
[TOC]
<br>
最近在整理JVM相关的PPT,把CMS算法又过了一遍,每次阅读源码都能多了解一点,继续坚持。
什么是CMS
CMS全称 ConcurrentMarkSweep,是一款并发的、使用标记-清除算法的垃圾回收器, 如果老年代使用CMS垃圾回收器,需要添加虚拟机参数-"XX:+UseConcMarkSweepGC"。
使用场景:
GC过程短暂停,适合对时延要求较高的服务,用户线程不允许长时间的停顿。
缺点:
服务长时间运行,造成严重的内存碎片化。 另外,算法实现比较复杂(如果也算缺点的话)
实现机制
根据GC的触发机制分为:周期性Old GC(被动)和主动Old GC,纯属个人理解,实在不知道怎么分才好。
周期性Old GC
周期性Old GC,执行的逻辑也叫 BackgroundCollect,对老年代进行回收,在GC日志中比较常见,由后台线程ConcurrentMarkSweepThread循环判断(默认2s)是否需要触发。
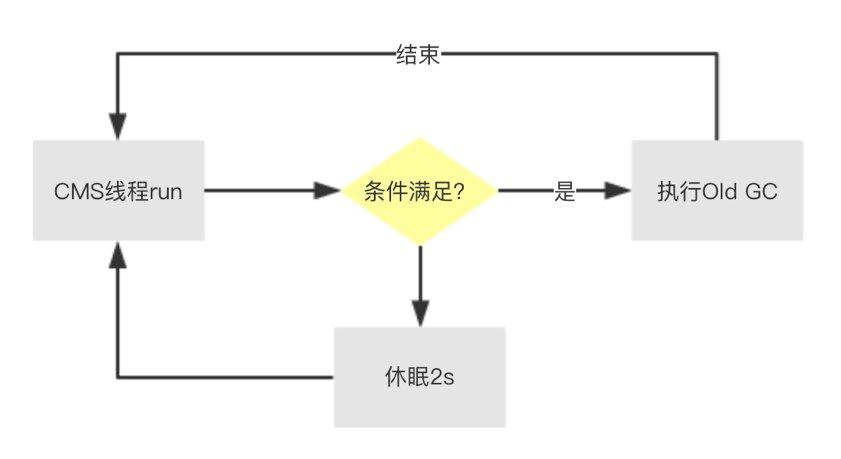
触发条件
1. 如果没有设置 UseCMSInitiatingOccupancyOnly,虚拟机会根据收集的数据决定是否触发(线上环境建议带上这个参数,不然会加大问题排查的难度)
2. 老年代使用率达到阈值 CMSInitiatingOccupancyFraction,默认92%
3. 永久代的使用率达到阈值 CMSInitiatingPermOccupancyFraction,默认92%,前提是开启 CMSClassUnloadingEnabled
4. 新生代的晋升担保失败
晋升担保失败
老年代是否有足够的空间来容纳全部的新生代对象或历史平均晋升到老年代的对象,如果不够的话,就提早进行一次老年代的回收,防止下次进行YGC的时候发生晋升失败。
周期性Old GC过程
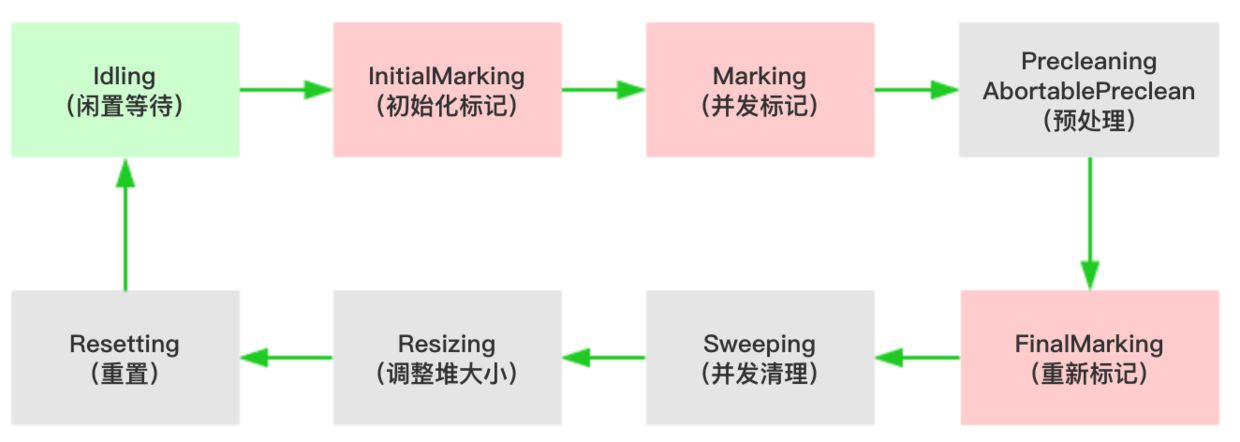
