
# 理解卷积
**卷积**是 CNN 架构背后的核心概念。简单来说,卷积是一种数学运算,它结合了两个来源的信息来产生一组新的信息。具体来说,它将一个称为内核的特殊矩阵应用于输入张量,以产生一组称为特征图的矩阵。可以使用任何流行的算法将内核应用于输入张量。
生成卷积矩阵的最常用算法如下:
```py
N_STRIDES = [1,1]
1\. Overlap the kernel with the top-left cells of the image matrix.
2\. Repeat while the kernel overlaps the image matrix:
2.1 c_col = 0
2.2 Repeat while the kernel overlaps the image matrix:
2.1.1 set c_row = 0 2.1.2 convolved_scalar = scalar_prod(kernel, overlapped cells)
2.1.3 convolved_matrix(c_row,c_col) = convolved_scalar
2.1.4 Slide the kernel down by N_STRIDES[0] rows.
2.1.5 c_row = c_row + 1
2.3 Slide the kernel to (topmost row, N_STRIDES[1] columns right)
2.4 c_col = c_col + 1
```
例如,我们假设核矩阵是 2 x 2 矩阵,输入图像是 3 x 3 矩阵。下图逐步显示了上述算法:
| | |
| --- | --- |
| 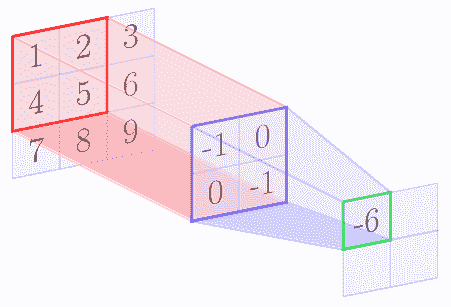 | 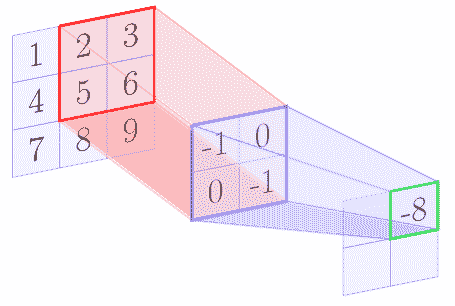 |
| 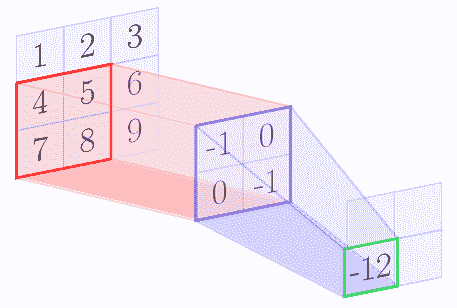 | 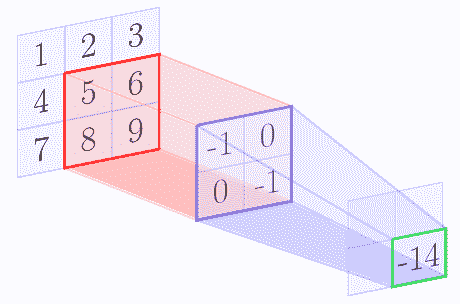 |
在 con 卷积操作结束时,我们得到以下特征图:
| | |
| --- | --- |
| -6 | -8 |
| -12 | -14 |
在上面的示例中,与卷积的原始输入相比,生成的特征映射的大小更小。通常,特征图的大小减小(内核大小-1)。因此,特征图的大小为:

**三维张量**
对于具有额外深度尺寸的三维张量,您可以将前面的算法视为应用于深度维度中的每个层。将卷积应用于 3D 张量的输出也是 2D 张量,因为卷积运算添加了三个通道。
**大步**
数组 N_STRIDES 中的 **步长** 是您想要将内核滑过的行或列的数字。在我们的例子中,我们使用了 1 的步幅。如果我们使用更多的步幅,那么特征图的大小将根据以下等式进一步减小:

**填充**
如果我们不希望减小特征映射的大小,那么我们可以在输入的所有边上使用填充,使得特征的大小增加填充大小的两倍。使用填充,可以按如下方式计算特征图的大小:
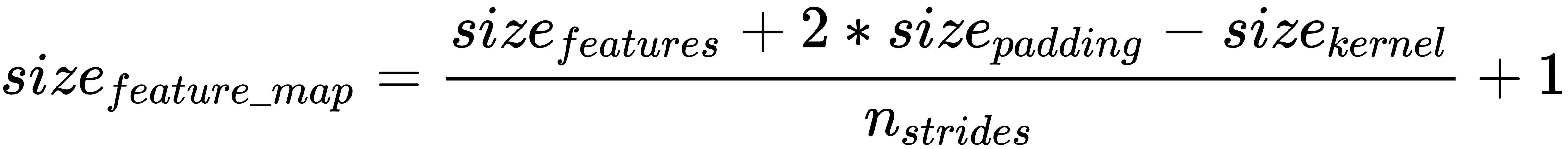
TensorFlow 允许两种填充:SAME 或 VALID。 SAME 填充意味着添加填充,使输出特征图与输入特征具有相同的大小。 VALID 填充意味着没有填充。
应用前面提到的卷积算法的结果是特征图,是原始张量的滤波版本。例如,特征图可能只有从原始图像中过滤出的轮廓。因此,内核也称为过滤器。对于每个内核,您将获得单独的 2D 特征图。
