
# 训练模型
现在我们已经定义了模型,损失函数和优化函数,训练模型来学习参数`w`和`b`。要训练模型,请定义以下全局变量:
* `num_epochs`:运行训练的迭代次数。每次迭代,模型都会学习更好的参数,我们将在后面的图中看到。
* `w_hat`和`b_hat`:收集估计的`w`和`b`参数。
* `loss_epochs`,`mse_epochs`,`rs_epochs`:收集训练数据集中的总误差值,以及每次迭代中测试数据集上模型的 mse 和 r 平方值。
* `mse_score`和`rs_score`:收集最终训练模型的 mse 和 r 平方值。
```py
num_epochs = 1500
w_hat = 0
b_hat = 0
loss_epochs = np.empty(shape=[num_epochs],dtype=float)
mse_epochs = np.empty(shape=[num_epochs],dtype=float)
rs_epochs = np.empty(shape=[num_epochs],dtype=float)
mse_score = 0
rs_score = 0
```
初始化会话和全局变量后,运行`num_epoch`次的训练循环:
```py
with tf.Session() as tfs:
tf.global_variables_initializer().run()
for epoch in range(num_epochs):
```
在循环的每次迭代中,在训练数据上运行优化器:
```py
tfs.run(optimizer, feed_dict={x_tensor: X_train, y_tensor: y_train})
```
使用学习的`w`和`b`值,计算误差并将其保存在`loss_val`中以便稍后绘制:
```py
loss_val = tfs.run(loss,feed_dict={x_tensor: X_train, y_tensor: y_train})
loss_epochs[epoch] = loss_val
```
计算测试数据预测值的均方误差和 r 平方值:
```py
mse_score = tfs.run(mse,feed_dict={x_tensor: X_test, y_tensor: y_test})
mse_epochs[epoch] = mse_score
rs_score = tfs.run(rs,feed_dict={x_tensor: X_test, y_tensor: y_test})
rs_epochs[epoch] = rs_score
```
最后,一旦完成循环,保存`w`和`b`的值以便稍后绘制它们:
```py
w_hat,b_hat = tfs.run([w,b])
w_hat = w_hat.reshape(1)
```
让我们在 2,000 次迭代后打印模型和测试数据的最终均方误差:
```py
print('model : Y = {0:.8f} X + {1:.8f}'.format(w_hat[0],b_hat[0]))
print('For test data : MSE = {0:.8f}, R2 = {1:.8f} '.format(
mse_score,rs_score))
```
This gives us the following output:
```py
