
[TOC]
## JVM GC机制
**JVM GC 算法讲解**
**1、根搜索算法**
根搜索算法是从离散数学中的图论引入的,程序把所有引用关系看作一张图,从一个节点GC ROOT 开始,寻找对应的引用节点,找到这个节点后,继续寻找这个节点的引用节点。当所有的引用节点寻找完毕后,剩余的节点则被认为是没有被引用到的节点,即无用的节点。
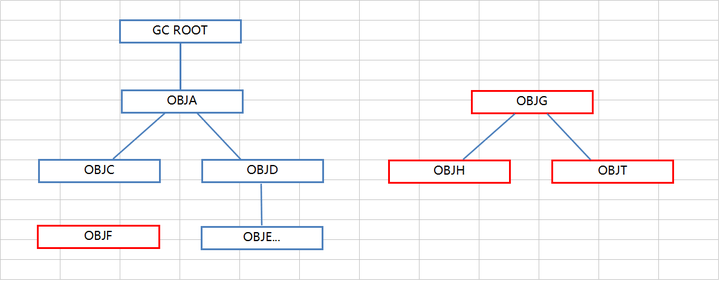
上图红色为无用的节点,可以被回收。
目前Java中可以作为GC ROOT的对象有:
1、虚拟机栈中引用的对象(本地变量表)
2、方法区中静态属性引用的对象
3、方法区中常亮引用的对象
4、本地方法栈中引用的对象(Native对象)
基本所有GC算法都引用根搜索算法这种概念。
**2、标记 - 清除算法**
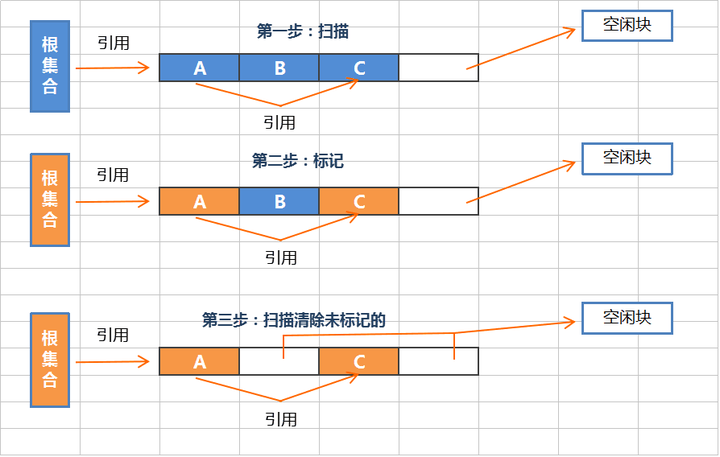
标记-清除算法采用从根集合进行扫描,**对存活的对象进行标记**,标记完毕后,再扫描整个空间中未被标记的对象进行直接回收,如上图。
标记-清除算法不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活的对象比较多的情况下极为高效,但由于标记-清除算法直接回收不存活的对象,并没有对还存活的对象进行整理,因此会导致内存碎片。
**3、复制算法**
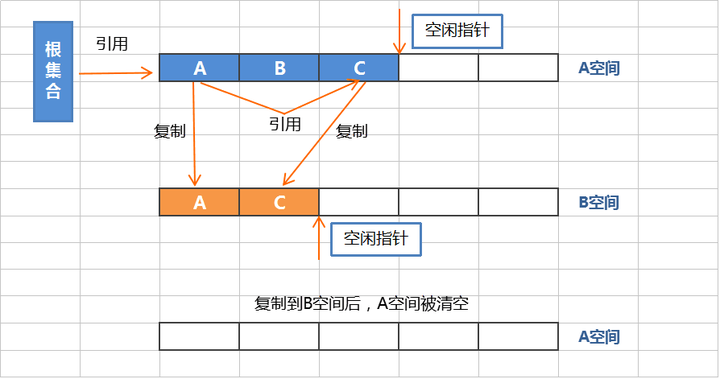
复制算法将内存划分为两个区间,使用此算法时,所有动态分配的对象都只能分配在其中一个区间(活动区间),而另外一个区间(空间区间)则是空闲的。
复制算法采用从根集合扫描,将存活的对象复制到空闲区间,当扫描完毕活动区间后,会的将活动区间一次性全部回收。**此时原本的空闲区间变成了活动区间**。下次GC时候又会重复刚才的操作,以此循环。
复制算法在存活对象比较少的时候,极为高效,但是带来的成本是牺牲一半的内存空间用于进行对象的移动。**所以复制算法的使用场景,必须是对象的存活率非常低才行**,而且最重要的是,我们需要克服50%内存的浪费。
**4、标记 - 整理算法**
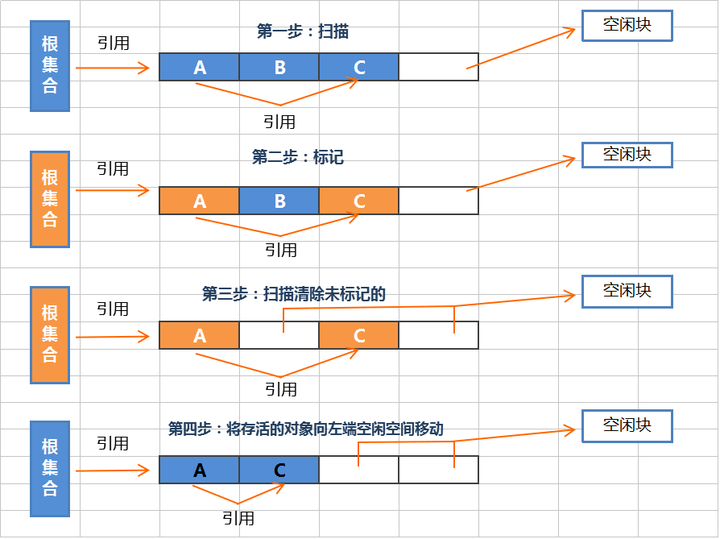
标记-整理算法采用 标记-清除 算法一样的方式进行对象的标记、清除,但在回收不存活的对象占用的空间后,会将所有存活的对象往左端空闲空间移动,并更新对应的指针。标记-整理 算法是在标记-清除 算法之上,又进行了对象的移动排序整理,因此成本更高,但却解决了内存碎片的问题。
JVM为了优化内存的回收,使用了分代回收的方式,对于新生代内存的回收(Minor GC)主要采用**复制算法**。而对于老年代的回收(Major GC),大多采用**标记-整理算法**。