根据您希望网络学习的特征,您必须应用适当的过滤器来强调所需的特征。 但是,使用 CNN,模型可以自动了解哪些内核在卷积层中最有效。
**TensorFlow** 中的卷积运算
TensorFlow 提供实现卷积算法的卷积层。例如,具有以下签名的`tf.nn.conv2d()`操作:
```py
tf.nn.conv2d(
input,
filter,
strides,
padding,
use_cudnn_on_gpu=None,
data_format=None,
name=None
)
```
`input`和`filter`表示形状`[batch_size, input_height, input_width, input_depth]`的数据张量和形状`[filter_height, filter_width, input_depth, output_depth]`的核张量。内核张量中的 `output_depth`表示应该应用于输入的内核数量。 `strides`张量表示每个维度中要滑动的单元数。如上所述,`padding`是有效的或相同的。
您可以在以下链接中找到有关TensorFlow中可用卷积操作的更多信息:[https://www.tensorflow.org/api_guides/python/nn#Convolution](https://www.tensorflow.org/api_guides/python/nn#Convolution)
您可以在以下链接中找到有关 Keras 中可用卷积层的更多信息:[https://keras.io/layers/convolutional/](https://keras.io/layers/convolutional/)
以下链接提供了卷积的详细数学解释:[http://colah.github.io/posts/2014-07-Understanding-Convolutions/](http://colah.github.io/posts/2014-07-Understanding-Convolutions/)
[http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/](http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/)
[http://colah.github.io/posts/2014-07-Understanding-Convolutions/](http://colah.github.io/posts/2014-07-Understanding-Convolutions/)
卷积层或操作将输入值或神经元连接到下一个隐藏层神经元。每个隐藏层神经元连接到与内核中元素数量相同数量的输入神经元。所以在前面的例子中,内核有 4 个元素,因此隐藏层神经元连接到输入层的 4 个神经元(3×3 个神经元中)。在我们的例子中,输入层的 4 个神经元的这个区域被称为 CNN 理论中的**感受域**。
卷积层具有每个内核的单独权重和偏差参数。权重参数的数量等于内核中元素的数量,并且只有一个偏差参数。内核的所有连接共享相同的权重和偏差参数。因此在我们的例子中,将有 4 个权重参数和 1 个偏差参数,但如果我们在卷积层中使用 5 个内核,则总共将有 5 x 4 个权重参数和 5 个 1 个偏差参数,一组(4)每个特征图的权重,1 个偏差)参数。
- TensorFlow 101
- 什么是 TensorFlow?
