
## 8.3 生成随机数
运行蒙特卡罗模拟需要我们生成随机数。只有通过物理过程才能生成真正的随机数(即完全不可预测的数),例如原子衰变或骰子滚动,这些过程很难获得和/或太慢,无法用于计算机模拟(尽管可以从[NIST 随机信标](https://www.nist.gov/programs-projects/nist-randomness-beacon%5D))。
一般来说,我们使用计算机算法生成的 _ 伪随机 _ 数字来代替真正的随机数;从难以预测的意义上讲,这些数字看起来是随机的,但实际上这些数字序列在某一点上会重复出现。例如,R 中使用的随机数生成器将在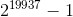个数之后重复。这远远超过了宇宙历史上的秒数,我们一般认为这对于统计分析的大多数目的来说都是好的。
在 R 中,有一个函数可以为每个主要概率分布生成随机数,例如:
* `runif()`-均匀分布(0 和 1 之间的所有值相等)
* `rnorm()`-正态分布
* `rbinom()`-二项分布(如掷骰子、掷硬币)
图[8.1](#fig:rngExamples)显示了使用`runif()`和`rnorm()`函数生成的数字示例,这些函数使用以下代码生成:
```r
p1 <-
tibble(
x = runif(10000)
) %>%
ggplot((aes(x))) +
geom_histogram(bins = 100) +
labs(title = "Uniform")
p2 <-
tibble(
x = rnorm(10000)
) %>%
ggplot(aes(x)) +
geom_histogram(bins = 100) +
labs(title = "Normal")
plot_grid(p1, p2, ncol = 3)
```
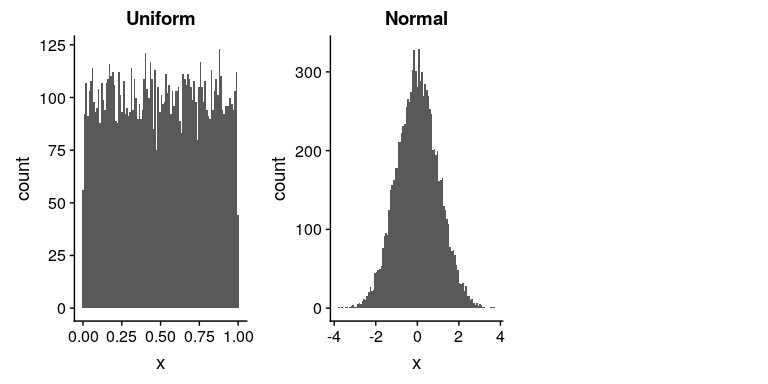
图 8.1 由均匀(左)或正态(右)分布生成的随机数示例。
如果您有一个 _ 分位数 _ 函数用于分发,您还可以为任何分发生成随机数。这是累积分布函数的倒数;分位数函数不是确定一组值的累积概率,而是确定一组累积概率的值。使用分位数函数,我们可以从均匀分布中生成随机数,然后通过它的分位数函数将其映射到兴趣分布中。
默认情况下,每次运行上面描述的随机数生成器函数之一时,R 都会生成一组不同的随机数。但是,通过将所谓的 _ 随机种子 _ 设置为特定值,也可以生成完全相同的随机数集。我们将在本书中的许多示例中这样做,以确保示例是可重复的。
```r
# if we run the rnorm() command twice, it will give us different sets of pseudorandom numbers each time
print(rnorm(n = 5))
```
```r
## [1] 1.48 0.18 0.21 -0.15 -1.72
```
```r
print(rnorm(n = 5))
```
```r
## [1] -0.691 -2.231 0.391 0.029 -0.647
```
```r
# if we set the random seed to the same value each time, then it will give us the same series of pseudorandom numbers each time.
set.seed(12345)
print(rnorm(n = 5))
```
```r
## [1] 0.59 0.71 -0.11 -0.45 0.61
```
```r
set.seed(12345)
print(rnorm(n = 5))
```
```r
## [1] 0.59 0.71 -0.11 -0.45 0.61
```
- 前言
- 0.1 本书为什么存在?
- 0.2 你不是统计学家-我们为什么要听你的?
- 0.3 为什么是 R?
- 0.4 数据的黄金时代
- 0.5 开源书籍
- 0.6 确认
- 1 引言
- 1.1 什么是统计思维?
