
[TOC]
我们这篇文章就来试着分析下 HashMap 的源码,由于 HashMap 底层涉及到太多方面,一篇文章总是不能面面俱到,所以我们可以带着面试官常问的几个问题去看源码:
1. 了解底层如何存储数据的
2. HashMap 的几个主要方法
3. HashMap 是如何确定元素存储位置的以及如何处理哈希冲突的
4. HashMap 扩容机制是怎样的
5. JDK 1.8 在扩容和解决哈希冲突上对 HashMap 源码做了哪些改动?有什么好处?
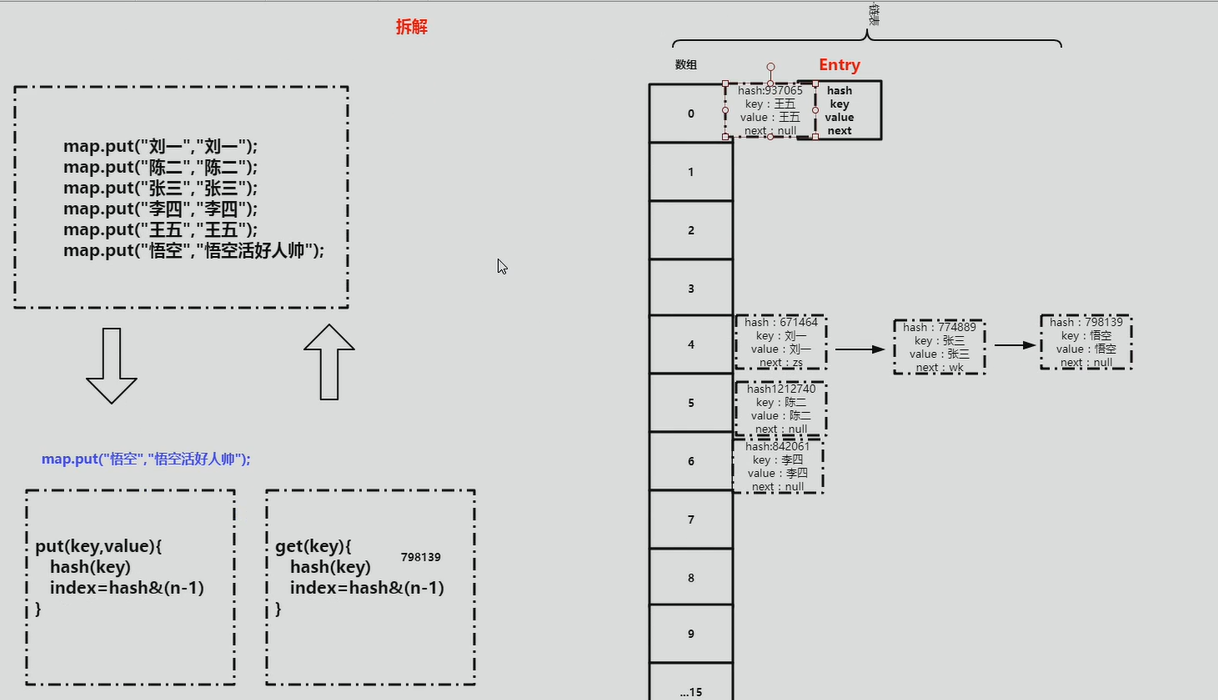
HashMap 的内部功能实现很多,本文主要从根据 key 获取哈希桶数组索引位置、put 方法的详细执行、扩容过程三个具有代表性的点深入展开讲解。
### 1. 存储结构
#### DK1.7 的存储结构
在 1.7 之前 JDK 采用「拉链法」来存储数据,即数组和链表结合的方式:
:-: 
「拉链法」用专业点的名词来说叫做**链地址法**。简单来说,就是数组加链表的结合。在每个数组元素上存储的都是一个链表。
我们之前说到不同的 key 可能经过 hash 运算可能会得到相同的地址,但是一个数组单位上只能存放一个元素,采用链地址法以后,如果遇到相同的 hash 值的 key 的时候,我们可以将它放到作为数组元素的链表上。待我们去取元素的时候通过 hash 运算的结果找到这个链表,再在链表中找到与 key 相同的节点,就能找到 key 相应的值了。
JDK1.7 中新添加进来的元素总是放在数组相应的角标位置,而原来处于该角标的位置的节点作为 next 节点放到新节点的后边。稍后通过源码分析我们也能看到这一点。
#### JDK1.8 的存储结构
对于 JDK1.8 之后的`HashMap`底层在解决哈希冲突的时候,就不单单是使用数组加上单链表的组合了,因为当处理如果 hash 值冲突较多的情况下,链表的长度就会越来越长,此时通过单链表来寻找对应 Key 对应的 Value 的时候就会使得时间复杂度达到 O(n),因此在 JDK1.8 之后,在链表新增节点导致链表长度超过`TREEIFY_THRESHOLD = 8`的时候,就会在添加元素的同时将原来的单链表转化为红黑树。
对数据结构很在行的读者应该,知道红黑树是一种易于增删改查的二叉树,他对与数据的查询的时间复杂度是`O(logn)`级别,所以利用红黑树的特点就可以更高效的对`HashMap`中的元素进行操作。
:-: 
从结构实现来讲,HashMap 是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下如所示。
1. 