当条件满足时,采用“标记-清理”算法对老年代进行回收,过程可以说很简单,标记出存活对象,清理掉垃圾对象,但是为了实现整个过程的低延迟,实际算法远远没这么简单,整个过程分为如下几个部分:
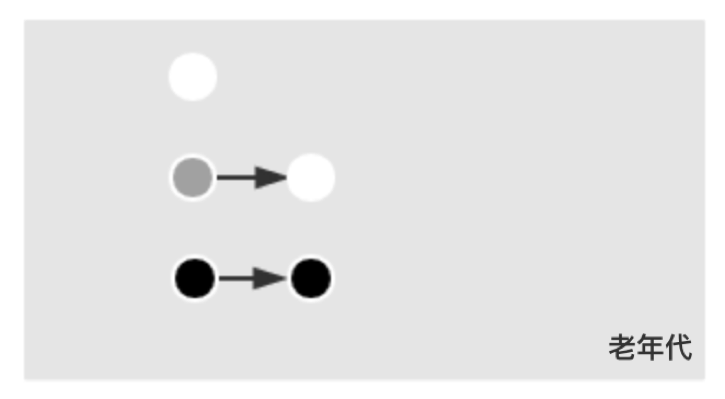
对象在标记过程中,根据标记情况,分成三类:
1. 白色对象,表示自身未被标记;
2. 灰色对象,表示自身被标记,但内部引用未被处理;
3. 黑色对象,表示自身被标记,内部引用都被处理;
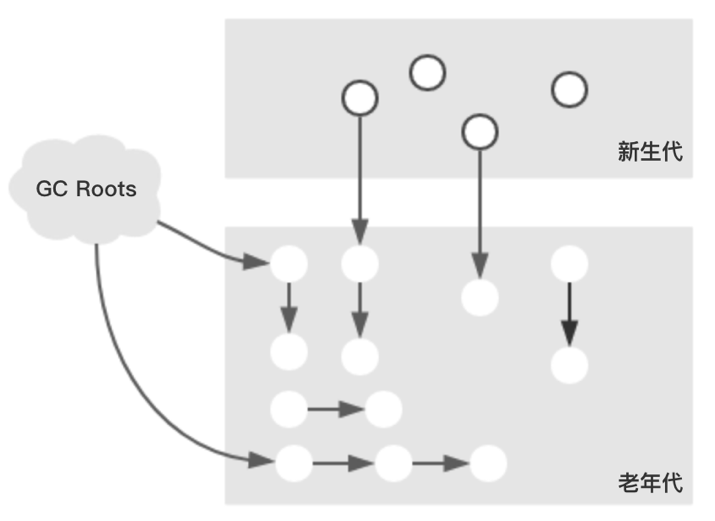
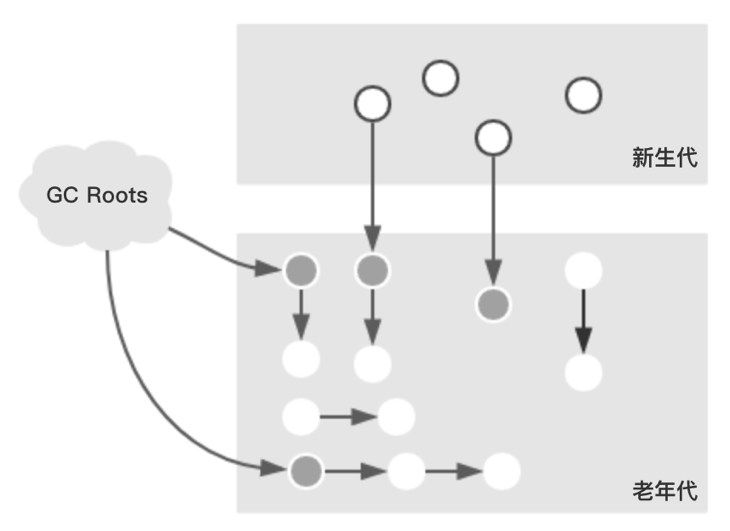
假设发生Background Collect时,Java堆的对象分布如下:
1、InitialMarking(初始化标记,整个过程STW)
该阶段单线程执行,主要分分为两步:
1. 标记GC Roots可达的老年代对象;
2. 遍历新生代对象,标记可达的老年代对象;
该过程结束后,对象分布如下:
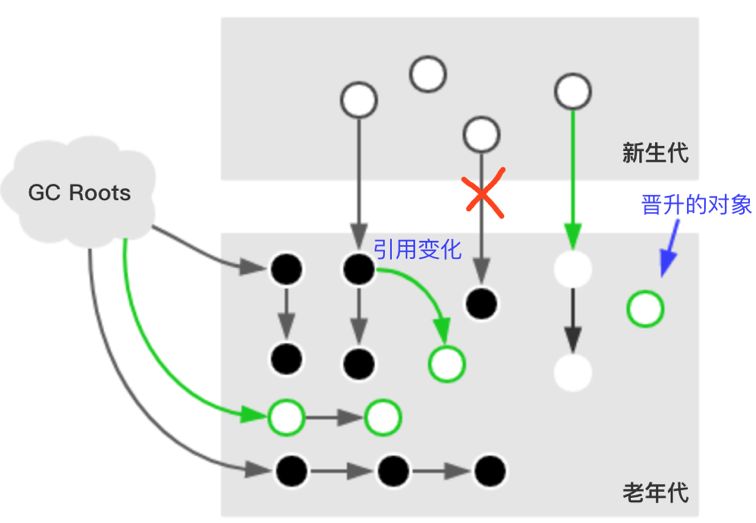
2、Marking(并发标记)
该阶段GC线程和应用线程并发执行,遍历InitialMarking阶段标记出来的存活对象,然后继续递归标记这些对象可达的对象。
因为该阶段并发执行的,在运行期间可能发生新生代的对象晋升到老年代、或者是直接在老年代分配对象、或者更新老年代对象的引用关系等等,对于这些对象,都是需要进行重新标记的,否则有些对象就会被遗漏,发生漏标的情况。
为了提高重新标记的效率,该阶段会把上述对象所在的Card标识为Dirty,后续只需扫描这些Dirty Card的对象,避免扫描整个老年代。
3、Precleaning(预清理)
通过参数 CMSPrecleaningEnabled选择关闭该阶段,默认启用,主要做两件事情:
1. 处理新生代已经发现的引用,比如在并发阶段,在Eden区中分配了一个A对象,A对象引用了一个老年代对象B(这个B之前没有被标记),在这个阶段就会标记对象B为活跃对象。
