
# 强化学习 101
强化学习由智能体从前一个时间步骤输入观察和奖励并以动作产生输出来描述,目标是最大化累积奖励。
智能体具有策略,值函数和模型:
* 智能体用于选择下一个动作的算法称为**策略**。在上一节中,我们编写了一个策略,它将采用一组参数 theta,并根据观察和参数之间的乘法返回下一个动作。该策略由以下等式表示:

`S`是一组状态,`A`是一组动作。
策略是确定性的或随机性的。
* 确定性策略在每次运行中为相同状态返回相同的操作:
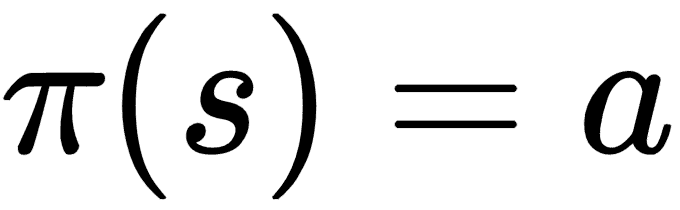
* 随机策略为每次运行中的相同状态返回相同操作的不同概率:

* **值函数**根据当前状态中的所选动作预测长期奖励的数量。因此,值函数特定于智能体使用的策略。奖励表示行动的直接收益,而价值函数表示行动的累积或长期未来收益。奖励由环境返回,价值函数由智能体在每个时间步骤估计。
* **模型**表示智能体在内部保存的环境。该模型可能是环境的不完美表示。智能体使用该模型来估计所选动作的奖励和下一个状态。
智能体的目标还可以是为马尔可夫决策过程(MDP)找到最优策略。 MDP 是从一个州到另一个州的观察,行动,奖励和过渡的数学表示。为简洁起见,我们将省略对 MDP 的讨论,并建议好奇的读者在互联网上搜索更深入 MDP 的资源。
- TensorFlow 101
- 什么是 TensorFlow?
- TensorFlow 核心
- 代码预热 - Hello TensorFlow
- 张量
- 常量
- 操作
- 占位符
- 从 Python 对象创建张量
- 变量
- 从库函数生成的张量
- 使用相同的值填充张量元素
- 用序列填充张量元素
- 使用随机分布填充张量元素
- 使用tf.get_variable()获取变量
- 数据流图或计算图
- 执行顺序和延迟加载
- 跨计算设备执行图 - CPU 和 GPU
- 将图节点放置在特定的计算设备上
- 简单放置
- 动态展示位置
- 软放置
- GPU 内存处理
- 多个图
- TensorBoard
- TensorBoard 最小的例子
- TensorBoard 详情
- 总结
- TensorFlow 的高级库
- TF Estimator - 以前的 TF 学习
- TF Slim
- TFLearn
- 创建 TFLearn 层
- TFLearn 核心层
- TFLearn 卷积层
- TFLearn 循环层
- TFLearn 正则化层
- TFLearn 嵌入层
- TFLearn 合并层
- TFLearn 估计层
- 创建 TFLearn 模型
- TFLearn 模型的类型
- 训练 TFLearn 模型
- 使用 TFLearn 模型
- PrettyTensor
- Sonnet
- 总结
- Keras 101
- 安装 Keras
- Keras 中的神经网络模型
- 在 Keras 建立模型的工作流程
- 创建 Keras 模型
- 用于创建 Keras 模型的顺序 API
- 用于创建 Keras 模型的函数式 API
- Keras 层
- Keras 核心层
- Keras 卷积层
- Keras 池化层
- Keras 本地连接层
- Keras 循环层
- Keras 嵌入层
- Keras 合并层
- Keras 高级激活层
- Keras 正则化层
- Keras 噪音层
- 将层添加到 Keras 模型
- 用于将层添加到 Keras 模型的顺序 API
- 用于向 Keras 模型添加层的函数式 API
- 编译 Keras 模型
- 训练 Keras 模型
- 使用 Keras 模型进行预测
- Keras 的附加模块
- MNIST 数据集的 Keras 序列模型示例
- 总结
- 使用 TensorFlow 进行经典机器学习
- 简单的线性回归
- 数据准备
- 构建一个简单的回归模型
- 定义输入,参数和其他变量
- 定义模型
- 定义损失函数
- 定义优化器函数
- 训练模型
- 使用训练的模型进行预测
- 多元回归
- 正则化回归
- 套索正则化
- 岭正则化
- ElasticNet 正则化
- 使用逻辑回归进行分类
- 二分类的逻辑回归
- 多类分类的逻辑回归
- 二分类
- 多类分类
- 总结
- 使用 TensorFlow 和 Keras 的神经网络和 MLP
- 感知机
- 多层感知机
- 用于图像分类的 MLP
- 用于 MNIST 分类的基于 TensorFlow 的 MLP
- 用于 MNIST 分类的基于 Keras 的 MLP
- 用于 MNIST 分类的基于 TFLearn 的 MLP
- 使用 TensorFlow,Keras 和 TFLearn 的 MLP 总结
- 用于时间序列回归的 MLP
- 总结
- 使用 TensorFlow 和 Keras 的 RNN
- 简单循环神经网络
- RNN 变种
- LSTM 网络
- GRU 网络
- TensorFlow RNN
- TensorFlow RNN 单元类
- TensorFlow RNN 模型构建类
- TensorFlow RNN 单元包装器类
- 适用于 RNN 的 Keras
- RNN 的应用领域
- 用于 MNIST 数据的 Keras 中的 RNN
- 总结
- 使用 TensorFlow 和 Keras 的时间序列数据的 RNN
- 航空公司乘客数据集
- 加载 airpass 数据集
- 可视化 airpass 数据集
- 使用 TensorFlow RNN 模型预处理数据集
- TensorFlow 中的简单 RNN
- TensorFlow 中的 LSTM
- TensorFlow 中的 GRU