**这里需要讲明白两个问题:数据底层具体存储的是什么?这样的存储方式有什么优点呢?**
(1)从源码可知,HashMap 类中有一个非常重要的字段,就是 Node\[\] table,即哈希桶数组,明显它是一个 Node 的数组。我们来看 Node( JDK1.8 中) 是何物。
~~~java
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
~~~
Node 是 HashMap 的一个内部类,实现了 Map.Entry 接口,本质是就是一个映射(键值对)。上图中的每个黑色圆点就是一个Node对象。
(2)HashMap 就是使用哈希表来存储的。哈希表为解决冲突,可以采用**开放地址法**和**链地址法**等来解决问题, Java 中 HashMap 采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被 Hash 后,得到数组下标,把数据放在对应下标元素的链表上。例如程序执行下面代码:
~~~java
map.put("美团","小美");
~~~
系统将调用 "美团" 这个 key 的 hashCode() 方法得到其 hashCode 值(该方法适用于每个 Java 对象),然后再通过 Hash 算法的后两步运算(高位运算和取模运算,下文有介绍)来定位该键值对的存储位置,有时两个 key 会定位到相同的位置,表示发生了 Hash 碰撞。当然 Hash 算法计算结果越分散均匀,Hash 碰撞的概率就越小,map 的存取效率就会越高。
如果哈希桶数组很大,即使较差的 Hash 算法也会比较分散,如果哈希桶数组数组很小,即使好的 Hash 算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的 hash 算法减少 Hash 碰撞。
**那么通过什么方式来控制 map 使得 Hash 碰撞的概率又小,哈希桶数组(Node\[\] table)占用空间又少呢?**
答案就是好的 Hash 算法和扩容机制。
在理解 Hash 和扩容流程之前,我们得先了解下 HashMap 的几个字段。从 HashMap 的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化,源码如下:
~~~java
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;
~~~
首先,**Node\[\] table的初始化长度 length (默认值是16)**,**Load factor 为负载因子(默认值是0.75)**,threshold 是 HashMap 所能容纳的最大数据量的 Node (键值对)个数。**threshold = length \* Load factor**。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
结合负载因子的定义公式可知,threshold 就是在此 Load factor 和 length (数组长度)对应下允许的最大元素数目,超过这个数目就重新 resize(扩容),扩容后的 HashMap 容量是之前容量的两倍。默认的负载因子 0.75 是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子 Load factor 的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子 loadFactor 的值,这个值可以大于1。
size 这个字段其实很好理解,就是 HashMap 中实际存在的键值对数量。注意和 table 的长度 length、容纳最大键值对数量 threshold 的区别。而 modCount 字段主要用来记录 HashMap 内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化指的是结构发生变化,例如 put 新键值对,但是某个 key 对应的 value 值被覆盖不属于结构变化。
在 HashMap 中,哈希桶数组 table 的长度 length 大小必须为 2n(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数,具体证明可以参考[为什么一般hashtable的桶数会取一个素数?](https://blog.csdn.net/liuqiyao_01/article/details/14475159),**Hashtable 初始化桶大小为 11,就是桶大小设计为素数的应用(Hashtable 扩容后不能保证还是素数)**。HashMap 采用这种非常规设计,**主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap 定位哈希桶索引位置时,也加入了高位参与运算的过程**。
这里存在一个问题,即使负载因子和 Hash 算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响 HashMap 的性能。于是,在 JDK1.8 版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高 HashMap 的性能,其中会用到红黑树的插入、删除、查找等算法。本文不再对红黑树展开讨论,想了解更多红黑树数据结构的工作原理可以参考:[教你初步了解红黑树](https://blog.csdn.net/v_july_v/article/details/6105630)。
### 2\. 重要参数
| 参数 | 说明 |
| --- | --- |
