
## 6.2 绘图解剖
绘制数据的目的是以二维(有时是三维)表示形式呈现数据集的摘要。我们将尺寸称为 _ 轴 _——水平轴称为 _X 轴 _,垂直轴称为 _Y 轴 _。我们可以按照突出显示数据值的方式沿轴排列数据。这些值可以是连续的,也可以是分类的。
我们可以使用许多不同类型的地块,它们有不同的优点和缺点。假设我们有兴趣在 nhanes 数据集中描述男女身高差异。图[6.3](#fig:plotHeight)显示了绘制这些数据的四种不同方法。
1. 面板 A 中的条形图显示了平均值的差异,但没有显示这些平均值周围的数据分布有多广——正如我们稍后将看到的,了解这一点对于确定我们认为两组之间的差异是否足够大而重要至关重要。
2. 第二个图显示了所有数据点重叠的条形图——这使得男性和女性的身高分布重叠更加清晰,但由于数据点数量众多,仍然很难看到。
一般来说,我们更喜欢使用一种绘图技术,它可以清楚地显示数据点的分布情况。
1. 在面板 C 中,我们看到一个清晰显示数据点的例子,称为 _ 小提琴图 _,它绘制了每种情况下的数据分布(经过一点平滑处理)。
2. 另一个选项是面板 D 中显示的 _ 方框图 _,它显示了中间值(中心线)、可变性测量值(方框宽度,基于称为四分位范围的测量值)和任何异常值(由线条末端的点表示)。这两种方法都是显示数据的有效方法,为数据的分发提供了良好的感觉。
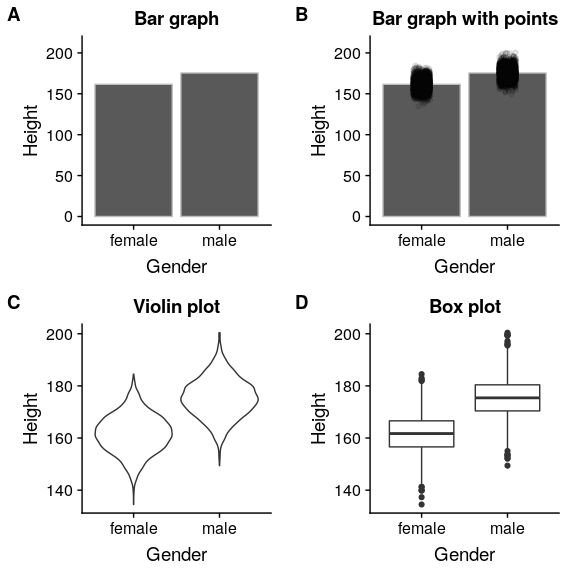
图 6.3 nhanes 数据集中绘制男女身高差异的四种不同方法。面板 A 绘制了两组的平均值,这无法评估两个分布的相对重叠。面板 B 显示了相同的条,但也覆盖了数据点,使它们抖动,以便我们可以看到它们的总体分布。面板 C 显示了小提琴图,显示了每组数据集的分布。面板 D 显示了一个方框图,它突出了分布的分布以及任何异常值(显示为单个点)。
- 前言
- 0.1 本书为什么存在?
- 0.2 你不是统计学家-我们为什么要听你的?
- 0.3 为什么是 R?
- 0.4 数据的黄金时代
- 0.5 开源书籍
- 0.6 确认
- 1 引言
- 1.1 什么是统计思维?
- 1.2 统计数据能为我们做什么?
- 1.3 统计学的基本概念
- 1.4 因果关系与统计
- 1.5 阅读建议
- 2 处理数据
- 2.1 什么是数据?
- 2.2 测量尺度
- 2.3 什么是良好的测量?
- 2.4 阅读建议
- 3 概率
- 3.1 什么是概率?
- 3.2 我们如何确定概率?
- 3.3 概率分布
- 3.4 条件概率
- 3.5 根据数据计算条件概率
- 3.6 独立性
- 3.7 逆转条件概率:贝叶斯规则
- 3.8 数据学习
- 3.9 优势比
- 3.10 概率是什么意思?
- 3.11 阅读建议
- 4 汇总数据
- 4.1 为什么要总结数据?
- 4.2 使用表格汇总数据
- 4.3 分布的理想化表示
- 4.4 阅读建议
- 5 将模型拟合到数据
- 5.1 什么是模型?
- 5.2 统计建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最简单的模型:平均值
- 5.6 模式
- 5.7 变异性:平均值与数据的拟合程度如何?
- 5.8 使用模拟了解统计数据
- 5.9 Z 分数
- 6 数据可视化
- 6.1 数据可视化如何拯救生命
- 6.2 绘图解剖
- 6.3 使用 ggplot 在 R 中绘制
- 6.4 良好可视化原则
- 6.5 最大化数据/墨水比
- 6.6 避免图表垃圾
- 6.7 避免数据失真
- 6.8 谎言因素
- 6.9 记住人的局限性
- 6.10 其他因素的修正
- 6.11 建议阅读和视频
- 7 取样
- 7.1 我们如何取样?
- 7.2 采样误差
- 7.3 平均值的标准误差
- 7.4 中心极限定理
- 7.5 置信区间
- 7.6 阅读建议
- 8 重新采样和模拟
- 8.1 蒙特卡罗模拟
- 8.2 统计的随机性
- 8.3 生成随机数
- 8.4 使用蒙特卡罗模拟
- 8.5 使用模拟统计:引导程序
- 8.6 阅读建议
- 9 假设检验
- 9.1 无效假设统计检验(NHST)
- 9.2 无效假设统计检验:一个例子
- 9.3 无效假设检验过程
- 9.4 现代环境下的 NHST:多重测试
- 9.5 阅读建议
- 10 置信区间、效应大小和统计功率
- 10.1 置信区间
- 10.2 效果大小
- 10.3 统计能力
- 10.4 阅读建议
- 11 贝叶斯统计
- 11.1 生成模型
- 11.2 贝叶斯定理与逆推理
- 11.3 进行贝叶斯估计
- 11.4 估计后验分布
- 11.5 选择优先权
- 11.6 贝叶斯假设检验
- 11.7 阅读建议
- 12 分类关系建模
- 12.1 示例:糖果颜色
- 12.2 皮尔逊卡方检验
- 12.3 应急表及双向试验
- 12.4 标准化残差
- 12.5 优势比
- 12.6 贝叶斯系数
- 12.7 超出 2 x 2 表的分类分析
- 12.8 注意辛普森悖论
- 13 建模持续关系
- 13.1 一个例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否与仇恨犯罪有关?
- 13.3 协方差和相关性
- 13.4 相关性和因果关系
- 13.5 阅读建议
- 14 一般线性模型
- 14.1 线性回归
- 14.2 安装更复杂的模型
- 14.3 变量之间的相互作用
- 14.4“预测”的真正含义是什么?
- 14.5 阅读建议
- 15 比较方法
- 15.1 学生 T 考试
- 15.2 t 检验作为线性模型
- 15.3 平均差的贝叶斯因子
- 15.4 配对 t 检验
- 15.5 比较两种以上的方法
- 16 统计建模过程:一个实例
- 16.1 统计建模过程
- 17 做重复性研究
- 17.1 我们认为科学应该如何运作
- 17.2 科学(有时)是如何工作的
- 17.3 科学中的再现性危机
- 17.4 有问题的研究实践
- 17.5 进行重复性研究
- 17.6 进行重复性数据分析
- 17.7 结论:提高科学水平
- 17.8 阅读建议
- References