
## 10.3 统计能力
请记住,在上一章中,根据 Neyman-Pearson 假设检验方法,我们必须指定我们对两种错误的容忍程度:假阳性(他们称之为 _I 型错误 _)和假阴性(他们称之为 _II 型错误 _)。人们经常把重点放在 I 型错误上,因为作出假阳性的声明通常被视为一件非常糟糕的事情;例如,韦克菲尔德(1999)现在不可信的声称自闭症与疫苗接种有关,导致了反疫苗情绪的大幅上升。儿童疾病,如麻疹。同样,我们也不想声称一种药物如果真的不能治愈一种疾病,这就是为什么 I 型错误的耐受性通常被设定为相当低的原因,通常是在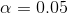。但是 II 型错误呢?
_ 统计功率 _ 的概念是对第二类错误的补充,也就是说,如果存在的话,很可能会得到一个正的结果:
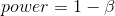
Neyman-Pearson 模型的另一个重要方面,我们没有在上面讨论过,事实上,除了说明 I 型和 II 型错误的可接受水平外,我们还必须描述一个特定的替代假设——即,我们希望检测的影响大小计算机断层扫描?否则,我们无法解释——发现大效应的可能性总是高于发现小效应的可能性,因此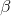将根据我们试图检测的效应大小而有所不同。
影响功率的因素有三个:
* 样本量:较大的样本提供更大的统计能力
* 效果大小:给定的设计总是比小效果有更大的发现大效果的能力(因为发现大效果更容易)
* I 型错误率:I 型错误与功率之间存在一种关系,因此(其他所有情况相同)减少 I 型错误也会降低功率。
我们可以通过模拟看到这一点。首先,让我们模拟一个单独的实验,在这个实验中,我们使用标准 t 检验比较两组的平均值。我们将改变影响的大小(根据 Cohen's d 的规定)、I 类错误率和样本大小,并针对每一个,我们将检查重要结果(即功率)的比例是如何受到影响的。图[10.4](#fig:plotPowerSim)显示了功率如何随这些因素的函数而变化的示例。
```r
# Simulate power as a function of sample size, effect size, and alpha
# create a set of functions to generate simulated results
powerDf <-
expand.grid(
sampSizePerGroup = c(12, 24, 48, 96),
effectSize = c(.2, .5, .8),
alpha = c(0.005, 0.05)
) %>%
tidyr::expand(effectSize, sampSizePerGroup, alpha) %>%
group_by(effectSize, sampSizePerGroup, alpha)
runPowerSim <- function(df, nsims = 1000) {
p <- array(NA, dim = nsims)
for (s in 1:nsims) {
data <- data.frame(
y = rnorm(df$sampSizePerGroup * 2),
group = array(0, dim = df$sampSizePerGroup * 2)
)
data$group[1:df$sampSizePerGroup] <- 1
data$y[data$group == 1] <- data$y[data$group == 1] + df$effectSize
tt <- t.test(y ~ group, data = data)
p[s] <- tt$p.value
}
return(data.frame(power = mean(p < df$alpha)))
}
# run the simulation
powerSimResults <- powerDf %>%
do(runPowerSim(.))
```
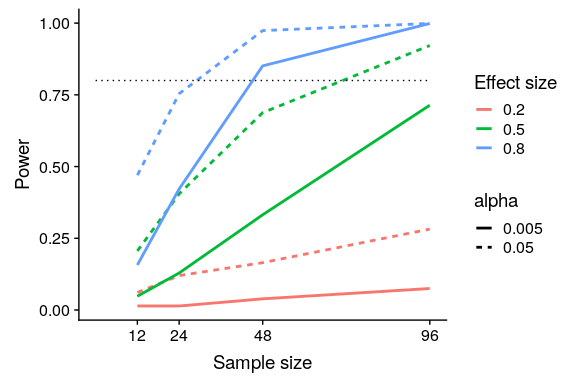
图 10.4 功率模拟结果,显示功率与样本大小的函数关系,效果大小显示为不同颜色,alpha 显示为线条类型。80%功率的标准标准标准用虚线黑线表示。
这个模拟表明,即使样本大小为 96,我们也几乎没有能力用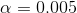找到一个小的效果(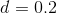)。这意味着,一项旨在实现这一目标的研究将是徒劳的,也就是说,即使存在这种规模的真实效应,也几乎可以保证什么也找不到。
至少有两个重要的原因需要关注统计能力,一个是我们在这里讨论的,另一个是我们将在第[17 章](#doing-reproducible-research)中讨论的。如果你是一名研究人员,你可能不想花时间做无用的实验。运行一个动力不足的研究基本上是徒劳的,因为这意味着即使它存在,人们也很难找到效果。
### 10.3.1 功率分析
幸运的是,有一些工具可以帮助我们确定实验的统计能力。这些工具最常见的用途是在计划一个实验时,我们想确定我们的样本需要多大才能有足够的能力发现我们感兴趣的效果。
假设我们有兴趣进行一项研究,研究 iOS 和 Android 设备用户之间的特定个性特征是如何不同的。我们的计划是收集两组个体并测量他们的人格特征,然后用 t 检验比较这两组。为了确定必要的样本大小,我们可以使用`pwr`库中的`pwr.t.test()`函数。
```r
# power analysis for Cohen's d = 0.5, for 80% power with alpha = 0.05
pwr.t.test(d = 0.5, power = 0.8, sig.level = 0.05)
```
```r
##
## Two-sample t test power calculation
##
## n = 64
## d = 0.5
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group
```
这告诉我们,为了有足够的力量找到中等规模的效果,我们需要每组至少 64 名受试者。在开始一项新的研究之前进行一次功率分析总是很重要的,以确保研究不会因为样本太小而无效。
您可能会想到,如果效果大小足够大,那么所需的样本将非常小。例如,如果我们运行相同的功率分析,效果大小为 d=3,那么我们将看到,每个组中只有大约 3 个受试者有足够的功率来发现差异。
```r
##
## Two-sample t test power calculation
##
## n = 3.1
## d = 3
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group
```
然而,在科学界很少有人做这样一个实验,我们期望能发现如此巨大的影响——正如我们不需要统计数据来告诉我们 16 岁的孩子比 6 岁的孩子高一样。当我们进行功率分析时,我们需要指定一个对我们的研究合理的效应大小,这通常来自以前的研究。然而,在第[17 章](#doing-reproducible-research)中,我们将讨论一种被称为“赢家诅咒”的现象,这种现象可能导致公布的效果大小大于实际效果大小,因此也应记住这一点。
- 前言
- 0.1 本书为什么存在?