## redis删除策略
可以设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略。
Redis 具体有 6 种淘汰策略:
| 策略 | 描述 |
| --- | --- |
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据 |
作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
使用 Redis 缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用 allkeys-lru 淘汰策略,将最近最少使用的数据淘汰。
## 限流令牌桶
令牌桶算法:
1,令牌按固定速率发放,生成的令牌放入令牌桶中。2,令牌桶有容量限制,当桶满时,新生成的令牌会被丢弃。
3,请求到来时,先从令牌桶中获取令牌,如果取得,则执行请求;如果令牌桶为空,则丢弃该请求。
令牌桶算法可以把请求平均分散在时间段内,是使用较为广发的限流算法。
## Java中的对象和引用
[https://www.zhihu.com/question/31203609/answer/50992895](https://www.zhihu.com/question/31203609/answer/50992895)
## kafka乱序解决
Kafka分布式的单位是partition,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。不同partition之间不能保证顺序。
但是绝大多数用户都可以通过message key来定义,因为同一个key的message可以保证只发送到同一个partition,比如说key是user id,table row id等等,所以同一个user或者同一个record的消息永远只会发送到同一个partition上,保证了同一个user或record的顺序。
[https://www.taosdata.com/blog/2019/10/08/922.html](https://www.taosdata.com/blog/2019/10/08/922.html)
[https://blog.csdn.net/u012386386/article/details/79033040](https://blog.csdn.net/u012386386/article/details/79033040)
## rabbitMq如何保证均匀分发
使用 basicQos 方法,并将传递参数为 prefetchCount = 1。