- TensorFlow 核心
- 代码预热 - Hello TensorFlow
- 张量
- 常量
- 操作
- 占位符
- 从 Python 对象创建张量
- 变量
- 从库函数生成的张量
- 使用相同的值填充张量元素
- 用序列填充张量元素
- 使用随机分布填充张量元素
- 使用tf.get_variable()获取变量
- 数据流图或计算图
- 执行顺序和延迟加载
- 跨计算设备执行图 - CPU 和 GPU
- 将图节点放置在特定的计算设备上
- 简单放置
- 动态展示位置
- 软放置
- GPU 内存处理
- 多个图
- TensorBoard
- TensorBoard 最小的例子
- TensorBoard 详情
- 总结
- TensorFlow 的高级库
- TF Estimator - 以前的 TF 学习
- TF Slim
- TFLearn
- 创建 TFLearn 层
- TFLearn 核心层
- TFLearn 卷积层
- TFLearn 循环层
- TFLearn 正则化层
- TFLearn 嵌入层
- TFLearn 合并层
- TFLearn 估计层
- 创建 TFLearn 模型
- TFLearn 模型的类型
- 训练 TFLearn 模型
- 使用 TFLearn 模型
- PrettyTensor
- Sonnet
- 总结
- Keras 101
- 安装 Keras
- Keras 中的神经网络模型
- 在 Keras 建立模型的工作流程
- 创建 Keras 模型
- 用于创建 Keras 模型的顺序 API
- 用于创建 Keras 模型的函数式 API
- Keras 层
- Keras 核心层
- Keras 卷积层
- Keras 池化层
- Keras 本地连接层
- Keras 循环层
- Keras 嵌入层
- Keras 合并层
- Keras 高级激活层
- Keras 正则化层
- Keras 噪音层
- 将层添加到 Keras 模型
- 用于将层添加到 Keras 模型的顺序 API
- 用于向 Keras 模型添加层的函数式 API
- 编译 Keras 模型
- 训练 Keras 模型
- 使用 Keras 模型进行预测
- Keras 的附加模块
- MNIST 数据集的 Keras 序列模型示例
- 总结
- 使用 TensorFlow 进行经典机器学习
- 简单的线性回归
- 数据准备
- 构建一个简单的回归模型
- 定义输入,参数和其他变量
- 定义模型
- 定义损失函数
- 定义优化器函数
- 训练模型
- 使用训练的模型进行预测
- 多元回归
- 正则化回归
- 套索正则化
- 岭正则化
- ElasticNet 正则化
- 使用逻辑回归进行分类
- 二分类的逻辑回归
- 多类分类的逻辑回归
- 二分类
- 多类分类
- 总结
- 使用 TensorFlow 和 Keras 的神经网络和 MLP
- 感知机
- 多层感知机
- 用于图像分类的 MLP
- 用于 MNIST 分类的基于 TensorFlow 的 MLP
- 用于 MNIST 分类的基于 Keras 的 MLP
- 用于 MNIST 分类的基于 TFLearn 的 MLP
- 使用 TensorFlow,Keras 和 TFLearn 的 MLP 总结
- 用于时间序列回归的 MLP
- 总结
- 使用 TensorFlow 和 Keras 的 RNN
- 简单循环神经网络
- RNN 变种
- LSTM 网络
- GRU 网络
- TensorFlow RNN
- TensorFlow RNN 单元类
- TensorFlow RNN 模型构建类
- TensorFlow RNN 单元包装器类
- 适用于 RNN 的 Keras
- RNN 的应用领域
- 用于 MNIST 数据的 Keras 中的 RNN
- 总结
- 使用 TensorFlow 和 Keras 的时间序列数据的 RNN
- 航空公司乘客数据集
- 加载 airpass 数据集
- 可视化 airpass 数据集
- 使用 TensorFlow RNN 模型预处理数据集
- TensorFlow 中的简单 RNN
- TensorFlow 中的 LSTM
- TensorFlow 中的 GRU
- 使用 Keras RNN 模型预处理数据集
- 使用 Keras 的简单 RNN
- 使用 Keras 的 LSTM
- 使用 Keras 的 GRU
- 总结
- 使用 TensorFlow 和 Keras 的文本数据的 RNN
- 词向量表示
- 为 word2vec 模型准备数据
- 加载和准备 PTB 数据集
- 加载和准备 text8 数据集
- 准备小验证集
- 使用 TensorFlow 的 skip-gram 模型
- 使用 t-SNE 可视化单词嵌入
- keras 的 skip-gram 模型
- 使用 TensorFlow 和 Keras 中的 RNN 模型生成文本