| buckets | 在 HashMap 的注释里使用哈希桶来形象的表示数组中每个地址位置。注意这里并不是数组本身,数组是装哈希桶的,他可以被称为**哈希表**。 |
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。 |
| size | table 的实际使用量。 |
| threshold | size 的临界值,size 必须小于 threshold,如果大于等于,就必须进行扩容操作。 |
| loadFactor | 装载因子,table 能够使用的比例,threshold = capacity \* loadFactor。 |
| TREEIFY\_THRESHOLD | 树化阀值,哈希桶中的节点个数大于该值(默认为8)的时候将会被转为红黑树行存储结构。 |
| UNTREEIFY\_THRESHOLD | 非树化阀值,小于该值(默认为 6)的时候将再次改为单链表的格式存储 |
### 3\. 确定哈希桶数组索引位置
很多操作都需要先确定一个键值对所在的桶下标。
~~~java
int hash = hash(key);
int i = indexFor(hash, table.length);
~~~
(一)计算 hash 值
~~~java
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
//此处通过一定的固定值的算法 得出相对分散的hash值 目的是为了减少碰撞
//JDK.1.8之后优化了这里的算法
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
~~~
(二)取模
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
~~~
x : 00010000
x-1 : 00001111
~~~
令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
~~~
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010
~~~
这个性质和 y 对 x 取模效果是一样的:
~~~
y : 10110010
x : 00010000
y%x : 00000010
~~~
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
~~~java
static int indexFor(int h, int length) {
return h & (length-1);
}
~~~
### 4\. 分析HashMap的put方法
HashMap 的 put 方法执行过程可以通过下图来理解,自己有兴趣可以去对比源码更清楚地研究学习。
1. 
①.判断键值对数组 table\[i\] 是否为空或为 null,否则执行 resize() 进行扩容;
②.根据键值 key 计算 hash 值得到插入的数组索引i,如果 table\[i\]==null,直接新建节点添加,转向 ⑥,如果table\[i\] 不为空,转向 ③;
③.判断 table\[i\] 的首个元素是否和 key 一样,如果相同直接覆盖 value,否则转向 ④,这里的相同指的是 hashCode 以及 equals;
④.判断table\[i\] 是否为 treeNode,即 table\[i\] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向 ⑤;
⑤.遍历 table\[i\],判断链表长度是否大于 8,大于 8 的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现 key 已经存在直接覆盖 value 即可;
⑥.插入成功后,判断实际存在的键值对数量 size 是否超多了最大容量 threshold,如果超过,进行扩容。
JDK1.8 HashMap 的 put 方法源码如下:
~~~java
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤①:tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 步骤③:节点key存在,直接覆盖value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 步骤④:判断该链为红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 步骤⑤:该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key,value,null);
//链表长度大于8转换为红黑树进行处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 步骤⑥:超过最大容量 就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
~~~
### 5\. 扩容机制
扩容 (resize) 就是重新计算容量,向 HashMap 对象里不停的添加元素,而 HashMap 对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然 Java 里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
我们分析下 resize 的源码,鉴于 JDK1.8 融入了红黑树,较复杂,为了便于理解我们仍然使用 JDK1.7 的代码,好理解一些,本质上区别不大,具体区别后文再说。