- 1.2 统计数据能为我们做什么?
- 1.3 统计学的基本概念
- 1.4 因果关系与统计
- 1.5 阅读建议
- 2 处理数据
- 2.1 什么是数据?
- 2.2 测量尺度
- 2.3 什么是良好的测量?
- 2.4 阅读建议
- 3 概率
- 3.1 什么是概率?
- 3.2 我们如何确定概率?
- 3.3 概率分布
- 3.4 条件概率
- 3.5 根据数据计算条件概率
- 3.6 独立性
- 3.7 逆转条件概率:贝叶斯规则
- 3.8 数据学习
- 3.9 优势比
- 3.10 概率是什么意思?
- 3.11 阅读建议
- 4 汇总数据
- 4.1 为什么要总结数据?
- 4.2 使用表格汇总数据
- 4.3 分布的理想化表示
- 4.4 阅读建议
- 5 将模型拟合到数据
- 5.1 什么是模型?
- 5.2 统计建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最简单的模型:平均值
- 5.6 模式
- 5.7 变异性:平均值与数据的拟合程度如何?
- 5.8 使用模拟了解统计数据
- 5.9 Z 分数
- 6 数据可视化
- 6.1 数据可视化如何拯救生命
- 6.2 绘图解剖
- 6.3 使用 ggplot 在 R 中绘制
- 6.4 良好可视化原则
- 6.5 最大化数据/墨水比
- 6.6 避免图表垃圾
- 6.7 避免数据失真
- 6.8 谎言因素
- 6.9 记住人的局限性
- 6.10 其他因素的修正
- 6.11 建议阅读和视频
- 7 取样
- 7.1 我们如何取样?
- 7.2 采样误差
- 7.3 平均值的标准误差
- 7.4 中心极限定理
- 7.5 置信区间
- 7.6 阅读建议
- 8 重新采样和模拟
- 8.1 蒙特卡罗模拟
- 8.2 统计的随机性
- 8.3 生成随机数
- 8.4 使用蒙特卡罗模拟
- 8.5 使用模拟统计:引导程序
- 8.6 阅读建议
- 9 假设检验
- 9.1 无效假设统计检验(NHST)
- 9.2 无效假设统计检验:一个例子
- 9.3 无效假设检验过程
- 9.4 现代环境下的 NHST:多重测试
- 9.5 阅读建议
- 10 置信区间、效应大小和统计功率
- 10.1 置信区间
- 10.2 效果大小
- 10.3 统计能力
- 10.4 阅读建议
- 11 贝叶斯统计
- 11.1 生成模型
- 11.2 贝叶斯定理与逆推理
- 11.3 进行贝叶斯估计
- 11.4 估计后验分布
- 11.5 选择优先权
- 11.6 贝叶斯假设检验
- 11.7 阅读建议
- 12 分类关系建模
- 12.1 示例:糖果颜色
- 12.2 皮尔逊卡方检验
- 12.3 应急表及双向试验
- 12.4 标准化残差
- 12.5 优势比
- 12.6 贝叶斯系数
- 12.7 超出 2 x 2 表的分类分析
- 12.8 注意辛普森悖论
- 13 建模持续关系
- 13.1 一个例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否与仇恨犯罪有关?
- 13.3 协方差和相关性
- 13.4 相关性和因果关系
- 13.5 阅读建议
- 14 一般线性模型
- 14.1 线性回归
- 14.2 安装更复杂的模型
- 14.3 变量之间的相互作用
- 14.4“预测”的真正含义是什么?
- 14.5 阅读建议
- 15 比较方法
- 15.1 学生 T 考试
- 15.2 t 检验作为线性模型
- 15.3 平均差的贝叶斯因子
- 15.4 配对 t 检验
- 15.5 比较两种以上的方法
- 16 统计建模过程:一个实例
- 16.1 统计建模过程
- 17 做重复性研究
- 17.1 我们认为科学应该如何运作
- 17.2 科学(有时)是如何工作的
- 17.3 科学中的再现性危机
- 17.4 有问题的研究实践
- 17.5 进行重复性研究
- 17.6 进行重复性数据分析
- 17.7 结论:提高科学水平
- 17.8 阅读建议
- References