
## 10.2 效果大小
> “统计显著性是最不有趣的结果。你应该用数量尺度来描述结果——不仅仅是治疗对人有影响,还有它对人有多大的影响。”基因玻璃(Ref)
在最后一章中,我们讨论了统计学意义不一定反映实际意义的观点。为了讨论实际意义,我们需要一种标准的方法来根据实际数据描述效应的大小,我们称之为 _ 效应大小 _。在本节中,我们将介绍这个概念,并讨论计算影响大小的各种方法。
效应大小是一种标准化的测量,它将某些统计效应的大小与参考量(如统计的可变性)进行比较。在一些科学和工程领域中,这个概念被称为“信噪比”。有许多不同的方法可以量化效果大小,这取决于数据的性质。
### 10.2.1 科恩
影响大小最常见的度量之一是以统计学家雅各布·科恩(Jacob Cohen)的名字命名的 _ 科恩的 D_,他在 1994 年发表的题为“地球是圆的(P<;.05)”的论文中最为著名。它用于量化两种方法之间的差异,根据它们的标准偏差:

其中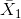和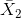是两组的平均值,而是合并标准偏差(这是两个样本的标准偏差的组合,由样本大小加权):

其中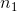和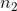是样品尺寸,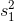和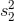分别是两组的标准偏差。
有一个常用的尺度可以用科恩的 D 来解释效应的大小:
<colgroup><col style="width: 8%"> <col style="width: 22%"></colgroup>
| D | 解释 |
| --- | --- |
| 0.2 条 | 小的 |
| 0.5 倍 | 中等的 |
| 0.8 倍 | 大的 |
观察一些常见的理解效果,有助于理解这些解释。
```r
# compute effect size for gender difference in NHANES
NHANES_sample <-
NHANES_adult %>%
drop_na(Height) %>%
sample_n(250)
hsum <-
NHANES_sample %>%
group_by(Gender) %>%
summarize(
meanHeight = mean(Height),
varHeight = var(Height),
n = n()
)
#pooled SD
s_height_gender <- sqrt(
((hsum$n[1] - 1) * hsum$varHeight[1] + (hsum$n[2] - 1) * hsum$varHeight[2]) /
(hsum$n[1] + hsum$n[2] - 2)
)
#cohen's d
d_height_gender <- (hsum$meanHeight[2] - hsum$meanHeight[1]) / s_height_gender
sprintf("Cohens d for male vs. female height = %0.2f", d_height_gender)
```
```r
## [1] "Cohens d for male vs. female height = 1.95"
```
参照上表,身高性别差异的影响大小(d=1.95)很大。我们也可以通过观察样本中男性和女性身高的分布来看到这一点。图[10.2](#fig:genderHist)显示,这两个分布虽然仍然重叠,但分离得很好,突出了这样一个事实:即使两个组之间的差异有很大的影响大小,每个组中的个体也会更像另一个组。
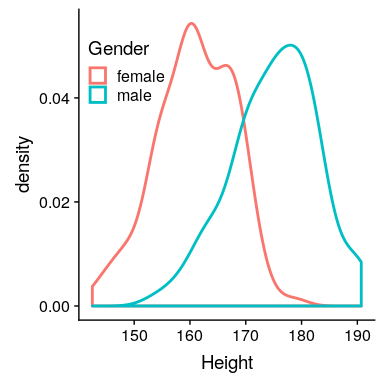
图 10.2 nhanes 数据集中男性和女性身高的平滑柱状图,显示了明显不同但明显重叠的分布。
同样值得注意的是,我们很少在科学中遇到这种规模的影响,部分原因是它们是如此明显的影响,以至于我们不需要科学研究来找到它们。正如我们将在第[17](#doing-reproducible-research)章中看到的那样,在科学研究中报告的非常大的影响往往反映出有问题的研究实践的使用,而不是自然界中真正的巨大影响。同样值得注意的是,即使有如此巨大的影响,这两种分布仍然是重叠的——会有一些女性比普通男性高,反之亦然。对于最有趣的科学效应来说,重叠的程度会大得多,所以我们不应该马上就基于一个大的效应大小得出关于不同人群的强有力的结论。