这样告诉 RabbitMQ 不要一次给一个工作线程多个消息。换句话说,在处理并确认前一个消息之前,不要向工作线程发送新消息。相反,它将发送到下一个还不忙的工作线程
## 阻塞队列实现原理
[https://zhuanlan.zhihu.com/p/56579882](https://zhuanlan.zhihu.com/p/56579882)
[https://my.oschina.net/u/3464538/blog/4491417](https://my.oschina.net/u/3464538/blog/4491417)更好的理解 出入都要加锁,所以是一把锁两个condition,用AtomicInteger 统计容量
可查看LinkedBlockingDeque类的代码
## 简述下IOC加载过程
### Ioc容器的加载过程简单概括:
1.刷新预处理
2.将配置信息解析,注册到BeanFactory
3.设置bean的类加载器
4.如果有第三方想再bean加载注册完成后,初始化前做点什么(例如修改属性的值,修改bean的scope为单例或者多例。),提供了相应的模板方法,后面还调用了这个方法的实现,并且把这些个实现类注册到对应的容器中
5.初始化当前的事件广播器
6.初始化所有的bean。(懒加载不执行这一步)
7.广播applicationcontext初始化完成。
### ps:BeanFactory 与 ApplicationContext区别
BeanFactory 看下去可以去做IOC当中的大部分事情,为什么还要去定义一个ApplicationContext 呢?
ApplicationContext 它由BeanFactory接口派生而来,因而提供了BeanFactory所有的功能。除此之外context包还提供了以下的功能:
1.MessageSource, 提供国际化的消息访问
2.资源访问,如URL和文件
3.事件传播,实现了ApplicationListener接口的bean
4.载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
##一条sql执行原理
## 执行alter修改表结构,如何实现不锁表?
概述
在 mysql 5.5 版本以前,修改表结构如添加索引、修改列,需要锁表,期间不能写入,对于大表这简直是灾难。从5.5特别是5.6里,情况有了好转,支持Online DDL,pt-online-schema-change是Percona-toolkit一员,通过改进原生ddl的方式,达到不锁表在线修改表结构。
1、pt-osc工作过程
1)创建一个和要执行 alter 操作的表一样的新的空表结构(是alter之前的结构)
2)在新表执行alter table 语句(速度应该很快)