2. 在并发标记阶段,如果老年代中有对象内部引用发生变化,会把所在的Card标记为Dirty(其实这里并非使用CardTable,而是一个类似的数据结构,叫ModUnionTalble),通过扫描这些Table,重新标记那些在并发标记阶段引用被更新的对象(晋升到老年代的对象、原本就在老年代的对象)
4、AbortablePreclean(可中断的预清理)
该阶段发生的前提是,新生代Eden区的内存使用量大于参数CMSScheduleRemarkEdenSizeThreshold默认是2M,如果新生代的对象太少,就没有必要执行该阶段,直接执行重新标记阶段。
为什么需要这个阶段,存在的价值是什么?
因为CMS GC的终极目标是降低垃圾回收时的暂停时间,所以在该阶段要尽最大的努力去处理那些在并发阶段被应用线程更新的老年代对象,这样在暂停的重新标记阶段就可以少处理一些,暂停时间也会相应的降低。
在该阶段,主要循环的做两件事:
1. 处理 From 和 To 区的对象,标记可达的老年代对象
2. 和上一个阶段一样,扫描处理Dirty Card中的对象
当然了,这个逻辑不会一直循环下去,打断这个循环的条件有三个:
1. 可以设置最多循环的次数 CMSMaxAbortablePrecleanLoops,默认是0,表示没有循环次数的限制。
2. 如果执行这个逻辑的时间达到了阈值 CMSMaxAbortablePrecleanTime,默认是5s,会退出循环。
3. 如果新生代Eden区的内存使用率达到了阈值 CMSScheduleRemarkEdenPenetration,默认50%,会退出循环。(这个条件能够成立的前提是,在进行Precleaning时,Eden区的使用率小于十分之一)
如果在循环退出之前,发生了一次YGC,对于后面的Remark阶段来说,大大减轻了扫描年轻代的负担,但是发生YGC并非人为控制,所以只能祈祷这5s内可以来一次YGC。
1. ...
