
## 12.3 应急表及双向试验
我们经常使用卡方检验的另一种方法是询问两个分类变量是否相互关联。作为一个更现实的例子,让我们来考虑一个问题,当一个黑人司机被警察拦下时,他们是否比一个白人司机更有可能被搜查,斯坦福公开警务项目([https://open policing.stanford.edu/](https://openpolicing.stanford.edu/))研究了这个问题,并提供了我们可以用来分析问题的数据。我们将使用来自康涅狄格州的数据,因为它们相当小。首先清理这些数据,以删除所有不必要的数据(参见 code/process_ct_data.py)。
```r
# load police stop data
stopData <-
read_csv("data/CT_data_cleaned.csv") %>%
rename(searched = search_conducted)
```
表示分类分析数据的标准方法是通过 _ 列联表 _,列联表显示了属于每个变量值的每个可能组合的观测值的数量或比例。
让我们计算一下警察搜索数据的应急表:
```r
# compute and print two-way contingency table
summaryDf2way <-
stopData %>%
count(searched, driver_race) %>%
arrange(driver_race, searched)
summaryContingencyTable <-
summaryDf2way %>%
spread(driver_race, n)
pander(summaryContingencyTable)
```
<colgroup><col style="width: 15%"> <col style="width: 11%"> <col style="width: 11%"></colgroup>
| 已搜索 | 黑色 | 白色 |
| --- | --- | --- |
| 错误的 | 36244 个 | 239241 个 |
| 真的 | 1219 年 | 3108 个 |
使用比例而不是原始数字查看应急表也很有用,因为它们更容易在视觉上进行比较。
```r
# Compute and print contingency table using proportions
# rather than raw frequencies
summaryContingencyTableProportion <-
summaryContingencyTable %>%
mutate(
Black = Black / nrow(stopData), #count of Black individuals searched / total searched
White = White / nrow(stopData)
)
pander(summaryContingencyTableProportion, round = 4)
```
<colgroup><col style="width: 15%"> <col style="width: 12%"> <col style="width: 12%"></colgroup>
| searched | Black | White |
| --- | --- | --- |
| FALSE | 0.1295 年 | 0.855 个 |
| TRUE | 0.0044 美元 | 0.0111 个 |
Pearson 卡方检验允许我们检验观察到的频率是否与预期频率不同,因此我们需要确定如果搜索和种族不相关,我们期望在每个细胞中出现的频率,我们可以定义为 _ 独立。_ 请记住,如果 x 和 y 是独立的,那么:
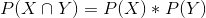
也就是说,零独立假设下的联合概率仅仅是每个变量的 _ 边际 _ 概率的乘积。边际概率只是每一个事件发生的概率,与其他事件无关。我们可以计算这些边际概率,然后将它们相乘,得到独立状态下的预期比例。
| | 黑色 | 白色 | |
| --- | --- | --- | --- |
| 未搜索 | P(ns)*P(b) | P(ns)*P(w) | P(纳秒) |
| 已搜索 | P(S)*P(B) | P(S)*P(W) | P(S) |
| | P(B) | P(宽) | |
我们可以使用称为“外积”的线性代数技巧(通过`outer()`函数)来轻松计算。
```r
# first, compute the marginal probabilities
# probability of being each race
summaryDfRace <-
stopData %>%
count(driver_race) %>% #count the number of drivers of each race
mutate(
prop = n / sum(n) #compute the proportion of each race out of all drivers
)
# probability of being searched
summaryDfStop <-
stopData %>%
count(searched) %>% #count the number of searched vs. not searched
mutate(
prop = n / sum(n) # compute proportion of each outcome out all traffic stops
)
```
```r
# second, multiply outer product by n (all stops) to compute expected frequencies
expected <- outer(summaryDfRace$prop, summaryDfStop$prop) * nrow(stopData)
# create a data frame of expected frequencies for each race
expectedDf <-
data.frame(expected, driverRace = c("Black", "White")) %>%
rename(
NotSearched = X1,
Searched = X2
)
# tidy the data frame
expectedDfTidy <-
gather(expectedDf, searched, n, -driverRace) %>%
arrange(driverRace, searched)
```
```r
# third, add expected frequencies to the original summary table
# and fourth, compute the standardized squared difference between
# the observed and expected frequences
summaryDf2way <-
summaryDf2way %>%
mutate(expected = expectedDfTidy$n)
summaryDf2way <-
summaryDf2way %>%
mutate(stdSqDiff = (n - expected)**2 / expected)
pander(summaryDf2way)
```
<colgroup><col style="width: 15%"> <col style="width: 19%"> <col style="width: 12%"> <col style="width: 15%"> <col style="width: 15%"></colgroup>
| searched | 车手比赛 | N 号 | 预期 | 标准平方差 |
| --- | --- | --- | --- | --- |
| FALSE | 黑色 | 36244 | 36883.67 个 | 2009 年 11 月 |
| TRUE | Black | 1219 | 579.33 条 | 第 706.31 条 |
| FALSE | 白色 | 239241 | 238601.3 条 | 1.71 条 |
| TRUE | White | 3108 | 3747.67 美元 | 109.18 条 |
```r
# finally, compute chi-squared statistic by
# summing the standardized squared differences
chisq <- sum(summaryDf2way$stdSqDiff)
sprintf("Chi-squared value = %0.2f", chisq)
```
```r
## [1] "Chi-squared value = 828.30"
```
在计算了卡方统计之后,我们现在需要将其与卡方分布进行比较,以确定它与我们在无效假设下的期望相比有多极端。这种分布的自由度是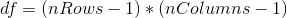——因此,对于类似于这里的 2x2 表,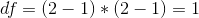。这里的直觉是计算预期频率需要我们使用三个值:观察总数和两个变量的边际概率。因此,一旦计算出这些值,就只有一个数字可以自由变化,因此有一个自由度。鉴于此,我们可以计算卡方统计的 p 值:
```r
pval <- pchisq(chisq, df = 1, lower.tail = FALSE)
sprintf("p-value = %e", pval)
```
```r
## [1] "p-value = 3.795669e-182"
```
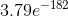的 p 值非常小,表明如果种族和警察搜查之间真的没有关系,观察到的数据就不太可能,因此我们应该拒绝独立性的无效假设。
我们还可以使用 r 中的`chisq.test()`函数轻松执行此测试:
```r
# first need to rearrange the data into a 2x2 table
summaryDf2wayTable <-
summaryDf2way %>%
dplyr::select(-expected, -stdSqDiff) %>%
spread(searched, n) %>%
dplyr::select(-driver_race)
chisqTestResult <- chisq.test(summaryDf2wayTable, 1, correct = FALSE)
chisqTestResult
```
```r
##
## Pearson's Chi-squared test
##
## data: summaryDf2wayTable
## X-squared = 800, df = 1, p-value <2e-16
```
- 前言
- 0.1 本书为什么存在?