3)在原表中创建触发器3个触发器分别对应insert,update,delete操作
4)以一定块大小从原表拷贝数据到临时表,拷贝过程中通过原表上的触发器在原表进行的写操作都会更新到新建的临时表
5)Rename 原表到old表中,在把临时表Rename为原表
6)如果有参考该表的外键,根据alter-foreign-keys-method参数的值,检测外键相关的表,做相应设置的处理
7)默认最后将旧原表删除
4、使用 pt-osc原生 5.6 online ddl相比,如何选择
online ddl在必须copy table时成本较高,不宜采用
pt-osc工具在存在触发器时,不适用
修改索引、外键、列名时,优先采用online ddl,并指定 ALGORITHM=INPLACE
其它情况使用pt-?>,l;kh-osc,虽然存在copy data
pt-osc比online ddl要慢一倍左右,因为它是根据负载调整的
无论哪种方式都选择的业务低峰期执行
特殊情况需要利用主从特性,先alter从库,主备切换,再改原主库
————————————————
## HashMap为什么线程不安全?
扩容的时候,因为获取数组桶下标时候 需要先1.获取hash,2hash桶数取模或者(hash&(n-1) n为同数量),多线程的情况下不同线程可能会有扩容需求,而桶数量可能是不同的,这样导致取到的数组桶下标不一样,破坏了原子性
## Thread.join的实现原理
https://www.cnblogs.com/barrywxx/p/10153776.html
1.join()方法是有`synchronized`修饰,**我们需要知道的是,调用wait方法必须要获取锁**,所以join方法是被synchronized修饰的
2.isAlive为true时说明没有执行完,需要调用Object中的wait方法实现线程的阻塞
3.唤醒是在JVM hotspot中调用notify
**总结**,Thread.join其实底层是通过wait/notifyall来实现线程的通信达到线程阻塞的目的;当线程执行结束以后,会触发两个事情,第一个是设置native线程对象为null、第二个是通过notifyall方法,让等待在previousThread对象锁上的wait方法被唤醒。
## redis的hash结构是怎么扩容和rehash的
当hash内部的元素比较拥挤时(hash碰撞比较频繁),就需要进行扩容。**扩容需要申请新的两倍大小的数组,然后将所有的键值对重新分配到新的数组下标对应的链表中(rehash)**。如果hash结构很大,比如有上百万个键值对,那么一次完整rehash的过程就会耗时很长。这对于单线程的Redis里来说有点压力山大。所以**Redis采用了渐进式rehash的方案。它会同时保留两个新旧hash结构,在后续的定时任务以及hash结构的读写指令中将旧结构的元素逐渐迁移到新的结构中。这样就可以避免因扩容导致的线程卡顿现象**。
## 分布式事务解决方案
## 无界队列和有界队列区别
## rabbitMq怎么保证高可用?
镜像集群模式:
这种模式才是高可用模式. 与普通集群模式的主要区别在于. 无论queue的元数据还是queue中的消息都会同时存在与多个实例上.
设计集群的目的:
1. 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
2. 通过增加更多的节点来扩展消息通信的吞吐量
要开启镜像集群模式,需要在后台新增镜像集群模式策略. 即要求数据同步到所有的节点.也可以指定同步到指定数量的节点.
这种方式的好处就在于, 任何一个服务宕机了,都不会影响整个集群数据的完整性, 因为其他服务中都有queue的完整数据, 当进行消息消费的时候,连接其他的服务器节点一样也能获取到数据.
缺点:
1: 性能开销大: 因为需要进行整个集群内部所有实例的数据同步
2:无法线性扩容: 因为每一个服务器中都包含整个集群服务节点中的所有数据, 这样如果一旦单个服务器节点的容量无法容纳了怎么办?.
## kafka中的CAP机制
CAP是不可能同时满足的,所以在Kafka中也是一样,也只能尽量满足。Kafka只实现了CA,Partition tolerance是通过一定的机制尽量尽量满足。
kafka首先将数据写入到不同的分区里面去,每个分区又可能有好多个副本,数据首先写入到leader分区里面去,读写的操作都是与leader分区进行通信,保证了数据的一致性原则,也就是满足了Consistency原则。然后kafka通过分区副本机制,来保证了kafka当中数据的可用性。但是也存在另外一个问题,就是副本分区当中的数据与leader当中的数据存在差别的问题如何解决,这个就是Partition tolerance的问题。
kafka为了解决Partition tolerance的问题,使用了ISR的同步策略,来尽最大可能减少
Partition tolerance的问题。在leader分区中会维护一个ISR(a set of in-sync replicas,基本同步)列表,ISR列表主要的作用就是决定哪些副本分区是可用的,也就是说可以将leader分区里面的数据同步到副本分区里面去,决定一个副本分区是否可用的条件有两个
• replica.lag.time.max.ms=10000 副本分区与主分区心跳时间延迟
• replica.lag.max.messages=4000 副本分区与主分区消息同步最大差
1
2
这里的意思就是说如果某个follower分区超过最大延迟时间还没和leader进行心跳感知或者和leader分区的消息同步差值超过4000条,ISR就认为这个分区不可用了,就会把该分区从ISR中移除。