model : Y = 20.37448120 X + -2.75295663
For test data : MSE = 297.57995605, R2 = 0.66098368
```
因此,我们训练的模型不是一个非常好的模型,但我们将在后面的章节中看到如何使用神经网络来改进它。
本章的目标是介绍如何使用 TensorFlow 构建和训练回归模型,而无需使用神经网络。
让我们绘制估计模型和原始数据:
```py
plt.figure(figsize=(14,8))
plt.title('Original Data and Trained Model')
x_plot = [np.min(X)-1,np.max(X)+1]
y_plot = w_hat*x_plot+b_hat
plt.axis([x_plot[0],x_plot[1],y_plot[0],y_plot[1]])
plt.plot(X,y,'b.',label='Original Data')
plt.plot(x_plot,y_plot,'r-',label='Trained Model')
plt.legend()
plt.show()
```
我们得到以下原始数据与受训模型数据的关系图:
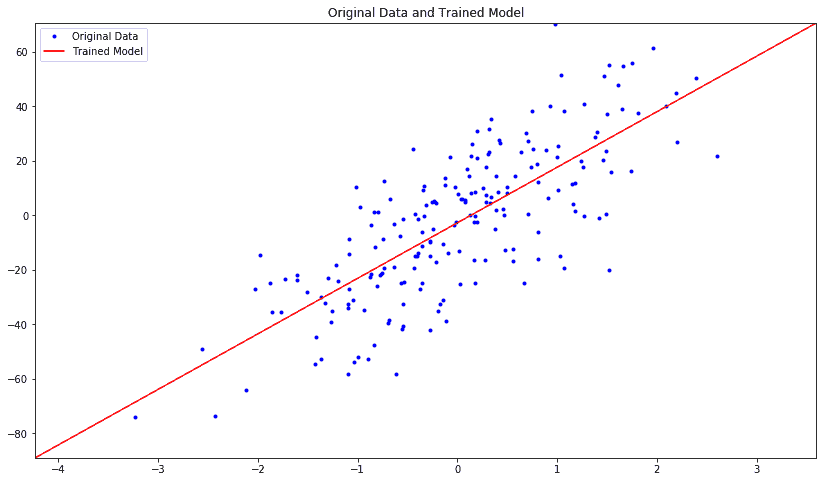
让我们绘制每次迭代中训练和测试数据的均方误差:
```py
plt.figure(figsize=(14,8))
plt.axis([0,num_epochs,0,np.max(loss_epochs)])
plt.plot(loss_epochs, label='Loss on X_train')
plt.title('Loss in Iterations')
plt.xlabel('# Epoch')
plt.ylabel('MSE')
plt.axis([0,num_epochs,0,np.max(mse_epochs)])
plt.plot(mse_epochs, label='MSE on X_test')
plt.xlabel('# Epoch')
plt.ylabel('MSE')
plt.legend()
plt.show()
```
我们得到以下图,显示每次迭代时,均方误差减小,然后保持在 500 附近的相同水平:
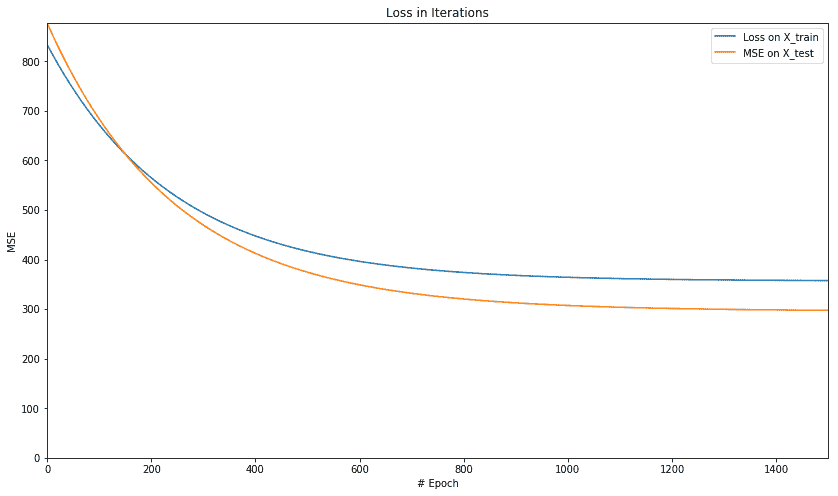
让我们绘制 r 平方的值:
```py
plt.figure(figsize=(14,8))
plt.axis([0,num_epochs,0,np.max(rs_epochs)])
plt.plot(rs_epochs, label='R2 on X_test')
plt.xlabel('# Epoch')
plt.ylabel('R2')
plt.legend()
plt.show()
```
当我们绘制 r 平方超过周期的值时,我们得到以下图:
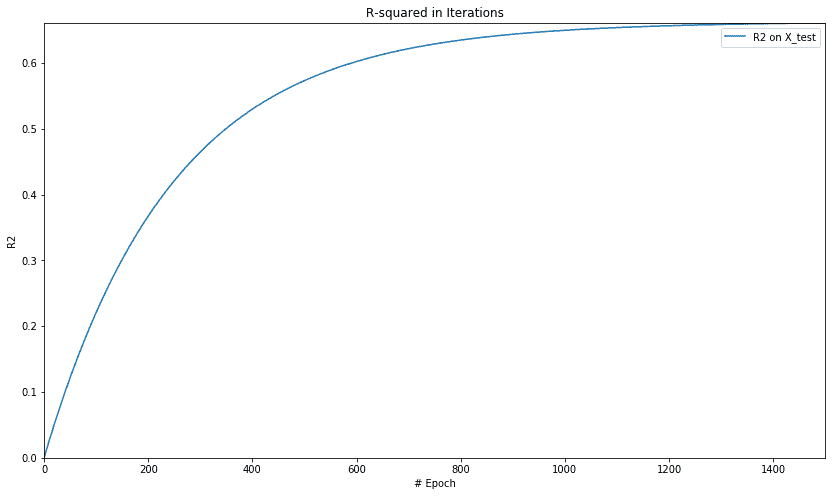
这基本上表明该模型以 r 的平均值开始,但随着模型的训练并减少误差,r 平方的值开始变高,最终在某一点变得稳定略高于 0.6。
绘制 MSE 和 r-squared 可以让我们看到我们的模型得到多快的训练以及它开始变得稳定的地方,以便进一步的训练在减少错误方面产生微不足道的好处或几乎没有好处。
- TensorFlow 101
- 什么是 TensorFlow?