~~~java
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int)(newCapacity * loadFactor);//修改阈值
}
~~~
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer() 方法将原有 Entry 数组的元素拷贝到新的 Entry 数组里。
~~~java
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}
~~~
newTable\[i\] 的引用赋给了 e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到 Entry 链的尾部(如果发生了 hash 冲突的话),这一点和 Jdk1.8 有区别,下文详解。在旧数组中同一条 Entry 链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
下面举个例子说明下扩容过程。假设了我们的 hash 算法就是简单的用 key mod 一下表的大小(也就是数组的长度)。其中的哈希桶数组 table 的 size=2, 所以 key = 3、7、5,put 顺序依次为 5、7、3。在 mod 2 以后都冲突在 table\[1\] 这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小 size 大于 table 的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize 成 4,然后所有的 Node 重新 rehash 的过程。
:-: 
下面我们讲解下 JDK1.8 做了哪些优化。经过观测可以发现,我们使用的是 2 次幂的扩展 (指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。看下图可以明白这句话的意思,n 为 table 的长度,图(a)表示扩容前的 key1 和 key2 两种 key 确定索引位置的示例,图(b)表示扩容后 key1 和 key2 两种 key 确定索引位置的示例,其中 hash1 是 key1 对应的哈希与高位运算结果。
:-: 
元素在重新计算 hash 之后,因为 n 变为 2 倍,那么 n-1 的 mask 范围在高位多 1bit (红色),因此新的 index 就会发生这样的变化:
:-: 
因此,我们在扩充 HashMap 的时候,不需要像 JDK1.7 的实现那样重新计算 hash,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话索引变成“原索引+oldCap”,可以看看下图为 16 扩充为 32 的 resize 示意图:
:-: 
这个设计确实非常的巧妙,既省去了重新计算 hash 值的时间,而且同时,由于新增的 1bit 是 0 还是 1 可以认为是随机的,因此 resize 的过程,均匀的把之前的冲突的节点分散到新的 bucket 了。这一块就是 JDK1.8 新增的优化点。有一点注意区别,JDK1.7 中 rehash 的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8 不会倒置。有兴趣的同学可以研究下 JDK1.8 的 resize源 码,写的很赞,如下:
~~~java
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
~~~
### 6\. 线程安全性
在多线程使用场景中,应该尽量避免使用线程不安全的 HashMap,而使用线程安全的 ConcurrentHashMap。那么为什么说 HashMap 是线程不安全的,下面举例子说明在并发的多线程使用场景中使用 HashMap 可能造成死循环。代码例子如下(便于理解,仍然使用 JDK1.7 的环境):
~~~java
public class HashMapInfiniteLoop {
private static HashMap<Integer,String> map = new HashMap<Integer,String>(2,0.75f);
public static void main(String[] args) {
map.put(5, "C");
new Thread("Thread1") {
public void run() {
map.put(7, "B");
System.out.println(map);
};
}.start();
new Thread("Thread2") {
public void run() {
map.put(3, "A);
System.out.println(map);
};
}.start();
}
}
~~~
其中,map初始化为一个长度为2的数组,loadFactor=0.75,threshold=2\*0.75=1,也就是说当put第二个key的时候,map就需要进行resize。
通过设置断点让线程1和线程2同时debug到transfer方法(3.3小节代码块)的首行。注意此时两个线程已经成功添加数据。放开thread1的断点至transfer方法的“Entry next = e.next;” 这一行;然后放开线程2的的断点,让线程2进行resize。结果如下图。
:-: 
注意,Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。
线程一被调度回来执行,先是执行 newTalbe\[i\] = e, 然后是e = next,导致了e指向了key(7),而下一次循环的next = e.next导致了next指向了key(3)。