### 10.2.2 皮尔逊 R
Pearson 的 _r_ 也称为 _ 相关系数 _,是对两个连续变量之间线性关系强度的度量。我们将在[13](#modeling-continuous-relationships)章中更详细地讨论相关性,因此我们将保存该章的详细信息;这里,我们简单地介绍 _r_ 作为量化两个变量之间关系的方法。
_r_ 是一个在-1 到 1 之间变化的度量值,其中值 1 表示变量之间的完全正关系,0 表示没有关系,而-1 表示完全负关系。图[10.3](#fig:corrFig)显示了使用随机生成的数据的各种相关级别的示例。

图 10.3 不同水平皮尔逊 R 的示例。
### 10.2.3 优势比
在我们之前关于概率的讨论中,我们讨论了概率的概念——也就是说,某些事件发生与未发生的相对可能性:
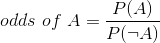
优势比只是两个优势比。例如,让我们以吸烟和肺癌为例。2012 年发表在《国际癌症杂志》上的一项研究(Pesch 等人 2012 年)关于吸烟者和从未吸烟的个体肺癌发生率的综合数据,通过许多不同的研究。请注意,这些数据来自病例对照研究,这意味着这些研究的参与者之所以被招募,是因为他们要么患了癌症,要么没有患癌症;然后检查他们的吸烟状况。因此,这些数字并不代表一般人群中吸烟者的癌症患病率,但它们可以告诉我们癌症与吸烟之间的关系。
```r
# create table for cancer occurrence depending on smoking status
smokingDf <- tibble(
NeverSmoked = c(2883, 220),
CurrentSmoker = c(3829, 6784),
row.names = c("NoCancer", "Cancer")
)
pander(smokingDf)
```
<colgroup><col style="width: 19%"> <col style="width: 22%"> <col style="width: 15%"></colgroup>
| 从不吸烟 | 当前吸烟者 | 行名称 |
| --- | --- | --- |
| 2883 个 | 3829 年 | 无癌症者 |
| 220 | 6784 个 | 癌症 |
我们可以将这些数字转换为每个组的优势比:
```r
# convert smoking data to odds
smokingDf <-
smokingDf %>%
mutate(
pNeverSmoked = NeverSmoked / sum(NeverSmoked),
pCurrentSmoker = CurrentSmoker / sum(CurrentSmoker)
)
oddsCancerNeverSmoked <- smokingDf$NeverSmoked[2] / smokingDf$NeverSmoked[1]
oddsCancerCurrentSmoker <- smokingDf$CurrentSmoker[2] / smokingDf$CurrentSmoker[1]
```
从未吸烟的人患肺癌的几率为 0.08,而目前吸烟者患肺癌的几率为 1.77。这些比值告诉我们两组患者患癌症的相对可能性:
```r
#compute odds ratio
oddsRatio <- oddsCancerCurrentSmoker/oddsCancerNeverSmoked
sprintf('odds ratio of cancer for smokers vs. nonsmokers: %0.3f',oddsRatio)
```
```r
## [1] "odds ratio of cancer for smokers vs. nonsmokers: 23.218"
```
23.22 的比值比告诉我们,吸烟者患癌症的几率大约是不吸烟者的 23 倍。
- 前言
- 0.1 本书为什么存在?
- 0.2 你不是统计学家-我们为什么要听你的?
- 0.3 为什么是 R?
- 0.4 数据的黄金时代
- 0.5 开源书籍
- 0.6 确认
- 1 引言
- 1.1 什么是统计思维?
- 1.2 统计数据能为我们做什么?
- 1.3 统计学的基本概念
- 1.4 因果关系与统计
- 1.5 阅读建议
- 2 处理数据
- 2.1 什么是数据?