2. 1678.150:\[CMS-concurrent-preclean-start\]
3. 1678.186:\[CMS-concurrent-preclean:0.044/0.055secs\]
4. 1678.186:\[CMS-concurrent-abortable-preclean-start\]
5. 1678.365:\[GC 1678.465:\[ParNew:2080530K->1464K(2044544K),0.0127340secs\]
6. 1389293K->306572K(2093120K),
7. 0.0167509secs\]
8. 1680.093:\[CMS-concurrent-abortable-preclean:1.052/1.907secs\]
9. ....
在上面GC日志中,1678.186启动了AbortablePreclean阶段,在随后不到2s就发生了一次YGC。
5、FinalMarking(并发重新标记,STW过程)
该阶段并发执行,在之前的并行阶段(GC线程和应用线程同时执行,好比你妈在打扫房间,你还在扔纸屑),可能产生新的引用关系如下:
1. 老年代的新对象被GC Roots引用
2. 老年代的未标记对象被新生代对象引用
3. 老年代已标记的对象增加新引用指向老年代其它对象
4. 新生代对象指向老年代引用被删除
5. 也许还有其它情况..
上述对象中可能有一些已经在Precleaning阶段和AbortablePreclean阶段被处理过,但总存在没来得及处理的,所以还有进行如下的处理:
1. 遍历新生代对象,重新标记
2. 根据GC Roots,重新标记
3. 遍历老年代的Dirty Card,重新标记,这里的Dirty Card大部分已经在clean阶段处理过
在第一步骤中,需要遍历新生代的全部对象,如果新生代的使用率很高,需要遍历处理的对象也很多,这对于这个阶段的总耗时来说,是个灾难(因为可能大量的对象是暂时存活的,而且这些对象也可能引用大量的老年代对象,造成很多应该回收的老年代对象而没有被回收,遍历递归的次数也增加不少),如果在AbortablePreclean阶段中能够恰好的发生一次YGC,这样就可以避免扫描无效的对象。
如果在AbortablePreclean阶段没来得及执行一次YGC,怎么办?
CMS算法中提供了一个参数: CMSScavengeBeforeRemark,默认并没有开启,如果开启该参数,在执行该阶段之前,会强制触发一次YGC,可以减少新生代对象的遍历时间,回收的也更彻底一点。
不过,这种参数有利有弊,利是降低了Remark阶段的停顿时间,弊的是在新生代对象很少的情况下也多了一次YGC,最可怜的是在AbortablePreclean阶段已经发生了一次YGC,然后在该阶段又傻傻的触发一次。
所以利弊需要把握。
主动Old GC
这个主动Old GC的过程,触发条件比较苛刻:
1. YGC过程发生Promotion Failed,进而对老年代进行回收
2. System.gc(),前提是添加了-XX:+ExplicitGCInvokesConcurrent参数
如果触发了主动Old GC,这时周期性Old GC正在执行,那么会夺过周期性Old GC的执行权(同一个时刻只能有一种在Old GC在运行),并记录 concurrent mode failure 或者 concurrent mode interrupted。
主动GC开始时,需要判断本次GC是否要对老年代的空间进行Compact(因为长时间的周期性GC会造成大量的碎片空间),判断逻辑实现如下:
1. \*should\_compact =
2. UseCMSCompactAtFullCollection&&
3. ((\_full\_gcs\_since\_conc\_gc >=CMSFullGCsBeforeCompaction)||
4. GCCause::is\_user\_requested\_gc(gch->gc\_cause())||
5. gch->incremental\_collection\_will\_fail(true/\* consult\_young \*/));
在三种情况下会进行压缩:
1. 其中参数 UseCMSCompactAtFullCollection(默认true)和CMSFullGCsBeforeCompaction(默认0),所以默认每次的主动GC都会对老年代的内存空间进行压缩,就是把对象移动到内存的最左边。
2. 当然了,比如执行了 System.gc(),也会进行压缩。
3. 如果新生代的晋升担保会失败。
带压缩动作的算法,称为MSC,标记-清理-压缩,采用单线程,全暂停的方式进行垃圾收集,暂停时间很长很长...