## kafka文件存机制
https://blog.csdn.net/qq_41893274/article/details/112746898
## Spring 中拦截器(Interceptor)与过滤器(Filter)的区别
## mysql死锁形成原因和解决方案
## 熔断机制,熔断什么实现?
## 灰度如何实现。A/B testing、分流等设计方案了解吗?
- 一.JVM
- 1.1 java代码是怎么运行的
- 1.2 JVM的内存区域
- 1.3 JVM运行时内存
- 1.4 JVM内存分配策略
- 1.5 JVM类加载机制与对象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面试相关文章
- 2.1 可能是把Java内存区域讲得最清楚的一篇文章
- 2.0 GC调优参数
- 2.1GC排查系列
- 2.2 内存泄漏和内存溢出
- 2.2.3 深入理解JVM-hotspot虚拟机对象探秘
- 1.10 并发的可达性分析相关问题
- 二.Java集合架构
- 1.ArrayList深入源码分析
- 2.Vector深入源码分析
- 3.LinkedList深入源码分析
- 4.HashMap深入源码分析
- 5.ConcurrentHashMap深入源码分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的设计模式
- 8.集合架构之面试指南
- 9.TreeSet和TreeMap
- 三.Java基础
- 1.基础概念
- 1.1 Java程序初始化的顺序是怎么样的
- 1.2 Java和C++的区别
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字节与字符的区别以及访问修饰符
- 1.7 深拷贝与浅拷贝
- 1.8 字符串常量池
- 2.面向对象
- 3.关键字
- 4.基本数据类型与运算
- 5.字符串与数组
- 6.异常处理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 数据流(Stream)
- 8.3 Java 8 并发教程:线程和执行器
- 8.4 Java 8 并发教程:同步和锁
- 8.5 Java 8 并发教程:原子变量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、数值、算术和文件
- 8.7 在 Java 8 中避免 Null 检查
- 8.8 使用 Intellij IDEA 解决 Java 8 的数据流问题
- 四.Java 并发编程
- 1.线程的实现/创建
- 2.线程生命周期/状态转换
- 3.线程池
- 4.线程中的协作、中断
- 5.Java锁
- 5.1 乐观锁、悲观锁和自旋锁
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平锁和非公平锁
- 5.3.1 说说ReentrantLock的实现原理,以及ReentrantLock的核心源码是如何实现的?
- 5.5 锁优化和升级
- 6.多线程的上下文切换
- 7.死锁的产生和解决
- 8.J.U.C(java.util.concurrent)
- 0.简化版(快速复习用)
- 9.锁优化
- 10.Java 内存模型(JMM)
- 11.ThreadLocal详解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的实现原理
- 1.DelayQueue的实现原理
- 14.Thread.join()实现原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的实际使用场景
- 五.Java I/O NIO
- 1.I/O模型简述
- 2.Java NIO之缓冲区
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之选择器
- 6.基于 Java NIO 实现简单的 HTTP 服务器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面试题
- 六.Java设计模式
- 1.单例模式
- 2.策略模式
- 3.模板方法
- 4.适配器模式
- 5.简单工厂
- 6.门面模式
- 7.代理模式
- 七.数据结构和算法
- 1.什么是红黑树
- 2.二叉树
- 2.1 二叉树的前序、中序、后序遍历
- 3.排序算法汇总
- 4.java实现链表及链表的重用操作
- 4.1算法题-链表反转
- 5.图的概述
- 6.常见的几道字符串算法题
- 7.几道常见的链表算法题
- 8.leetcode常见算法题1
- 9.LRU缓存策略
- 10.二进制及位运算
- 10.1.二进制和十进制转换
- 10.2.位运算
- 11.常见链表算法题
- 12.算法好文推荐
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事务管理
- 4.SpringMVC 运行流程和手动实现
- 0.Spring 核心技术
- 5.spring如何解决循环依赖问题