- 2.2 测量尺度
- 2.3 什么是良好的测量?
- 2.4 阅读建议
- 3 概率
- 3.1 什么是概率?
- 3.2 我们如何确定概率?
- 3.3 概率分布
- 3.4 条件概率
- 3.5 根据数据计算条件概率
- 3.6 独立性
- 3.7 逆转条件概率:贝叶斯规则
- 3.8 数据学习
- 3.9 优势比
- 3.10 概率是什么意思?
- 3.11 阅读建议
- 4 汇总数据
- 4.1 为什么要总结数据?
- 4.2 使用表格汇总数据
- 4.3 分布的理想化表示
- 4.4 阅读建议
- 5 将模型拟合到数据
- 5.1 什么是模型?
- 5.2 统计建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最简单的模型:平均值
- 5.6 模式
- 5.7 变异性:平均值与数据的拟合程度如何?
- 5.8 使用模拟了解统计数据
- 5.9 Z 分数
- 6 数据可视化
- 6.1 数据可视化如何拯救生命
- 6.2 绘图解剖
- 6.3 使用 ggplot 在 R 中绘制
- 6.4 良好可视化原则
- 6.5 最大化数据/墨水比
- 6.6 避免图表垃圾
- 6.7 避免数据失真
- 6.8 谎言因素
- 6.9 记住人的局限性
- 6.10 其他因素的修正
- 6.11 建议阅读和视频
- 7 取样
- 7.1 我们如何取样?
- 7.2 采样误差
- 7.3 平均值的标准误差
- 7.4 中心极限定理
- 7.5 置信区间
- 7.6 阅读建议
- 8 重新采样和模拟
- 8.1 蒙特卡罗模拟
- 8.2 统计的随机性
- 8.3 生成随机数
- 8.4 使用蒙特卡罗模拟
- 8.5 使用模拟统计:引导程序
- 8.6 阅读建议
- 9 假设检验
- 9.1 无效假设统计检验(NHST)
- 9.2 无效假设统计检验:一个例子
- 9.3 无效假设检验过程
- 9.4 现代环境下的 NHST:多重测试
- 9.5 阅读建议
- 10 置信区间、效应大小和统计功率
- 10.1 置信区间
- 10.2 效果大小
- 10.3 统计能力
- 10.4 阅读建议
- 11 贝叶斯统计
- 11.1 生成模型
- 11.2 贝叶斯定理与逆推理
- 11.3 进行贝叶斯估计
- 11.4 估计后验分布
- 11.5 选择优先权
- 11.6 贝叶斯假设检验
- 11.7 阅读建议
- 12 分类关系建模
- 12.1 示例:糖果颜色
- 12.2 皮尔逊卡方检验
- 12.3 应急表及双向试验
- 12.4 标准化残差
- 12.5 优势比
- 12.6 贝叶斯系数
- 12.7 超出 2 x 2 表的分类分析
- 12.8 注意辛普森悖论
- 13 建模持续关系
- 13.1 一个例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否与仇恨犯罪有关?
- 13.3 协方差和相关性
- 13.4 相关性和因果关系
- 13.5 阅读建议
- 14 一般线性模型
- 14.1 线性回归
- 14.2 安装更复杂的模型
- 14.3 变量之间的相互作用
- 14.4“预测”的真正含义是什么?
- 14.5 阅读建议
- 15 比较方法
- 15.1 学生 T 考试
- 15.2 t 检验作为线性模型
- 15.3 平均差的贝叶斯因子
- 15.4 配对 t 检验
- 15.5 比较两种以上的方法
- 16 统计建模过程:一个实例
- 16.1 统计建模过程
- 17 做重复性研究
- 17.1 我们认为科学应该如何运作
- 17.2 科学(有时)是如何工作的
- 17.3 科学中的再现性危机
- 17.4 有问题的研究实践
- 17.5 进行重复性研究
- 17.6 进行重复性数据分析
- 17.7 结论:提高科学水平
- 17.8 阅读建议
- References