那不带压缩动作的算法是什么样的呢?
不带压缩动作的执行逻辑叫 ForegroundCollect,整个过程相对周期性Old GC来说,少了Precleaning和AbortablePreclean两个阶段,其它过程都差不多。
--转至:http://www.cnblogs.com/aspirant/p/8663911.html
- 一.JVM
- 1.1 java代码是怎么运行的
- 1.2 JVM的内存区域
- 1.3 JVM运行时内存
- 1.4 JVM内存分配策略
- 1.5 JVM类加载机制与对象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面试相关文章
- 2.1 可能是把Java内存区域讲得最清楚的一篇文章
- 2.0 GC调优参数
- 2.1GC排查系列
- 2.2 内存泄漏和内存溢出
- 2.2.3 深入理解JVM-hotspot虚拟机对象探秘
- 1.10 并发的可达性分析相关问题
- 二.Java集合架构
- 1.ArrayList深入源码分析
- 2.Vector深入源码分析
- 3.LinkedList深入源码分析
- 4.HashMap深入源码分析
- 5.ConcurrentHashMap深入源码分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的设计模式
- 8.集合架构之面试指南
- 9.TreeSet和TreeMap
- 三.Java基础
- 1.基础概念
- 1.1 Java程序初始化的顺序是怎么样的
- 1.2 Java和C++的区别
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字节与字符的区别以及访问修饰符
- 1.7 深拷贝与浅拷贝
- 1.8 字符串常量池
- 2.面向对象
- 3.关键字
- 4.基本数据类型与运算
- 5.字符串与数组
- 6.异常处理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 数据流(Stream)
- 8.3 Java 8 并发教程:线程和执行器
- 8.4 Java 8 并发教程:同步和锁
- 8.5 Java 8 并发教程:原子变量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、数值、算术和文件
- 8.7 在 Java 8 中避免 Null 检查
- 8.8 使用 Intellij IDEA 解决 Java 8 的数据流问题
- 四.Java 并发编程
- 1.线程的实现/创建
- 2.线程生命周期/状态转换
- 3.线程池
- 4.线程中的协作、中断
- 5.Java锁
- 5.1 乐观锁、悲观锁和自旋锁
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平锁和非公平锁
- 5.3.1 说说ReentrantLock的实现原理,以及ReentrantLock的核心源码是如何实现的?
- 5.5 锁优化和升级
- 6.多线程的上下文切换
- 7.死锁的产生和解决
- 8.J.U.C(java.util.concurrent)
- 0.简化版(快速复习用)
- 9.锁优化
- 10.Java 内存模型(JMM)
- 11.ThreadLocal详解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的实现原理
- 1.DelayQueue的实现原理
- 14.Thread.join()实现原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的实际使用场景
- 五.Java I/O NIO
- 1.I/O模型简述
- 2.Java NIO之缓冲区
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之选择器
- 6.基于 Java NIO 实现简单的 HTTP 服务器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面试题
- 六.Java设计模式
- 1.单例模式
- 2.策略模式
- 3.模板方法
- 4.适配器模式
- 5.简单工厂
- 6.门面模式
- 7.代理模式
- 七.数据结构和算法
- 1.什么是红黑树
- 2.二叉树
- 2.1 二叉树的前序、中序、后序遍历
- 3.排序算法汇总
- 4.java实现链表及链表的重用操作
- 4.1算法题-链表反转
- 5.图的概述
- 6.常见的几道字符串算法题
- 7.几道常见的链表算法题
- 8.leetcode常见算法题1
- 9.LRU缓存策略
- 10.二进制及位运算
- 10.1.二进制和十进制转换
- 10.2.位运算
- 11.常见链表算法题
- 12.算法好文推荐
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事务管理
- 4.SpringMVC 运行流程和手动实现
- 0.Spring 核心技术
- 5.spring如何解决循环依赖问题