:-: 
:-: 
e.next = newTable\[i\] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
:-: 
于是,当我们用线程一调用map.get(11)时,悲剧就出现了——Infinite Loop。
### 7\. JDK1.8与JDK1.7的性能对比
HashMap中,如果key经过hash算法得出的数组索引位置全部不相同,即Hash算法非常好,那样的话,getKey方法的时间复杂度就是O(1),如果Hash算法技术的结果碰撞非常多,假如Hash算极其差,所有的Hash算法结果得出的索引位置一样,那样所有的键值对都集中到一个桶中,或者在一个链表中,或者在一个红黑树中,时间复杂度分别为O(n)和O(lgn)。 鉴于JDK1.8做了多方面的优化,总体性能优于JDK1.7,下面我们从两个方面用例子证明这一点。
### 8\. Hash较均匀的情况
为了便于测试,我们先写一个类Key,如下:
~~~java
class Key implements Comparable<Key> {
private final int value;
Key(int value) {
this.value = value;
}
@Override
public int compareTo(Key o) {
return Integer.compare(this.value, o.value);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
Key key = (Key) o;
return value == key.value;
}
@Override
public int hashCode() {
return value;
}
}
~~~
这个类复写了equals方法,并且提供了相当好的hashCode函数,任何一个值的hashCode都不会相同,因为直接使用value当做hashcode。为了避免频繁的GC,我将不变的Key实例缓存了起来,而不是一遍一遍的创建它们。代码如下:
~~~java
public class Keys {
public static final int MAX_KEY = 10_000_000;
private static final Key[] KEYS_CACHE = new Key[MAX_KEY];
static {
for (int i = 0; i < MAX_KEY; ++i) {
KEYS_CACHE[i] = new Key(i);
}
}
public static Key of(int value) {
return KEYS_CACHE[value];
}
}
~~~
现在开始我们的试验,测试需要做的仅仅是,创建不同size的HashMap(1、10、100、......10000000),屏蔽了扩容的情况,代码如下:
~~~java
static void test(int mapSize) {
HashMap<Key, Integer> map = new HashMap<Key,Integer>(mapSize);
for (int i = 0; i < mapSize; ++i) {
map.put(Keys.of(i), i);
}
long beginTime = System.nanoTime(); //获取纳秒
for (int i = 0; i < mapSize; i++) {
map.get(Keys.of(i));
}
long endTime = System.nanoTime();
System.out.println(endTime - beginTime);
}
public static void main(String[] args) {
for(int i=10;i<= 1000 0000;i*= 10){
test(i);
}
}
~~~
在测试中会查找不同的值,然后度量花费的时间,为了计算getKey的平均时间,我们遍历所有的get方法,计算总的时间,除以key的数量,计算一个平均值,主要用来比较,绝对值可能会受很多环境因素的影响。结果如下:
:-: 
通过观测测试结果可知,JDK1.8的性能要高于JDK1.7 15%以上,在某些size的区域上,甚至高于100%。由于Hash算法较均匀,JDK1.8引入的红黑树效果不明显,下面我们看看Hash不均匀的的情况。
### 9\. Hash极不均匀的情况
假设我们又一个非常差的Key,它们所有的实例都返回相同的hashCode值。这是使用HashMap最坏的情况。代码修改如下:
~~~java
class Key implements Comparable<Key> {
//...
@Override
public int hashCode() {
return 1;
}
}
~~~
仍然执行main方法,得出的结果如下表所示:
:-: 
从表中结果中可知,随着size的变大,JDK1.7的花费时间是增长的趋势,而JDK1.8是明显的降低趋势,并且呈现对数增长稳定。当一个链表太长的时候,HashMap会动态的将它替换成一个红黑树,这话的话会将时间复杂度从O(n)降为O(logn)。hash算法均匀和不均匀所花费的时间明显也不相同,这两种情况的相对比较,可以说明一个好的hash算法的重要性。
测试环境:处理器为2.2 GHz Intel Core i7,内存为16 GB 1600 MHz DDR3,SSD硬盘,使用默认的JVM参数,运行在64位的OS X 10.10.1上。
### 10\. HashMap与HashTable
1. HashTable 使用 synchronized 来进行同步。