- 0.2 你不是统计学家-我们为什么要听你的?
- 0.3 为什么是 R?
- 0.4 数据的黄金时代
- 0.5 开源书籍
- 0.6 确认
- 1 引言
- 1.1 什么是统计思维?
- 1.2 统计数据能为我们做什么?
- 1.3 统计学的基本概念
- 1.4 因果关系与统计
- 1.5 阅读建议
- 2 处理数据
- 2.1 什么是数据?
- 2.2 测量尺度
- 2.3 什么是良好的测量?
- 2.4 阅读建议
- 3 概率
- 3.1 什么是概率?
- 3.2 我们如何确定概率?
- 3.3 概率分布
- 3.4 条件概率
- 3.5 根据数据计算条件概率
- 3.6 独立性
- 3.7 逆转条件概率:贝叶斯规则
- 3.8 数据学习
- 3.9 优势比
- 3.10 概率是什么意思?
- 3.11 阅读建议
- 4 汇总数据
- 4.1 为什么要总结数据?
- 4.2 使用表格汇总数据
- 4.3 分布的理想化表示
- 4.4 阅读建议
- 5 将模型拟合到数据
- 5.1 什么是模型?
- 5.2 统计建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最简单的模型:平均值
- 5.6 模式
- 5.7 变异性:平均值与数据的拟合程度如何?
- 5.8 使用模拟了解统计数据
- 5.9 Z 分数
- 6 数据可视化
- 6.1 数据可视化如何拯救生命
- 6.2 绘图解剖
- 6.3 使用 ggplot 在 R 中绘制
- 6.4 良好可视化原则
- 6.5 最大化数据/墨水比
- 6.6 避免图表垃圾
- 6.7 避免数据失真
- 6.8 谎言因素
- 6.9 记住人的局限性
- 6.10 其他因素的修正
- 6.11 建议阅读和视频
- 7 取样
- 7.1 我们如何取样?
- 7.2 采样误差
- 7.3 平均值的标准误差
- 7.4 中心极限定理
- 7.5 置信区间
- 7.6 阅读建议
- 8 重新采样和模拟
- 8.1 蒙特卡罗模拟
- 8.2 统计的随机性
- 8.3 生成随机数
- 8.4 使用蒙特卡罗模拟
- 8.5 使用模拟统计:引导程序
- 8.6 阅读建议
- 9 假设检验
- 9.1 无效假设统计检验(NHST)
- 9.2 无效假设统计检验:一个例子
- 9.3 无效假设检验过程
- 9.4 现代环境下的 NHST:多重测试
- 9.5 阅读建议
- 10 置信区间、效应大小和统计功率
- 10.1 置信区间
- 10.2 效果大小
- 10.3 统计能力
- 10.4 阅读建议
- 11 贝叶斯统计
- 11.1 生成模型
- 11.2 贝叶斯定理与逆推理
- 11.3 进行贝叶斯估计
- 11.4 估计后验分布
- 11.5 选择优先权
- 11.6 贝叶斯假设检验
- 11.7 阅读建议
- 12 分类关系建模
- 12.1 示例:糖果颜色
- 12.2 皮尔逊卡方检验
- 12.3 应急表及双向试验
- 12.4 标准化残差
- 12.5 优势比
- 12.6 贝叶斯系数
- 12.7 超出 2 x 2 表的分类分析
- 12.8 注意辛普森悖论
- 13 建模持续关系
- 13.1 一个例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否与仇恨犯罪有关?
- 13.3 协方差和相关性
- 13.4 相关性和因果关系
- 13.5 阅读建议
- 14 一般线性模型
- 14.1 线性回归
- 14.2 安装更复杂的模型
- 14.3 变量之间的相互作用
- 14.4“预测”的真正含义是什么?
- 14.5 阅读建议
- 15 比较方法
- 15.1 学生 T 考试
- 15.2 t 检验作为线性模型
- 15.3 平均差的贝叶斯因子
- 15.4 配对 t 检验
- 15.5 比较两种以上的方法
- 16 统计建模过程:一个实例
- 16.1 统计建模过程
- 17 做重复性研究
- 17.1 我们认为科学应该如何运作
- 17.2 科学(有时)是如何工作的
- 17.3 科学中的再现性危机
- 17.4 有问题的研究实践
- 17.5 进行重复性研究
- 17.6 进行重复性数据分析
- 17.7 结论:提高科学水平
- 17.8 阅读建议
- References