- TensorFlow 中的 LSTM 文本生成
- Keras 中的 LSTM 文本生成
- 总结
- 使用 TensorFlow 和 Keras 的 CNN
- 理解卷积
- 了解池化
- CNN 架构模式 - LeNet
- 用于 MNIST 数据的 LeNet
- 使用 TensorFlow 的用于 MNIST 的 LeNet CNN
- 使用 Keras 的用于 MNIST 的 LeNet CNN
- 用于 CIFAR10 数据的 LeNet
- 使用 TensorFlow 的用于 CIFAR10 的 ConvNets
- 使用 Keras 的用于 CIFAR10 的 ConvNets
- 总结
- 使用 TensorFlow 和 Keras 的自编码器
- 自编码器类型
- TensorFlow 中的栈式自编码器
- Keras 中的栈式自编码器
- TensorFlow 中的去噪自编码器
- Keras 中的去噪自编码器
- TensorFlow 中的变分自编码器
- Keras 中的变分自编码器
- 总结
- TF 服务:生产中的 TensorFlow 模型
- 在 TensorFlow 中保存和恢复模型
- 使用保护程序类保存和恢复所有图变量
- 使用保护程序类保存和恢复所选变量
- 保存和恢复 Keras 模型
- TensorFlow 服务
- 安装 TF 服务
- 保存 TF 服务的模型
- 提供 TF 服务模型
- 在 Docker 容器中提供 TF 服务
- 安装 Docker
- 为 TF 服务构建 Docker 镜像
- 在 Docker 容器中提供模型
- Kubernetes 中的 TensorFlow 服务
- 安装 Kubernetes
- 将 Docker 镜像上传到 dockerhub
- 在 Kubernetes 部署
- 总结
- 迁移学习和预训练模型
- ImageNet 数据集
- 再训练或微调模型
- COCO 动物数据集和预处理图像
- TensorFlow 中的 VGG16
- 使用 TensorFlow 中预训练的 VGG16 进行图像分类
- TensorFlow 中的图像预处理,用于预训练的 VGG16
- 使用 TensorFlow 中的再训练的 VGG16 进行图像分类
- Keras 的 VGG16
- 使用 Keras 中预训练的 VGG16 进行图像分类
- 使用 Keras 中再训练的 VGG16 进行图像分类
- TensorFlow 中的 Inception v3
- 使用 TensorFlow 中的 Inception v3 进行图像分类
- 使用 TensorFlow 中的再训练的 Inception v3 进行图像分类
- 总结
- 深度强化学习
- OpenAI Gym 101
- 将简单的策略应用于 cartpole 游戏
- 强化学习 101
- Q 函数(在模型不可用时学习优化)
- RL 算法的探索与开发
- V 函数(模型可用时学习优化)
- 强化学习技巧
- 强化学习的朴素神经网络策略
- 实现 Q-Learning
- Q-Learning 的初始化和离散化
- 使用 Q-Table 进行 Q-Learning
- Q-Network 或深 Q 网络(DQN)的 Q-Learning
- 总结
- 生成性对抗网络
- 生成性对抗网络 101
- 建立和训练 GAN 的最佳实践
- 使用 TensorFlow 的简单的 GAN
- 使用 Keras 的简单的 GAN
- 使用 TensorFlow 和 Keras 的深度卷积 GAN
- 总结
- 使用 TensorFlow 集群的分布式模型
- 分布式执行策略
- TensorFlow 集群
- 定义集群规范
- 创建服务器实例
- 定义服务器和设备之间的参数和操作
- 定义并训练图以进行异步更新
- 定义并训练图以进行同步更新
- 总结
- 移动和嵌入式平台上的 TensorFlow 模型
- 移动平台上的 TensorFlow
- Android 应用中的 TF Mobile
- Android 上的 TF Mobile 演示
- iOS 应用中的 TF Mobile
- iOS 上的 TF Mobile 演示
- TensorFlow Lite
- Android 上的 TF Lite 演示
- iOS 上的 TF Lite 演示
- 总结
- R 中的 TensorFlow 和 Keras
- 在 R 中安装 TensorFlow 和 Keras 软件包
- R 中的 TF 核心 API
- R 中的 TF 估计器 API
- R 中的 Keras API
- R 中的 TensorBoard
- R 中的 tfruns 包
- 总结
- 调试 TensorFlow 模型
- 使用tf.Session.run()获取张量值
- 使用tf.Print()打印张量值
- 用tf.Assert()断言条件
- 使用 TensorFlow 调试器(tfdbg)进行调试
- 总结
- 张量处理单元