- 6.springboot自动装配原理
- 7.Spring中的循环依赖解决机制中,为什么要三级缓存,用二级缓存不够吗
- 8.beanFactory和factoryBean有什么区别
- 九.数据库
- 1.mybatis
- 1.1 MyBatis-# 与 $ 区别以及 sql 预编译
- Mybatis系列1-Configuration
- Mybatis系列2-SQL执行过程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-参数设置揭秘(ParameterHandler)
- Mybatis系列8-缓存机制
- 2.浅谈聚簇索引和非聚簇索引的区别
- 3.mysql 证明为什么用limit时,offset很大会影响性能
- 4.MySQL中的索引
- 5.数据库索引2
- 6.面试题收集
- 7.MySQL行锁、表锁、间隙锁详解
- 8.数据库MVCC详解
- 9.一条SQL查询语句是如何执行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能优化神器 Explain 使用分析
- 12.mysql中,一条update语句执行的过程是怎么样的?期间用到了mysql的哪些log,分别有什么作用
- 十.Redis
- 0.快速复习回顾Redis
- 1.通俗易懂的Redis数据结构基础教程
- 2.分布式锁(一)
- 3.分布式锁(二)
- 4.延时队列
- 5.位图Bitmaps
- 6.Bitmaps(位图)的使用
- 7.Scan
- 8.redis缓存雪崩、缓存击穿、缓存穿透
- 9.Redis为什么是单线程、及高并发快的3大原因详解
- 10.布隆过滤器你值得拥有的开发利器
- 11.Redis哨兵、复制、集群的设计原理与区别
- 12.redis的IO多路复用
- 13.相关redis面试题
- 14.redis集群
- 十一.中间件
- 1.RabbitMQ
- 1.1 RabbitMQ实战,hello world
- 1.2 RabbitMQ 实战,工作队列
- 1.3 RabbitMQ 实战, 发布订阅
- 1.4 RabbitMQ 实战,路由
- 1.5 RabbitMQ 实战,主题
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 实战 – 整合 RabbitMQ 发送邮件
- 1.8 RabbitMQ 的消息持久化与 Spring AMQP 的实现剖析
- 1.9 RabbitMQ必备核心知识
- 2.RocketMQ 的几个简单问题与答案
- 2.Kafka
- 2.1 kafka 基础概念和术语
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志机制
- 2.4 kafka是pull还是push的方式传递消息的?
- 2.5 Kafka的数据处理流程
- 2.6 Kafka的脑裂预防和处理机制
- 2.7 Kafka中partition副本的Leader选举机制
- 2.8 如果Leader挂了的时候,follower没来得及同步,是否会出现数据不一致
- 2.9 kafka的partition副本是否会出现脑裂情况
- 十二.Zookeeper
- 0.什么是Zookeeper(漫画)
- 1.使用docker安装Zookeeper伪集群
- 3.ZooKeeper-Plus
- 4.zk实现分布式锁
- 5.ZooKeeper之Watcher机制
- 6.Zookeeper之选举及数据一致性
- 十三.计算机网络
- 1.进制转换:二进制、八进制、十六进制、十进制之间的转换
- 2.位运算
- 3.计算机网络面试题汇总1
- 十四.Docker
- 100.面试题收集合集
- 1.美团面试常见问题总结
- 2.b站部分面试题
- 3.比心面试题
- 4.腾讯面试题
- 5.哈罗部分面试
- 6.笔记
- 十五.Storm
- 1.Storm和流处理简介
- 2.Storm 核心概念详解
- 3.Storm 单机版本环境搭建
- 4.Storm 集群环境搭建
- 5.Storm 编程模型详解
- 6.Storm 项目三种打包方式对比分析
- 7.Storm 集成 Redis 详解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初识ElasticSearch
- 2.文档基本CRUD、集群健康检查
- 3.shard&replica
- 4.document核心元数据解析及ES的并发控制
- 5.document的批量操作及数据路由原理
- 6.倒排索引
- 十七.分布式相关
- 1.分布式事务解决方案一网打尽
- 2.关于xxx怎么保证高可用的问题
- 3.一致性hash原理与实现
- 4.微服务注册中心 Nacos 比 Eureka的优势
- 5.Raft 协议算法
- 6.为什么微服务架构中需要网关
- 0.CAP与BASE理论
- 十八.Dubbo
- 1.快速掌握Dubbo常规应用
- 2.Dubbo应用进阶
- 3.Dubbo调用模块详解
- 4.Dubbo调用模块源码分析
- 6.Dubbo协议模块