- 0.2 你不是统计学家-我们为什么要听你的?
- 0.3 为什么是 R?
- 0.4 数据的黄金时代
- 0.5 开源书籍
- 0.6 确认
- 1 引言
- 1.1 什么是统计思维?
- 1.2 统计数据能为我们做什么?
- 1.3 统计学的基本概念
- 1.4 因果关系与统计
- 1.5 阅读建议
- 2 处理数据
- 2.1 什么是数据?
- 2.2 测量尺度
- 2.3 什么是良好的测量?
- 2.4 阅读建议
- 3 概率
- 3.1 什么是概率?
- 3.2 我们如何确定概率?
- 3.3 概率分布
- 3.4 条件概率
- 3.5 根据数据计算条件概率
- 3.6 独立性
- 3.7 逆转条件概率:贝叶斯规则
- 3.8 数据学习
- 3.9 优势比
- 3.10 概率是什么意思?
- 3.11 阅读建议
- 4 汇总数据
- 4.1 为什么要总结数据?
- 4.2 使用表格汇总数据
- 4.3 分布的理想化表示
- 4.4 阅读建议
- 5 将模型拟合到数据
- 5.1 什么是模型?
- 5.2 统计建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最简单的模型:平均值
- 5.6 模式
- 5.7 变异性:平均值与数据的拟合程度如何?
- 5.8 使用模拟了解统计数据
- 5.9 Z 分数
- 6 数据可视化
- 6.1 数据可视化如何拯救生命
- 6.2 绘图解剖
- 6.3 使用 ggplot 在 R 中绘制
- 6.4 良好可视化原则
- 6.5 最大化数据/墨水比
- 6.6 避免图表垃圾
- 6.7 避免数据失真
- 6.8 谎言因素
- 6.9 记住人的局限性
- 6.10 其他因素的修正
- 6.11 建议阅读和视频
- 7 取样
- 7.1 我们如何取样?
- 7.2 采样误差
- 7.3 平均值的标准误差
- 7.4 中心极限定理
- 7.5 置信区间
- 7.6 阅读建议
- 8 重新采样和模拟
- 8.1 蒙特卡罗模拟
- 8.2 统计的随机性
- 8.3 生成随机数
- 8.4 使用蒙特卡罗模拟
- 8.5 使用模拟统计:引导程序
- 8.6 阅读建议
- 9 假设检验
- 9.1 无效假设统计检验(NHST)
- 9.2 无效假设统计检验:一个例子
- 9.3 无效假设检验过程
- 9.4 现代环境下的 NHST:多重测试
- 9.5 阅读建议
- 10 置信区间、效应大小和统计功率
- 10.1 置信区间
- 10.2 效果大小
- 10.3 统计能力
- 10.4 阅读建议
- 11 贝叶斯统计
- 11.1 生成模型
- 11.2 贝叶斯定理与逆推理
- 11.3 进行贝叶斯估计
- 11.4 估计后验分布
- 11.5 选择优先权
- 11.6 贝叶斯假设检验
- 11.7 阅读建议
- 12 分类关系建模
- 12.1 示例:糖果颜色
- 12.2 皮尔逊卡方检验
- 12.3 应急表及双向试验
- 12.4 标准化残差
- 12.5 优势比
- 12.6 贝叶斯系数
- 12.7 超出 2 x 2 表的分类分析
- 12.8 注意辛普森悖论
- 13 建模持续关系
- 13.1 一个例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否与仇恨犯罪有关?
- 13.3 协方差和相关性
- 13.4 相关性和因果关系
- 13.5 阅读建议
- 14 一般线性模型
- 14.1 线性回归
- 14.2 安装更复杂的模型
- 14.3 变量之间的相互作用
- 14.4“预测”的真正含义是什么?
- 14.5 阅读建议
- 15 比较方法
- 15.1 学生 T 考试
- 15.2 t 检验作为线性模型
- 15.3 平均差的贝叶斯因子
- 15.4 配对 t 检验
- 15.5 比较两种以上的方法
- 16 统计建模过程:一个实例
- 16.1 统计建模过程
- 17 做重复性研究
- 17.1 我们认为科学应该如何运作
- 17.2 科学(有时)是如何工作的
- 17.3 科学中的再现性危机
- 17.4 有问题的研究实践
- 17.5 进行重复性研究
- 17.6 进行重复性数据分析
- 17.7 结论:提高科学水平
- 17.8 阅读建议
- References