2. HashMap 可以插入键为 null 的 Entry。
3. HashMap 的迭代器是 fail-fast 迭代器。
4. HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
### 11\. 小结
1. 扩容是一个特别耗性能的操作,所以当程序员在使用 HashMap 的时候,估算 map 的大小,初始化的时候给一个大致的数值,避免 map 进行频繁的扩容。
2. 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
3. HashMap 是线程不安全的,不要在并发的环境中同时操作 HashMap,建议使用 ConcurrentHashMap。
4. JDK1.8 引入红黑树大程度优化了 HashMap 的性能。
参考资料:
* [Java 8系列之重新认识HashMap——美团技术](https://tech.meituan.com/java_hashmap.html)
* [搞懂 Java HashMap 源码 - 掘金](https://juejin.im/post/5ac83fa35188255c5668afd0)
* [搞懂 Java equals 和 hashCode 方法 - 掘金](https://juejin.im/post/5ac4d8abf265da23a4050ae3)
- 一.JVM
- 1.1 java代码是怎么运行的
- 1.2 JVM的内存区域
- 1.3 JVM运行时内存
- 1.4 JVM内存分配策略
- 1.5 JVM类加载机制与对象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面试相关文章
- 2.1 可能是把Java内存区域讲得最清楚的一篇文章
- 2.0 GC调优参数
- 2.1GC排查系列
- 2.2 内存泄漏和内存溢出
- 2.2.3 深入理解JVM-hotspot虚拟机对象探秘
- 1.10 并发的可达性分析相关问题
- 二.Java集合架构
- 1.ArrayList深入源码分析
- 2.Vector深入源码分析
- 3.LinkedList深入源码分析
- 4.HashMap深入源码分析
- 5.ConcurrentHashMap深入源码分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的设计模式
- 8.集合架构之面试指南
- 9.TreeSet和TreeMap
- 三.Java基础
- 1.基础概念
- 1.1 Java程序初始化的顺序是怎么样的
- 1.2 Java和C++的区别
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字节与字符的区别以及访问修饰符
- 1.7 深拷贝与浅拷贝
- 1.8 字符串常量池
- 2.面向对象
- 3.关键字
- 4.基本数据类型与运算
- 5.字符串与数组
- 6.异常处理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 数据流(Stream)
- 8.3 Java 8 并发教程:线程和执行器
- 8.4 Java 8 并发教程:同步和锁
- 8.5 Java 8 并发教程:原子变量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、数值、算术和文件
- 8.7 在 Java 8 中避免 Null 检查
- 8.8 使用 Intellij IDEA 解决 Java 8 的数据流问题
- 四.Java 并发编程
- 1.线程的实现/创建
- 2.线程生命周期/状态转换
- 3.线程池
- 4.线程中的协作、中断
- 5.Java锁
- 5.1 乐观锁、悲观锁和自旋锁
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平锁和非公平锁
- 5.3.1 说说ReentrantLock的实现原理,以及ReentrantLock的核心源码是如何实现的?
- 5.5 锁优化和升级
- 6.多线程的上下文切换
- 7.死锁的产生和解决
- 8.J.U.C(java.util.concurrent)
- 0.简化版(快速复习用)
- 9.锁优化
- 10.Java 内存模型(JMM)
- 11.ThreadLocal详解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的实现原理
- 1.DelayQueue的实现原理
- 14.Thread.join()实现原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的实际使用场景
- 五.Java I/O NIO
- 1.I/O模型简述
- 2.Java NIO之缓冲区
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之选择器
- 6.基于 Java NIO 实现简单的 HTTP 服务器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面试题
- 六.Java设计模式
- 1.单例模式
- 2.策略模式
- 3.模板方法
- 4.适配器模式
- 5.简单工厂
- 6.门面模式
- 7.代理模式
- 七.数据结构和算法
- 1.什么是红黑树
- 2.二叉树
- 2.1 二叉树的前序、中序、后序遍历
- 3.排序算法汇总
- 4.java实现链表及链表的重用操作
- 4.1算法题-链表反转
- 5.图的概述
- 6.常见的几道字符串算法题