- 使用 Keras RNN 模型预处理数据集
- 使用 Keras 的简单 RNN
- 使用 Keras 的 LSTM
- 使用 Keras 的 GRU
- 总结
- 使用 TensorFlow 和 Keras 的文本数据的 RNN
- 词向量表示
- 为 word2vec 模型准备数据
- 加载和准备 PTB 数据集
- 加载和准备 text8 数据集
- 准备小验证集
- 使用 TensorFlow 的 skip-gram 模型
- 使用 t-SNE 可视化单词嵌入
- keras 的 skip-gram 模型
- 使用 TensorFlow 和 Keras 中的 RNN 模型生成文本
- TensorFlow 中的 LSTM 文本生成
- Keras 中的 LSTM 文本生成
- 总结
- 使用 TensorFlow 和 Keras 的 CNN
- 理解卷积
- 了解池化
- CNN 架构模式 - LeNet
- 用于 MNIST 数据的 LeNet
- 使用 TensorFlow 的用于 MNIST 的 LeNet CNN
- 使用 Keras 的用于 MNIST 的 LeNet CNN
- 用于 CIFAR10 数据的 LeNet
- 使用 TensorFlow 的用于 CIFAR10 的 ConvNets
- 使用 Keras 的用于 CIFAR10 的 ConvNets
- 总结
- 使用 TensorFlow 和 Keras 的自编码器
- 自编码器类型
- TensorFlow 中的栈式自编码器
- Keras 中的栈式自编码器
- TensorFlow 中的去噪自编码器
- Keras 中的去噪自编码器
- TensorFlow 中的变分自编码器
- Keras 中的变分自编码器
- 总结
- TF 服务:生产中的 TensorFlow 模型
- 在 TensorFlow 中保存和恢复模型
- 使用保护程序类保存和恢复所有图变量
- 使用保护程序类保存和恢复所选变量
- 保存和恢复 Keras 模型
- TensorFlow 服务
- 安装 TF 服务
- 保存 TF 服务的模型
- 提供 TF 服务模型
- 在 Docker 容器中提供 TF 服务
- 安装 Docker
- 为 TF 服务构建 Docker 镜像
- 在 Docker 容器中提供模型
- Kubernetes 中的 TensorFlow 服务
- 安装 Kubernetes
- 将 Docker 镜像上传到 dockerhub
- 在 Kubernetes 部署
- 总结
- 迁移学习和预训练模型
- ImageNet 数据集
- 再训练或微调模型
- COCO 动物数据集和预处理图像
- TensorFlow 中的 VGG16
- 使用 TensorFlow 中预训练的 VGG16 进行图像分类
- TensorFlow 中的图像预处理,用于预训练的 VGG16
- 使用 TensorFlow 中的再训练的 VGG16 进行图像分类
- Keras 的 VGG16
- 使用 Keras 中预训练的 VGG16 进行图像分类
- 使用 Keras 中再训练的 VGG16 进行图像分类
- TensorFlow 中的 Inception v3
- 使用 TensorFlow 中的 Inception v3 进行图像分类
- 使用 TensorFlow 中的再训练的 Inception v3 进行图像分类
- 总结
- 深度强化学习
- OpenAI Gym 101
- 将简单的策略应用于 cartpole 游戏
- 强化学习 101
- Q 函数(在模型不可用时学习优化)
- RL 算法的探索与开发
- V 函数(模型可用时学习优化)
- 强化学习技巧
- 强化学习的朴素神经网络策略
- 实现 Q-Learning
- Q-Learning 的初始化和离散化
- 使用 Q-Table 进行 Q-Learning
- Q-Network 或深 Q 网络(DQN)的 Q-Learning
- 总结
- 生成性对抗网络
- 生成性对抗网络 101
- 建立和训练 GAN 的最佳实践
- 使用 TensorFlow 的简单的 GAN
- 使用 Keras 的简单的 GAN
- 使用 TensorFlow 和 Keras 的深度卷积 GAN
- 总结
- 使用 TensorFlow 集群的分布式模型
- 分布式执行策略
- TensorFlow 集群
- 定义集群规范
- 创建服务器实例
- 定义服务器和设备之间的参数和操作
- 定义并训练图以进行异步更新
- 定义并训练图以进行同步更新
- 总结
- 移动和嵌入式平台上的 TensorFlow 模型
- 移动平台上的 TensorFlow
- Android 应用中的 TF Mobile
- Android 上的 TF Mobile 演示
- iOS 应用中的 TF Mobile
- iOS 上的 TF Mobile 演示
- TensorFlow Lite
- Android 上的 TF Lite 演示
- iOS 上的 TF Lite 演示
- 总结
- R 中的 TensorFlow 和 Keras
- 在 R 中安装 TensorFlow 和 Keras 软件包
- R 中的 TF 核心 API
- R 中的 TF 估计器 API
- R 中的 Keras API
- R 中的 TensorBoard
- R 中的 tfruns 包
- 总结
- 调试 TensorFlow 模型
- 使用tf.Session.run()获取张量值
- 使用tf.Print()打印张量值
- 用tf.Assert()断言条件
- 使用 TensorFlow 调试器(tfdbg)进行调试
- 总结
- 张量处理单元