- TensorFlow 核心
- 代码预热 - Hello TensorFlow
- 张量
- 常量
- 操作
- 占位符
- 从 Python 对象创建张量
- 变量
- 从库函数生成的张量
- 使用相同的值填充张量元素
- 用序列填充张量元素
- 使用随机分布填充张量元素
- 使用tf.get_variable()获取变量
- 数据流图或计算图
- 执行顺序和延迟加载
- 跨计算设备执行图 - CPU 和 GPU
- 将图节点放置在特定的计算设备上
- 简单放置
- 动态展示位置
- 软放置
- GPU 内存处理
- 多个图
- TensorBoard
- TensorBoard 最小的例子
- TensorBoard 详情
- 总结
- TensorFlow 的高级库
- TF Estimator - 以前的 TF 学习
- TF Slim
- TFLearn
- 创建 TFLearn 层
- TFLearn 核心层
- TFLearn 卷积层
- TFLearn 循环层
- TFLearn 正则化层
- TFLearn 嵌入层
- TFLearn 合并层
- TFLearn 估计层
- 创建 TFLearn 模型
- TFLearn 模型的类型
- 训练 TFLearn 模型
- 使用 TFLearn 模型
- PrettyTensor
- Sonnet
- 总结
- Keras 101
- 安装 Keras
- Keras 中的神经网络模型
- 在 Keras 建立模型的工作流程
- 创建 Keras 模型
- 用于创建 Keras 模型的顺序 API
- 用于创建 Keras 模型的函数式 API
- Keras 层
- Keras 核心层
- Keras 卷积层
- Keras 池化层
- Keras 本地连接层
- Keras 循环层
- Keras 嵌入层
- Keras 合并层
- Keras 高级激活层
- Keras 正则化层
- Keras 噪音层
- 将层添加到 Keras 模型
- 用于将层添加到 Keras 模型的顺序 API
- 用于向 Keras 模型添加层的函数式 API
- 编译 Keras 模型
- 训练 Keras 模型
- 使用 Keras 模型进行预测
- Keras 的附加模块
- MNIST 数据集的 Keras 序列模型示例
- 总结
- 使用 TensorFlow 进行经典机器学习
- 简单的线性回归
- 数据准备
- 构建一个简单的回归模型
- 定义输入,参数和其他变量
- 定义模型
- 定义损失函数
- 定义优化器函数
- 训练模型
- 使用训练的模型进行预测
- 多元回归
- 正则化回归
- 套索正则化
- 岭正则化
- ElasticNet 正则化
- 使用逻辑回归进行分类
- 二分类的逻辑回归
- 多类分类的逻辑回归
- 二分类
- 多类分类
- 总结
- 使用 TensorFlow 和 Keras 的神经网络和 MLP
- 感知机
- 多层感知机
- 用于图像分类的 MLP
- 用于 MNIST 分类的基于 TensorFlow 的 MLP
- 用于 MNIST 分类的基于 Keras 的 MLP
- 用于 MNIST 分类的基于 TFLearn 的 MLP
- 使用 TensorFlow,Keras 和 TFLearn 的 MLP 总结
- 用于时间序列回归的 MLP
- 总结
- 使用 TensorFlow 和 Keras 的 RNN
- 简单循环神经网络
- RNN 变种
- LSTM 网络
- GRU 网络
- TensorFlow RNN
- TensorFlow RNN 单元类
- TensorFlow RNN 模型构建类
- TensorFlow RNN 单元包装器类
- 适用于 RNN 的 Keras
- RNN 的应用领域
- 用于 MNIST 数据的 Keras 中的 RNN
- 总结
- 使用 TensorFlow 和 Keras 的时间序列数据的 RNN
- 航空公司乘客数据集
- 加载 airpass 数据集
- 可视化 airpass 数据集
- 使用 TensorFlow RNN 模型预处理数据集
- TensorFlow 中的简单 RNN
- TensorFlow 中的 LSTM
- TensorFlow 中的 GRU
- 使用 Keras RNN 模型预处理数据集
- 使用 Keras 的简单 RNN
- 使用 Keras 的 LSTM
- 使用 Keras 的 GRU
- 总结
- 使用 TensorFlow 和 Keras 的文本数据的 RNN
- 词向量表示
- 为 word2vec 模型准备数据
- 加载和准备 PTB 数据集
- 加载和准备 text8 数据集
- 准备小验证集
- 使用 TensorFlow 的 skip-gram 模型
- 使用 t-SNE 可视化单词嵌入
- keras 的 skip-gram 模型
- 使用 TensorFlow 和 Keras 中的 RNN 模型生成文本