- 7.几道常见的链表算法题
- 8.leetcode常见算法题1
- 9.LRU缓存策略
- 10.二进制及位运算
- 10.1.二进制和十进制转换
- 10.2.位运算
- 11.常见链表算法题
- 12.算法好文推荐
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事务管理
- 4.SpringMVC 运行流程和手动实现
- 0.Spring 核心技术
- 5.spring如何解决循环依赖问题
- 6.springboot自动装配原理
- 7.Spring中的循环依赖解决机制中,为什么要三级缓存,用二级缓存不够吗
- 8.beanFactory和factoryBean有什么区别
- 九.数据库
- 1.mybatis
- 1.1 MyBatis-# 与 $ 区别以及 sql 预编译
- Mybatis系列1-Configuration
- Mybatis系列2-SQL执行过程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-参数设置揭秘(ParameterHandler)
- Mybatis系列8-缓存机制
- 2.浅谈聚簇索引和非聚簇索引的区别
- 3.mysql 证明为什么用limit时,offset很大会影响性能
- 4.MySQL中的索引
- 5.数据库索引2
- 6.面试题收集
- 7.MySQL行锁、表锁、间隙锁详解
- 8.数据库MVCC详解
- 9.一条SQL查询语句是如何执行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能优化神器 Explain 使用分析
- 12.mysql中,一条update语句执行的过程是怎么样的?期间用到了mysql的哪些log,分别有什么作用
- 十.Redis
- 0.快速复习回顾Redis
- 1.通俗易懂的Redis数据结构基础教程
- 2.分布式锁(一)
- 3.分布式锁(二)
- 4.延时队列
- 5.位图Bitmaps
- 6.Bitmaps(位图)的使用
- 7.Scan
- 8.redis缓存雪崩、缓存击穿、缓存穿透
- 9.Redis为什么是单线程、及高并发快的3大原因详解
- 10.布隆过滤器你值得拥有的开发利器
- 11.Redis哨兵、复制、集群的设计原理与区别
- 12.redis的IO多路复用
- 13.相关redis面试题
- 14.redis集群
- 十一.中间件
- 1.RabbitMQ
- 1.1 RabbitMQ实战,hello world
- 1.2 RabbitMQ 实战,工作队列
- 1.3 RabbitMQ 实战, 发布订阅
- 1.4 RabbitMQ 实战,路由
- 1.5 RabbitMQ 实战,主题
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 实战 – 整合 RabbitMQ 发送邮件
- 1.8 RabbitMQ 的消息持久化与 Spring AMQP 的实现剖析
- 1.9 RabbitMQ必备核心知识
- 2.RocketMQ 的几个简单问题与答案
- 2.Kafka
- 2.1 kafka 基础概念和术语
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志机制
- 2.4 kafka是pull还是push的方式传递消息的?
- 2.5 Kafka的数据处理流程
- 2.6 Kafka的脑裂预防和处理机制
- 2.7 Kafka中partition副本的Leader选举机制
- 2.8 如果Leader挂了的时候,follower没来得及同步,是否会出现数据不一致
- 2.9 kafka的partition副本是否会出现脑裂情况
- 十二.Zookeeper
- 0.什么是Zookeeper(漫画)
- 1.使用docker安装Zookeeper伪集群
- 3.ZooKeeper-Plus
- 4.zk实现分布式锁
- 5.ZooKeeper之Watcher机制
- 6.Zookeeper之选举及数据一致性
- 十三.计算机网络
- 1.进制转换:二进制、八进制、十六进制、十进制之间的转换
- 2.位运算
- 3.计算机网络面试题汇总1
- 十四.Docker
- 100.面试题收集合集
- 1.美团面试常见问题总结
- 2.b站部分面试题
- 3.比心面试题
- 4.腾讯面试题
- 5.哈罗部分面试
- 6.笔记
- 十五.Storm
- 1.Storm和流处理简介
- 2.Storm 核心概念详解
- 3.Storm 单机版本环境搭建
- 4.Storm 集群环境搭建
- 5.Storm 编程模型详解
- 6.Storm 项目三种打包方式对比分析
- 7.Storm 集成 Redis 详解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初识ElasticSearch
- 2.文档基本CRUD、集群健康检查
- 3.shard&replica
- 4.document核心元数据解析及ES的并发控制
- 5.document的批量操作及数据路由原理
- 6.倒排索引
- 十七.分布式相关
- 1.分布式事务解决方案一网打尽
- 2.关于xxx怎么保证高可用的问题
- 3.一致性hash原理与实现
- 4.微服务注册中心 Nacos 比 Eureka的优势
- 5.Raft 协议算法
- 6.为什么微服务架构中需要网关
- 0.CAP与BASE理论
- 十八.Dubbo
- 1.快速掌握Dubbo常规应用
- 2.Dubbo应用进阶
- 3.Dubbo调用模块详解
- 4.Dubbo调用模块源码分析
- 6.Dubbo协议模块