- 6.springboot自动装配原理
- 7.Spring中的循环依赖解决机制中,为什么要三级缓存,用二级缓存不够吗
- 8.beanFactory和factoryBean有什么区别
- 九.数据库
- 1.mybatis
- 1.1 MyBatis-# 与 $ 区别以及 sql 预编译
- Mybatis系列1-Configuration
- Mybatis系列2-SQL执行过程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-参数设置揭秘(ParameterHandler)
- Mybatis系列8-缓存机制
- 2.浅谈聚簇索引和非聚簇索引的区别
- 3.mysql 证明为什么用limit时,offset很大会影响性能
- 4.MySQL中的索引
- 5.数据库索引2
- 6.面试题收集
- 7.MySQL行锁、表锁、间隙锁详解
- 8.数据库MVCC详解
- 9.一条SQL查询语句是如何执行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能优化神器 Explain 使用分析
- 12.mysql中,一条update语句执行的过程是怎么样的?期间用到了mysql的哪些log,分别有什么作用
- 十.Redis
- 0.快速复习回顾Redis
- 1.通俗易懂的Redis数据结构基础教程
- 2.分布式锁(一)
- 3.分布式锁(二)
- 4.延时队列
- 5.位图Bitmaps
- 6.Bitmaps(位图)的使用
- 7.Scan
- 8.redis缓存雪崩、缓存击穿、缓存穿透
- 9.Redis为什么是单线程、及高并发快的3大原因详解
- 10.布隆过滤器你值得拥有的开发利器
- 11.Redis哨兵、复制、集群的设计原理与区别
- 12.redis的IO多路复用
- 13.相关redis面试题
- 14.redis集群
- 十一.中间件
- 1.RabbitMQ
- 1.1 RabbitMQ实战,hello world
- 1.2 RabbitMQ 实战,工作队列
- 1.3 RabbitMQ 实战, 发布订阅
- 1.4 RabbitMQ 实战,路由
- 1.5 RabbitMQ 实战,主题
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 实战 – 整合 RabbitMQ 发送邮件
- 1.8 RabbitMQ 的消息持久化与 Spring AMQP 的实现剖析
- 1.9 RabbitMQ必备核心知识
- 2.RocketMQ 的几个简单问题与答案
- 2.Kafka
- 2.1 kafka 基础概念和术语
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志机制
- 2.4 kafka是pull还是push的方式传递消息的?
- 2.5 Kafka的数据处理流程
- 2.6 Kafka的脑裂预防和处理机制
- 2.7 Kafka中partition副本的Leader选举机制
- 2.8 如果Leader挂了的时候,follower没来得及同步,是否会出现数据不一致
- 2.9 kafka的partition副本是否会出现脑裂情况
- 十二.Zookeeper
- 0.什么是Zookeeper(漫画)
- 1.使用docker安装Zookeeper伪集群
- 3.ZooKeeper-Plus
- 4.zk实现分布式锁
- 5.ZooKeeper之Watcher机制
- 6.Zookeeper之选举及数据一致性
- 十三.计算机网络
- 1.进制转换:二进制、八进制、十六进制、十进制之间的转换
- 2.位运算
- 3.计算机网络面试题汇总1
- 十四.Docker
- 100.面试题收集合集
- 1.美团面试常见问题总结
- 2.b站部分面试题
- 3.比心面试题
- 4.腾讯面试题
- 5.哈罗部分面试
- 6.笔记
- 十五.Storm
- 1.Storm和流处理简介
- 2.Storm 核心概念详解
- 3.Storm 单机版本环境搭建
- 4.Storm 集群环境搭建
- 5.Storm 编程模型详解
- 6.Storm 项目三种打包方式对比分析
- 7.Storm 集成 Redis 详解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初识ElasticSearch
- 2.文档基本CRUD、集群健康检查
- 3.shard&replica
- 4.document核心元数据解析及ES的并发控制
- 5.document的批量操作及数据路由原理
- 6.倒排索引
- 十七.分布式相关
- 1.分布式事务解决方案一网打尽
- 2.关于xxx怎么保证高可用的问题
- 3.一致性hash原理与实现
- 4.微服务注册中心 Nacos 比 Eureka的优势
- 5.Raft 协议算法
- 6.为什么微服务架构中需要网关
- 0.CAP与BASE理论
- 十八.Dubbo
- 1.快速掌握Dubbo常规应用
- 2.Dubbo应用进阶
- 3.Dubbo调用模块详解
- 4.Dubbo调用模块源码分析
- 6.Dubbo协议模块