- TensorFlow 中的 LSTM 文本生成
- Keras 中的 LSTM 文本生成
- 总结
- 使用 TensorFlow 和 Keras 的 CNN
- 理解卷积
- 了解池化
- CNN 架构模式 - LeNet
- 用于 MNIST 数据的 LeNet
- 使用 TensorFlow 的用于 MNIST 的 LeNet CNN
- 使用 Keras 的用于 MNIST 的 LeNet CNN
- 用于 CIFAR10 数据的 LeNet
- 使用 TensorFlow 的用于 CIFAR10 的 ConvNets
- 使用 Keras 的用于 CIFAR10 的 ConvNets
- 总结
- 使用 TensorFlow 和 Keras 的自编码器
- 自编码器类型
- TensorFlow 中的栈式自编码器
- Keras 中的栈式自编码器
- TensorFlow 中的去噪自编码器
- Keras 中的去噪自编码器
- TensorFlow 中的变分自编码器
- Keras 中的变分自编码器
- 总结
- TF 服务:生产中的 TensorFlow 模型
- 在 TensorFlow 中保存和恢复模型
- 使用保护程序类保存和恢复所有图变量
- 使用保护程序类保存和恢复所选变量
- 保存和恢复 Keras 模型
- TensorFlow 服务
- 安装 TF 服务
- 保存 TF 服务的模型
- 提供 TF 服务模型
- 在 Docker 容器中提供 TF 服务
- 安装 Docker
- 为 TF 服务构建 Docker 镜像
- 在 Docker 容器中提供模型
- Kubernetes 中的 TensorFlow 服务
- 安装 Kubernetes
- 将 Docker 镜像上传到 dockerhub
- 在 Kubernetes 部署
- 总结
- 迁移学习和预训练模型
- ImageNet 数据集
- 再训练或微调模型
- COCO 动物数据集和预处理图像
- TensorFlow 中的 VGG16
- 使用 TensorFlow 中预训练的 VGG16 进行图像分类
- TensorFlow 中的图像预处理,用于预训练的 VGG16
- 使用 TensorFlow 中的再训练的 VGG16 进行图像分类
- Keras 的 VGG16
- 使用 Keras 中预训练的 VGG16 进行图像分类
- 使用 Keras 中再训练的 VGG16 进行图像分类
- TensorFlow 中的 Inception v3
- 使用 TensorFlow 中的 Inception v3 进行图像分类
- 使用 TensorFlow 中的再训练的 Inception v3 进行图像分类
- 总结
- 深度强化学习
- OpenAI Gym 101
- 将简单的策略应用于 cartpole 游戏
- 强化学习 101
- Q 函数(在模型不可用时学习优化)
- RL 算法的探索与开发
- V 函数(模型可用时学习优化)
- 强化学习技巧
- 强化学习的朴素神经网络策略
- 实现 Q-Learning
- Q-Learning 的初始化和离散化
- 使用 Q-Table 进行 Q-Learning
- Q-Network 或深 Q 网络(DQN)的 Q-Learning
- 总结
- 生成性对抗网络
- 生成性对抗网络 101
- 建立和训练 GAN 的最佳实践
- 使用 TensorFlow 的简单的 GAN
- 使用 Keras 的简单的 GAN
- 使用 TensorFlow 和 Keras 的深度卷积 GAN
- 总结
- 使用 TensorFlow 集群的分布式模型
- 分布式执行策略
- TensorFlow 集群
- 定义集群规范
- 创建服务器实例
- 定义服务器和设备之间的参数和操作
- 定义并训练图以进行异步更新
- 定义并训练图以进行同步更新
- 总结
- 移动和嵌入式平台上的 TensorFlow 模型
- 移动平台上的 TensorFlow
- Android 应用中的 TF Mobile
- Android 上的 TF Mobile 演示
- iOS 应用中的 TF Mobile
- iOS 上的 TF Mobile 演示
- TensorFlow Lite
- Android 上的 TF Lite 演示
- iOS 上的 TF Lite 演示
- 总结
- R 中的 TensorFlow 和 Keras
- 在 R 中安装 TensorFlow 和 Keras 软件包
- R 中的 TF 核心 API
- R 中的 TF 估计器 API
- R 中的 Keras API
- R 中的 TensorBoard
- R 中的 tfruns 包
- 总结
- 调试 TensorFlow 模型
- 使用tf.Session.run()获取张量值
- 使用tf.Print()打印张量值
- 用tf.Assert()断言条件
- 使用 TensorFlow 调试器(tfdbg)进行调试
- 总结
- 张量处理单元