一般来说,研究人员必须假设他们的特定样本代表了更大的(htg0)群体(htg1),这要求他们以无偏见的方式获取样本。例如,如果纯研究从信奉素食主义的宗教派别中招募了所有参与者,那么我们可能不想将结果推广到遵循不同饮食标准的人身上。
- 前言
- 0.1 本书为什么存在?
- 0.2 你不是统计学家-我们为什么要听你的?
- 0.3 为什么是 R?
- 0.4 数据的黄金时代
- 0.5 开源书籍
- 0.6 确认
- 1 引言
- 1.1 什么是统计思维?
- 1.2 统计数据能为我们做什么?
- 1.3 统计学的基本概念
- 1.4 因果关系与统计
- 1.5 阅读建议
- 2 处理数据
- 2.1 什么是数据?
- 2.2 测量尺度
- 2.3 什么是良好的测量?
- 2.4 阅读建议
- 3 概率
- 3.1 什么是概率?
- 3.2 我们如何确定概率?
- 3.3 概率分布
- 3.4 条件概率
- 3.5 根据数据计算条件概率
- 3.6 独立性
- 3.7 逆转条件概率:贝叶斯规则
- 3.8 数据学习
- 3.9 优势比
- 3.10 概率是什么意思?
- 3.11 阅读建议
- 4 汇总数据
- 4.1 为什么要总结数据?
- 4.2 使用表格汇总数据
- 4.3 分布的理想化表示
- 4.4 阅读建议
- 5 将模型拟合到数据
- 5.1 什么是模型?
- 5.2 统计建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最简单的模型:平均值
- 5.6 模式
- 5.7 变异性:平均值与数据的拟合程度如何?
- 5.8 使用模拟了解统计数据
- 5.9 Z 分数
- 6 数据可视化
- 6.1 数据可视化如何拯救生命
- 6.2 绘图解剖
- 6.3 使用 ggplot 在 R 中绘制
- 6.4 良好可视化原则
- 6.5 最大化数据/墨水比
- 6.6 避免图表垃圾
- 6.7 避免数据失真
- 6.8 谎言因素
- 6.9 记住人的局限性
- 6.10 其他因素的修正
- 6.11 建议阅读和视频
- 7 取样
- 7.1 我们如何取样?
- 7.2 采样误差
- 7.3 平均值的标准误差
- 7.4 中心极限定理
- 7.5 置信区间
- 7.6 阅读建议
- 8 重新采样和模拟
- 8.1 蒙特卡罗模拟
- 8.2 统计的随机性
- 8.3 生成随机数
- 8.4 使用蒙特卡罗模拟
- 8.5 使用模拟统计:引导程序
- 8.6 阅读建议
- 9 假设检验
- 9.1 无效假设统计检验(NHST)
- 9.2 无效假设统计检验:一个例子
- 9.3 无效假设检验过程
- 9.4 现代环境下的 NHST:多重测试
- 9.5 阅读建议
- 10 置信区间、效应大小和统计功率
- 10.1 置信区间
- 10.2 效果大小
- 10.3 统计能力
- 10.4 阅读建议
- 11 贝叶斯统计
- 11.1 生成模型
- 11.2 贝叶斯定理与逆推理
- 11.3 进行贝叶斯估计
- 11.4 估计后验分布
- 11.5 选择优先权
- 11.6 贝叶斯假设检验
- 11.7 阅读建议
- 12 分类关系建模
- 12.1 示例:糖果颜色
- 12.2 皮尔逊卡方检验
- 12.3 应急表及双向试验
- 12.4 标准化残差
- 12.5 优势比
- 12.6 贝叶斯系数
- 12.7 超出 2 x 2 表的分类分析
- 12.8 注意辛普森悖论
- 13 建模持续关系
- 13.1 一个例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否与仇恨犯罪有关?
- 13.3 协方差和相关性
- 13.4 相关性和因果关系
- 13.5 阅读建议
- 14 一般线性模型
- 14.1 线性回归
- 14.2 安装更复杂的模型
- 14.3 变量之间的相互作用
- 14.4“预测”的真正含义是什么?
- 14.5 阅读建议
- 15 比较方法
- 15.1 学生 T 考试
- 15.2 t 检验作为线性模型
- 15.3 平均差的贝叶斯因子
- 15.4 配对 t 检验
- 15.5 比较两种以上的方法
- 16 统计建模过程:一个实例
- 16.1 统计建模过程
- 17 做重复性研究
- 17.1 我们认为科学应该如何运作
- 17.2 科学(有时)是如何工作的
- 17.3 科学中的再现性危机
- 17.4 有问题的研究实践
- 17.5 进行重复性研究
- 17.6 进行重复性数据分析
- 17.7 结论:提高科学水平
- 17.8 阅读建议
- References